إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
يدعم Azure الذكاء الاصطناعي Search طريقتين أساسيتين لاستيراد البيانات إلى فهرس البحث: دفع بياناتك إلى الفهرس بشكل برمجي أو سحب بياناتك عن طريق توجيه مؤشر إلى مصدر بيانات مدعوم.
يشرح هذا البرنامج التعليمي كيفية فهرسة البيانات بكفاءة باستخدام نموذج الدفع عن طريق تجميع الطلبات واستخدام استراتيجية إعادة محاولة التراجع الأسي. يمكنك تحميل وتشغيل نموذج التطبيق. يشرح هذا البرنامج التعليمي أيضا الجوانب الرئيسية للتطبيق والعوامل التي يجب مراعاتها عند فهرسة البيانات.
في هذا البرنامج التعليمي، يمكنك استخدام C# ومكتبة Azure.Search.Documents من Azure SDK ل .NET إلى:
- إنشاء فهرس
- اختبار أحجام الدفعات المختلفة لتحديد الحجم الأكثر كفاءة
- دفعات الفهرس بشكل غير متزامن
- استخدام مؤشرات ترابط متعددة لزيادة سرعات الفهرسة
- استخدام استراتيجية إعادة محاولة التراجع الأسي لإعادة محاولة المستندات الفاشلة
المتطلبات الأساسية
- حساب Azure مع اشتراك نشط. أنشئ حساباً مجاناً.
- الاستوديو المرئي.
تنزيل الملفات
توجد التعليمات البرمجية المصدر لهذا البرنامج التعليمي في المجلد optimize-data-indexing/v11 في مستودع GitHub Azure-Samples/azure-search-dotnet-scale .
الاعتبارات الرئيسية
تؤثر العوامل التالية على سرعات الفهرسة. لمزيد من المعلومات، راجع فهرسة مجموعات البيانات الكبيرة.
- مستوى التسعير وعدد الأقسام/النسخ المقلدة: إضافة أقسام أو ترقية المستوى يزيد من سرعة الفهرسة.
- تعقيد مخطط الفهرس: تؤدي إضافة الحقول وخصائص الحقول إلى خفض سرعات الفهرسة. الفهارس الأصغر أسرع للفهرسة.
- حجم الدفعة: يختلف حجم الدفعة الأمثل استنادا إلى مخطط الفهرس ومجموعة البيانات.
- عدد مؤشرات الترابط/العمال: لا يستفيد مؤشر الترابط الواحد استفادة كاملة من سرعات الفهرسة.
- استراتيجية إعادة المحاولة: استراتيجية إعادة محاولة التراجع الأسي هي أفضل ممارسة للفهرسة المثلى.
- سرعات نقل بيانات الشبكة: يمكن أن تكون سرعات نقل البيانات عاملا مقيدا. فهرسة البيانات من داخل بيئة Azure لزيادة سرعات نقل البيانات.
إنشاء خدمة بحث
يتطلب هذا البرنامج التعليمي خدمة Azure الذكاء الاصطناعي Search، والتي يمكنك إنشاؤها في مدخل Microsoft Azure. يمكنك أيضا العثور على خدمة موجودة في اشتراكك الحالي. لاختبار وتحسين سرعات الفهرسة بدقة، نوصي باستخدام نفس مستوى التسعير الذي تخطط لاستخدامه في الإنتاج.
الحصول على مفتاح مسؤول وعنوان URL ل Azure الذكاء الاصطناعي Search
يستخدم هذا البرنامج التعليمي المصادقة المستندة إلى المفتاح. انسخ مفتاح واجهة برمجة تطبيقات المسؤول للصقها في appsettings.json الملف.
انتقل إلى خدمة البحث في مدخل Microsoft Azure.
من اللوحة اليسرى، اختر نظرة عامة وانسخ نقطة النهاية. يجب أن يكون بهذا الشكل:
https://my-service.search.windows.netمن اللوحة اليسرى، اخترمفاتيح> وانسخ مفتاح المسؤول للحصول على الصلاحيات الكاملة للخدمة. هناك مفتاحان مسؤولان قابلان للتبديل، مقدمان لاستمرارية العمل في حالة الحاجة إلى لفة واحدة. يمكنك استخدام أي من المفتاحين على طلبات الإضافة أو التعديل أو حذف الكائنات.
إعداد بيئتك
افتح الملف
OptimizeDataIndexing.slnفي Visual Studio.في مستكشف الحلول، قم بتعديل الملف
appsettings.jsonباستخدام معلومات الاتصال التي جمعتها في الخطوة السابقة.{ "SearchServiceUri": "https://{service-name}.search.windows.net", "SearchServiceAdminApiKey": "", "SearchIndexName": "optimize-indexing" }
استكشاف التعليمات البرمجية
بعد التحديث appsettings.json، يجب أن يكون البرنامج النموذجي جاهزا OptimizeDataIndexing.sln للبناء والتشغيل.
هذه التعليمة البرمجية مشتقة من قسم C# من Quickstart: بحث النص الكامل، والذي يوفر معلومات مفصلة حول أساسيات العمل مع .NET SDK.
هذا التطبيق وحدة التحكم C#/.NET بسيط ينفذ المهام التالية:
- إنشاء فهرس جديد استنادا إلى بنية البيانات لفئة C#
Hotel(التي تشير أيضا إلىAddressالفئة) - اختبار أحجام الدفعات المختلفة لتحديد الحجم الأكثر كفاءة
- فهرسة البيانات بشكل غير متزامن
- استخدام مؤشرات ترابط متعددة لزيادة سرعات الفهرسة
- استخدام استراتيجية إعادة محاولة التراجع الأسي لإعادة محاولة العناصر الفاشلة
قبل تشغيل البرنامج، خذ دقيقة لدراسة الكود وتعريفات المؤشرات لهذه العينة. توجد التعليمات البرمجية ذات الصلة في عدة ملفات:
-
Hotel.csوتحتويAddress.csعلى المخطط الذي يعرف الفهرس -
DataGenerator.csتحتوي على فئة بسيطة لتسهيل إنشاء كميات كبيرة من بيانات الفنادق -
ExponentialBackoff.csيحتوي على كود لتحسين عملية الفهرسة كما هو موضح في هذا المقال -
Program.csيحتوي على وظائف تنشئ وتحذف فهرس البحث الذكاء الاصطناعي في Azure، وتقوم بفهرسة دفعات من البيانات، وتختبر أحجام دفعات مختلفة
إنشاء الفهرس
يستخدم هذا البرنامج النموذجي Azure SDK ل .NET لتعريف وإنشاء فهرس Azure الذكاء الاصطناعي Search. يستفيد من FieldBuilder الفئة لإنشاء بنية فهرس من فئة نموذج بيانات C#.
يتم تعريف نموذج البيانات بواسطة Hotel الفئة التي تحتوي أيضا على مراجع إلى Address الفئة.
FieldBuilder التنقل لأسفل من خلال تعريفات فئة متعددة لإنشاء بنية بيانات معقدة للفهرس. يتم استخدام علامات بيانات التعريف لتعريف سمات كل حقل، مثل ما إذا كان قابلا للبحث أو للفرز.
تحدد المقتطفات التالية من Hotel.cs الملف حقلا واحدا ومرجعا إلى فئة نموذج بيانات أخرى.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
في Program.cs الملف، يعرف الفهرس باسم ومجموعة حقول تولدها FieldBuilder.Build(typeof(Hotel)) الطريقة، ثم يتم إنشاؤه كما يلي:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
إنشاء البيانات
يتم تنفيذ فئة بسيطة في الملف DataGenerator.cs لتوليد بيانات للاختبار. الغرض من هذه الفئة هو تسهيل إنشاء عدد كبير من المستندات بمعرف فريد للفهرسة.
للحصول على قائمة تضم 100,000 فندق بمعرفات فريدة، قم بتشغيل التعليمات البرمجية التالية:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
هناك حجمان من الفنادق المتاحة للاختبار في هذه العينة: صغيرةوكبيرة.
يؤثر مخطط الفهرس على سرعات الفهرسة. بعد إكمال هذا البرنامج التعليمي، ضع في اعتبارك تحويل هذه الفئة لإنشاء بيانات تتطابق مع مخطط الفهرس المقصود على أفضل نحو.
اختبار أحجام الدفعات
لتحميل مستندات مفردة أو متعددة في فهرس، يدعم Azure الذكاء الاصطناعي Search واجهات برمجة التطبيقات التالية:
تؤدي فهرسة المستندات على دفعات إلى تحسين أداء الفهرسة بشكل كبير. يمكن أن تصل هذه الدفعات إلى 1000 مستند أو ما يصل إلى حوالي 16 ميغابايت لكل دفعة.
يعد تحديد الحجم الأمثل للدفعة لبياناتك مكونا رئيسيا لتحسين سرعات الفهرسة. العاملان الأساسيان التان تؤثران على الحجم الأمثل للدفعة هما:
- مخطط الفهرس
- حجم بياناتك
نظرا لأن الحجم الأمثل للدفعة يعتمد على الفهرس والبيانات الخاصة بك، فإن أفضل طريقة هي اختبار أحجام دفعات مختلفة لتحديد النتائج في أسرع سرعات الفهرسة للسيناريو الخاص بك.
توضح الدالة التالية نهجا بسيطا لاختبار أحجام الدفعات.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
نظرا لعدم وجود نفس الحجم لجميع المستندات (على الرغم من أنها موجودة في هذه العينة)، فإننا نقدر حجم البيانات التي نرسلها إلى خدمة البحث. يمكنك القيام بذلك باستخدام الدالة التالية التي تحول العنصر أولا إلى JSON ثم تحدد حجمه بالبايت. تتيح لنا هذه التقنية تحديد أحجام الدفعات الأكثر كفاءة من حيث سرعات الفهرسة بالميغابايت/الثانية.
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
تتطلب الدالة SearchClient بالإضافة إلى عدد المحاولات التي تريد اختبارها لكل حجم دفعة. نظرا لأنه قد يكون هناك تباين في أوقات الفهرسة لكل دفعة، جرب كل دفعة ثلاث مرات بشكل افتراضي لجعل النتائج أكثر أهمية إحصائيا.
await TestBatchSizesAsync(searchClient, numTries: 3);
عند تشغيل الدالة، يجب أن تشاهد إخراجا في وحدة التحكم الخاصة بك مشابها للمثال التالي:
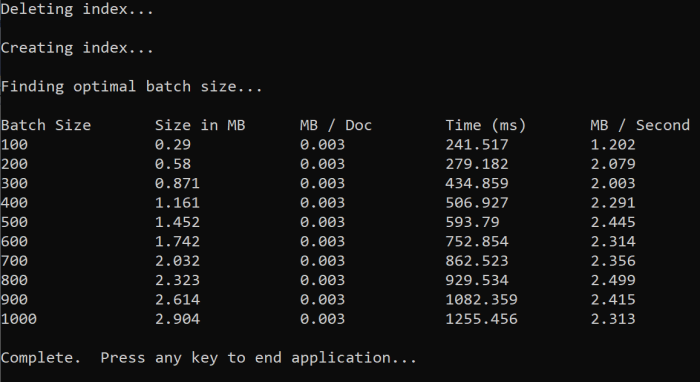
حدد حجم الدفعة الأكثر كفاءة واستخدم حجم الدفعة هذا في الخطوة التالية من هذا البرنامج التعليمي. قد ترى هضبة بالميغابايت/ثانية عبر أحجام دفعات مختلفة.
فهرسة البيانات
الآن بعد أن حددت حجم الدفعة الذي تنوي استخدامه، فإن الخطوة التالية هي البدء في فهرسة البيانات. لفهرسة البيانات بكفاءة، هذه العينة:
- يستخدم مؤشرات ترابط/عمال متعددة
- تنفيذ استراتيجية إعادة محاولة التراجع الأسي
قم بإلغاء تعليق الأسطر من 41 إلى 49، ثم أعد تشغيل البرنامج. في هذا التشغيل، يقوم النموذج بإنشاء وإرسال دفعات من المستندات، حتى 100000 إذا قمت بتشغيل التعليمات البرمجية دون تغيير المعلمات.
استخدام مؤشرات ترابط/عمال متعددة
للاستفادة من سرعات فهرسة Azure الذكاء الاصطناعي Search، استخدم مؤشرات ترابط متعددة لإرسال طلبات الفهرسة الدفعية بشكل متزامن إلى الخدمة.
يمكن أن تؤثر العديد من الاعتبارات الرئيسية على العدد الأمثل من مؤشرات الترابط. يمكنك تعديل هذا النموذج والاختبار مع عدد مؤشرات ترابط مختلفة لتحديد عدد مؤشرات الترابط الأمثل للسيناريو الخاص بك. ومع ذلك، طالما أن لديك العديد من مؤشرات الترابط التي تعمل بشكل متزامن، يجب أن تكون قادرا على الاستفادة من معظم مكاسب الكفاءة.
أثناء زيادة الطلبات التي تصل إلى خدمة البحث، قد تواجه رموز حالة HTTP تشير إلى أن الطلب لم ينجح بشكل كامل. أثناء الفهرسة، يوجد رمزان شائعان لحالة HTTP هما:
- 503 الخدمة غير متوفرة: يعني هذا الخطأ أن النظام تحت حمل ثقيل ولا يمكن معالجة طلبك في الوقت الحالي.
- 207 متعدد الحالات: يعني هذا الخطأ نجاح بعض المستندات، ولكن فشل مستند واحد على الأقل.
تنفيذ استراتيجية إعادة محاولة التراجع الأسي
إذا حدث فشل، يجب إعادة محاولة الطلبات باستخدام استراتيجية إعادة محاولة التراجع الأسي.
يقوم Azure الذكاء الاصطناعي Search.NET SDK تلقائيا بإعادة محاولة 503s والطلبات الفاشلة الأخرى، ولكن يجب عليك تنفيذ المنطق الخاص بك لإعادة محاولة 207s. يمكن أن تكون الأدوات مفتوحة المصدر مثل Polly مفيدة في استراتيجية إعادة المحاولة.
في هذه العينة، ننفذ استراتيجية إعادة محاولة التراجع الأسية الخاصة بنا. نبدأ بتعريف بعض المتغيرات، بما في maxRetryAttempts ذلك و الأولي delay لطلب فاشل.
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
يتم تخزين نتائج عملية الفهرسة في المتغير IndexDocumentResult result. يسمح لك هذا المتغير بالتحقق مما إذا كانت المستندات في الدفعة قد فشلت، كما هو موضح في المثال التالي. إذا كان هناك فشل جزئي، يتم إنشاء دفعة جديدة استنادا إلى معرف المستندات الفاشلة.
RequestFailedException يجب أيضا اكتشاف الاستثناءات، لأنها تشير إلى فشل الطلب تماما، وإعادة المحاولة.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
من هنا، قم بتضمين التعليمة البرمجية للتراجع الأسي في دالة بحيث يمكن استدعاؤها بسهولة.
ثم يتم إنشاء دالة أخرى لإدارة مؤشرات الترابط النشطة. للتبسيط، لا يتم تضمين هذه الدالة هنا ولكن يمكن العثور عليها في ExponentialBackoff.cs. يمكنك استدعاء الدالة باستخدام الأمر التالي، حيث hotels هي البيانات التي نريد تحميلها، 1000 هو حجم الدفعة، وهو 8 عدد مؤشرات الترابط المتزامنة.
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
عند تشغيل الدالة، يجب أن تشاهد إخراجا مشابها للمثال التالي:
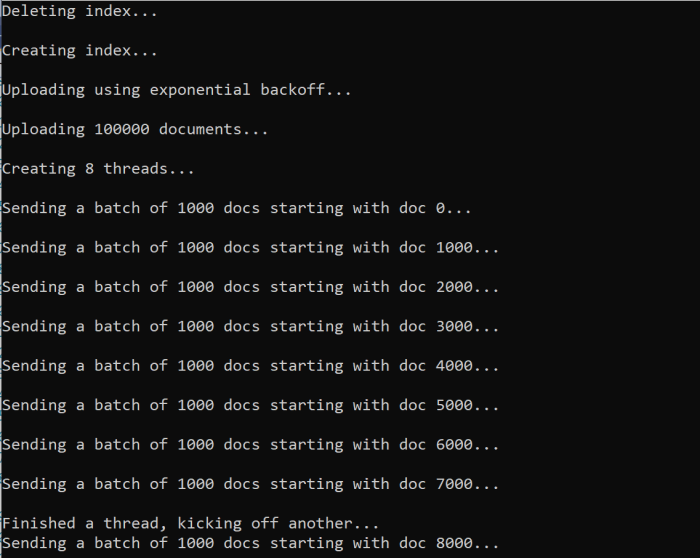
عند فشل دفعة من المستندات، تتم طباعة خطأ يشير إلى الفشل وأنه تتم إعادة محاولة الدفعة.
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
بعد انتهاء تشغيل الدالة، يمكنك التحقق من إضافة جميع المستندات إلى الفهرس.
استكشاف الفهرس
بعد انتهاء تشغيل البرنامج، يمكنك استكشاف فهرس البحث المملوء إما برمجيا أو باستخدام مستكشف البحث في مدخل Microsoft Azure.
برمجيا
هناك خياران رئيسيان للتحقق من عدد المستندات في فهرس: واجهة برمجة تطبيقات Count Documentsوواجهة برمجة تطبيقات Get Index Statistics. يتطلب كلا المسارين وقتا للمعالجة، لذلك لا تقلق إذا كان عدد المستندات التي تم إرجاعها في البداية أقل مما تتوقع.
عدد المستندات
تسترد عملية Count Documents عدد المستندات في فهرس البحث.
long indexDocCount = await searchClient.GetDocumentCountAsync();
الحصول على إحصائيات الفهرس
ترجع عملية الحصول على إحصائيات الفهرس عدد المستندات للفهرس الحالي، بالإضافة إلى استخدام التخزين. تستغرق إحصائيات الفهرس وقتا أطول للتحديث من عدد المستندات.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
مدخل Azure
في مدخل Microsoft Azure، من الجزء الأيمن، ابحث عن فهرس تحسين الفهرسة في قائمة الفهارس .

يستند عدد المستنداتوحجم التخزين إلى واجهة برمجة تطبيقات الحصول على إحصائيات الفهرس ويمكن أن يستغرق تحديثها عدة دقائق.
إعادة تعيين وإعادة تشغيل
في المراحل التجريبية المبكرة من التطوير، يتمثل النهج الأكثر عملية لتكرار التصميم في حذف الكائنات من Azure الذكاء الاصطناعي Search والسماح للتعليمات البرمجية بإعادة إنشائها. أسماء الموارد فريدة. يتيح لك حذف كائن إعادة إنشائه باستخدام نفس الاسم.
يتحقق نموذج التعليمات البرمجية لهذا البرنامج التعليمي من الفهارس الموجودة ويحذفها بحيث يمكنك إعادة تشغيل التعليمات البرمجية الخاصة بك.
يمكنك أيضا استخدام مدخل Microsoft Azure لحذف الفهارس.
تنظيف الموارد
عندما تعمل في اشتراكك الخاص، في نهاية المشروع، من المستحسن إزالة الموارد التي لم تعد بحاجة إليها. الموارد المتبقية قيد التشغيل يمكن أن تكلفك المال. يمكنك حذف الموارد بشكل فردي أو حذف مجموعة الموارد لحذف تشكيلة الموارد بأكملها.
يمكنك العثور على الموارد وإدارتها في مدخل Microsoft Azure، باستخدام الارتباط All resources أو Resource groups في جزء التنقل الأيسر.
الخطوة التالية
لمعرفة المزيد حول فهرسة كميات كبيرة من البيانات، جرب البرنامج التعليمي التالي: