التشغيل السريع: إنشاء تجمع Apache Spark بدون خادم جديد باستخدام بوابة Azure
يقدم Azure Synapse Analytics محركات تحليلات مختلفة لمساعدتك في استيعاب بياناتك، وتحويلها، ونمذجتها، وتحليلها، وتوزيعها. يوفر تجمع Apache Spark قدرات حساب البيانات الضخمة مفتوحة المصدر. بعد إنشاء تجمع Apache Spark في مساحة عمل Synapse، يمكن تحميل البيانات ونمذجتها ومعالجتها وتوزيعها للحصول على رؤية تحليلية أسرع.
في هذه البداية السريعة، يمكنك معرفة كيفية استخدام المدخل Azure لإنشاء تجمع Apache Spark في مساحة عمل Synapse.
هام
يتم تصنيف الفوترة لمثيلات Spark كل دقيقة، سواء كنت تستخدمها أم لا. تأكد من إيقاف تشغيل مثيل Spark بعد الانتهاء من استخدامه أو تحديد مهلة قصيرة. لمزيد من المعلومات، راجع قسم تنظيف الموارد من هذه المقالة.
في حال لم يكن لديك اشتراك Azure، فأنشئ حساباً مجانيّاً قبل البدء.
المتطلبات الأساسية
- ستحتاج إلى اشتراك Azure. إذا لزم الأمر، قم بإنشاء حساب Azure مجاني
- ستستخدم مساحة عمل Synapse.
سجِّل الدخول إلى مدخل Azure
سجِّل الدخول إلى مدخل Azure
الانتقال إلى مساحة عمل Synapse
انتقل إلى مساحة عمل Synapse حيث سيتم إنشاء تجمع Apache Spark بكتابة اسم الخدمة (أو اسم المورد مباشرة) في شريط البحث.
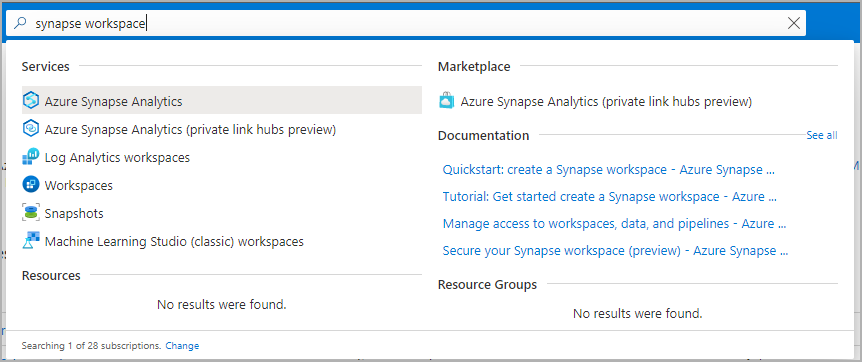
من قائمة مساحات العمل، اكتب اسم (أو جزءًا من الاسم) لمساحة العمل لفتحها. على سبيل المثال، نستخدم مساحة عمل تسمى contosoanalytics.
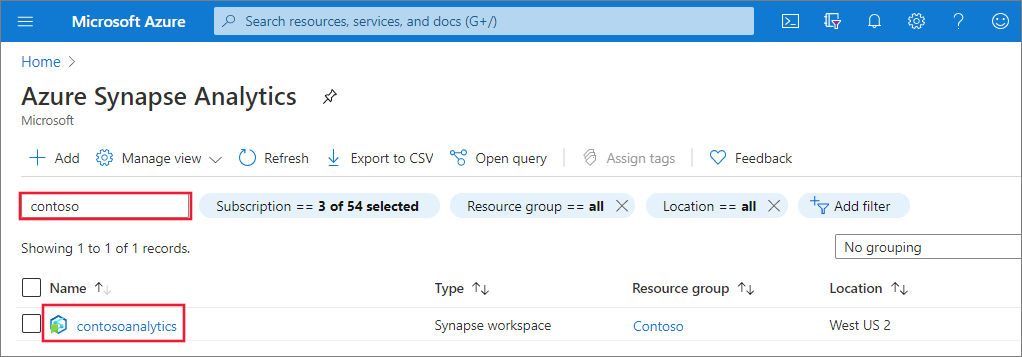


إنشاء مجموعة Apache Spark جديدة بدون خادم
هام
تم إهمال وقت تشغيل Azure Synapse ل Apache Spark 2.4 ولم يتم دعمه رسميا منذ سبتمبر 2023. نظرا إلى أن Spark 3.1 وSpark 3.2 هما أيضا انتهاء الدعم المعلن، نوصي العملاء بالترحيل إلى Spark 3.3.
في مساحة عمل Synapse حيث تريد إنشاء تجمع، حدد New Apache Spark pool.

أدخل التفاصيل التالية في علامة التبويب الأساسيات :
الإعدادات القيمة المقترحة الوصف اسم تجمع Apache Spark اسم تجمع صالح، مثل contososparkإنه الاسم الذي سيحمله تجمع Apache Spark. حجم العقدة صغير (4 vCPU / 32 GB) تعيين هذا إلى أصغر حجم لتقليل التكاليف لهذه البداية السريعة التحجيم التلقائي مُعطل نحن لسنا بحاجة إلى مقياس تلقائي لهذه البداية السريعة عدد العقد 5 استخدام حجم صغير للحد من التكاليف لهذه البداية السريعة 
هام
هناك قيود محددة للأسماء التي يمكن أن تستخدمها تجمعات Apache Spark. يجب أن تحتوي الأسماء على أحرف أو أرقام فقط، ويجب أن تكون 15 حرفًا أو أقل، ويجب أن تبدأ بحرف، ولا تحتوي على كلمات محجوزة، وأن تكون فريدة في مساحة العمل.
حدد التالي: إعدادات إضافية وراجع الإعدادات الافتراضية. لا تقم بتعديل أي إعدادات افتراضية.

حدد Next: tags. ضع في اعتبارك استخدام علامات Azure. على سبيل المثال، علامة "المالك" أو "CreatedBy" لتحديد من أنشأ المورد، وعلامة "البيئة" لتحديد ما إذا كان هذا المورد في الإنتاج والتطوير وما إلى ذلك. لمزيد من المعلومات، راجع تطوير استراتيجية التسمية ووضع العلامات لموارد Azure.

حدد "Review + create".
تأكد من أن التفاصيل تبدو صحيحة اعتمادًا على ما تم إدخاله مسبقًا وحدد Create.
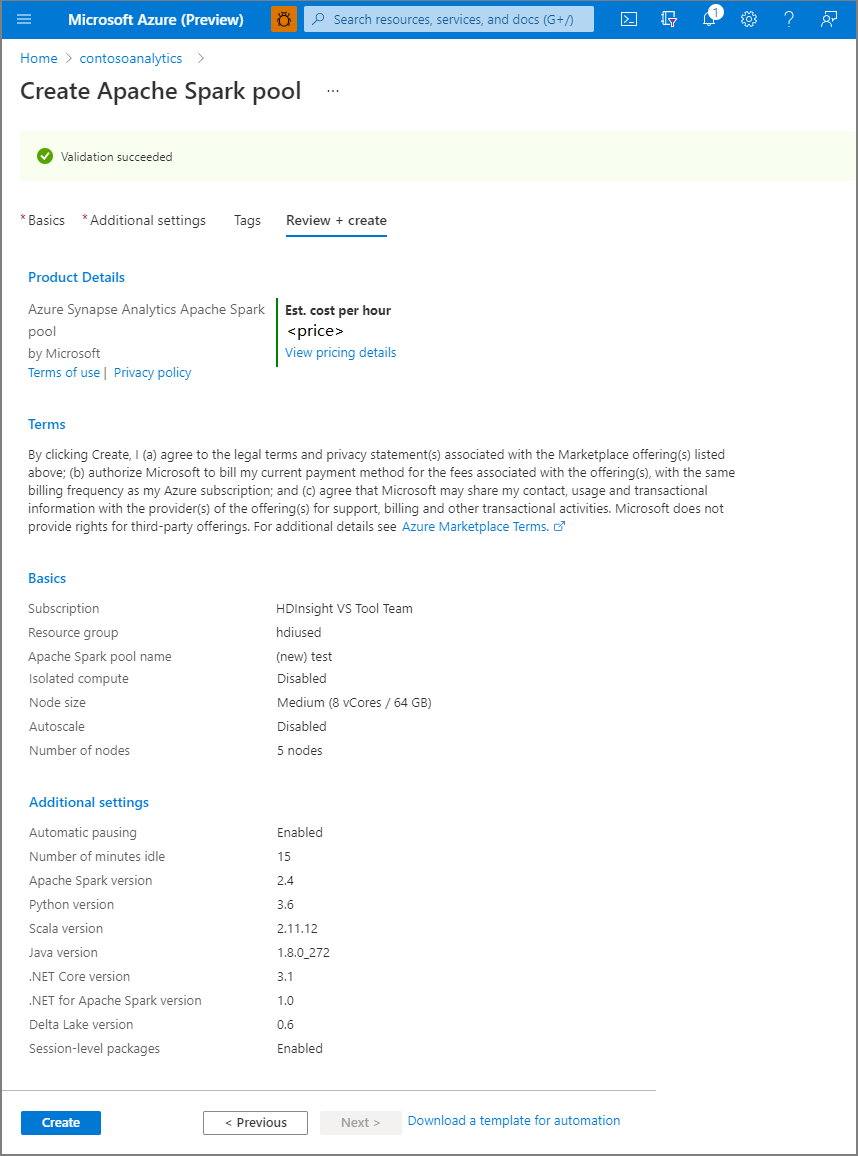
في هذه المرحلة، سيبدأ تدفق توفير الموارد، مشيرًا عند اكتماله.

بعد اكتمال التوفير، سيُظهر الانتقال مرة أخرى إلى مساحة العمل إدخالاً جديدًا لتجمع Apache Spark المخصص الذي تم إنشاؤه حديثًا.

عند هذه النقطة، لا توجد موارد قيد التشغيل، ولا توجد رسوم لـ Spark، لقد قمت بإنشاء بيانات تعريف حول مثيلات Spark التي تريد إنشاءَها.







تنظيف الموارد
تحذف الخطوات التالية تجمع Apache Spark من مساحة العمل.
تحذير
سيؤدي حذف تجمع Apache Spark إلى إزالة محرك التحليلات من مساحة العمل. لن يكون من الممكن الاتصال بالتجمع، ولن تعمل كافة الاستعلامات وخطوط الأنابيب وأجهزة الكمبيوتر المحمولة التي تستخدم تجمع Apache Spark هذا.
إذا كنت تريد حذف تجمع Apache Spark، فقم بالخطوات التالية:
- انتقل إلى جزء تجمعات Apache Spark في مساحة العمل.
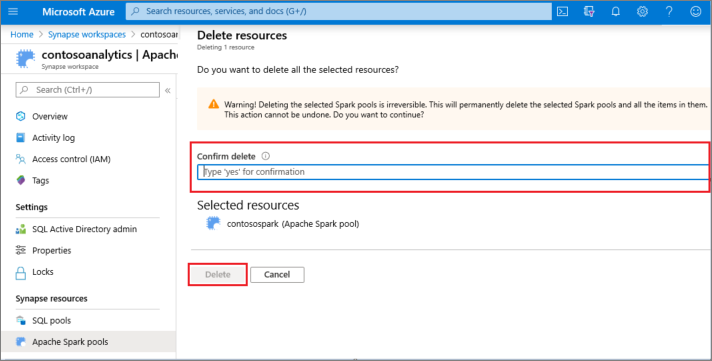
- حدد تجمع Apache Spark ليتم حذفه (في هذه الحالة، contosospark).
- حدد حذف.

- قم بتأكيد الحذف، وحدد الزر حذف .
- عند إكمال العملية بنجاح، لن يتم سرد وعاء Spark Apache في موارد مساحة العمل.
