البرنامج التعليمي: تدريب نموذج في Python باستخدام التعلّم الآلي التلقائي
يتمثل التعلم الآلي من Azure في بيئة تستند إلى السحابة تسمح لك بتدريب نماذج التعلّم الآلي ونشرها وتشغيلها تلقائياً وإدارتها وتتبعها.
في هذا البرنامج التعليمي، يمكنك استخدام التعلّم الآلي التلقائي في التعلم الآلي من Azure لإنشاء نموذج انحدار لتوقع أسعار سيارات الأجرة. تصل هذه العملية إلى أفضل نموذج من خلال قبول بيانات التدريب وإعدادات التكوين، والتكرار التلقائي عبر مجموعات مختلفة من الأساليب والنماذج وإعدادات الإفراط في قياس المعلمات.
في هذا البرنامج التعليمي، تتعلم كيفية:
- تنزيل البيانات باستخدام Apache Spark ومجموعات بيانات Azure المفتوحة.
- تحويل البيانات وتنظيفها باستخدام Apache Spark DataFrames.
- تدريب نموذج انحدار في التعلّم الآلي التلقائي.
- حساب دقة نموذج.
قبل البدء
- أنشئ مجموعة Apache Spark بلا خادم باتباع التشغيل السريع إنشاء مجموعة Apache Spark بلا خادم.
- أكمل برنامج إعداد مساحة عمل التعلم الآلي من Azure التعليمي إذا لم تكن لديك مساحة عمل تعلم آلي حالية من Azure.
تحذير
- اعتبارا من 29 سبتمبر 2023، سيتوقف Azure Synapse عن الدعم الرسمي لوقت تشغيل Spark 2.4. بعد 29 سبتمبر 2023، لن نتناول أي تذاكر دعم تتعلق ب Spark 2.4. لن يكون هناك مسار إصدار في مكانه لإصلاحات الأخطاء أو الأمان ل Spark 2.4. استخدام Spark 2.4 بعد تاريخ قطع الدعم يتم على مسؤوليته الخاصة. ونثبط بشدة استمرار استخدامها بسبب مخاوف أمنية ووظائف محتملة.
- كجزء من عملية إهمال Apache Spark 2.4، نود إعلامك بأن AutoML في Azure Synapse Analytics سيتم إهماله أيضا. يتضمن ذلك كلا من واجهة التعليمات البرمجية المنخفضة وواجهات برمجة التطبيقات المستخدمة لإنشاء إصدارات AutoML التجريبية من خلال التعليمات البرمجية.
- يرجى ملاحظة أن وظيفة AutoML كانت متوفرة حصريا من خلال وقت تشغيل Spark 2.4.
- بالنسبة للعملاء الذين يرغبون في الاستمرار في الاستفادة من إمكانات AutoML، نوصي بحفظ بياناتك في حساب Azure Data Lake Storage Gen2 (ADLSg2). من هناك، يمكنك الوصول بسلاسة إلى تجربة AutoML من خلال Azure التعلم الآلي (AzureML). تتوفر هنا معلومات إضافية حول هذا الحل البديل.
فهم نماذج الانحدار
تتوقع نماذج الانحدار بقيم الناتج العددي استناداً إلى مؤشرات مستقلة. في الانحدار، يتمثل الهدف في المساعدة على إنشاء علاقة بين متغيرات المؤشرات المستقلة تلك من خلال تقدير كيفية تأثير أحد المتغيرات في المتغيرات الأخرى.
مثال يستند إلى بيانات سيارات الأجرة في مدينة نيويورك
في هذا المثال، يمكنك استخدام Spark لإجراء بعض التحليلات على بيانات بقشيش رحلة سيارة أجرة من مدينة نيويورك (NYC). تتوفر البيانات من مجموعات بيانات Azure المفتوحة. تحتوي هذه المجموعة الفرعية من مجموعة البيانات على معلومات حول رحلات سيارات الأجرة الصفراء، بما في ذلك معلومات حول كل رحلة ووقت البدء والانتهاء والمواقع والتكلفة.
هام
قد تكون هناك رسوم إضافية لسحب هذه البيانات من موقع تخزينها. في الخطوات الآتية، تقوم بتطوير نموذج لتوقع أسعار سيارات الأجرة في مدينة نيويورك.
تنزيل البيانات وإعدادها
وإليك الطريقة:
إنشاء دفتر ملاحظات باستخدام PySpark kernel. للحصول على الإرشادات، راجع إنشاء دفتر ملاحظات.
إشعار
بفضل نظام نواة PySpark، فإنك لن تحتاج إلى إنشاء أي سياقات بشكل صريح. يتم إنشاء سياق Spark تلقائيًا عند تشغيلك لأول خلية رمز.
يمكنك استخدام سياق Spark لسحب الملف مباشرةً إلى الذاكرة في صورة DataFrame، لأن البيانات غير المنسقة تكون بتنسيق Parquet. إنشاء Spark DataFrame من خلال استرداد البيانات عبر "واجهة برمجة تطبيقات مجموعات البيانات المفتوحة". في هذه الحالة، يمكنك استخدام خصائص Spark DataFrame
schema on readلاستنتاج أنواع البيانات والمخطط.blob_account_name = "azureopendatastorage" blob_container_name = "nyctlc" blob_relative_path = "yellow" blob_sas_token = r"" # Allow Spark to read from the blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name),blob_sas_token) # Spark read parquet; note that it won't load any data yet df = spark.read.parquet(wasbs_path)بناءً على حجم مجموعة Spark، فقد تكون البيانات غير المنسقة كبيرة للغاية أو تستغرق وقتاً طويلاً للعمل عليها. يمكنك تصفية هذه البيانات وصولاً إلى حجم أصغر، مثل شهر من البيانات، وذلك باستخدام عوامل التصفية
start_dateوend_date. بعد تصفية DataFrame، يمكنك أيضاً تشغيل الدالةdescribe()على DataFrame الجديد لاستعراض إحصائيات موجزة لكل حقل.استناداً إلى الإحصائيات الموجزة، يمكنك ملاحظة وجود بعض حالات عدم الانتظام في البيانات. على سبيل المثال، تُظهر الإحصائيات أن الحد الأدنى لمسافة الرحلة أقل من 0. تحتاج إلى تصفية نقاط البيانات غير المنتظمة هذه.
# Create an ingestion filter start_date = '2015-01-01 00:00:00' end_date = '2015-12-31 00:00:00' filtered_df = df.filter('tpepPickupDateTime > "' + start_date + '" and tpepPickupDateTime< "' + end_date + '"') filtered_df.describe().show()أنشئ ميزات من مجموعة البيانات من خلال تحديد مجموعة من الأعمدة وإنشاء ميزات مختلفة تستند إلى الوقت من حقل الالتقاء
datetime. يجب تصفية القيم الخارجية التي تم تحديدها من الخطوة السابقة، ثم إزالة الأعمدة القليلة المتبقية لأنها غير ضرورية للتدريب.from datetime import datetime from pyspark.sql.functions import * # To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) taxi_df = sampled_taxi_df.select('vendorID', 'passengerCount', 'tripDistance', 'startLon', 'startLat', 'endLon' \ , 'endLat', 'paymentType', 'fareAmount', 'tipAmount'\ , column('puMonth').alias('month_num') \ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , date_format('tpepPickupDateTime', 'EEEE').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month') ,(unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('trip_time'))\ .filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\ & (sampled_taxi_df.tipAmount >= 0)\ & (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\ & (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\ & (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 200)\ & (sampled_taxi_df.rateCodeId <= 5)\ & (sampled_taxi_df.paymentType.isin({"1", "2"}))) taxi_df.show(10)كما يتضح، سيُنشئ هذا DataFrame جديداً بأعمدة إضافية ليوم الشهر وساعة الالتقاء واليوم من الأسبوع وإجمالي وقت الرحلة.

إنشاء مجموعات بيانات الاختبار والتحقق من الصحة
بعد حصولك على مجموعة البيانات النهائية، يمكنك تقسيم البيانات إلى مجموعات التدريب والاختبار باستخدام الدالة random_ split في Spark. باستخدام الأحجام المزودة، تُقسم هذه الدالة البيانات عشوائياً إلى مجموعة بيانات التدريب لتدريب النموذج ومجموعة بيانات التحقق من الصحة للاختبار.
# Random split dataset using Spark; convert Spark to pandas
training_data, validation_data = taxi_df.randomSplit([0.8,0.2], 223)
تضمن هذه الخطوة أن نقاط البيانات المستخدمة لاختبار النموذج النهائي لم تستخدم لتدريب النموذج.
الاتصال بمساحة عمل التعلم الآلي من Azure
تُمثل مساحة العمل في التعلم الآلي من Azure فئة تقبل اشتراك Azure الخاص بك ومعلومات المورد. كما أنها تنشئ موردًا سحابيًّا لمراقبة وتتبع تشغيل النموذج الخاص بك. في هذه الخطوة، تقوم بإنشاء كائن مساحة عمل من مساحة عمل التعلم الآلي من Azure الموجودة حالياً.
from azureml.core import Workspace
# Enter your subscription id, resource group, and workspace name.
subscription_id = "<enter your subscription ID>" #you should be owner or contributor
resource_group = "<enter your resource group>" #you should be owner or contributor
workspace_name = "<enter your workspace name>" #your workspace name
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
تحويل DataFrame إلى مجموعة بيانات التعلم الآلي من Azure
لإرسال تجربة عن بُعد، حول مجموعة البيانات إلى مثيل التعلم الآلي من Azure TabularDatset. تعرض TabularDataset البيانات بتنسيق جدولي من خلال تحليل الملفات المزودة.
تحصل التعليمة البرمجية الآتية على مساحة العمل الموجودة ومخزن البيانات الافتراضي للتعلم الآلي من Azure. ثم تمرر مواقع مخزن البيانات والملف إلى معلمة المسار لإنشاء مثيل TabularDataset جديد.
import pandas
from azureml.core import Dataset
# Get the Azure Machine Learning default datastore
datastore = ws.get_default_datastore()
training_pd = training_data.toPandas().to_csv('training_pd.csv', index=False)
# Convert into an Azure Machine Learning tabular dataset
datastore.upload_files(files = ['training_pd.csv'],
target_path = 'train-dataset/tabular/',
overwrite = True,
show_progress = True)
dataset_training = Dataset.Tabular.from_delimited_files(path = [(datastore, 'train-dataset/tabular/training_pd.csv')])

إرسال تجربة تلقائية
ترشدك الأقسام التالية خلال عملية إرسال تجربة التعلّم الآلي التلقائي.
تحديد إعدادات التدريب
لإرسال تجربة، تحتاج إلى تحديد معلمة التجربة وإعدادات النموذج للتدريب. للحصول على قائمة كاملة بالإعدادات، راجع تكوين تجارب التعلّم الآلي التلقائي في Python.
import logging automl_settings = { "iteration_timeout_minutes": 10, "experiment_timeout_minutes": 30, "enable_early_stopping": True, "primary_metric": 'r2_score', "featurization": 'auto', "verbosity": logging.INFO, "n_cross_validations": 2}مرر إعدادات التدريب المحددة بوصفها معلمة
kwargsللكائنAutoMLConfig. نظراً إلى أنك تستخدم Spark، يجب عليك أيضاً تمرير سياق Spark، الذي يمكن الوصول إليه تلقائياً بواسطة المتغيرsc. إضافة إلى ذلك، تقوم بتحديد بيانات التدريب ونوع النموذج، الذي يتمثل في الانحدار في هذه الحالة.from azureml.train.automl import AutoMLConfig automl_config = AutoMLConfig(task='regression', debug_log='automated_ml_errors.log', training_data = dataset_training, spark_context = sc, model_explainability = False, label_column_name ="fareAmount",**automl_settings)
إشعار
تصبح خطوات المعالجة السابقة للتعلّم الآلي التلقائي جزءاً من النموذج الأساسي. تتضمن هذه الخطوات تسوية الميزة ومعالجة البيانات المفقودة وتحويل النصوص إلى أرقام. عند استخدام النموذج للتوقعات، يتم تطبيق خطوات المعالجة السابقة نفسها التي تم تطبيقها في أثناء التدريب على بيانات الإدخال تلقائياً.
تدريب نموذج الانحدار التلقائي
بعد ذلك، تقوم بإنشاء كائن تجربة في مساحة عمل التعلم الآلي من Azure. تعمل التجربة كحاوية لعمليات التشغيل الفردية الخاصة بك.
from azureml.core.experiment import Experiment
# Start an experiment in Azure Machine Learning
experiment = Experiment(ws, "aml-synapse-regression")
tags = {"Synapse": "regression"}
local_run = experiment.submit(automl_config, show_output=True, tags = tags)
# Use the get_details function to retrieve the detailed output for the run.
run_details = local_run.get_details()
عند انتهاء التجربة، يُعيد الناتج تفاصيل حول التكرارات المكتملة. تظهر معلومات نوع النموذج ومدة التشغيل ودقة التدريب لكل تكرار. يتتبع الحقل BEST درجة أفضل تدريب قيد التشغيل بناءً على نوع المقياس الذي تستخدمه.

إشعار
بعد إرسال تجربة التعلّم الآلي التلقائي، تقوم بتشغيل تكرارات وأنواع نماذج متعددة. يستغرق هذا التشغيل بشكل نموذجي من 60 إلى 90 دقيقة.
استرداد أفضل نموذج
لتحديد أفضل نموذج من التكرارات، استخدم دالة get_output لإرجاع أفضل نموذج من حيث التشغيل والمواءمة. تسترد التعليمة البرمجية الآتية أفضل نموذج من حيث التشغيل والمواءمة لأي مقياس مُسجل أو تكرار محدد.
# Get best model
best_run, fitted_model = local_run.get_output()
اختبار دقة النموذج
لاختبار دقة النموذج، استخدم أفضل نموذج لتشغيل توقعات أسعار سيارة الأجرة في مجموعة بيانات الاختبار. تستخدم الدالة
predictأفضل نموذج وتتوقع قيمy(مبلغ الأجرة) من مجموعة بيانات التحقق من الصحة.# Test best model accuracy validation_data_pd = validation_data.toPandas() y_test = validation_data_pd.pop("fareAmount").to_frame() y_predict = fitted_model.predict(validation_data_pd)يستخدم خطأ متوسط الجذر التربيعي عادة لقياس الاختلافات بين قيم العينة المتوقعة من النموذج والقيم المُلاحظة. يمكنك حساب خطأ متوسط الجذر التربيعي للنتائج من خلال مقارنة
y_testDataFrame بالقيم المتوقعة من النموذج.تأخذ الدالة
mean_squared_errorمصفوفتين وتحسب متوسط الخطأ التربيعي بينهما. ثم تأخذ الجذر التربيعي للنتيجة. يشير هذا المقياس بشكل تقريبي إلى الفارق بين توقعات أسعار سيارة الأجرة وبين قيم الأسعار الفعلية.from sklearn.metrics import mean_squared_error from math import sqrt # Calculate root-mean-square error y_actual = y_test.values.flatten().tolist() rmse = sqrt(mean_squared_error(y_actual, y_predict)) print("Root Mean Square Error:") print(rmse)Root Mean Square Error: 2.309997102577151يعد خطأ متوسط الجذر التربيعي مقياساً جيداً لدقة توقع النموذج للاستجابة. من النتائج، يمكنك ملاحظة أن النموذج جيد إلى حد ما في توقع أسعار سيارات الأجرة من ميزات مجموعة البيانات، بشكل نموذجي في حدود 2.00 دولار.
شغل التعليمة البرمجية الآتية لحساب متوسط النسبة المئوية المطلقة للخطأ. يُعبر هذا المقياس عن الدقة كنسبة مئوية للخطأ. ويقوم بذلك من خلال حساب الاختلاف المطلق بين كل قيمة متوقعة وفعلية ثم جمع كل الاختلافات. ثم يعبر عن هذا المجموع كنسبة مئوية من إجمالي القيم الفعلية.
# Calculate mean-absolute-percent error and model accuracy sum_actuals = sum_errors = 0 for actual_val, predict_val in zip(y_actual, y_predict): abs_error = actual_val - predict_val if abs_error < 0: abs_error = abs_error * -1 sum_errors = sum_errors + abs_error sum_actuals = sum_actuals + actual_val mean_abs_percent_error = sum_errors / sum_actuals print("Model MAPE:") print(mean_abs_percent_error) print() print("Model Accuracy:") print(1 - mean_abs_percent_error)Model MAPE: 0.03655071038487368 Model Accuracy: 0.9634492896151263من مقاييس دقة التوقع، يمكنك ملاحظة أن النموذج جيد إلى حد ما في توقع أسعار سيارات الأجرة من ميزات مجموعة البيانات.
بعد ملاءمة نموذج الانحدار الخطي، أنت الآن بحاجة إلى تحديد مدى ملاءمة النموذج للبيانات. للقيام بذلك، يمكنك رسم قيم الأجرة الفعلية مقابل الناتج المتوقع. إضافة إلى ذلك، يمكنك حساب قياس R-تربيع لفهم مدى اقتراب البيانات من خط الانحدار الملائم.
import matplotlib.pyplot as plt import numpy as np from sklearn.metrics import mean_squared_error, r2_score # Calculate the R2 score by using the predicted and actual fare prices y_test_actual = y_test["fareAmount"] r2 = r2_score(y_test_actual, y_predict) # Plot the actual versus predicted fare amount values plt.style.use('ggplot') plt.figure(figsize=(10, 7)) plt.scatter(y_test_actual,y_predict) plt.plot([np.min(y_test_actual), np.max(y_test_actual)], [np.min(y_test_actual), np.max(y_test_actual)], color='lightblue') plt.xlabel("Actual Fare Amount") plt.ylabel("Predicted Fare Amount") plt.title("Actual vs Predicted Fare Amount R^2={}".format(r2)) plt.show()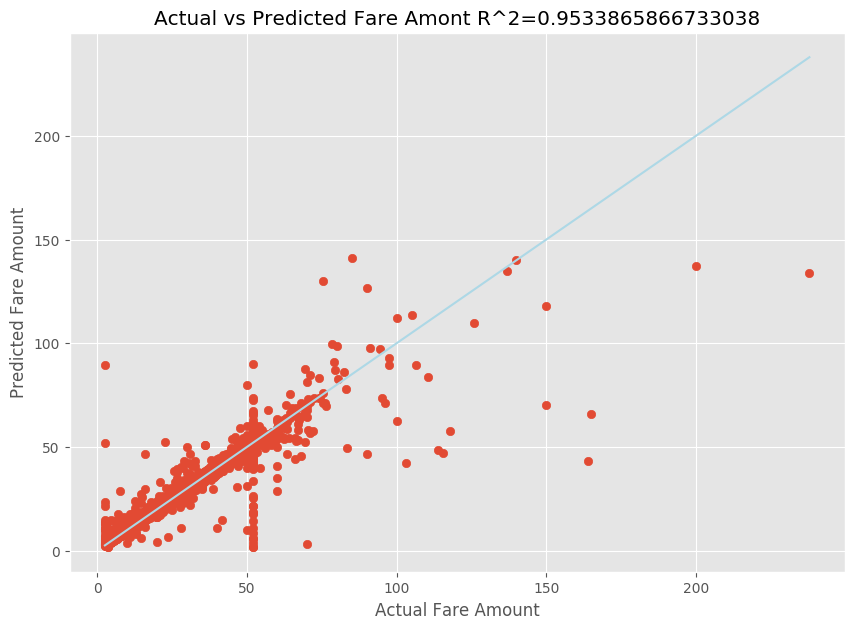
من النتائج، يمكنك ملاحظة أن قياس R-تربيع يُمثل 95 في المئة من نسبة الفارق. يتم التحقق من صحة ذلك أيضاً من خلال المقارنة بين الرسم الفعلي والرسم المُلاحظ. كلما زاد الفارق الذي يمثله نموذج الانحدار، اقتربت نقاط البيانات من خط الانحدار الملائم.
تسجيل النموذج في التعلم الآلي من Azure
بعد التحقق من صحة أفضل نموذج لديك، يمكنك تسجيله في التعلم الآلي من Azure. ثم يمكنك تنزيل النموذج المسجل أو نشره والحصول على جميع الملفات التي سجلتها.
description = 'My automated ML model'
model_path='outputs/model.pkl'
model = best_run.register_model(model_name = 'NYCYellowTaxiModel', model_path = model_path, description = description)
print(model.name, model.version)
NYCYellowTaxiModel 1
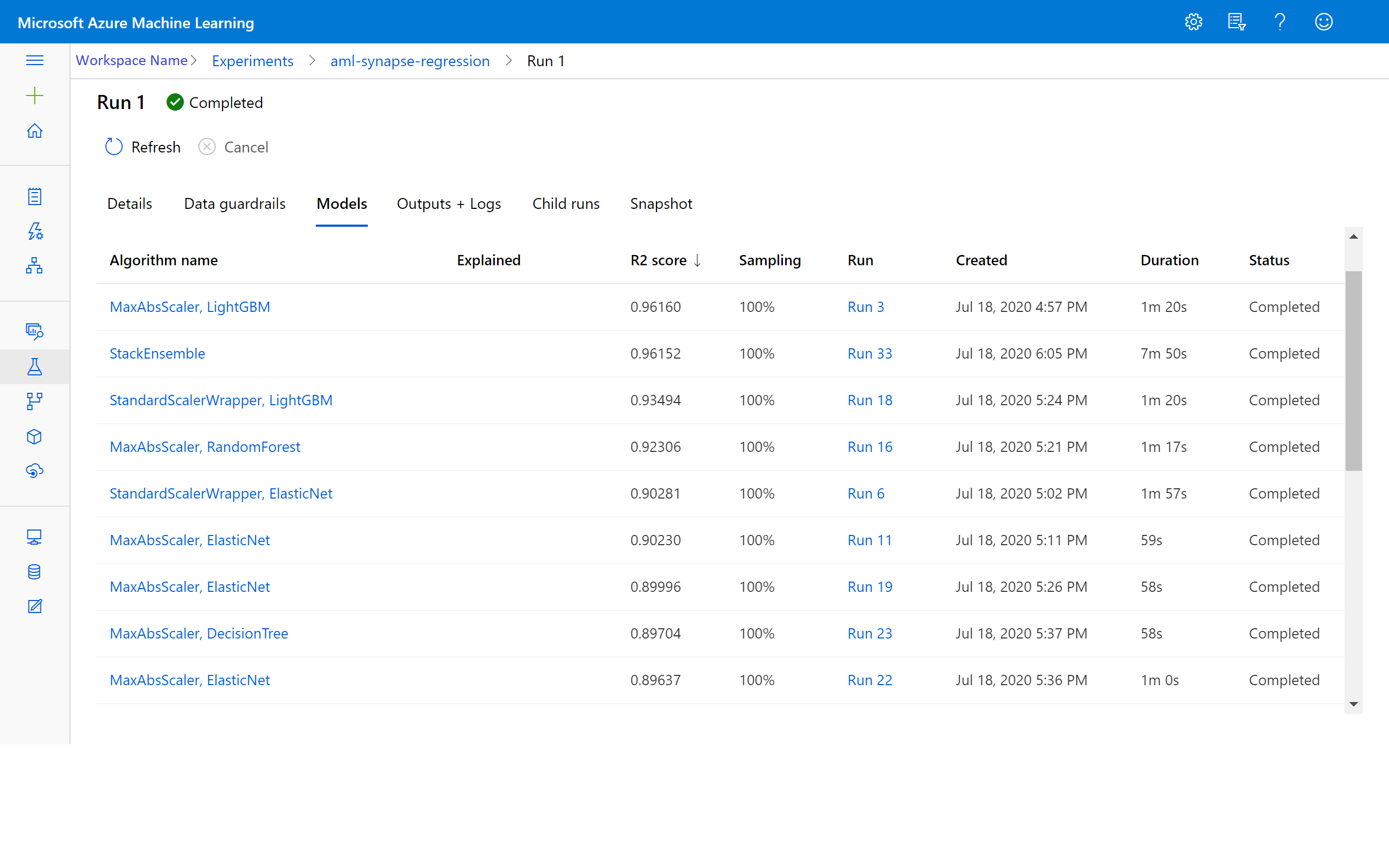
عرض النتائج في التعلم الآلي من Azure
يمكنك أيضاً الوصول إلى نتائج التكرارات من خلال الانتقال إلى التجربة في مساحة عمل التعلم الآلي من Azure. يمكنك هنا الحصول على تفاصيل إضافية حول حالة التشغيل والنماذج التي تمت محاولة استخدامها ومقاييس النماذج الأخرى.