ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
إن Apache Spark عبارة عن إطار عمل لمعالجة متوازٍ يدعم المعالجة داخل الذاكرة لتعزيز أداء تطبيقات تحليل البيانات الضخمة. يعد Apache Spark في Azure Synapse Analytics أحد تطبيقات Microsoft لـ Apache Spark في السحابة. يعمل Azure Synapse على تسهيل إنشاء وتكوين مجموعة Apache Spark بلا خادم في Azure. تتوافق مجموعات Spark في Azure Synapse مع Azure Storage وAzure Data Lake Generation 2 Storage. لذا يمكنك استخدام مجموعات Spark لمعالجة بياناتك المخزنة في Azure.
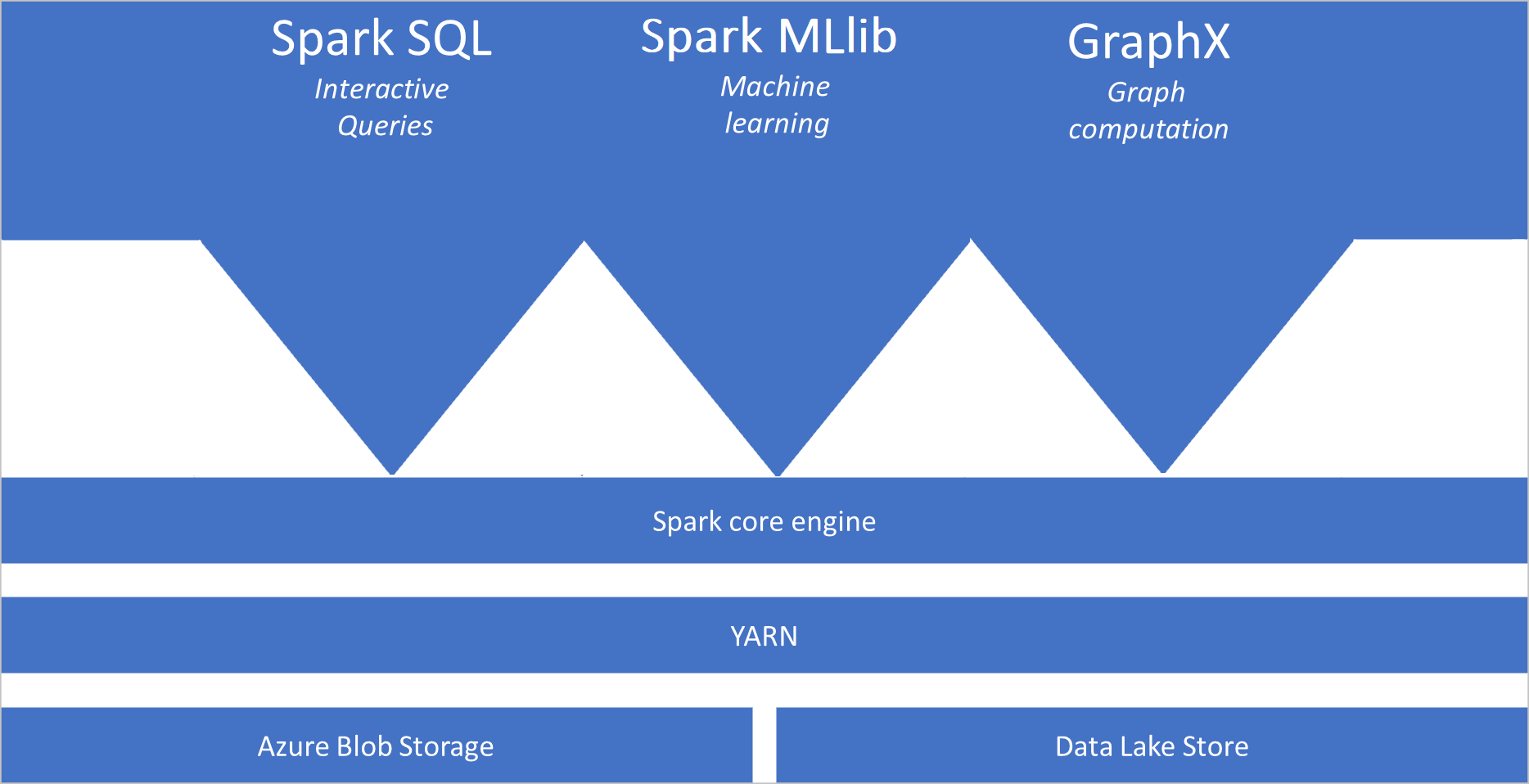
ما هو Apache Spark
يوفر Apache Spark الأساسيات للحوسبة المجمّعة في الذاكرة. يمكن لوظيفة Spark تحميل البيانات وتخزينها في الذاكرة والاستعلام عنها بشكل متكرر. الحوسبة في الذاكرة أسرع من التطبيقات المستندة إلى القرص. يتكامل Spark أيضًا مع لغات برمجة متعددة للسماح لك بمعالجة مجموعات البيانات الموزعة مثل المجموعات المحلية. لا حاجة لهيكلة كل شيء كخريطة وتقليل العمليات. يمكنك معرفة المزيد من فيديو Apache Spark for Synapse.
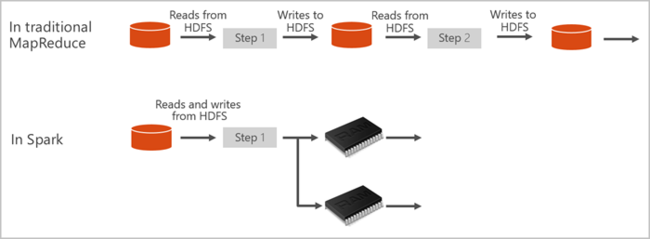
تقدم مجموعات Spark في Azure Synapse خدمة Spark مُدارة بالكامل. يتم عرض مزايا إنشاء مجموعة Spark في Azure Synapse Analytics هنا.
| ميزة | الوصف |
|---|---|
| السرعة والكفاءة | تبدأ مثيلات Spark في دقيقتين تقريبًا لأقل من 60 عقدة و5 دقائق تقريبًا لأكثر من 60 عقدة. يتم إيقاف تشغيل المثيل، بشكل افتراضي، بعد 5 دقائق من تشغيل آخر مهمة ما لم يتم الاحتفاظ بها قيد التشغيل بواسطة اتصال دفتر ملاحظات. |
| سهولة الإنشاء | يمكنك إنشاء وعاء Spark جديد في Azure Synapse في دقائق باستخدام Azure portal أو Azure PowerShell أو Synapse Analytics .NET SDK. راجع بدء استخدام تجمعات Spark في Azure Synapse Analytics. |
| سهولة الاستخدام | يتضمن Synapse Analytics دفتر ملاحظات مخصصًا مشتقًا من Nteract. يمكنك استخدام دفاتر الملاحظات هذه لمعالجة البيانات التفاعلية والتصور. |
| واجهة برمجة تطبيقات REST | يتضمن Spark في Azure Synapse Analytics Apache Livy، وهو خادم مهام Spark قائم على واجهة برمجة تطبيقات REST لإرسال المهام ومراقبتها عن بعد. |
| دعم Azure Data Lake Storage Generation 2 | يمكن لتجمعات Spark في Azure Synapse استخدام الجيل الثاني من Azure Data Lake Storage وتخزين BLOB. لمزيد من المعلومات حول Data Lake Storage، راجع نظرة عامة على Azure Data Lake Storage |
| التكامل مع بيئات التطوير المتكاملة IDE التابعة لجهات خارجية | يوفر Azure Synapse مكونا إضافي ل IDE ل JetBrains'IntelliJ IDEA ، وهو مفيد لإنشاء التطبيقات وإرسالها إلى تجمع Spark. |
| مكتبات Anaconda المحملة مسبقًا | تتوفر مجموعات Spark في Azure Synapse مع مكتبات Anaconda مثبتة مسبقًا. توفر Anaconda ما يقرب من 200 مكتبة للتعلم الآلي وتحليل البيانات والتصور والتقنيات الأخرى. |
| قابلية التوسع | يمكن أن تحتوي Apache Spark في أوعية Synapse Azure على إمكانية تغيير الحجم التلقائي، بحيث يتغير حجم التجمّعات عن طريق إضافة العقد أو إزالتها حسب الحاجة. ويمكن أيضاً إيقاف تجمعات Spark دون فقدان البيانات نظراً لأن جميع البيانات مخزنة في Azure Storage أو Data Lake Storage. |
تتضمن تجمعات Spark في Azure Synapse المكونات التالية المتوفرة في التجمعات افتراضيًا:
- Spark Core. يتضمن Spark Core، وSpark SQL، وGraphX، وMLlib.
- Anaconda
- Apache Livy
- دفتر ملاحظات nteract
بنية Spark pool
تعمل تطبيقات Spark كمجموعات مستقلة من العمليات على مجموعة، يتم تنسيقها بواسطة عنصر SparkContextفي برنامجك الرئيس يسمى برنامج المشغل.
يستطيع SparkContext الاتصال بمدير نظام المجموعة، الذي يخصص الموارد عبر التطبيقات. ويُعد مدير مجموعة النظام هو Apache Hadoop YARN. بمجرد الاتصال، يكتسب Spark منفذين على العُقد في التجمع، وهي عمليات تقوم بتشغيل الحسابات وتخزين البيانات لتطبيقك. بعد ذلك، يرسل التعليمة البرمجية للتطبيق المحدد بواسطة ملفات JAR أو Python التي تم تمريرها إلى SparkContext للمنفذين. وأخيرًا، يرسل SparkContext المهام إلى المنفذين لتشغيلها.
يشغِّل SparkContext الدالة الرئيسة للمستخدم، وينفذ مختلف العمليات المتوازية على العقد. بعد ذلك، يجمع SparkContext نتائج العمليات. ويمكن للعُقد قراءة البيانات وكتابتها من نظام الملفات وإليه. يتم من خلال العُقد أيضًا تخزين البيانات المحولة في الذاكرة مؤقتًا كمجموعات بيانات موزعة مرنة (RDDs).
يتصل SparkContext بمجموعة Spark، وهو مسؤول عن تحويل تطبيق إلى رسم بياني غير دوري موجه (DAG). ويتكون الرسم البياني من المهام الفردية التي تعمل ضمن إحدى عمليات المنفذ على العقد. ويحصل كل تطبيق على عمليات المنفذ الخاصة به، والتي تظل مستمرة أثناء التطبيق بأكمله وتشغيل المهام في سلاسل محادثات متعددة.
Apache Spark في حالات استخدام Azure Synapse Analytics
تعمل مجموعات Spark في Azure Synapse Analytics على تمكين السيناريوهات الرئيسية التالية:
- هندسة البيانات/ تحضير البيانات
يتضمن Apache Spark العديد من ميزات اللغة لدعم إعداد ومعالجة كميات كبيرة من البيانات بحيث يمكن جعلها أكثر قيمة، ثم استهلاكها بواسطة الخدمات الأخرى ضمن Azure Synapse Analytics. يتم تمكين ذلك من خلال لغات متعددة (C# وScala وPySpark وSpark SQL) والمكتبات المتوفرة للمعالجة والاتصال.
- التعلّم الآلي
يأتي Apache Spark مزودا ب MLlib، وهي مكتبة للتعلم الآلي مبنية على Spark يمكنك استخدامها من تجمع Spark في Azure Synapse Analytics. تتضمن تجمعات Spark في Azure Synapse Analytics أيضًا Anaconda، وهو توزيع Python مع حزم مختلفة لعلوم البيانات بما في ذلك التعلم الآلي. وعند جمعها مع الدعم المضمن لدفاتر الملاحظات يكون لديك بيئة لإنشاء تطبيقات التعلم الآلي.
- دفق البيانات
يدعم Synapse Spark الدفق المنظم ل Spark طالما أنك تقوم بتشغيل إصدار مدعوم من إصدار وقت تشغيل Azure Synapse Spark. يتم دعم جميع الوظائف للعيش لمدة سبعة أيام. ينطبق هذا على كل من مهام الدفعات والتدفق، وبشكل عام، يقوم العملاء بأتمتة عملية إعادة التشغيل باستخدام Azure Functions.
المحتوى ذو الصلة
استخدم المقالات التالية لمعرفة المزيد حول Apache Spark في Azure Synapse Analytics:
- التشغيل السريع: إنشاء تجمع Spark في Azure Synapse
- التشغيل السريع: إنشاء دفتر ملاحظات Apache Spark
- البرنامج التعليمي: التعلم الآلي باستخدام Apache Spark
إشعار
تعتمد بعض وثائق Apache Spark الرسمية على استخدام وحدة تحكم Spark، والتي لا تتوفر على Azure Synapse Spark. استخدم دفتر الملاحظات أو تجارب IntelliJ بدلاً من ذلك.