إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: ✔️ أجهزة ظاهرية بنظام التشغيل Linux ✔️ أجهزة ظاهرية بنظام التشغيل Windows ✔️ مجموعات التوسعة المرنة ✔️ مجموعات التوسعة الموحدة
واجهة تمرير الرسائل (MPI) هي مكتبة مفتوحة وقياس defacto لتوازي الذاكرة الموزعة. يتم استخدامه بشكل شائع عبر العديد من أحمال عمل HPC. يمكن لأحمال عمل HPC على الأجهزة الظاهرية المزودة بسلسلة HB والسلسلة N من RDMAاستخدام MPI للاتصال عبر زمن الانتقال المنخفض والنطاق الترددي العالي لشبكة InfiniBand.
- تسمح أحجام الأجهزة الظاهرية التي تدعم SR-IOV في Azure باستخدام أي نوع من MPI تقريباً مع Mellanox OFED.
- في الأجهزة الظاهرية التي لا تدعم SR-IOV، تستخدم تطبيقات MPI المعتمدة واجهة Microsoft Network Direct (ND) للاتصال بين الأجهزة الظاهرية. وبالتالي، يتم دعم إصدارات واجهة Microsoft MPI (MS-MPI) 2012 R2 أو الإصدارات الأحدث منها وواجهة Intel MPI 5.x فقط. الإصدارات الأخيرة (2017، 2018) من مكتبة التعليمات الإصدار لوقت تشغيل Intel MPI قد تكون أو لا تكون متوافقة مع برامج تشغيل Azure RDMA.
بالنسبة للأجهزة الظاهرية المزودة بإمكانية SR-IOV ل RDMA، تكون صور الجهاز الظاهري Ubuntu-HPC وصور الجهاز الظاهري AlmaLinux-HPC مناسبة. تأتي صور الجهاز الظاهري هذه محسنة ومحملة مسبقا مع برامج تشغيل OFED ل RDMA والعديد من مكتبات MPI شائعة الاستخدام وحزم الحوسبة العلمية وهي أسهل طريقة للبدء.
على الرغم من أن الأمثلة هنا هي ل RHEL، ولكن الخطوات عامة ويمكن استخدامها لأي نظام تشغيل Linux متوافق مثل Ubuntu (18.04 و20.04 و22.04) وSLES (12 SP4 و15 SP4). يتوفر مزيد من الأمثلة لإعداد تطبيقات MPI الأخرى على توزيعات أخرى على مستودع azhpc-images.
إشعار
تشغيل مهام واجهة MPI على الأجهزة الظاهرية التي تدعم SR-IOV مع مكتبات التعليمات البرمجية لواجهة MPI معينة (مثل Platform MPI) قد يتطلب إعداد مفاتيح الأقسام (p-keys) عبر مستأجر للعزل والأمان. اتبع الخطوات الموجودة في قسم اكتشاف مفاتيح الأقسام للحصول على تفاصيل حول تحديد قيم المفتاح p-key وتعيينها تعييناً صحيحاً يناسب مهمة واجهة MPI باستخدام مكتبة التعليمات البرمجية لواجهة MPI تلك.
إشعار
القصاصات البرمجية أدناه أمثلة. نوصي باستخدام أحدث الإصدارات المستقرة من الحزم، أو الرجوع إلى مستودع azhpc-images.
اختيار مكتبة التعليمات البرمجية لواجهة MPI
إذا أوصى أحد تطبيقات HPC بمكتبة MPI معينة، فجرب هذا الإصدار أولاً. إذا كان لديك المرونة فيما يتعلق بواجهة MPI التي يمكنك اختيارها، وترغب في الأداء الأفضل، جرب HPC-X. تقدم واجهة HPC-X MPI أفضل أداء عن طريق استخدام إطار عمل UCX لواجهة InfiniBand، وتستفاد من جميع قدرات برامج Mellanox InfiniBand وأجهزتها. بالإضافة إلى ذلك، HPCX وOpenMPI متوافقان مع ABI، لذا يمكنك تشغيل تطبيق الحوسبة عالية الأداء ديناميكياً باستخدام HPC-X الذي تم إنشاؤه باستخدام OpenMPI. وبالمثل، فإن Intel MPI وMVAPICH وMPICH متوافقة مع ABI.
يوضح الشكل التالي بنية مكتبات التعليمات البرمجية لواجهة MPI الشهيرة.
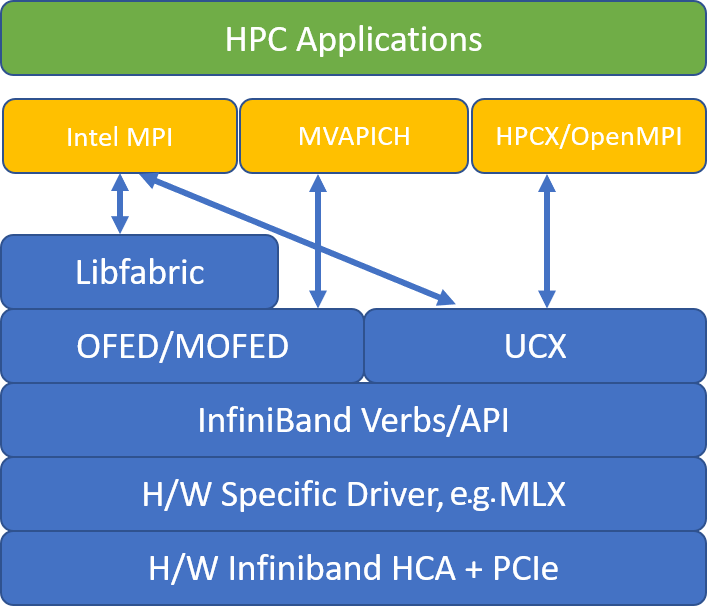
HPC-X
تحتوي مجموعة أدوات برنامج HPC-X على UCX وHCOLL ويمكن تأسيسها مقابل UCX.
HPCX_VERSION="v2.6.0"
HPCX_DOWNLOAD_URL=https://azhpcstor.blob.core.windows.net/azhpc-images-store/hpcx-v2.6.0-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
wget --retry-connrefused --tries=3 --waitretry=5 $HPCX_DOWNLOAD_URL
tar -xvf hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
mv hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64 ${INSTALL_PREFIX}
HPCX_PATH=${INSTALL_PREFIX}/hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64
يوضح أمر التشغيل التالي بعض وسيطات mpirun الموصى بها لـ HPC-X وOpenMPI.
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
الموقع:
| المعلمة | الوصف |
|---|---|
NPROCS |
تحديد عدد عمليات MPI. على سبيل المثال: -n 16. |
$HOSTFILE |
تحديد ملف يحتوي على اسم المضيف أو عنوان IP، للإشارة إلى موقع مكان تشغيل عمليات MPI. على سبيل المثال: --hostfile hosts. |
$NUMBER_PROCESSES_PER_NUMA |
تحديد عدد عمليات MPI التي تعمل في كل مجال NUMA. على سبيل المثال، لتحديد أربع عمليات MPI لكل NUMA، يمكنك استخدام --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
تحديد عدد مؤشرات الترابط لكل عملية MPI. على سبيل المثال، لتحديد عملية MPI واحدة وأربعة مؤشرات ترابط لكل NUMA، يمكنك استخدام --map-by ppr:1:numa:pe=4. |
-report-bindings |
تقوم عمليات طباعة MPI بمعالجة التعيين إلى الذاكرات الأساسية، وهو أمر مفيد للتحقق من صحة تثبيت عملية MPI. |
$MPI_EXECUTABLE |
تحديد MPI التنفيذي الذي تم إنشاؤه في مكتبات MPI. تقوم برامج تضمين المحول البرمجي MPI بذلك تلقائيًا. على سبيل المثال: mpicc أو mpif90. |
مثال على تشغيل المعيار الجزئي لزمن انتقال OSU هو كما يلي:
${HPCX_PATH}mpirun -np 2 --map-by ppr:2:node -x UCX_TLS=rc ${HPCX_PATH}/ompi/tests/osu-micro-benchmarks-5.3.2/osu_latency
تحسين مجموعات MPI
توفر أساسيات الاتصال الجماعي لواجهة MPI طريقة مرنة ومحمولة لتنفيذ عمليات الاتصال الجماعي. يتم استخدامها على نطاق واسع عبر تطبيقات علمية متوازية مختلفة، كما لها تأثير كبير على أداء التطبيق العام. راجع مقالة TechCommunity للحصول على تفاصيل حول معلمات التكوين لتحسين أداء الاتصال الجماعي باستخدام مكتبة التعليمات البرمجية HPC-X وHCOLL للاتصال الجماعي.
على سبيل المثال، إذا كنت تشك أن تطبيق MPI المقترن بإحكام يقوم بقدر مفرط من الاتصال الجماعي، يمكنك محاولة تمكين المجموعات الهرمية (HCOLL). لتمكين هذه الميزات، استخدم المعلمات التالية.
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
إشعار
من خلال HPC-X 2.7.4+، قد يكون من الضروري تمرير LD_LIBRARY_PATH مباشرة إذا كان إصدار UCX على MOFED مختلفاً عن نظيره الإصدار HPC-X.
OpenMPI
ثبت UCX كما هو موضح أعلاه. HCOLL هو جزء من مجموعة أدوات برامج HPC-X ولا يتطلب تثبيتا خاصا.
يمكن تثبيت OpenMPI من الحزم المتوفرة في المستودع.
sudo yum install –y openmpi
نوصي بإنشاء أحدث إصدار مستقر من OpenMPI باستخدام UCX.
OMPI_VERSION="4.0.3"
OMPI_DOWNLOAD_URL=https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-${OMPI_VERSION}.tar.gz
wget --retry-connrefused --tries=3 --waitretry=5 $OMPI_DOWNLOAD_URL
tar -xvf openmpi-${OMPI_VERSION}.tar.gz
cd openmpi-${OMPI_VERSION}
./configure --prefix=${INSTALL_PREFIX}/openmpi-${OMPI_VERSION} --with-ucx=${UCX_PATH} --with-hcoll=${HCOLL_PATH} --enable-mpirun-prefix-by-default --with-platform=contrib/platform/mellanox/optimized && make -j$(nproc) && make install
للحصول على الأداء الأمثل، قم بتشغيل OpenMPI باستخدام ucx و hcoll. راجع أيضاً المثال الخاص بحوسبة HPC-X.
${INSTALL_PREFIX}/bin/mpirun -np 2 --map-by node --hostfile ~/hostfile -mca pml ucx --mca btl ^vader,tcp,openib -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_IB_PKEY=0x0003 ./osu_latency
تحقق من مفتاح القسم الخاص بك كما هو مذكور أعلاه.
إنتل MPI
قم بتنزيل الإصدار الذي تختاره من Intel MPI. يحول إصدار Intel MPI 2019 من إطار Open Fabrics Alliance (OFA) إلى إطار Open Fabrics Interfaces (OFI)، ويدعم حاليًا libfabric. هناك نوعان من مقدمي دعم InfiniBand، هما mlx وverbs. عدّل متغير بيئة I_MPI_FABRICS وفقاً للإصدار.
- Intel MPI 2019 و2021: استخدم
I_MPI_FABRICS=shm:ofi،I_MPI_OFI_PROVIDER=mlx. الموفرmlxيستخدم UCX. وقد وُجد أن استخدام الأفعال غير مستقر ويتمتع بأداء أقل. راجع مقالة TechCommunity لمزيد من التفاصيل. - Intel MPI 2018: استخدم
I_MPI_FABRICS=shm:ofa - Intel MPI 2016: استخدم
I_MPI_DAPL_PROVIDER=ofa-v2-ib0
فيما يلي بعض وسائط mpirun المقترحة لتحديث Intel MPI 2019 5+.
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
الموقع:
| المعلمة | الوصف |
|---|---|
FI_PROVIDER |
يحدد موفر libfabric المراد استخدامه، والذي سيؤثر على واجهة برمجة التطبيقات والبروتوكول والشبكة المستخدمة. تُعد الأفعال خيارًا آخر، ولكن بشكل عام، يمنحك mlx أداء أفضل. |
I_MPI_DEBUG |
يحدد مستوى إخراج التصحيح الإضافي، والذي يمكن أن يوفر تفاصيل حول مكان تثبيت العمليات والبروتوكول والشبكة المستخدمة. |
I_MPI_PIN_DOMAIN |
تحديد الطريقة التي تريد تثبيت العمليات بها. على سبيل المثال، يمكنك تثبيت مراكز المعالجات أو مآخذ التوصيل أو مجالات NUMA. في هذا المثال، قمت بتعيين هذا المتغير البيئي على numa، ما يعني أنه سيتم تثبيت العمليات في مجالات عقدة NUMA. |
تحسين مجموعات MPI
هناك بعض الخيارات الأخرى التي يمكنك تجربتها، خاصةً إذا كانت العمليات الجماعية تستغرق وقتًا طويلاً. يدعم تحديث Intel MPI 2019 5+ توفير mlx ويستخدم إطار UCX للتواصل مع InfiniBand. كما أنه يدعم HCOLL.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
الأجهزة الظاهرية التي لا تدعم SR-IOV
بالنسبة للأجهزة الظاهرية التي لا تدعم SR-IOV، فيما يلي مثال على تنزيل إصدار التقييم المجاني لوقت التشغيل 5.x:
wget http://registrationcenter-download.intel.com/akdlm/irc_nas/tec/9278/l_mpi_p_5.1.3.223.tgz
للحصول على خطوات التثبيت، راجع دليل تثبيت مكتبة التعليمات البرمجية Intel MPI. اختيارياً، قد ترغب في تمكين ptrace لعمليات ليس لها صلة بالجذر ومصحح الأخطاء (اللازمة لأحدث إصدارات Intel MPI).
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
SUSE Linux
بالنسبة لإصدارات صور الجهاز الظاهري لتوزيعة خادم نظام SUSE Linux Enterprise Server - SLES 12 SP3 مخصص لـ HPC، وSLES 12 SP3 مخصص لـ HPC (Premium)، وSLES 12 SP1 مخصص لـ HPC، وSLES 12 SP1 مخصص لـ HPC (Premium)، وSLES 12 SP4 وSLES 15، ويتم تثبيت برامج تشغيل RDMA بينما يتم نشر حزم Intel MPI في الجهاز الظاهري. ثبت Intel MPI عن طريق تشغيل الأمر التالي:
sudo rpm -v -i --nodeps /opt/intelMPI/intel_mpi_packages/*.rpm
MVAPICH
فيما يلي مثال على إنشاء MVAPICH2. ملاحظة قد تتوفر إصدارات أحدث من الإصدار المستخدم أدناه.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/mv2/mvapich2-2.3.tar.gz
tar -xv mvapich2-2.3.tar.gz
cd mvapich2-2.3
./configure --prefix=${INSTALL_PREFIX}
make -j 8 && make install
مثال على تشغيل المعيار الجزئي لزمن انتقال OSU هو كما يلي:
${INSTALL_PREFIX}/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=48 ./osu_latency
تحتوي القائمة التالية على عدة وسيطات موصى بها mpirun .
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
الموقع:
| المعلمة | الوصف |
|---|---|
MV2_CPU_BINDING_POLICY |
يحدد نهج الربط الذي يجب استخدامه، والذي ستؤثر على كيفية تثبيت العمليات بمعرفات ذاكرات أساسية. في هذه الحالة، يمكنك تحديد scatter، لذلك يتم تشتت العمليات بالتساوي بين مجالات NUMA. |
MV2_CPU_BINDING_LEVEL |
تحديد مكان تثبيت العمليات. في هذه الحالة، يمكنك تعيينها على numanode، مما يعني أن العمليات مثبتة على وحدات مجالات NUMA. |
MV2_SHOW_CPU_BINDING |
تحديد ما إذا كنت تريد الحصول على معلومات تصحيح الأخطاء حول مكان تثبيت العمليات. |
MV2_SHOW_HCA_BINDING |
تحديد ما إذا كنت ترغب في الحصول على معلومات التصحيح حول محول القناة المضيفة الذي تستخدمه كل عملية. |
منصة MPI
ثبت الحزم المطلوبة لإصدار مجتمع Platform MPI Community Edition.
sudo yum install libstdc++.i686
sudo yum install glibc.i686
Download platform MPI at https://www.ibm.com/developerworks/downloads/im/mpi/index.html
sudo ./platform_mpi-09.01.04.03r-ce.bin
اتبع عملية التثبيت.
MPICH
ثبت UCX كما هو موضح أعلاه. أنشئ MPICH.
wget https://www.mpich.org/static/downloads/3.3/mpich-3.3.tar.gz
tar -xvf mpich-3.3.tar.gz
cd mpich-3.3
./configure --with-ucx=${UCX_PATH} --prefix=${INSTALL_PREFIX} --with-device=ch4:ucx
make -j 8 && make install
شغّل MPICH.
${INSTALL_PREFIX}/bin/mpiexec -n 2 -hostfile ~/hostfile -env UCX_IB_PKEY=0x0003 -bind-to hwthread ./osu_latency
تحقق من مفتاح القسم الخاص بك كما هو مذكور أعلاه.
معايير OSU MPI
تنزيل معايير OSU MPI وuntar.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.5.tar.gz
tar –xvf osu-micro-benchmarks-5.5.tar.gz
cd osu-micro-benchmarks-5.5
أنشئ المعايير باستخدام مكتبة تعليمات برمجية MPI معينة:
CC=<mpi-install-path/bin/mpicc>CXX=<mpi-install-path/bin/mpicxx> ./configure
make
توجد معايير MPI ضمن المجلد mpi/.
اكتشف مفاتيح الأقسام
اكتشف مفاتيح الأقسام (p-keys) للاتصال بالأجهزة الظاهرية الأخرى داخل المستأجر نفسه (مجموعة التوافر أو مجموعة توسعة الجهاز الظاهري).
/sys/class/infiniband/mlx5_0/ports/1/pkeys/0
/sys/class/infiniband/mlx5_0/ports/1/pkeys/1
يتمثل المفتاح الأكبر من الاثنين في مفتاح المستأجر الذي يجب استخدامه مع MPI. مثال: إذا كانت ما يلي هي p-keys، فيجب استخدام 0x800b مع MPI.
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/0
0x800b
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/1
0x7fff
تتم تسمية واجهات الملاحظات على أنها mlx5_ib* داخل صور HPC VM.
لاحظ أيضاً أنه طالما أن المستأجر (مجموعة التوافر أو مجموعة توسعة الجهاز الظاهري) موجود، تظل PKEYs كما هي. هذا صحيح حتى عند إضافة/حذف العقد. يحصل المستأجرون الجدد على PKEYs مختلفة.
قم بإعداد حدود مستخدم واجهة MPI
قم بإعداد حدود مستخدم واجهة MPI.
cat << EOF | sudo tee -a /etc/security/limits.conf
* hard memlock unlimited
* soft memlock unlimited
* hard nofile 65535
* soft nofile 65535
EOF
قم بإعداد مفاتيح SSH المخصصة لواجهة MPI
قم بإعداد مفاتيح SSH لأنواع واجهة MPI التي تتطلب ذلك.
ssh-keygen -f /home/$USER/.ssh/id_rsa -t rsa -N ''
cat << EOF > /home/$USER/.ssh/config
Host *
StrictHostKeyChecking no
EOF
cat /home/$USER/.ssh/id_rsa.pub >> /home/$USER/.ssh/authorized_keys
chmod 600 /home/$USER/.ssh/authorized_keys
chmod 644 /home/$USER/.ssh/config
يفترض بناء الجملة أعلاه دليلا منزليا مشتركا، ويجب نسخ الدليل الآخر .ssh إلى كل عقدة.
الخطوات التالية
- تعرف على الأجهزة الظاهرية لسلسلة HB وسلسلةN الممكنة من InfiniBand.
- راجع نظرة عامة على سلسلة HBv3 ونظرة عامة على سلسلة HC.
- اقرأ موضع عملية MPI المثلى للأجهزة الظاهرية من سلسلة HB.
- اقرأ بشأن أحدث الإعلانات، والأمثلة حول حمل عمل الحوسبة عالية الأداء (HPC)، ونتائج الأداء في مدوّنات المجتمع التقني حول الحساب في Azure.
- من أجل عرض هندسي ذي مستوى أعلى لتشغيل أحمال عمل الحوسبة عالية الأداء (HPC)، راجع الحوسبة عالية الأداء (HPC) على Azure.