Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Azure Managed Instance for Apache Cassandra is a fully managed service for pure open-source Apache Cassandra clusters. The service also allows configurations to be overridden, depending on the specific needs of each workload, which allows maximum flexibility and control where needed.
This article defines the management operations and features provided by the service. It also explains the separation of responsibilities between the Azure support team and customers when maintaining hybrid clusters.
Compaction
There are different types of compaction. This service currently performs a minor compaction by using repair, For more information, see Maintenance. This operation performs a Merkle tree compaction, which is a special kind of compaction.
Depending on the compaction strategy that was set on the table using CQL, for example
WITH compaction = { 'class' : 'LeveledCompactionStrategy' }, Cassandra automatically compacts when the table reaches a specific size. We recommend that you carefully select a compaction strategy for your workload. Don't do any manual compactions outside the strategy.
Patching
Operating System-level patches are done automatically at two week cadence.
Apache Cassandra software-level patches are done when security vulnerabilities are identified. The patching cadence might vary.
During patching, machines are rebooted one rack at a time. You shouldn't experience any degradation at the application side as long as quorum ALL setting isn't being used, and the replication factor is 3 or higher.
The version in Apache Cassandra is in the format
X.Y.Z. You can control the deployment of major (X) and minor (Y) versions manually by using service tools. The Cassandra patches (Z) that might be required for that major/minor version combination are done automatically.
Note
The service currently supports Cassandra versions till 5.0. To specify a Cassandra version when you deploy a cluster, see Azure CLI Quickstart.
Maintenance
The service runs nodetool repair using reaper. This tool is run once every week. If you use your own service for a hybrid deployment, you might want to disable reaper.
Node health monitoring consists of:
- Actively monitoring each node's membership in the Cassandra ring.
- Autodetecting and automitigating infrastructure issues like virtual machine, network, storage, Linux, and support software failures.
- Pro-actively monitoring CPU, disk, quorum loss, and other resource issues.
- Automatically bringing up failed nodes where possible, and manually bringing up nodes in response to autogenerated warnings.
Support
Azure Managed Instance for Apache Cassandra provides an SLA for the availability of data centers in a managed cluster. If you encounter any issues with using the service, file a support request in the Azure portal.
Our support benefits include:
- Single point of contact for Cassandra infrastructure issues. No need to raise support cases with IaaS teams like disk, compute, and networking separately.
- Pro-active advice by email on performance bottle necks, sizing, and other resource constraint issues.
- 24x7 support coverage, including autogenerated incidents for any severe outage issues.
- Community approved patch support. See Patching.
- In-house Java JDK/JVM engineering team support.
- Linux Operating System support with software supply chain security.
Important
Microsoft investigates and diagnoses any issues reported by using support case. Support resolves or mitigates where possible. You're ultimately responsible for any Apache Cassandra configuration level usage which causes CPU, disk, or network problems.
Examples of such issues include:
- Inefficient query operations.
- Throughput that exceeds capacity.
- Ingesting data that exceeds storage capacity.
- Incorrect keyspace configuration settings.
- Poor data model or partition key strategy.
Microsoft might investigate a support case and discover that the cause of the issue is at the Apache Cassandra configuration level. Such an issue doesn't come from any underlying platform level aspects that Azure maintains. Support still provides recommendations and guidance on remediation, or mitigation when possible, before they close the case.
We recommend that you enable metrics and become familiar with our Azure monitor integration to prevent common application/configuration level issues in Apache Cassandra, such as previously described.
Warning
Azure Managed Instance for Apache Cassandra also lets's you run nodetool and sstable commands for routine DBA administration. For more information, see DBA commands for Azure Managed Instance for Apache Cassandra.
Some of these commands can destabilize the Cassandra cluster. You should run these commands carefully and after being tested in nonproduction environments. Where possible, use a --dry-run option first. Microsoft doesn't offer any SLA or support on issues with running commands which alter the default database configuration or tables.
Backup and restore
Snapshot backups are enabled by default and taken every 24 hours. Backups are stored in an internal Azure Blob Storage account and are retained for up to two days (48 hours). There's no cost for the initial two backups. Extra backups are charged. See pricing. To change the backup interval or retention period, you can edit the policy in the Azure portal:

To restore from an existing backup, file a support request in the Azure portal. When you file a support case, you need to:
Provide the backup ID from portal for the backup you want to restore. You can find this ID in the Azure portal:
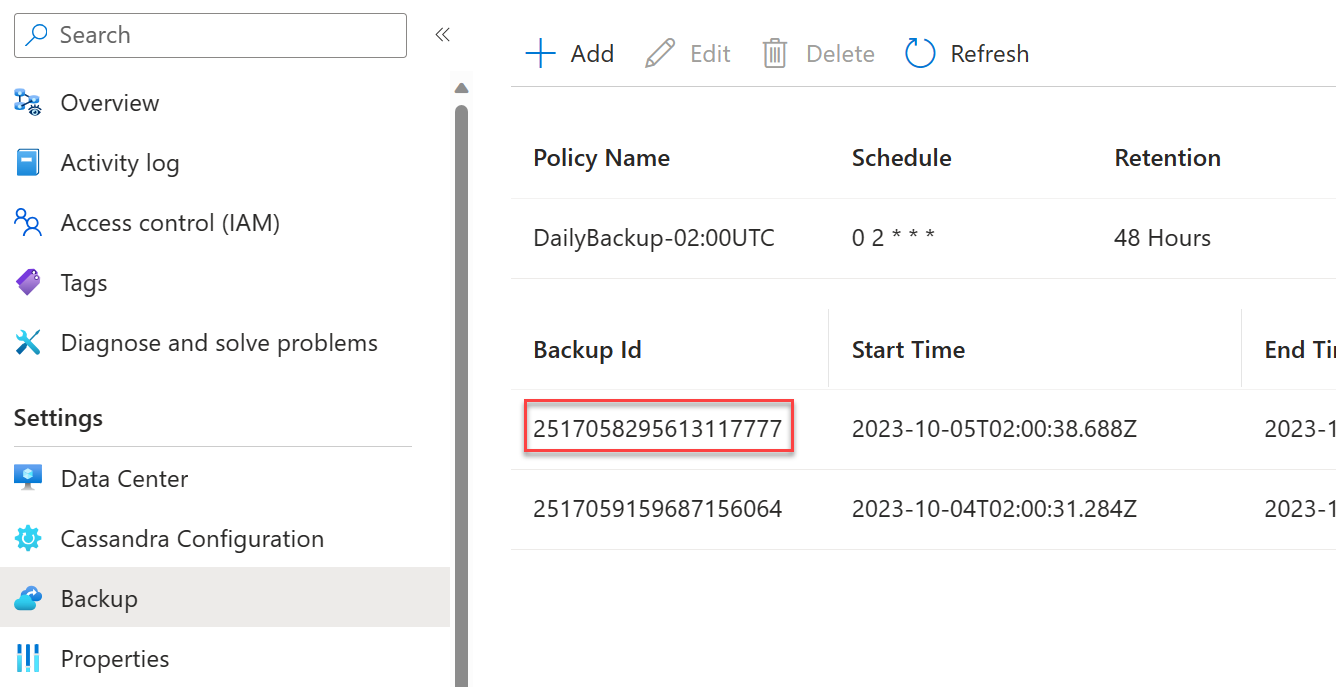
Let us know if the source datacenter was deleted. This fact is important to identify the correct backup account to restore from.
If you don't need to restore the whole cluster, provide the keyspace and table, if applicable, that needs to be restored.
Advise whether you want the backup to be restored in the existing cluster, or in a new cluster.
If you want to restore to a new cluster, you need to create the new cluster first. Ensure that the target cluster matches the source cluster in terms of the number of data centers. Verify that the corresponding data center has the same number of nodes. You can also decide whether to keep the credentials in the new target cluster. Alternatively, allow restore to override the username and password with what was originally created.
You can also decide whether to keep
system_authkeyspace in the new target cluster or allow the restore to overwrite it with data from the backup. Thesystem_authkeyspace in Cassandra contains authorization and internal authentication data, including roles, role permissions, and passwords. The default restore process overwrites thesystem_authkeyspace.
Note
The time it takes to respond to a request to restore from backup depends on the severity of support case you raise, the SLA for response time, and the amount of data to restore. We don't provide an SLA for time to complete the restore. That value is time dependent on the volume of data being restored.
Warning
Backups are intended for accidental deletion scenarios, and aren't geo-redundant. We don't recommend backups for use as a disaster recovery (DR) strategy for regional outage. To safeguard against region-wide outages, we recommend a multiple region deployment. For more information, see quickstart for multi-region deployments.
Security
Azure Managed Instance for Apache Cassandra provides many built-in explicit security controls and features:
- Hardened Linux virtual machine images with a controlled supply chain.
- Common Vulnerability & Exposure (CVE) monitoring at the operating system level.
- Certificate rotation for both Apache Cassandra and Prometheus software hosted on the managed Virtual Machines.
- Active vulnerability scanning.
- Active virus scanning.
- Secure coding practices.
For more information on security features, see Security in Azure Managed Instance for Apache Cassandra.
Hybrid support
When a hybrid cluster is configured, automated reaper operations that run in the service benefit the whole cluster. This aspect includes data centers that aren't provisioned by the service. It is your responsibility to maintain your on-premises or externally hosted data center.