Fault tolerance of copy activity in Azure Data Factory and Synapse Analytics pipelines
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
When you copy data from source to destination store, the copy activity provides certain level of fault tolerances to prevent interruption from failures in the middle of data movement. For example, you are copying millions of rows from source to destination store, where a primary key has been created in the destination database, but source database does not have any primary keys defined. When you happen to copy duplicated rows from source to the destination, you will hit the PK violation failure on the destination database. At this moment, copy activity offers you two ways to handle such errors:
- You can abort the copy activity once any failure is encountered.
- You can continue to copy the rest by enabling fault tolerance to skip the incompatible data. For example, skip the duplicated row in this case. In addition, you can log the skipped data by enabling session log within copy activity. You can refer to session log in copy activity for more details.
Copying binary files
The service supports the following fault tolerance scenarios when copying binary files. You can choose to abort the copy activity or continue to copy the rest in the following scenarios:
- The files to be copied by the service are being deleted by other applications at the same time.
- Some particular folders or files do not allow the service access because ACLs of those files or folders require higher permission level than the configured connection information.
- One or more files are not verified to be consistent between source and destination store if you enable data consistency verification setting.
Enable fault tolerance with UI
To configure fault tolerance in a Copy activity in a pipeline with UI, complete the following steps:
If you did not create a Copy activity for your pipeline already, search for Copy in the pipeline Activities pane, and drag a Copy Data activity to the pipeline canvas.
Select the new Copy Data activity on the canvas if it is not already selected, and its Settings tab, to configure fault tolerance.
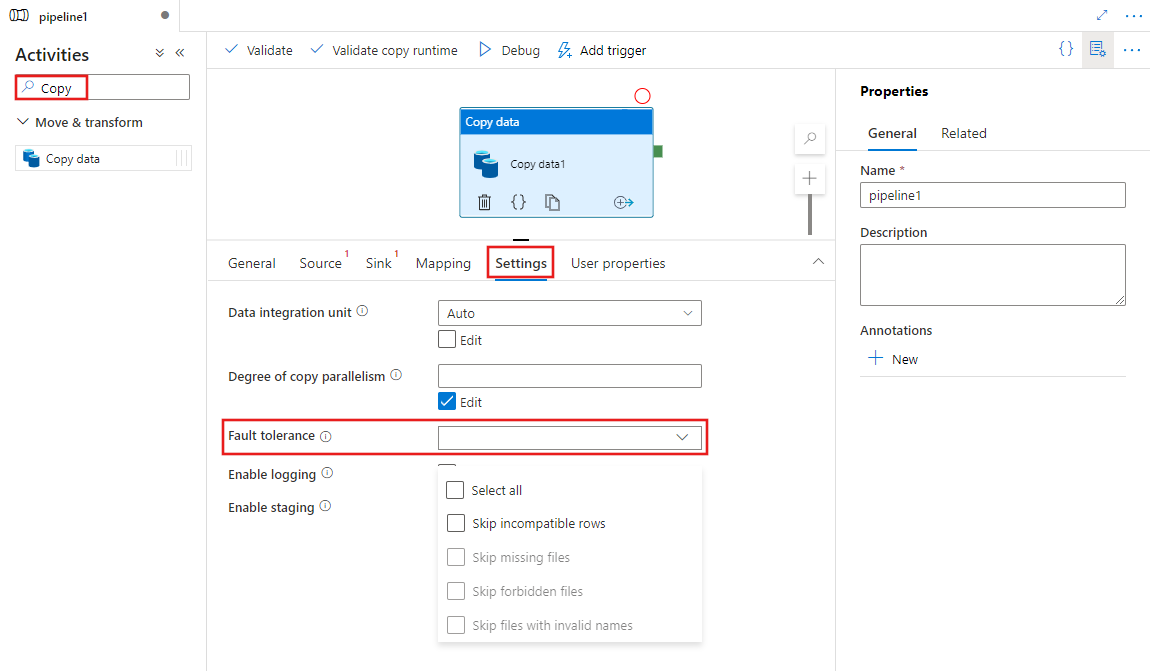
Configuration
When you copy binary files between storage stores, you can enable fault tolerance as followings:
{
"name": "CopyActivityFaultTolerance",
"type": "Copy",
"typeProperties": {
"source": {
"type": "BinarySource",
"storeSettings": {
"type": "AzureDataLakeStoreReadSettings",
"recursive": true
}
},
"sink": {
"type": "BinarySink",
"storeSettings": {
"type": "AzureDataLakeStoreWriteSettings"
}
},
"skipErrorFile": {
"fileMissing": true,
"fileForbidden": true,
"dataInconsistency": true,
"invalidFileName": true
},
"validateDataConsistency": true,
"logSettings": {
"enableCopyActivityLog": true,
"copyActivityLogSettings": {
"logLevel": "Warning",
"enableReliableLogging": false
},
"logLocationSettings": {
"linkedServiceName": {
"referenceName": "ADLSGen2",
"type": "LinkedServiceReference"
},
"path": "sessionlog/"
}
}
}
}
| Property | Description | Allowed values | Required |
|---|---|---|---|
| skipErrorFile | A group of properties to specify the types of failures you want to skip during the data movement. | No | |
| fileMissing | One of the key-value pairs within skipErrorFile property bag to determine if you want to skip files that are being deleted by other applications at the time the service is performing the copy operation. -True: you want to copy the rest by skipping the files being deleted by other applications. - False: you want to abort the copy activity once any files are being deleted from source store in the middle of data movement. Be aware this property is set to true as default. |
True(default) False |
No |
| fileForbidden | One of the key-value pairs within skipErrorFile property bag to determine if you want to skip the particular files, when the ACLs of those files or folders require higher permission level than the configured connection. -True: you want to copy the rest by skipping the files. - False: you want to abort the copy activity once getting the permission issue on folders or files. |
True False(default) |
No |
| dataInconsistency | One of the key-value pairs within skipErrorFile property bag to determine if you want to skip the inconsistent data between source and destination store. -True: you want to copy the rest by skipping inconsistent data. - False: you want to abort the copy activity once inconsistent data found. Be aware this property is only valid when you set validateDataConsistency as True. |
True False(default) |
No |
| invalidFileName | One of the key-value pairs within skipErrorFile property bag to determine if you want to skip the particular files, when the file names are invalid for the destination store. -True: you want to copy the rest by skipping the files having invalid file names. - False: you want to abort the copy activity once any files have invalid file names. Be aware this property works when copying binary files from any storage store to ADLS Gen2 or copying binary files from AWS S3 to any storage store only. |
True False(default) |
No |
| logSettings | A group of properties that can be specified when you want to log the skipped object names. | No | |
| linkedServiceName | The linked service of Azure Blob Storage or Azure Data Lake Storage Gen2 to store the session log files. | The names of an AzureBlobStorage or AzureBlobFS type linked service, which refers to the instance that you use to store the log file. |
No |
| path | The path of the log files. | Specify the path that you use to store the log files. If you do not provide a path, the service creates a container for you. | No |
Note
The followings are the prerequisites of enabling fault tolerance in copy activity when copying binary files. For skipping particular files when they are being deleted from source store:
- The source dataset and sink dataset have to be binary format, and the compression type cannot be specified.
- The supported data store types are Azure Blob storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, SFTP, Amazon S3, Google Cloud Storage and HDFS.
- Only if when you specify multiple files in source dataset, which can be a folder, wildcard or a list of files, copy activity can skip the particular error files. If a single file is specified in source dataset to be copied to the destination, copy activity will fail if any error occurred.
For skipping particular files when their access are forbidden from source store:
- The source dataset and sink dataset have to be binary format, and the compression type cannot be specified.
- The supported data store types are Azure Blob storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, SFTP, Amazon S3 and HDFS.
- Only if when you specify multiple files in source dataset, which can be a folder, wildcard or a list of files, copy activity can skip the particular error files. If a single file is specified in source dataset to be copied to the destination, copy activity will fail if any error occurred.
For skipping particular files when they are verified to be inconsistent between source and destination store:
- You can get more details from data consistency doc here.
Monitoring
Output from copy activity
You can get the number of files being read, written, and skipped via the output of each copy activity run.
"output": {
"dataRead": 695,
"dataWritten": 186,
"filesRead": 3,
"filesWritten": 1,
"filesSkipped": 2,
"throughput": 297,
"logFilePath": "myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"dataConsistencyVerification":
{
"VerificationResult": "Verified",
"InconsistentData": "Skipped"
}
}
Session log from copy activity
If you configure to log the skipped file names, you can find the log file from this path: https://[your-blob-account].blob.core.windows.net/[path-if-configured]/copyactivity-logs/[copy-activity-name]/[copy-activity-run-id]/[auto-generated-GUID].csv.
The log files have to be the csv files. The schema of the log file is as following:
| Column | Description |
|---|---|
| Timestamp | The timestamp when the file was skipped. |
| Level | The log level of this item. It will be in 'Warning' level for the item showing file skipping. |
| OperationName | Copy activity operational behavior on each file. It will be 'FileSkip' to specify the file to be skipped. |
| OperationItem | The file names to be skipped. |
| Message | More information to illustrate why the file being skipped. |
The example of a log file is as following:
Timestamp,Level,OperationName,OperationItem,Message
2020-03-24 05:35:41.0209942,Warning,FileSkip,"bigfile.csv","File is skipped after read 322961408 bytes: ErrorCode=UserErrorSourceBlobNotExist,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=The required Blob is missing. ContainerName: https://transferserviceonebox.blob.core.windows.net/skipfaultyfile, path: bigfile.csv.,Source=Microsoft.DataTransfer.ClientLibrary,'."
2020-03-24 05:38:41.2595989,Warning,FileSkip,"3_nopermission.txt","File is skipped after read 0 bytes: ErrorCode=AdlsGen2OperationFailed,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=ADLS Gen2 operation failed for: Operation returned an invalid status code 'Forbidden'. Account: 'adlsgen2perfsource'. FileSystem: 'skipfaultyfilesforbidden'. Path: '3_nopermission.txt'. ErrorCode: 'AuthorizationPermissionMismatch'. Message: 'This request is not authorized to perform this operation using this permission.'. RequestId: '35089f5d-101f-008c-489e-01cce4000000'..,Source=Microsoft.DataTransfer.ClientLibrary,''Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=Operation returned an invalid status code 'Forbidden',Source=,''Type=Microsoft.Azure.Storage.Data.Models.ErrorSchemaException,Message='Type=Microsoft.Azure.Storage.Data.Models.ErrorSchemaException,Message=Operation returned an invalid status code 'Forbidden',Source=Microsoft.DataTransfer.ClientLibrary,',Source=Microsoft.DataTransfer.ClientLibrary,'."
From the log above, you can see bigfile.csv has been skipped due to another application deleted this file when the service was copying it. And 3_nopermission.txt has been skipped because the service is not allowed to access it due to permission issue.
Copying tabular data
Supported scenarios
Copy activity supports three scenarios for detecting, skipping, and logging incompatible tabular data:
Incompatibility between the source data type and the sink native type.
For example: Copy data from a CSV file in Blob storage to a SQL database with a schema definition that contains three INT type columns. The CSV file rows that contain numeric data, such as 123,456,789 are copied successfully to the sink store. However, the rows that contain non-numeric values, such as 123,456, abc are detected as incompatible and are skipped.
Mismatch in the number of columns between the source and the sink.
For example: Copy data from a CSV file in Blob storage to a SQL database with a schema definition that contains six columns. The CSV file rows that contain six columns are copied successfully to the sink store. The CSV file rows that contain more than six columns are detected as incompatible and are skipped.
Primary key violation when writing to SQL Server/Azure SQL Database/Azure Cosmos DB.
For example: Copy data from a SQL server to a SQL database. A primary key is defined in the sink SQL database, but no such primary key is defined in the source SQL server. The duplicated rows that exist in the source cannot be copied to the sink. Copy activity copies only the first row of the source data into the sink. The subsequent source rows that contain the duplicated primary key value are detected as incompatible and are skipped.
Note
- To load data into Azure Synapse Analytics using PolyBase, configure PolyBase's native fault tolerance settings by specifying reject policies via "polyBaseSettings" in copy activity. You can still enable redirecting PolyBase incompatible rows to Blob or ADLS as normal as shown below.
- This feature doesn't apply when copy activity is configured to invoke Amazon Redshift Unload.
- This feature doesn't apply when copy activity is configured to invoke a stored procedure from a SQL sink, or use Upsert to write data into a SQL sink.
Configuration
The following example provides a JSON definition to configure skipping the incompatible rows in copy activity:
"typeProperties": {
"source": {
"type": "AzureSqlSource"
},
"sink": {
"type": "AzureSqlSink"
},
"enableSkipIncompatibleRow": true,
"logSettings": {
"enableCopyActivityLog": true,
"copyActivityLogSettings": {
"logLevel": "Warning",
"enableReliableLogging": false
},
"logLocationSettings": {
"linkedServiceName": {
"referenceName": "ADLSGen2",
"type": "LinkedServiceReference"
},
"path": "sessionlog/"
}
}
},
| Property | Description | Allowed values | Required |
|---|---|---|---|
| enableSkipIncompatibleRow | Specifies whether to skip incompatible rows during copy or not. | True False (default) |
No |
| logSettings | A group of properties that can be specified when you want to log the incompatible rows. | No | |
| linkedServiceName | The linked service of Azure Blob Storage or Azure Data Lake Storage Gen2 to store the log that contains the skipped rows. | The names of an AzureBlobStorage or AzureBlobFS type linked service, which refers to the instance that you use to store the log file. |
No |
| path | The path of the log files that contains the skipped rows. | Specify the path that you want to use to log the incompatible data. If you do not provide a path, the service creates a container for you. | No |
Monitor skipped rows
After the copy activity run completes, you can see the number of skipped rows in the output of the copy activity:
"output": {
"dataRead": 95,
"dataWritten": 186,
"rowsCopied": 9,
"rowsSkipped": 2,
"copyDuration": 16,
"throughput": 0.01,
"logFilePath": "myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"errors": []
},
If you configure to log the incompatible rows, you can find the log file from this path: https://[your-blob-account].blob.core.windows.net/[path-if-configured]/copyactivity-logs/[copy-activity-name]/[copy-activity-run-id]/[auto-generated-GUID].csv.
The log files will be the csv files. The schema of the log file is as following:
| Column | Description |
|---|---|
| Timestamp | The timestamp when the incompatible rows were skipped |
| Level | The log level of this item. It will be in 'Warning' level if this item shows the skipped rows |
| OperationName | Copy activity operational behavior on each row. It will be 'TabularRowSkip' to specify that the particular incompatible row has been skipped |
| OperationItem | The skipped rows from the source data store. |
| Message | More information to illustrate why the incompatibility of this particular row. |
An example of the log file content is as follows:
Timestamp, Level, OperationName, OperationItem, Message
2020-02-26 06:22:32.2586581, Warning, TabularRowSkip, """data1"", ""data2"", ""data3""," "Column 'Prop_2' contains an invalid value 'data3'. Cannot convert 'data3' to type 'DateTime'."
2020-02-26 06:22:33.2586351, Warning, TabularRowSkip, """data4"", ""data5"", ""data6"",", "Violation of PRIMARY KEY constraint 'PK_tblintstrdatetimewithpk'. Cannot insert duplicate key in object 'dbo.tblintstrdatetimewithpk'. The duplicate key value is (data4)."
From the sample log file above, you can see one row "data1, data2, data3" has been skipped due to type conversion issue from source to destination store. Another row "data4, data5, data6" has been skipped due to PK violation issue from source to destination store.
Copying tabular data (legacy):
The following approach is the legacy way to enable fault tolerance for copying tabular data only. If you are creating new pipeline or activity, you are encouraged to start from here instead.
Configuration
The following example provides a JSON definition to configure skipping the incompatible rows in copy activity:
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
},
"enableSkipIncompatibleRow": true,
"redirectIncompatibleRowSettings": {
"linkedServiceName": {
"referenceName": "<Azure Storage or Data Lake Store linked service>",
"type": "LinkedServiceReference"
},
"path": "redirectcontainer/erroroutput"
}
}
| Property | Description | Allowed values | Required |
|---|---|---|---|
| enableSkipIncompatibleRow | Specifies whether to skip incompatible rows during copy or not. | True False (default) |
No |
| redirectIncompatibleRowSettings | A group of properties that can be specified when you want to log the incompatible rows. | No | |
| linkedServiceName | The linked service of Azure Storage or Azure Data Lake Store to store the log that contains the skipped rows. | The names of an AzureStorage or AzureDataLakeStore type linked service, which refers to the instance that you want to use to store the log file. |
No |
| path | The path of the log file that contains the skipped rows. | Specify the path that you want to use to log the incompatible data. If you do not provide a path, the service creates a container for you. | No |
Monitor skipped rows
After the copy activity run completes, you can see the number of skipped rows in the output of the copy activity:
"output": {
"dataRead": 95,
"dataWritten": 186,
"rowsCopied": 9,
"rowsSkipped": 2,
"copyDuration": 16,
"throughput": 0.01,
"redirectRowPath": "https://myblobstorage.blob.core.windows.net//myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"errors": []
},
If you configure to log the incompatible rows, you can find the log file at this path: https://[your-blob-account].blob.core.windows.net/[path-if-configured]/[copy-activity-run-id]/[auto-generated-GUID].csv.
The log files can only be the csv files. The original data being skipped will be logged with comma as column delimiter if needed. We add two more columns "ErrorCode" and "ErrorMessage" in additional to the original source data in log file, where you can see the root cause of the incompatibility. The ErrorCode and ErrorMessage will be quoted by double quotes.
An example of the log file content is as follows:
data1, data2, data3, "UserErrorInvalidDataValue", "Column 'Prop_2' contains an invalid value 'data3'. Cannot convert 'data3' to type 'DateTime'."
data4, data5, data6, "2627", "Violation of PRIMARY KEY constraint 'PK_tblintstrdatetimewithpk'. Cannot insert duplicate key in object 'dbo.tblintstrdatetimewithpk'. The duplicate key value is (data4)."
Related content
See the other copy activity articles: