Copy activity performance and scalability guide
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Sometimes you want to perform a large-scale data migration from data lake or enterprise data warehouse (EDW), to Azure. Other times you want to ingest large amounts of data, from different sources into Azure, for big data analytics. In each case, it is critical to achieve optimal performance and scalability.
Azure Data Factory and Azure Synapse Analytics pipelines provide a mechanism to ingest data, with the following advantages:
- Handles large amounts of data
- Is highly performant
- Is cost-effective
These advantages are an excellent fit for data engineers who want to build scalable data ingestion pipelines that are highly performant.
After reading this article, you will be able to answer the following questions:
- What level of performance and scalability can I achieve using copy activity for data migration and data ingestion scenarios?
- What steps should I take to tune the performance of the copy activity?
- What performance optimizations can I utilize for a single copy activity run?
- What other external factors to consider when optimizing copy performance?
Note
If you aren't familiar with the copy activity in general, see the copy activity overview before you read this article.
Copy performance and scalability achievable using Azure Data Factory and Synapse pipelines
Azure Data Factory and Synapse pipelines offer a serverless architecture that allows parallelism at different levels.
This architecture allows you to develop pipelines that maximize data movement throughput for your environment. These pipelines fully utilize the following resources:
- Network bandwidth between the source and destination data stores
- Source or destination data store input/output operations per second (IOPS) and bandwidth
This full utilization means you can estimate the overall throughput by measuring the minimum throughput available with the following resources:
- Source data store
- Destination data store
- Network bandwidth in between the source and destination data stores
The table below shows the calculation of data movement duration. The duration in each cell is calculated based on a given network and data store bandwidth and a given data payload size.
Note
The duration provided below are meant to represent achievable performance in an end-to-end data integration solution by using one or more performance optimization techniques described in Copy performance optimization features, including using ForEach to partition and spawn off multiple concurrent copy activities. We recommend you to follow steps laid out in Performance tuning steps to optimize copy performance for your specific dataset and system configuration. You should use the numbers obtained in your performance tuning tests for production deployment planning, capacity planning, and billing projection.
| Data size / bandwidth |
50 Mbps | 100 Mbps | 500 Mbps | 1 Gbps | 5 Gbps | 10 Gbps | 50 Gbps |
|---|---|---|---|---|---|---|---|
| 1 GB | 2.7 min | 1.4 min | 0.3 min | 0.1 min | 0.03 min | 0.01 min | 0.0 min |
| 10 GB | 27.3 min | 13.7 min | 2.7 min | 1.3 min | 0.3 min | 0.1 min | 0.03 min |
| 100 GB | 4.6 hrs | 2.3 hrs | 0.5 hrs | 0.2 hrs | 0.05 hrs | 0.02 hrs | 0.0 hrs |
| 1 TB | 46.6 hrs | 23.3 hrs | 4.7 hrs | 2.3 hrs | 0.5 hrs | 0.2 hrs | 0.05 hrs |
| 10 TB | 19.4 days | 9.7 days | 1.9 days | 0.9 days | 0.2 days | 0.1 days | 0.02 days |
| 100 TB | 194.2 days | 97.1 days | 19.4 days | 9.7 days | 1.9 days | 1 day | 0.2 days |
| 1 PB | 64.7 mo | 32.4 mo | 6.5 mo | 3.2 mo | 0.6 mo | 0.3 mo | 0.06 mo |
| 10 PB | 647.3 mo | 323.6 mo | 64.7 mo | 31.6 mo | 6.5 mo | 3.2 mo | 0.6 mo |
Copy is scalable at different levels:
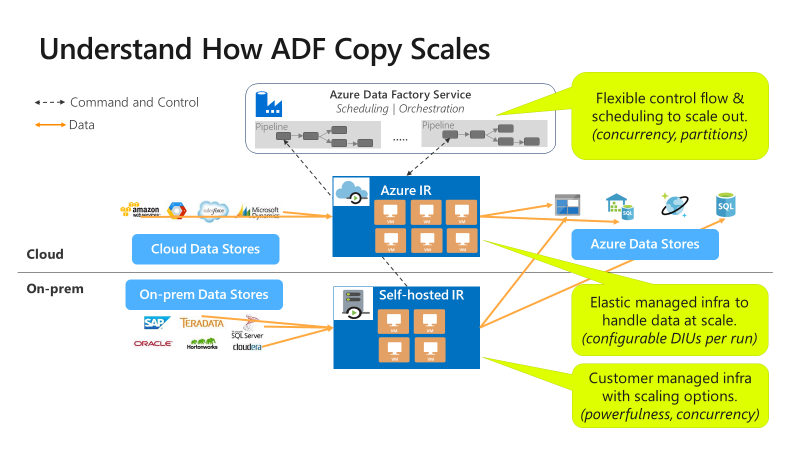
Control flow can start multiple copy activities in parallel, for example using For Each loop.
A single copy activity can take advantage of scalable compute resources.
- When using Azure integration runtime (IR), you can specify up to 256 data integration units (DIUs) for each copy activity, in a serverless manner.
- When using self-hosted IR, you can take either of the following approaches:
- Manually scale up the machine.
- Scale out to multiple machines (up to 4 nodes), and a single copy activity will partition its file set across all nodes.
A single copy activity reads from and writes to the data store using multiple threads in parallel.
Performance tuning steps
Take the following steps to tune the performance of your service with the copy activity:
Pick up a test dataset and establish a baseline.
During development, test your pipeline by using the copy activity against a representative data sample. The dataset you choose should represent your typical data patterns along the following attributes:
- Folder structure
- File pattern
- Data schema
And your dataset should be big enough to evaluate copy performance. A good size takes at least 10 minutes for copy activity to complete. Collect execution details and performance characteristics following copy activity monitoring.
How to maximize performance of a single copy activity:
We recommend you to first maximize performance using a single copy activity.
If the copy activity is being executed on an Azure integration runtime:
Start with default values for Data Integration Units (DIU) and parallel copy settings.
If the copy activity is being executed on a self-hosted integration runtime:
We recommend that you use a dedicated machine to host IR. The machine should be separate from the server hosting the data store. Start with default values for parallel copy setting and using a single node for the self-hosted IR.
Conduct a performance test run. Take a note of the performance achieved. Include the actual values used, such as DIUs and parallel copies. Refer to copy activity monitoring on how to collect run results and performance settings used. Learn how to troubleshoot copy activity performance to identify and resolve the bottleneck.
Iterate to conduct additional performance test runs following the troubleshooting and tuning guidance. Once single copy activity runs cannot achieve better throughput, consider whether to maximize aggregate throughput by running multiple copies concurrently. This option is discussed in the next numbered bullet.
How to maximize aggregate throughput by running multiple copies concurrently:
By now you have maximized the performance of a single copy activity. If you have not yet achieved the throughput upper limits of your environment, you can run multiple copy activities in parallel. You can run in parallel by using control flow constructs. One such construct is the For Each loop. For more information, see the following articles about solution templates:
Expand the configuration to your entire dataset.
When you're satisfied with the execution results and performance, you can expand the definition and pipeline to cover your entire dataset.
Troubleshoot copy activity performance
Follow the Performance tuning steps to plan and conduct performance test for your scenario. And learn how to troubleshoot each copy activity run's performance issue from Troubleshoot copy activity performance.
Copy performance optimization features
The service provides the following performance optimization features:
Data Integration Units
A Data Integration Unit (DIU) is a measure that represents the power of a single unit in Azure Data Factory and Synapse pipelines. Power is a combination of CPU, memory, and network resource allocation. DIU only applies to Azure integration runtime. DIU does not apply to self-hosted integration runtime. Learn more here.
Self-hosted integration runtime scalability
You might want to host an increasing concurrent workload. Or you might want to achieve higher performance in your present workload level. You can enhance the scale of processing by the following approaches:
- You can scale up the self-hosted IR, by increasing the number of concurrent jobs that can run on a node.
Scale up works only if the processor and memory of the node are being less than fully utilized. - You can scale out the self-hosted IR, by adding more nodes (machines).
For more information, see:
- Copy activity performance optimization features: Self-hosted integration runtime scalability
- Create and configure a self-hosted integration runtime: Scale considerations
Parallel copy
You can set the parallelCopies property to indicate the parallelism you want the copy activity to use. Think of this property as the maximum number of threads within the copy activity. The threads operate in parallel. The threads either read from your source, or write to your sink data stores. Learn more.
Staged copy
A data copy operation can send the data directly to the sink data store. Alternatively, you can choose to use Blob storage as an interim staging store. Learn more.
Related content
See the other copy activity articles: