Copy activity performance optimization features
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article outlines the copy activity performance optimization features that you can leverage in Azure Data Factory and Synapse pipelines.
Configuring performance features with UI
When you select a Copy activity on the pipeline editor canvas and choose the Settings tab in the activity configuration area below the canvas, you will see options to configure all of the performance features detailed below.
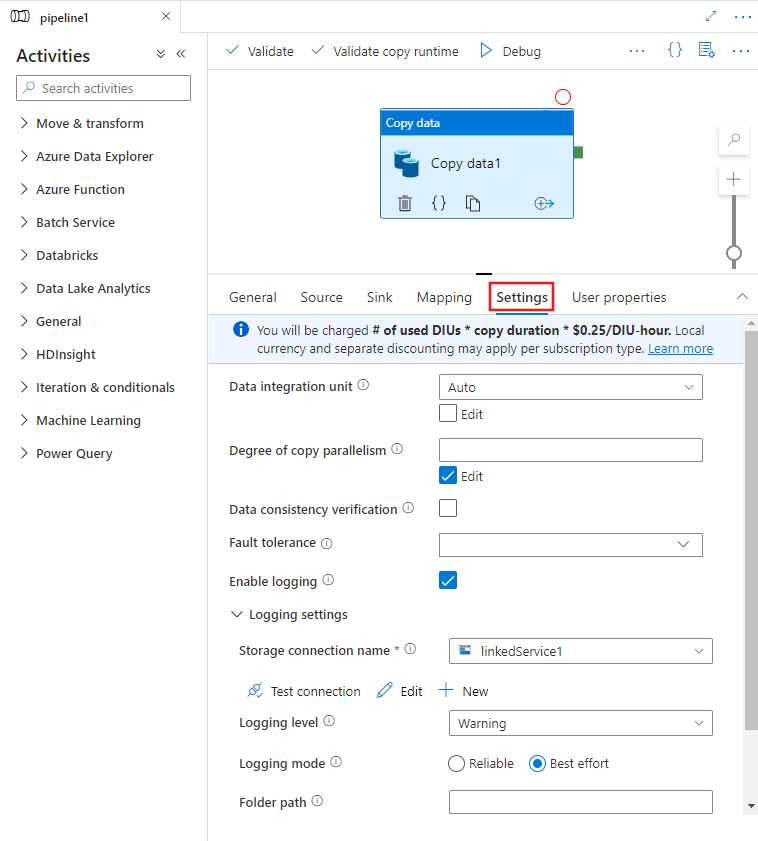
Data Integration Units
A Data Integration Unit is a measure that represents the power (a combination of CPU, memory, and network resource allocation) of a single unit within the service. Data Integration Unit only applies to Azure integration runtime, but not self-hosted integration runtime.
The allowed DIUs to empower a copy activity run is between 4 and 256. If not specified or you choose "Auto" on the UI, the service dynamically applies the optimal DIU setting based on your source-sink pair and data pattern. The following table lists the supported DIU ranges and default behavior in different copy scenarios:
| Copy scenario | Supported DIU range | Default DIUs determined by service |
|---|---|---|
| Between file stores | - Copy from or to single file: 4 - Copy from and to multiple files: 4-256 depending on the number and size of the files For example, if you copy data from a folder with 4 large files and choose to preserve hierarchy, the max effective DIU is 16; when you choose to merge file, the max effective DIU is 4. |
Between 4 and 32 depending on the number and size of the files |
| From file store to non-file store | - Copy from single file: 4 - Copy from multiple files: 4-256 depending on the number and size of the files For example, if you copy data from a folder with 4 large files, the max effective DIU is 16. |
- Copy into Azure SQL Database or Azure Cosmos DB: between 4 and 16 depending on the sink tier (DTUs/RUs) and source file pattern - Copy into Azure Synapse Analytics using PolyBase or COPY statement: 2 - Other scenario: 4 |
| From non-file store to file store | - Copy from partition-option-enabled data stores (including Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server, and Teradata): 4-256 when writing to a folder, and 4 when writing to one single file. Note per source data partition can use up to 4 DIUs. - Other scenarios: 4 |
- Copy from REST or HTTP: 1 - Copy from Amazon Redshift using UNLOAD: 4 - Other scenario: 4 |
| Between non-file stores | - Copy from partition-option-enabled data stores (including Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server, and Teradata): 4-256 when writing to a folder, and 4 when writing to one single file. Note per source data partition can use up to 4 DIUs. - Other scenarios: 4 |
- Copy from REST or HTTP: 1 - Other scenario: 4 |
You can see the DIUs used for each copy run in the copy activity monitoring view or activity output. For more information, see Copy activity monitoring. To override this default, specify a value for the dataIntegrationUnits property as follows. The actual number of DIUs that the copy operation uses at run time is equal to or less than the configured value, depending on your data pattern.
You will be charged # of used DIUs * copy duration * unit price/DIU-hour. See the current prices here. Local currency and separate discounting may apply per subscription type.
Example:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"dataIntegrationUnits": 128
}
}
]
Self-hosted integration runtime scalability
If you would like to achieve higher throughput, you can either scale up or scale out the Self-hosted IR:
- If the CPU and available memory on the Self-hosted IR node are not fully utilized, but the execution of concurrent jobs is reaching the limit, you should scale up by increasing the number of concurrent jobs that can run on a node. See here for instructions.
- If on the other hand, the CPU is high on the Self-hosted IR node or available memory is low, you can add a new node to help scale out the load across the multiple nodes. See here for instructions.
Note in the following scenarios, single copy activity execution can leverage multiple Self-hosted IR nodes:
- Copy data from file-based stores, depending on the number and size of the files.
- Copy data from partition-option-enabled data store (including Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, and Teradata), depending on the number of data partitions.
Parallel copy
You can set parallel copy (parallelCopies property in the JSON definition of the Copy activity, or Degree of parallelism setting in the Settings tab of the Copy activity properties in the user interface) on copy activity to indicate the parallelism that you want the copy activity to use. You can think of this property as the maximum number of threads within the copy activity that read from your source or write to your sink data stores in parallel.
The parallel copy is orthogonal to Data Integration Units or Self-hosted IR nodes. It is counted across all the DIUs or Self-hosted IR nodes.
For each copy activity run, by default the service dynamically applies the optimal parallel copy setting based on your source-sink pair and data pattern.
Tip
The default behavior of parallel copy usually gives you the best throughput, which is auto-determined by the service based on your source-sink pair, data pattern and number of DIUs or the Self-hosted IR's CPU/memory/node count. Refer to Troubleshoot copy activity performance on when to tune parallel copy.
The following table lists the parallel copy behavior:
| Copy scenario | Parallel copy behavior |
|---|---|
| Between file stores | parallelCopies determines the parallelism at the file level. The chunking within each file happens underneath automatically and transparently. It's designed to use the best suitable chunk size for a given data store type to load data in parallel. The actual number of parallel copies copy activity uses at run time is no more than the number of files you have. If the copy behavior is mergeFile into file sink, the copy activity can't take advantage of file-level parallelism. |
| From file store to non-file store | - When copying data into Azure SQL Database or Azure Cosmos DB, default parallel copy also depend on the sink tier (number of DTUs/RUs). - When copying data into Azure Table, default parallel copy is 4. |
| From non-file store to file store | - When copying data from partition-option-enabled data store (including Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS for SQL Server and Teradata), default parallel copy is 4. The actual number of parallel copies copy activity uses at run time is no more than the number of data partitions you have. When use Self-hosted Integration Runtime and copy to Azure Blob/ADLS Gen2, note the max effective parallel copy is 4 or 5 per IR node. - For other scenarios, parallel copy doesn't take effect. Even if parallelism is specified, it's not applied. |
| Between non-file stores | - When copying data into Azure SQL Database or Azure Cosmos DB, default parallel copy also depend on the sink tier (number of DTUs/RUs). - When copying data from partition-option-enabled data store (including Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS for SQL Server and Teradata), default parallel copy is 4. - When copying data into Azure Table, default parallel copy is 4. |
To control the load on machines that host your data stores, or to tune copy performance, you can override the default value and specify a value for the parallelCopies property. The value must be an integer greater than or equal to 1. At run time, for the best performance, the copy activity uses a value that is less than or equal to the value that you set.
When you specify a value for the parallelCopies property, take the load increase on your source and sink data stores into account. Also consider the load increase to the self-hosted integration runtime if the copy activity is empowered by it. This load increase happens especially when you have multiple activities or concurrent runs of the same activities that run against the same data store. If you notice that either the data store or the self-hosted integration runtime is overwhelmed with the load, decrease the parallelCopies value to relieve the load.
Example:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 32
}
}
]
Staged copy
When you copy data from a source data store to a sink data store, you might choose to use Azure Blob storage or Azure Data Lake Storage Gen2 as an interim staging store. Staging is especially useful in the following cases:
- You want to ingest data from various data stores into Azure Synapse Analytics via PolyBase, copy data from/to Snowflake, or ingest data from Amazon Redshift/HDFS performantly. Learn more details from:
- You don't want to open ports other than port 80 and port 443 in your firewall because of corporate IT policies. For example, when you copy data from an on-premises data store to an Azure SQL Database or an Azure Synapse Analytics, you need to activate outbound TCP communication on port 1433 for both the Windows firewall and your corporate firewall. In this scenario, staged copy can take advantage of the self-hosted integration runtime to first copy data to a staging storage over HTTP or HTTPS on port 443, then load the data from staging into SQL Database or Azure Synapse Analytics. In this flow, you don't need to enable port 1433.
- Sometimes it takes a while to perform a hybrid data movement (that is, to copy from an on-premises data store to a cloud data store) over a slow network connection. To improve performance, you can use staged copy to compress the data on-premises so that it takes less time to move data to the staging data store in the cloud. Then you can decompress the data in the staging store before you load into the destination data store.
How staged copy works
When you activate the staging feature, first the data is copied from the source data store to the staging storage (bring your own Azure Blob or Azure Data Lake Storage Gen2). Next, the data is copied from the staging to the sink data store. The copy activity automatically manages the two-stage flow for you, and also cleans up temporary data from the staging storage after the data movement is complete.

You need to grant delete permission to your Azure Data Factory in your staging storage, so that the temporary data can be cleaned after the copy activity runs.
When you activate data movement by using a staging store, you can specify whether you want the data to be compressed before you move data from the source data store to the staging store and then decompressed before you move data from an interim or staging data store to the sink data store.
Currently, you can't copy data between two data stores that are connected via different Self-hosted IRs, neither with nor without staged copy. For such scenario, you can configure two explicitly chained copy activities to copy from source to staging then from staging to sink.
Configuration
Configure the enableStaging setting in the copy activity to specify whether you want the data to be staged in storage before you load it into a destination data store. When you set enableStaging to TRUE, specify the additional properties listed in the following table.
| Property | Description | Default value | Required |
|---|---|---|---|
| enableStaging | Specify whether you want to copy data via an interim staging store. | False | No |
| linkedServiceName | Specify the name of an Azure Blob storage or Azure Data Lake Storage Gen2 linked service, which refers to the instance of Storage that you use as an interim staging store. | N/A | Yes, when enableStaging is set to TRUE |
| path | Specify the path that you want to contain the staged data. If you don't provide a path, the service creates a container to store temporary data. | N/A | No (Yes when storageIntegration in Snowflake connector is specified) |
| enableCompression | Specifies whether data should be compressed before it's copied to the destination. This setting reduces the volume of data being transferred. | False | No |
Note
If you use staged copy with compression enabled, the service principal or MSI authentication for staging blob linked service isn't supported.
Here's a sample definition of a copy activity with the properties that are described in the preceding table:
"activities":[
{
"name": "CopyActivityWithStaging",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "OracleSource",
},
"sink": {
"type": "SqlDWSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "stagingcontainer/path"
}
}
}
]
Staged copy billing impact
You're charged based on two steps: copy duration and copy type.
- When you use staging during a cloud copy, which is copying data from a cloud data store to another cloud data store, both stages empowered by Azure integration runtime, you're charged the [sum of copy duration for step 1 and step 2] x [cloud copy unit price].
- When you use staging during a hybrid copy, which is copying data from an on-premises data store to a cloud data store, one stage empowered by a self-hosted integration runtime, you're charged for [hybrid copy duration] x [hybrid copy unit price] + [cloud copy duration] x [cloud copy unit price].
Related content
See the other copy activity articles: