Свързване към таблици с общи модели на данни в Azure Data Lake Storage
Бележка
Azure Active Directory вече е Microsoft Entra ID. Научете повече
Поглъщане на данни при Dynamics 365 Customer Insights - Data използване на вашия Azure Data Lake Storage акаунт с таблици с общи модели на данни. Поглъщането на данни може да бъде пълно или постепенно.
Предварителни изисквания
Акаунтът Azure Data Lake Storage трябва да има разрешено йерархично пространство на имената. Данните трябва да се съхраняват в йерархичен формат на папки, който определя главната папка и има подпапки за всяка таблица. Подпапките могат да имат пълни данни или постъпкови папки с данни.
За да се удостоверите с принципал на Microsoft Entra услуга, уверете се, че е конфигуриран във вашия клиент. За повече информация вижте Свързване към Azure Data Lake Storage акаунт с главница Microsoft Entra науслуга.
Това Azure Data Lake Storage , от което искате да се свържете и да поглъщате данни, трябва да е в същия регион на Azure като средата, Dynamics 365 Customer Insights а абонаментите трябва да са в същия клиент. Не се поддържат връзки към папка на Common Data Model от хранилището с данни в различен регион на Azure. За да опознаете региона на Azure на околната среда, отидете на Настройки>на системата>за в Customer Insights - Data.
Данните, съхранявани в онлайн услугите, могат да се съхраняват на място, различно от мястото, където се обработват или съхраняват данните. Чрез импортиране или свързване с данни, съхранявани в онлайн услуги, Вие се съгласявате, че данните могат да бъдат прехвърляни. Научете повече в центъра за сигурност на Microsoft.
Директорът Customer Insights - Data на услугата трябва да бъде в една от следните роли, за да получи достъп до акаунта за съхранение. За повече информация вижте Даване на разрешения на принципала на услугата за достъп до акаунта за съхранение.
- Четец на данни за съхранение в Blob
- Собственик на данни за съхранение в Blob
- Сътрудник за данни за BLOB за съхранение
Когато се свързвате с вашето място за съхранение в Azure с помощта на опцията за абонамент за Azure, потребителят, който настройва връзката с източник на данни, се нуждае поне от разрешенията Storage Blob Data Contributor в акаунта за съхранение.
Когато се свързвате към мястото за съхранение в Azure с помощта на опцията за ресурс на Azure, потребителят, който задава източник на данни връзка, се нуждае поне от разрешението за действието Microsoft.Storage/storageAccounts/read в акаунта за съхранение. Вградената роля на Azure, която включва това действие, е ролята на четец . За да ограничите достъпа само до необходимото действие, създайте потребителска роля на Azure, която включва само това действие.
За оптимална производителност размерът на дяла трябва да бъде 1 GB или по-малко, а броят на файловете на дяловете в папката не трябва да надвишава 1000.
Данните във вашето хранилище на Data Lake трябва да следват стандарта Common Data Model за съхранение на вашите данни и да имат манифест Common Data Model, който да представя схемата на файловете с данни (*.csv или *.parquet). Манифестът трябва да предоставя подробни данни за таблиците, като например колони на таблици и типове данни, както и местоположението на файла с данни и типа на файла. За повече информация вижте манифеста на общия модел на данни. Ако манифестът не е налице, потребителите на администратори с достъп до Storage Blob Data Owner или Storage Blob Data Contributor могат да дефинират схемата при поглъщане на данните.
Бележка
Ако някое от полетата в .parquet файловете има тип данни Int96, данните може да не се показват на страницата Таблици . Препоръчваме ви да използвате стандартни типове данни, като например формата на Unix timestamp (който представя времето като брой секунди от 1 януари 1970 г. в полунощ UTC).
Ограничения
- Customer Insights - Data не поддържа колони от десетичен тип с точност по-голяма от 16.
Свързване с Azure Data Lake Storage
Отидете на Източници на>данни.
Изберете Добавяне на източник на данни.
Изберете Azure Data Lake Common Data Model tables.

Въведете име източник на данни и незадължително описание. Името се споменава в процесите надолу по веригата и не е възможно да се промени след създаването на източник на данни.
Изберете една от следните опции за Свързване на мястото за съхранение с помощта на. За повече информация вижте Свързване към Azure Data Lake Storage акаунт с главница Microsoft Entra науслуга.
- Azure ресурс: Въведете ИД наресурс. (private-link.md).
- Абонамент за Azure: Изберете абонамента и след това групата ресурси и акаунта за съхранение.
Бележка
Трябва да имате една от следните роли в контейнера, за да създадете източник на данни:
- Storage Blob Data Reader е достатъчен, за да чете от акаунт за съхранение и да Customer Insights - Data поглъща данните.
- Хранилище Blob Data Contributor или Owner се изисква, ако искате да редактирате манифестните файлове директно в Customer Insights - Data.
Наличието на ролята в сметката за съхранение ще осигури същата роля във всичките му контейнери.
По желание, ако искате да поглъщате данни от акаунт за съхранение чрез частна връзка на Azure, изберете Разрешаване на частна връзка. За повече информация вижте Частни връзки.
Изберете името на контейнера , съдържащ данните и схемата (model.json или manifest.json файл), от който да импортирате данни, и изберете Напред.
Бележка
Всеки файл model.json или manifest.json, свързан с друг източник на данни в средата, няма да се показва в списъка. Същият файл model.json или manifest.json обаче може да се използва за източници на данни в множество среди.
За да създадете нова схема, отидете на Създаване на нов файл със схема.
За да използвате съществуваща схема, отидете в папката, съдържаща файла model.json или manifest.cdm.json. Можете да търсите в директория, за да намерите файла.
Изберете json файла и изберете Напред. Показва се списък с наличните таблици.
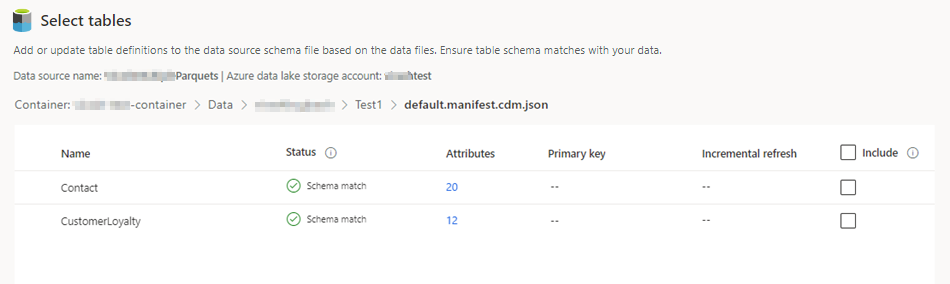
Изберете таблиците, които искате да включите.
Съвет
За да редактирате таблица в интерфейс за редактиране на JSON, изберете таблицата и след това Редактиране на файл със схема. Направете промени и изберете Запиши.
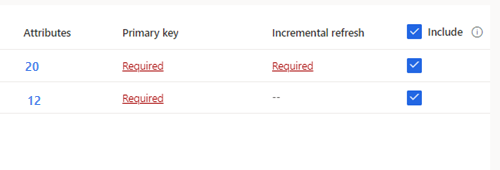
За избрани таблици, които изискват постъпково поглъщане,Задължително показва под Постъпково обновяване. За всяка от тези таблици вижте Конфигуриране на постъпково обновяване за източници на данни на Azure Data Lake.
За избрани таблици, където не е дефиниран първичен ключ,Задължително показва под Първичен ключ. За всяка от тези таблици:
- Изберете Задължително. Показва се панелът Редактиране на таблица .
- Изберете първичния ключ. Първичният ключ е атрибут, уникален за таблицата. За да бъде атрибутът валиден първичен ключ, той не трябва да включва дублирани стойности, липсващи стойности или нулеви стойности. Атрибутите string, integer и GUID тип данни се поддържат като първични ключове.
- По желание променете шаблона на дяла.
- Изберете Затвори , за да запишете и затворите панела.
Изберете броя на колоните за всяка включена таблица. Показва се страницата Управление на атрибути .
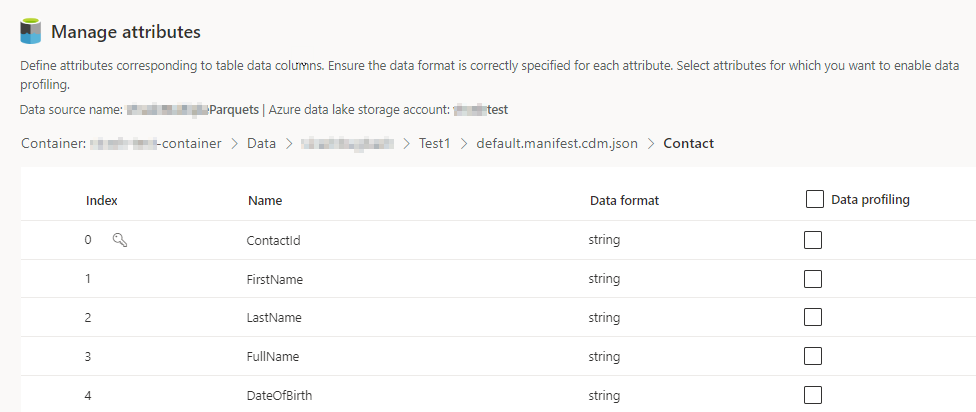
- Създаване на нови колони, редактиране или изтриване на съществуващи колони. Можете да промените името, формата на данните или да добавите семантичен тип.
- За да разрешите аналитичните и други възможности, изберете Профилиране на данни за цялата таблица или за конкретни колони. По подразбиране не е разрешена таблица за профилиране на данни.
- Изберете Готово.
Изберете Запиши. Отваря се страницата Източници на данни, показваща новата източник на данни в състояние Обновяване .
Съвет
Има състояния за задачи и процеси. Повечето процеси зависят от други процеси нагоре по веригата, като например източници на данни и опресняване на профилиранена данни.
Изберете състоянието, за да отворите екрана с подробни данни за хода на изпълнение и да видите хода на изпълнение на задачите. За да отмените проекта, изберете Отказ на задание в долната част на екрана.
Под всяка задача можете да изберете Преглед на подробни данни за повече информация за напредъка, като например време за обработка, последна дата на обработка и всички приложими грешки и предупреждения, свързани със задачата или процеса. Изберете Преглед на състоянието на системата в долната част на панела, за да видите други процеси в системата.

Зареждането на данни може да отнеме време. След успешно обновяване погълнатите данни могат да бъдат прегледани от страницата "Таблици ".
Създаване на нов файл със схема
Изберете Създаване на файл със схема.
Въведете име за файла и изберете Запиши.
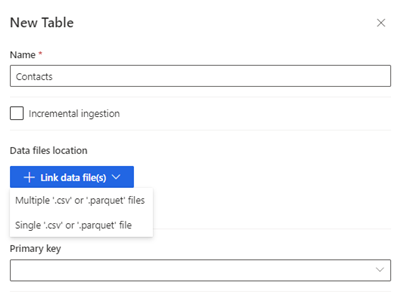
Изберете Нова таблица. Показва се панелът "Нова таблица ".
Въведете името на таблицата и изберете местоположението на файловете сданни.
- Множество .csv или .parquet файлове: Отидете до главната папка, изберете типа на шаблона и въведете израза.
- Единични .csv или .parquet файлове: Намерете файла .csv или .parquet и го изберете.
Изберете Запиши.
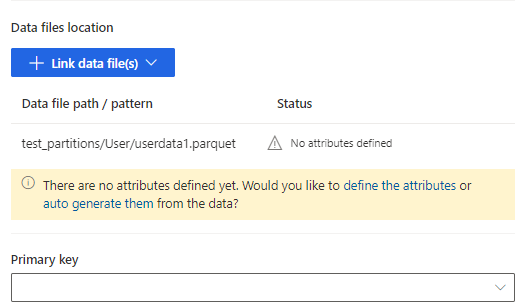
Изберете дефиниране на атрибутите , за да добавите ръчно атрибутите, или изберете автоматичното им генериране. За да дефинирате атрибутите, въведете име, изберете формата на данните и незадължителния семантичен тип. За автоматично генерирани атрибути:
След като атрибутите се генерират автоматично, изберете Преглед на атрибутите. Показва се страницата Управление на атрибути .
Уверете се, че форматът на данните е правилен за всеки атрибут.
За да разрешите аналитичните и други възможности, изберете Профилиране на данни за цялата таблица или за конкретни колони. По подразбиране не е разрешена таблица за профилиране на данни.
Изберете Готово. Показва се страницата Избор на таблици .
Продължете да добавяте таблици и колони, ако е приложимо.
След като всички таблици са добавени, изберете Включване , за да включите таблиците в източник на данни поглъщане.
За избрани таблици, които изискват постъпково поглъщане,Задължително показва под Постъпково обновяване. За всяка от тези таблици вижте Конфигуриране на постъпково обновяване за източници на данни на Azure Data Lake.
За избрани таблици, където не е дефиниран първичен ключ,Задължително показва под Първичен ключ. За всяка от тези таблици:
- Изберете Задължително. Показва се панелът Редактиране на таблица .
- Изберете първичния ключ. Първичният ключ е атрибут, уникален за таблицата. За да бъде атрибутът валиден първичен ключ, той не трябва да включва дублирани стойности, липсващи стойности или нулеви стойности. Атрибутите string, integer и GUID тип данни се поддържат като първични ключове.
- По желание променете шаблона на дяла.
- Изберете Затвори , за да запишете и затворите панела.
Изберете Запиши. Отваря се страницата Източници на данни, показваща новата източник на данни в състояние Обновяване .
Съвет
Има състояния за задачи и процеси. Повечето процеси зависят от други процеси нагоре по веригата, като например източници на данни и опресняване на профилиранена данни.
Изберете състоянието, за да отворите екрана с подробни данни за хода на изпълнение и да видите хода на изпълнение на задачите. За да отмените проекта, изберете Отказ на задание в долната част на екрана.
Под всяка задача можете да изберете Преглед на подробни данни за повече информация за напредъка, като например време за обработка, последна дата на обработка и всички приложими грешки и предупреждения, свързани със задачата или процеса. Изберете Преглед на състоянието на системата в долната част на панела, за да видите други процеси в системата.
Зареждането на данни може да отнеме време. След успешно обновяване погълнатите данни могат да бъдат прегледани от страницата Таблици с>данни .
Редактиране източник на данни Azure Data Lake Storage
Можете да актуализирате опцията Свързване към акаунт за съхранение с помощта на . За повече информация вижте Свързване към Azure Data Lake Storage акаунт с главница Microsoft Entra науслуга. За да се свържете с контейнер, различен от вашия акаунт за съхранение, или да промените името на акаунта, създайте нова източник на данни връзка.
Отидете на Източници на>данни. До източник на данни, която искате да актуализирате, изберете Редактиране.
Променете някоя от следните информации:
Описание
Свържете мястото си за съхранение с помощта на и информация за връзката. Не можете да променяте информацията за контейнера при актуализиране на връзката.
Бележка
Една от следните роли трябва да бъде присвоена на сметката за съхранение или контейнера:
- Четец на данни за съхранение в Blob
- Собственик на данни за съхранение в Blob
- Сътрудник за данни за BLOB за съхранение
Използвайте управлявани самоличности за Azure с вашите Azure Data Lake Storage ???
Разрешете частната връзка , ако искате да поглъщате данни от акаунт за съхранение чрез частна връзка на Azure. За повече информация вижте Частни връзки.
Изберете Напред.
Променете някое от следните неща:
Навигирайте до друг model.json или manifest.json файл с различен набор от таблици от контейнера.
За да добавите допълнителни таблици за поглъщане, изберете Нова таблица.
За да премахнете всички вече избрани таблици, ако няма зависимости, изберете таблицата и Изтрий.
Важно
Ако има зависимости от съществуващия model.json или manifest.json файл и набора от таблици, ще видите съобщение за грешка и не можете да изберете друг model.json или manifest.json файл. Премахнете тези зависимости, преди да промените файла model.json или manifest.json или създайте нов източник на данни с файла model.json или manifest.json, който искате да използвате, за да избегнете премахването на зависимостите.
За да промените местоположението на файла с данни или първичния ключ, изберете Редактиране.
За да промените данните за постъпково поглъщане, вижте Конфигуриране на постъпково обновяване за източници на данни на Azure Data Lake.
Променете само името на таблицата, за да съответства на името на таблицата в .json файл.
Бележка
Винаги запазвайте името на таблицата по същия начин като името на таблицата във файла model.json или manifest.json след поглъщане. Customer Insights - Data проверява всички имена на таблици с model.json или manifest.json по време на всяко обновяване на системата. Ако името на таблица се промени, възниква грешка, защото Customer Insights - Data не може да се намери новото име на таблица в .json файл. Ако случайно е променено име на погълната таблица, редактирайте името на таблицата, за да съответства на името в .json файл.
Изберете Колони , за да ги добавите или промените, или да разрешите профилирането на данни. След това изберете Готово.
ИзберетеЗапиши, за да приложите промените, и се върнете на страницата Източници на данни.
Съвет
Има състояния за задачи и процеси. Повечето процеси зависят от други процеси нагоре по веригата, като например източници на данни и опресняване на профилиранена данни.
Изберете състоянието, за да отворите екрана с подробни данни за хода на изпълнение и да видите хода на изпълнение на задачите. За да отмените проекта, изберете Отказ на задание в долната част на екрана.
Под всяка задача можете да изберете Преглед на подробни данни за повече информация за напредъка, като например време за обработка, последна дата на обработка и всички приложими грешки и предупреждения, свързани със задачата или процеса. Изберете Преглед на състоянието на системата в долната част на панела, за да видите други процеси в системата.