summarize operator
Applies to: ✅ Microsoft Fabric ✅ Azure Data Explorer ✅ Azure Monitor ✅ Microsoft Sentinel
Produces a table that aggregates the content of the input table.
Syntax
T | summarize [ SummarizeParameters ]
[[Column =] Aggregation [, ...]]
[by
[Column =] GroupExpression [, ...]]
Learn more about syntax conventions.
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| Column | string |
The name for the result column. Defaults to a name derived from the expression. | |
| Aggregation | string |
✔️ | A call to an aggregation function such as count() or avg(), with column names as arguments. |
| GroupExpression | scalar | ✔️ | A scalar expression that can reference the input data. The output will have as many records as there are distinct values of all the group expressions. |
| SummarizeParameters | string |
Zero or more space-separated parameters in the form of Name = Value that control the behavior. See supported parameters. |
Note
When the input table is empty, the output depends on whether GroupExpression is used:
- If GroupExpression is not provided, the output will be a single (empty) row.
- If GroupExpression is provided, the output will have no rows.
Supported parameters
| Name | Description |
|---|---|
hint.num_partitions |
Specifies the number of partitions used to share the query load on cluster nodes. See shuffle query |
hint.shufflekey=<key> |
The shufflekey query shares the query load on cluster nodes, using a key to partition data. See shuffle query |
hint.strategy=shuffle |
The shuffle strategy query shares the query load on cluster nodes, where each node will process one partition of the data. See shuffle query |
Returns
The input rows are arranged into groups having the same values of the by expressions. Then the specified aggregation functions are computed over each group, producing a row for each group. The result contains the by columns and also at least one column for each computed aggregate. (Some aggregation functions return multiple columns.)
The result has as many rows as there are distinct combinations of by values
(which may be zero). If there are no group keys provided, the result has a single
record.
To summarize over ranges of numeric values, use bin() to reduce ranges to discrete values.
Note
- Although you can provide arbitrary expressions for both the aggregation and grouping expressions, it's more efficient to use simple column names, or apply
bin()to a numeric column. - The automatic hourly bins for datetime columns is no longer supported. Use explicit binning instead. For example,
summarize by bin(timestamp, 1h).
Default values of aggregations
The following table summarizes the default values of aggregations:
| Operator | Default value |
|---|---|
count(), countif(), dcount(), dcountif(), count_distinct(), sum(), sumif(), variance(), varianceif(), stdev(), stdevif() |
0 |
make_bag(), make_bag_if(), make_list(), make_list_if(), make_set(), make_set_if() |
empty dynamic array ([]) |
| All others | null |
Note
When applying these aggregates to entities that include null values, the null values are ignored and don't factor into the calculation. For examples, see Aggregates default values.
Examples
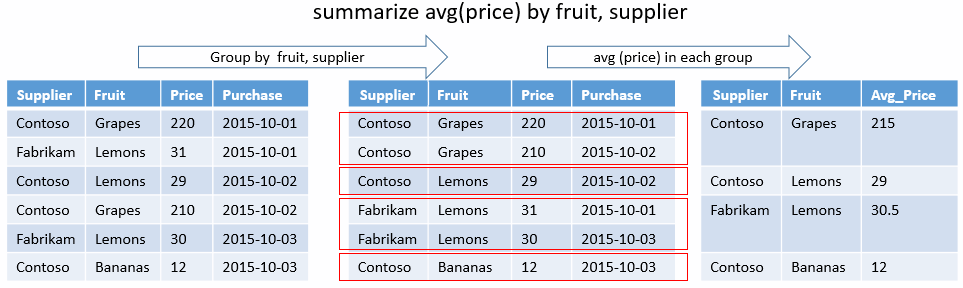
Unique combination
The following query determines what unique combinations of State and EventType there are for storms that resulted in direct injury. There are no aggregation functions, just group-by keys. The output will just show the columns for those results.
StormEvents
| where InjuriesDirect > 0
| summarize by State, EventType
Output
The following table shows only the first 5 rows. To see the full output, run the query.
| State | EventType |
|---|---|
| TEXAS | Thunderstorm Wind |
| TEXAS | Flash Flood |
| TEXAS | Winter Weather |
| TEXAS | High Wind |
| TEXAS | Flood |
| ... | ... |
Minimum and maximum timestamp
Finds the minimum and maximum heavy rain storms in Hawaii. There's no group-by clause, so there's just one row in the output.
StormEvents
| where State == "HAWAII" and EventType == "Heavy Rain"
| project Duration = EndTime - StartTime
| summarize Min = min(Duration), Max = max(Duration)
Output
| Min | Max |
|---|---|
| 01:08:00 | 11:55:00 |
Distinct count
The following query calculates the number of unique storm event types for each state and sorts the results by the number of unique storm types:
StormEvents
| summarize TypesOfStorms=dcount(EventType) by State
| sort by TypesOfStorms
Output
The following table shows only the first 5 rows. To see the full output, run the query.
| State | TypesOfStorms |
|---|---|
| TEXAS | 27 |
| CALIFORNIA | 26 |
| PENNSYLVANIA | 25 |
| GEORGIA | 24 |
| ILLINOIS | 23 |
| ... | ... |
Histogram
The following example calculates a histogram storm event types that had storms lasting longer than 1 day. Because Duration has many values, use bin() to group its values into 1-day intervals.
StormEvents
| project EventType, Duration = EndTime - StartTime
| where Duration > 1d
| summarize EventCount=count() by EventType, Length=bin(Duration, 1d)
| sort by Length
Output
| EventType | Length | EventCount |
|---|---|---|
| Drought | 30.00:00:00 | 1646 |
| Wildfire | 30.00:00:00 | 11 |
| Heat | 30.00:00:00 | 14 |
| Flood | 30.00:00:00 | 20 |
| Heavy Rain | 29.00:00:00 | 42 |
| ... | ... | ... |
Aggregates default values
When the input of summarize operator has at least one empty group-by key, its result is empty, too.
When the input of summarize operator doesn't have an empty group-by key, the result is the default values of the aggregates used in the summarize For more information, see Default values of aggregations.
datatable(x:long)[]
| summarize any_x=take_any(x), arg_max_x=arg_max(x, *), arg_min_x=arg_min(x, *), avg(x), buildschema(todynamic(tostring(x))), max(x), min(x), percentile(x, 55), hll(x) ,stdev(x), sum(x), sumif(x, x > 0), tdigest(x), variance(x)
Output
| any_x | arg_max_x | arg_min_x | avg_x | schema_x | max_x | min_x | percentile_x_55 | hll_x | stdev_x | sum_x | sumif_x | tdigest_x | variance_x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NaN | 0 | 0 | 0 | 0 |
The result of avg_x(x) is NaN due to dividing by 0.
datatable(x:long)[]
| summarize count(x), countif(x > 0) , dcount(x), dcountif(x, x > 0)
Output
| count_x | countif_ | dcount_x | dcountif_x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
datatable(x:long)[]
| summarize make_set(x), make_list(x)
Output
| set_x | list_x |
|---|---|
| [] | [] |
The aggregate avg sums all the non-nulls and counts only those which participated in the calculation (won't take nulls into account).
range x from 1 to 4 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize sum(y), avg(y)
Output
| sum_y | avg_y |
|---|---|
| 15 | 5 |
The regular count will count nulls:
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize count(y)
Output
| count_y |
|---|
| 2 |
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize make_set(y), make_set(y)
Output
| set_y | set_y1 |
|---|---|
| [5.0] | [5.0] |