Nota
L'accés a aquesta pàgina requereix autorització. Pots provar d'iniciar sessió o canviar de directori.
L'accés a aquesta pàgina requereix autorització. Pots provar de canviar directoris.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se describe cómo solucionar problemas de rendimiento de la actividad de copia en Azure Data Factory.
Después de ejecutar una actividad de copia, puede recopilar el resultado de la ejecución y estadísticas de rendimiento en la vista de supervisión de la actividad de copia. En la imagen siguiente se muestra un ejemplo:
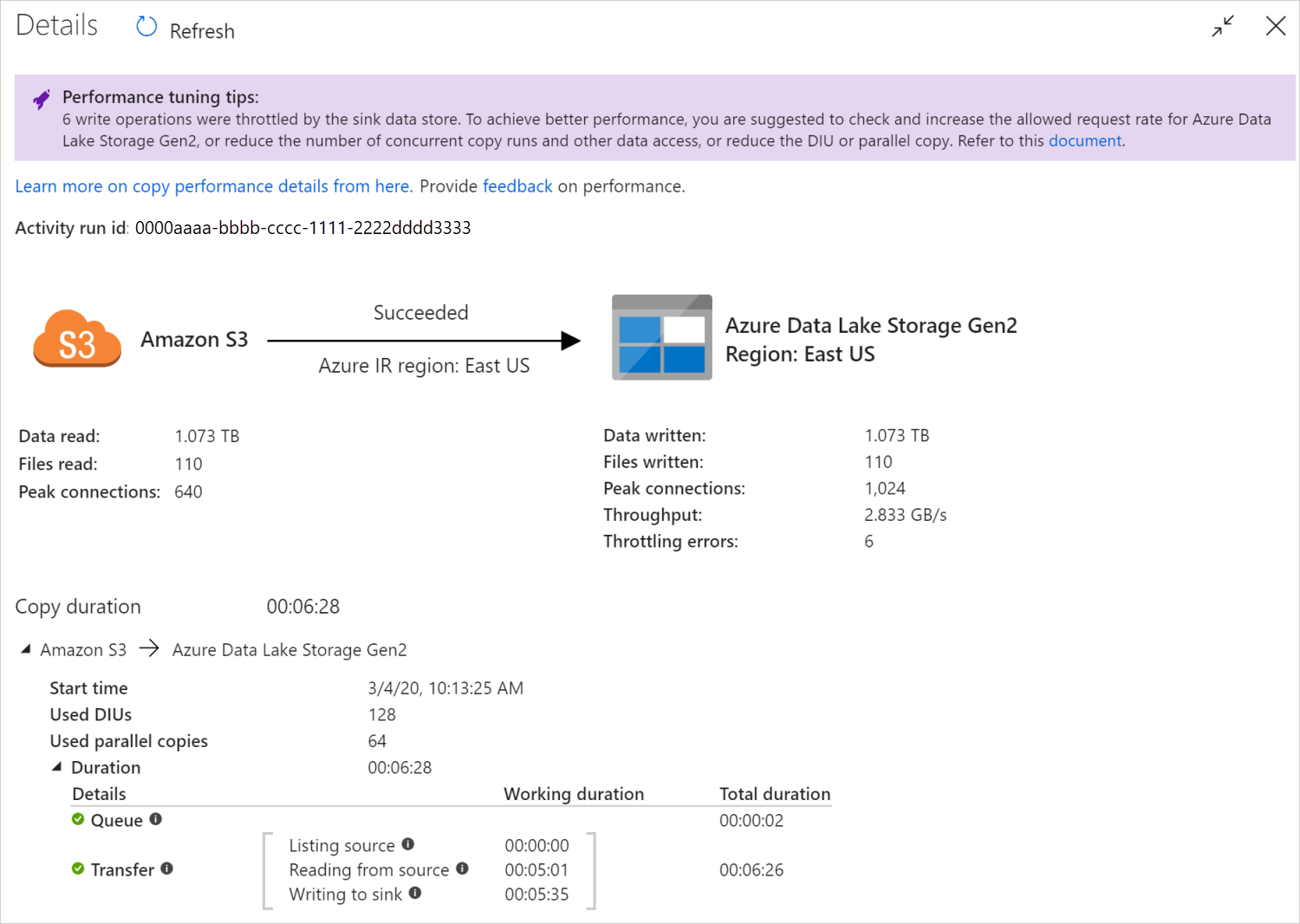
Sugerencias de optimización del rendimiento
En algunos escenarios, cuando se ejecuta una actividad de copia, aparece el mensaje "Sugerencias para el ajuste del rendimiento" en la parte superior, como se muestra en la imagen anterior. Las sugerencias indican el cuello de botella identificado por el servicio para la ejecución de esta copia en particular, junto con una recomendación sobre cómo mejorar el rendimiento de la copia. Intente llevar a cabo el cambio sugerido y ejecute la copia de nuevo.
Como referencia, actualmente las sugerencias de optimización del rendimiento proporcionan recomendaciones para los siguientes casos:
| Categoría | Sugerencias de optimización del rendimiento |
|---|---|
| Específica del almacén de datos | Carga de datos en Azure Synapse Analytics: se recomienda usar PolyBase o la instrucción COPY si no se están utilizando. |
| Copia de datos de o a Azure SQL Database: cuando el uso de DTU es elevado, se recomienda actualizar a un nivel superior. | |
| Copia de datos de o a Azure Cosmos DB: cuando la RU tiene un uso elevado, se recomienda actualizar a una RU mayor. | |
| Copia de datos de una tabla de SAP: cuando se copie una gran cantidad de datos, se recomienda usar la opción de partición del conector SAP para habilitar la carga paralela y aumentar el número máximo de particiones. | |
| Ingesta de datos de Amazon Redshift: se sugiere usar UNLOAD si aún no se está usando. | |
| Regulación del almacén de datos | Si el almacén de datos limita un gran número de operaciones de lectura o escritura durante la copia, se recomienda realizar una comprobación y aumentar la velocidad de solicitudes permitida para el almacén de datos, o bien reducir la carga de trabajo simultánea. |
| Tiempo de ejecución de integración | Si usa un entorno de ejecución de integración (IR) autohospedado y la actividad de copia espera mucho tiempo en la cola hasta que el IR tiene disponible un recurso para la ejecución, se recomienda escalar horizontal o verticalmente el entorno de ejecución de integración. |
| Si utiliza un Azure Integration Runtime que se encuentra en una región no óptima, lo que provoca una lectura y escritura lentas, se recomienda configurar para usar un IR en otra región. | |
| Tolerancia a errores | Si configura la tolerancia a errores y la omisión de filas incompatibles provoca un rendimiento lento, se recomienda asegurarse de que los datos de origen y receptor son compatibles. |
| copia almacenada provisionalmente | Si la copia almacenada provisionalmente está configurada pero no resulta útil para el par origen-receptor, se recomienda quitarla. |
| Reanudar | Tenga en cuenta que, cuando la actividad de copia se reanuda desde el último punto de error, pero se cambió la configuración de la unidad de integración de datos (DIU) después de la ejecución original, la nueva configuración de DIU no surte efecto. |
Comprender los detalles de ejecución de la actividad de copia
Los detalles de ejecución y las duraciones en la parte inferior de la vista de supervisión de la actividad de copia describen las fases clave por las que pasa la actividad de copia (consulte el ejemplo al principio de este artículo), lo que resulta especialmente útil para solucionar problemas de rendimiento de la copia. El cuello de botella de la ejecución de copia es la que tiene la mayor duración. Consulte en la tabla siguiente la definición de cada fase y aprenda a solucionar problemas de la actividad de copia en Azure IR y a solucionar problemas de la actividad de copia en el IR autohospedado con dicha información.
| Fase | Descripción |
|---|---|
| Cola | Tiempo transcurrido hasta que la actividad de copia se inicia realmente en el entorno de ejecución de integración. |
| Script de precopiado | Tiempo transcurrido entre la actividad de copia que comienza en IR y la actividad de copia que finaliza ejecutando el script previo a la copia en el almacén de datos de destino. Se aplica al configurar el script de pre-copia para los receptores de base de datos. Por ejemplo, al escribir datos en Azure SQL Database, realice la limpieza antes de copiar los datos nuevos. |
| Transferencia | Tiempo transcurrido entre el final del paso anterior y la transferencia de todos los datos del origen al destino por el IR. Tenga en cuenta que los subpasos de la transferencia se ejecutan en paralelo y que algunas operaciones no se muestran ahora, por ejemplo, analizar o generar el formato de archivo. - Time to first byte (Tiempo hasta el primer byte): tiempo transcurrido entre el final del paso anterior y el momento en que la instancia de IR recibe el primer byte del almacén de datos de origen. Se aplica a un origen no basado en archivos. - Enumeración de origen: el tiempo empleado en la enumeración de los archivos de origen o las particiones de datos. El último se aplica cuando se configuran las opciones de partición de los orígenes de base de datos; por ejemplo, cuando se copian datos de bases de datos como Oracle, SAP HANA, Teradata, Netezza, etc. - Reading from source (Lectura desde origen): tiempo empleado en la recuperación de datos desde el almacén de datos de origen. - Escritura en el depósito de destino: tiempo empleado en escribir datos en el almacén de datos destino. Tenga en cuenta que algunos conectores no tienen esta métrica en este momento, como Azure AI Search, Azure Data Explorer, Azure Table Storage, Oracle, SQL Server, Common Data Service, Dynamics 365, Dynamics CRM, Salesforce o Salesforce Service Cloud. |
Solución de problemas de la actividad de copia en Azure IR
Siga los pasos de optimización del rendimiento para planear y realizar la prueba de rendimiento de su escenario.
Si el rendimiento de la actividad de copia no satisface sus expectativas, quiere solucionar problemas de una única actividad de copia que se ejecuta en Azure Integration Runtime y aparecen sugerencias para optimizar el rendimiento en la vista de supervisión de la copia, aplique la recomendación e inténtelo de nuevo. De lo contrario, analice los detalles de ejecución de la actividad de copia, compruebe qué fase tiene la duración más larga y siga las siguientes indicaciones para mejorar el rendimiento de la copia:
El "script anterior a la copia" muestra una larga duración: esto significa que el script anterior a la copia que se ejecuta en la base de datos receptora tarda mucho tiempo en finalizar. Ajuste la lógica del script de precopia especificada para mejorar el rendimiento. Si necesita más ayuda para mejorar el script, póngase en contacto con el equipo de base de datos.
"Transferencia: tiempo hasta el primer byte" experimentó una larga duración de trabajo: la consulta de origen tarda mucho tiempo en devolver cualquier dato. Esto podría significar que la consulta tarda mucho tiempo en procesarse en el origen porque el origen está ocupado con otras tareas, o la consulta no es óptima, o los datos se almacenan de tal manera que tarda mucho tiempo en recuperarse. Considere si otras consultas se ejecutan en ese origen al mismo tiempo o si hay alguna actualización que pueda realizar en la consulta para que pueda recuperar datos más rápidamente. Si hay un equipo que administra el origen de datos, póngase en contacto con ellos para modificar la consulta o comprobar el rendimiento del origen.
En la fase de transferencia, el listado de orígenes muestra una larga duración de trabajo: significa que la enumeración de los archivos de origen o de las particiones de datos de la base de datos de origen es lenta.
Al copiar datos desde el origen basado en archivos, si usa el filtro de comodín en la ruta de acceso de la carpeta o en el nombre de archivo (
wildcardFolderPathowildcardFileName) o usa el filtro de hora de última modificación del archivo (modifiedDatetimeStartomodifiedDatetimeEnd), tenga en cuenta que dicho filtro daría lugar a que la actividad de copia enumerase todos los archivos de la carpeta especificada en el lado de cliente y después aplicase el filtro. Esta enumeración de archivos podría convertirse en el cuello de botella, especialmente cuando solo un pequeño conjunto de archivos cumple la regla del filtro.Compruebe si puede copiar archivos según la ruta de acceso o el nombre del archivo particionado por fecha y hora. De esta manera, no se genera carga en el proceso de listado del lado del origen.
Compruebe si en su lugar puede usar el filtro nativo del almacén de datos, específicamente "prefix" para Amazon S3/Azure Blob Storage/Azure Files y "listAfter/listBefore" para ADLS Gen1. Esos filtros son del lado servidor del almacén de datos y tendrían un rendimiento mejor.
Considere la posibilidad de dividir un conjunto de datos de gran tamaño en varios conjuntos de datos más pequeños y permitir que esos trabajos de copia se ejecuten simultáneamente, abordando cada uno de ellos una parte de los datos. Puede hacerlo con Lookup/GetMetadata + ForEach + Copy. Consulte las plantillas de solución de Copia de archivos de varios contenedores o Migración de datos de Amazon S3 a ADLS Gen2 como ejemplo general.
Compruebe si el servicio notifica algún error de restricción en la fuente de origen o si el almacén de datos se encuentra en un estado de alta utilización. Si es así, reduzca las cargas de trabajo en el almacén de datos o intente ponerse en contacto con el administrador del almacén de datos para aumentar el límite o los recursos disponibles.
Use una instancia de Azure IR en la misma región que el almacén de datos de origen o en una región próxima.
La operación "Transferencia - lectura desde el origen" experimentó una larga duración de trabajo:
Adopte el procedimiento recomendado de carga de datos específico del conector si es aplicable. Por ejemplo, al copiar datos desde Amazon Redshift, realice la configuración para que use UNLOAD de Redshift.
Compruebe si el servicio notifica algún error de limitación en el origen o si el almacén de datos registra un uso elevado. Si es así, reduzca las cargas de trabajo en el almacén de datos o intente ponerse en contacto con el administrador del almacén de datos para aumentar el límite o los recursos disponibles.
Compruebe el patrón de fuente y destino para la copia.
Si el patrón de copia admite más de cuatro unidades de integración de datos (DIU), consulte esta sección para obtener detalles; por lo general, puede intentar aumentar las unidades para obtener un mejor rendimiento.
En caso contrario, considere la posibilidad de dividir un conjunto de datos de gran tamaño en varios conjuntos de datos más pequeños y permitir que esos trabajos de copia se ejecuten simultáneamente, abordando cada uno de ellos una parte de los datos. Puede hacerlo con Lookup/GetMetadata + ForEach + Copy. Consulte las plantillas de solución de Copia de archivos de varios contenedores, Migración de datos de Amazon S3 a ADLS Gen2 o Copia masiva con una tabla de control como ejemplo general.
Use una instancia de Azure IR en la misma región que el almacén de datos de origen o en una región próxima.
"Transfer - escritura en el destino" experimentó una larga duración de trabajo:
Adopte el procedimiento recomendado de carga de datos específico del conector si es aplicable. Por ejemplo, al copiar datos en Azure Synapse Analytics, use PolyBase o la instrucción COPY.
Compruebe si el servicio informa sobre algún error de limitación en el sink o si su almacén de datos está bajo una alta utilización. Si es así, reduzca las cargas de trabajo en el almacén de datos o intente ponerse en contacto con el administrador del almacén de datos para aumentar el límite o los recursos disponibles.
Verifique su patrón de fuente y sumidero de copia:
Si el patrón de copia admite más de cuatro unidades de integración de datos (DIU), consulte esta sección para obtener detalles; por lo general, puede intentar aumentar las unidades para obtener un mejor rendimiento.
De lo contrario, ajuste gradualmente las copias paralelas. Un número excesivo de copias paralelas incluso puede degradar el rendimiento.
Use Azure IR en la misma región que el almacén de datos de destino o en una región cercana.
Solución de problemas de actividad de copia en IR autogestionado
Siga los pasos de optimización del rendimiento para planear y realizar la prueba de rendimiento de su escenario.
Si el rendimiento de la copia no satisface sus expectativas, quiere solucionar problemas de una única actividad de copia que se ejecuta en Azure Integration Runtime y aparecen sugerencias para optimizar el rendimiento en la vista de supervisión de la copia, aplique la recomendación e inténtelo de nuevo. De lo contrario, analice los detalles de ejecución de la actividad de copia, compruebe qué fase tiene la duración más larga y siga las siguientes indicaciones para mejorar el rendimiento de la copia:
La cola experimentó una larga duración: significa que la actividad de copia espera mucho tiempo en la cola hasta que su IR autoalojado dispone de recursos para ejecutar. Compruebe la capacidad y el uso de IR y escale vertical u horizontalmente según la carga de trabajo.
En la fase de transferencia, el tiempo hasta el primer byte muestra una larga duración de trabajo: significa que la consulta de origen tarda mucho tiempo en devolver datos. Compruebe y optimice la consulta o el servidor. Si necesita más ayuda, póngase en contacto con el equipo del almacén de datos.
En la fase de transferencia, el listado de orígenes muestra una larga duración de trabajo: significa que la enumeración de los archivos de origen o de las particiones de datos de la base de datos de origen es lenta.
Compruebe si la máquina de IR autohospedado tiene una latencia baja al conectarse al almacén de datos de origen. Si el origen está en Azure, puede usar esta herramienta para comprobar la latencia de la máquina de IR autohospedada en la región de Azure; cuanto menor, mejor.
Al copiar datos desde el origen basado en archivos, si usa el filtro de comodín en la ruta de acceso de la carpeta o en el nombre de archivo (
wildcardFolderPathowildcardFileName) o usa el filtro de hora de última modificación del archivo (modifiedDatetimeStartomodifiedDatetimeEnd), tenga en cuenta que dicho filtro daría lugar a que la actividad de copia enumerase todos los archivos de la carpeta especificada en el lado de cliente y después aplicase el filtro. Esta enumeración de archivos podría convertirse en el cuello de botella, especialmente cuando solo un pequeño conjunto de archivos cumple la regla del filtro.Compruebe si puede copiar archivos según la ruta de acceso o el nombre del archivo particionado por fecha y hora. De esta manera, no se genera carga en el proceso de listado del lado del origen.
Compruebe si en su lugar puede usar el filtro nativo del almacén de datos, específicamente "prefix" para Amazon S3/Azure Blob Storage/Azure Files y "listAfter/listBefore" para ADLS Gen1. Esos filtros son del lado servidor del almacén de datos y tendrían un rendimiento mejor.
Considere la posibilidad de dividir un conjunto de datos de gran tamaño en varios conjuntos de datos más pequeños y permitir que esos trabajos de copia se ejecuten simultáneamente, abordando cada uno de ellos una parte de los datos. Puede hacerlo con Lookup/GetMetadata + ForEach + Copy. Consulte las plantillas de solución de Copia de archivos de varios contenedores o Migración de datos de Amazon S3 a ADLS Gen2 como ejemplo general.
Compruebe si el servicio notifica algún error de restricción en la fuente de origen o si el almacén de datos se encuentra en un estado de alta utilización. Si es así, reduzca las cargas de trabajo en el almacén de datos o intente ponerse en contacto con el administrador del almacén de datos para aumentar el límite o los recursos disponibles.
La operación "Transferencia - lectura desde el origen" experimentó una larga duración de trabajo:
Compruebe si la máquina del IR autohospedado tiene una latencia baja al conectarse al almacén de datos de origen. Si el origen está en Azure, puede usar esta herramienta para comprobar la latencia desde la máquina de IR autohospedado hacia las regiones de Azure; cuanto menor sea, mejor.
Compruebe si la máquina de IR autohospedado tiene suficiente ancho de banda de entrada para leer y transferir los datos de forma eficaz. Si el almacén de datos de origen está en Azure, puede usar esta herramienta para comprobar la velocidad de descarga.
Compruebe la tendencia de uso de CPU y memoria del IR autohospedado en el portal de Azure -> su área de trabajo de Azure Data Factory o Synapse -> página de resumen. Considere la posibilidad de escalar vertical u horizontalmente los recursos del entorno de ejecución de integración si el uso de CPU es alto o hay poca memoria disponible.
Adopte el procedimiento recomendado de carga de datos específico del conector, siempre que se pueda aplicar. Por ejemplo:
\- Cuando copie datos desde Oracle, Netezza, Teradata, SAP HANA, SAP Table y SAP Open Hub, habilite las opciones de partición de datos para copiar datos en paralelo.
Al copiar datos desde HDFS, realice la configuración para usar DistCp.
Al copiar datos desde Amazon Redshift, realice la configuración para usar UNLOAD de Redshift.
Compruebe si el servicio notifica algún error de limitación en el origen o si el almacén de datos registra un uso elevado. Si es así, reduzca las cargas de trabajo en el almacén de datos o intente ponerse en contacto con el administrador del almacén de datos para aumentar el límite o los recursos disponibles.
Verifique su patrón de fuente y sumidero de copia:
Si copia datos de almacenes de datos habilitados para la opción de partición, considere la posibilidad de ajustar gradualmente las copias paralelas. Un número excesivo de copias paralelas incluso puede degradar el rendimiento.
En caso contrario, considere la posibilidad de dividir un conjunto de datos de gran tamaño en varios conjuntos de datos más pequeños y permitir que esos trabajos de copia se ejecuten simultáneamente, abordando cada uno de ellos una parte de los datos. Puede hacerlo con Lookup/GetMetadata + ForEach + Copy. Consulte las plantillas de solución de Copia de archivos de varios contenedores, Migración de datos de Amazon S3 a ADLS Gen2 o Copia masiva con una tabla de control como ejemplo general.
"Transfer - escritura en el destino" experimentó una larga duración de trabajo:
Adopte el procedimiento recomendado de carga de datos específico del conector si es aplicable. Por ejemplo, al copiar datos en Azure Synapse Analytics, use PolyBase o la instrucción COPY.
Compruebe si la máquina del IR autohospedado tiene una latencia baja al conectarse al almacén de datos receptor. Si el receptor está en Azure, puede usar esta herramienta para comprobar la latencia desde la máquina de Self-hosted IR hasta la región de Azure; cuanto menor, mejor.
Compruebe si la máquina de IR autohospedado tiene suficiente ancho de banda de salida para transferir y escribir los datos de forma eficaz. Si el almacén de datos receptor está en Azure, puede usar esta herramienta para comprobar la velocidad de carga.
Compruebe la tendencia de uso de la CPU y memoria del IR autohospedado en el portal de Azure -> del Data Factory o del área de trabajo de Synapse -> en la página de Información general. Considere la posibilidad de escalar vertical u horizontalmente los recursos del entorno de ejecución de integración si el uso de CPU es alto o hay poca memoria disponible.
Compruebe si el servicio informa de algún error de limitación de velocidad en el destino o si su almacén de datos está bajo una alta utilización. Si es así, reduzca las cargas de trabajo en el almacén de datos o intente ponerse en contacto con el administrador del almacén de datos para aumentar el límite o los recursos disponibles.
Considere la posibilidad de ajustar gradualmente las copias paralelas. Un número excesivo de copias paralelas incluso puede degradar el rendimiento.
Rendimiento del conector e IR
En esta sección se exploran algunas guías de solución de problemas de rendimiento para un tipo de conector o entorno de ejecución de integración concretos.
El tiempo de ejecución de la actividad varía según se use Azure IR o IR de red virtual de Azure
El tiempo de ejecución de la actividad varía cuando el conjunto de datos se basa en diferentes entornos de ejecución de integración.
Síntomas: Al alternar las opciones del desplegable de Servicio vinculado en el conjunto de datos se ejecutan las mismas actividades de la canalización, pero los tiempos de ejecución son radicalmente diferentes. Cuando el conjunto de datos se basa en el entorno de ejecución de integración de la red virtual administrada, tarda más tiempo promedio que la ejecución basada en el entorno de ejecución de integración predeterminado.
Causa: Al comprobar los detalles de las ejecuciones de la canalización, puede ver que la canalización lenta se ejecuta en el IR de la red virtual administrada (Virtual Network), mientras que la normal se ejecuta en Azure IR. Por diseño, el IR (runtime de integración) de la red virtual administrada requiere más tiempo de cola que Azure IR, ya que no se reserva un nodo de cálculo por instancia del servicio, lo que resulta en una fase de preparación para cada actividad de copia. Esto ocurre principalmente durante la integración a la red virtual, en lugar de hacerlo en Azure IR.
Bajo rendimiento al cargar datos en Azure SQL Database
Síntomas: La copia de datos en Azure SQL Database es lenta.
Causa: La causa principal del problema suele ser un cuello de botella en el lado de Azure SQL Database. Las posibles causas son las siguientes:
El nivel de Azure SQL Database no es suficientemente alto.
El uso de la DTU de Azure SQL Database está cerca del 100 %. Puede supervisar el rendimiento y considerar la posibilidad de actualizar el nivel de Azure SQL Database.
Los índices no se establecen correctamente. Quite todos los índices antes de la carga de datos y vuelva a crearlos después de completar la carga.
WriteBatchSize no es lo suficientemente grande como para ajustarse al tamaño de fila del esquema. Intente expandir la propiedad para resolver el problema.
En lugar de inserción masiva, se usa el procedimiento almacenado, del cual se espera un menor rendimiento.
Tiempo de espera o rendimiento lento al analizar archivos de Excel de gran tamaño
Síntomas:
Al crear un conjunto de datos de Excel e importar el esquema de la conexión o el almacenamiento, obtener una vista previa de los datos, enumerar o actualizar las hojas de cálculo, es posible que aparezca un error de tiempo de espera si el tamaño del archivo de Excel es grande.
Cuando use la tarea de copia para transferir datos de un archivo de Excel muy grande (> = 100 MB) a otro almacén de datos, es posible que experimente un rendimiento lento o un problema de falta de memoria.
Causa:
En operaciones como la importación de esquemas, la vista previa de datos y la enumeración de hojas de cálculo en un conjunto de datos de Excel. El tiempo de espera es de 100 s y es estático. En el caso de los archivos de Excel de gran tamaño, es posible que estas operaciones no finalicen dentro del valor del tiempo de espera.
La actividad de copia lee el archivo de Excel completo en la memoria y, luego, busca la hoja de cálculo y las celdas especificadas para leer los datos. Este comportamiento se debe al SDK subyacente que usa el servicio.
Solución:
Para importar el esquema, puede generar un archivo de ejemplo más pequeño que sea un subconjunto del archivo original y elegir "Importar esquema de archivo de ejemplo" en lugar de "Importar esquema desde conexión/almacén".
Para enumerar una hoja de cálculo, en la lista desplegable de la hoja de cálculo, puede seleccionar "Editar" e introducir en su lugar el nombre o índice de la hoja.
Para copiar un archivo de Excel de gran tamaño (>100 MB) en otro almacenamiento, puede usar la fuente de Excel de Data Flow que permite lectura continua y mejora el rendimiento.
El problema OOM al leer archivos grandes de JSON/Excel/XML
Síntomas: al leer archivos JSON/Excel/XML grandes, se produce la incidencia de memoria insuficiente (OOM) durante la ejecución de la actividad.
Causa:
- Para archivos XML grandes: el problema de OOM al leer archivos XML grandes es por diseño. La causa es que el archivo XML completo debe leerse en la memoria, ya que es un solo objeto y, luego, se deduce el esquema y se recuperan los datos.
- Para archivos Excel grandes: la incidencia de OOM relacionada con leer archivos Excel grandes es por diseño. La causa es que el SDK (POI/NPOI) usado debe leer todo el archivo de Excel en la memoria y, a continuación, deducir el esquema y obtener datos.
- Para archivos JSON grandes: el problema de OOM de leer archivos JSON grandes es por diseño cuando el archivo JSON es un solo objeto.
Recomendación: aplique una de las siguientes opciones para resolver el problema.
- Opción-1: registre un entorno de ejecución de integración autohospedado en línea con una máquina potente (con alta capacidad de CPU/memoria) para leer datos de su archivo grande a través de la actividad de copia de datos.
- Opción-2: Utilice memoria optimizada y clústeres de gran tamaño (por ejemplo, de 48 núcleos) para leer datos de su archivo grande mediante la actividad de flujo de datos de mapeo.
- Opción-3: divida el archivo grande en otros más pequeños y, a continuación, use la actividad de flujo de datos de asignación o copia para leer la carpeta.
- Opción-4: Si estás atascado o encuentras el problema de OOM durante la copia de archivos de la carpeta XML/Excel/JSON, utiliza la actividad foreach junto con la actividad de flujo de datos de mapeo y copia en tu canalización para manejar cada archivo o subcarpeta.
-
Opción-5: otros:
- Para XML, utilice la actividad de Notebook con un clúster optimizado para la memoria para leer datos de archivos si cada archivo tiene el mismo esquema. Actualmente, Spark tiene diferentes implementaciones para controlar XML.
- Para JSON, use diferentes formularios de documento (por ejemplo: Documento único, Documento por línea y Matriz de documentos) en la configuración JSON en origen de flujo de datos de asignación. Si el contenido del archivo JSON es Documento por línea, consume poca memoria.
Otras referencias
Estas son las referencias para la supervisión y ajuste del rendimiento de algunos de los almacenes de datos admitidos:
- Azure Blob Storage: Objetivos de escalabilidad y rendimiento de Blob Storage y Lista de comprobación de escalabilidad y rendimiento para Blob Storage.
- Azure Table Storage: Objetivos de escalabilidad y rendimiento de almacenamiento de tablas y Lista de comprobación de rendimiento y de escalabilidad para almacenamiento de tablas.
- Azure SQL Database: puede supervisar el rendimiento y comprobar el porcentaje de la unidad de transacción de base de datos (DTU).
- Azure Synapse Analytics: su funcionalidad se mide en unidades de Data Warehouse (DWU). Consulte Administración de la potencia de proceso en Azure Synapse Analytics (introducción).
- Azure Cosmos DB: Niveles de rendimiento en Azure Cosmos DB.
- SQL Server: Supervisión y optimización del rendimiento
- Servidor de archivos local: Performance tuning for file servers (Ajuste del rendimiento para los servidores de archivos).
Contenido relacionado
Vea los otros artículos sobre actividades de copia: