Personalización de modelos (versión preliminar 4.0)
Importante
Esta característica ahora está en desuso. El 10 de enero de 2025, se retirarán las características de reconocimiento de productos y personalización de modelos de Visión de Azure AI: después de esta fecha, las llamadas API a estos servicios fallarán.
Para mantener un funcionamiento sin problemas de los modelos, realice la transición a Custom Vision de Azure AI, que ahora está disponible con carácter general. Custom Vision ofrece una funcionalidad similar a estas características que se van a retirar.
La personalización de modelos le permite entrenar un modelo de Image Analysis especializado para su propio caso de uso. Los modelos personalizados pueden realizar clasificación de imágenes (las etiquetas se aplican a toda la imagen) o detección de objetos (las etiquetas se aplican a áreas específicas de la imagen). Después de crear y entrenar el modelo personalizado, este pertenece al recurso de Visión y puede llamarlo mediante la API Analyze Image.
Implemente la personalización de modelos de forma rápida y sencilla siguiendo un inicio rápido:
Importante
Puede entrenar un modelo personalizado mediante el servicio Custom Vision o el servicio Image Analysis 4.0 con personalización del modelo. En la tabla siguiente se comparan los dos servicios:
| Áreas | Servicio Custom Vision | Servicio Image Analysis 4.0 | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tareas | Clasificación de imágenes Detección de objetos |
Clasificación de imágenes Detección de objetos |
||||||||||||||||||||||||||||||||||||
| Modelo base | CNN | Nombre del transformador. | ||||||||||||||||||||||||||||||||||||
| Etiquetado | Customvision.ai | AML Studio | ||||||||||||||||||||||||||||||||||||
| Portal web | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| Bibliotecas | REST, SDK | REST, ejemplo de Python | ||||||||||||||||||||||||||||||||||||
| Datos mínimos de entrenamiento necesarios | 15 imágenes por categoría | 2-5 imágenes por categoría | ||||||||||||||||||||||||||||||||||||
| Almacenamiento de los datos de entrenamiento | Cargado en el servicio | Cuenta de almacenamiento de blobs del cliente | ||||||||||||||||||||||||||||||||||||
| Hospedaje de modelos | Nube y perimetral | Solo hospedaje en la nube, hospedaje de contenedores perimetrales próximamente | ||||||||||||||||||||||||||||||||||||
| Calidad de IA |
|
|
||||||||||||||||||||||||||||||||||||
| Precios | Precios de Custom Vision | Precio de análisis de imágenes |
Componentes del escenario
Los componentes principales de un sistema de personalización de modelos son las imágenes de entrenamiento, el archivo COCO, el objeto Conjunto de datos y el objeto Modelo.
Imágenes de entrenamiento
El conjunto de imágenes de entrenamiento debe incluir varios ejemplos de cada una de las etiquetas que desea detectar. También conviene recopilar algunas imágenes adicionales para probar el modelo una vez que esté entrenado. Las imágenes deben almacenarse en un contenedor de Azure Storage para poder acceder al modelo.
Para entrenar el modelo de forma eficaz, use imágenes con variedad visual. Seleccione imágenes que varíen en:
- ángulos de cámara
- iluminación
- background
- estilo visual
- sujetos individuales o grupos
- tamaño
- type
Además, asegúrese de que todas las imágenes de entrenamiento cumplen los criterios siguientes:
- La imagen debe presentarse en formato JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF o MPO.
- El tamaño del archivo de la imagen debe ser menor de 20 megabytes (MB).
- Las dimensiones de la imagen deben estar entre 50 x 50 píxeles y 16 000 x 16 000 píxeles.
Archivo COCO
El archivo COCO hace referencia a todas las imágenes de entrenamiento y las asocia a su información de etiquetado. En el caso de la detección de objetos, este ha especificado las coordenadas del rectángulo delimitador de cada etiqueta en cada imagen. Este archivo debe tener el formato COCO, que es un tipo específico de archivo JSON. El archivo COCO debe almacenarse en el mismo contenedor de Azure Storage que las imágenes de entrenamiento.
Sugerencia
Acerca de los archivos COCO
Los archivos COCO son archivos JSON con campos obligatorios específicos: "images", "annotations" y "categories". Un archivo COCO de ejemplo tendrá este aspecto:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
Referencia de campos del archivo COCO
Si está generando su propio archivo COCO desde cero, asegúrese de que todos los campos necesarios se rellenen con los detalles correctos. Estas tablas describen cada campo de un archivo COCO:
"images"
| Clave | Tipo | Description | ¿Necesario? |
|---|---|---|---|
id |
integer | Identificador de imagen único; empieza desde 1 | Sí |
width |
integer | Ancho de la imagen en píxeles | Sí |
height |
integer | Alto de la imagen en píxeles | Sí |
file_name |
string | Nombre único de la imagen. | Sí |
absolute_url o coco_url |
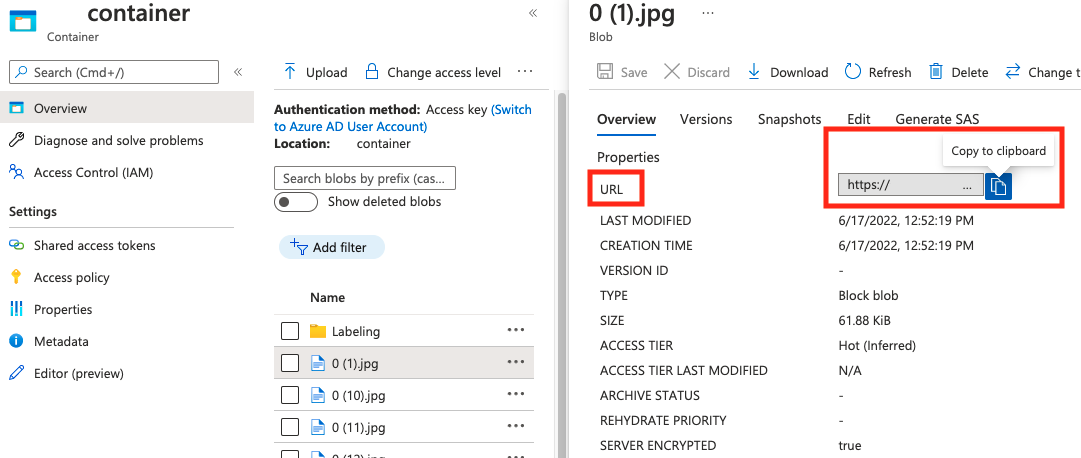
string | Ruta de acceso de imagen como un URI absoluto a un blob en un contenedor de blobs. El recurso de Visión debe tener permiso para leer los archivos de anotación y todos los archivos de imagen a los que se hace referencia. | Sí |
Puede encontrar el valor de absolute_url en las propiedades del contenedor de blobs.
"annotations"
| Clave | Tipo | Description | ¿Necesario? |
|---|---|---|---|
id |
integer | Id. de la anotación | Sí |
category_id |
integer | Id. de la categoría definida en la sección categories |
Sí |
image_id |
integer | Id. de la imagen | Sí |
area |
integer | Valor de "Ancho" x "Alto" (tercer y cuarto valor de bbox) |
No |
bbox |
list[float] | Coordenadas relativas del cuadro de límite (de 0 a 1), en el orden de "Izquierda", "Superior", "Ancho", "Alto" | Sí |
"categories"
| Clave | Tipo | Description | ¿Necesario? |
|---|---|---|---|
id |
integer | Id. único para cada categoría (clase de etiqueta). Estos deben estar presentes en la sección annotations. |
Sí |
name |
string | Nombre de la categoría (clase de etiqueta) | Sí |
Comprobación de archivos COCO
Puede usar nuestro código de ejemplo de Python para comprobar el formato de un archivo COCO.
Objeto Conjunto de datos
El objeto Conjunto de datos es una estructura de datos almacenada por el servicio Image Analysis que hace referencia al archivo de asociación. Debe crear un objeto Conjunto de datos para poder crear y entrenar un modelo.
Objeto Model.
El objeto Modelo es una estructura de datos almacenada por el servicio Image Analysis que representa un modelo personalizado. Debe estar asociado a un Conjunto de datos para realizar el entrenamiento inicial. Una vez entrenado, puede consultar el modelo al escribir su nombre en el parámetro de consulta model-name de la llamada a la API Analyze Image.
Límites de cuota
Esta tabla describe los límites de escala de sus proyectos de modelo personalizados.
| Category | Clasificador de imágenes genéricas | Detector de objetos genéricos |
|---|---|---|
| N.° máx. de horas de entrenamiento | 288 (12 días) | 288 (12 días) |
| N.° máx. de imágenes de entrenamiento | 1 000 000 | 200 000 |
| N.° máx. de imágenes de evaluación | 100 000 | 100 000 |
| N.° mín. de imágenes de entrenamiento por categoría | 2 | 2 |
| N.° máx. de etiquetas por imagen | 1 | N/D |
| N.° máx. de regiones por imagen | N/D | 1,000 |
| N.° máx. de categorías | 2,500 | 1,000 |
| N.° mín. de categorías | 2 | 1 |
| Tamaño de imagen máx. (entrenamiento) | 20 MB | 20 MB |
| Tamaño de imagen máx. (predicción) | Sincronización: 6 MB, lote: 20 MB | Sincronización: 6 MB, lote: 20 MB |
| Ancho/alto máx. de imágenes (entrenamiento) | 10 240 | 10 240 |
| Ancho/alto mín. de imágenes (predicción) | 50 | 50 |
| Regiones disponibles | Oeste de EE. UU. 2, Este de EE. UU., Oeste de Europa | Oeste de EE. UU. 2, Este de EE. UU., Oeste de Europa |
| Tipos de imágenes aceptadas | JPG, PNG, BMP, GIF, JPEG | JPG, PNG, BMP, GIF, JPEG |
Preguntas más frecuentes
¿Por qué se produce un error en la importación de archivos COCO al importar desde Blob Storage?
Actualmente, Microsoft está abordando un problema que provoca que la importación de archivos COCO falle con conjuntos de datos grandes cuando se inicia en Vision Studio. Para entrenar con un conjunto de datos grande, se recomienda usar la API de REST en su lugar.
¿Por qué el entrenamiento tarda más (o menos) que mi presupuesto especificado?
El presupuesto de entrenamiento especificado representa el tiempo de proceso calibrado, no el tiempo real. Aquí se muestran algunas razones comunes que explican esta diferencia:
Más tiempo que el presupuesto especificado:
- Image Analysis experimenta un alto tráfico de entrenamiento y los recursos de GPU pueden ser escasos. El trabajo puede esperar en la cola o ponerse en espera durante el entrenamiento.
- Se ha producido un error inesperado en el proceso de entrenamiento del backend, lo que ha resultado en una lógica de reintento. Las ejecuciones con errores no consumen el presupuesto, pero esto puede dar lugar a un tiempo de entrenamiento más largo en general.
- Los datos están almacenados en una región distinta al recurso de Visión creado, lo que provocará un tiempo de transmisión de datos más largo.
Menos tiempo que el presupuesto especificado: Los siguientes factores aceleran el entrenamiento a costa de usar más presupuesto en determinado tiempo real.
- Image Analysis a veces entrena con varias GPU en función de los datos.
- Image Analysis a veces entrena varias pruebas de exploración en varias GPU al mismo tiempo.
- Image Analysis a veces usa las mejores SKU de GPU (más rápidas) para entrenar.
¿Por qué falla mi entrenamiento y qué debo hacer?
Estos son algunos motivos por los que el entrenamiento falla:
diverged: el entrenamiento no puede aprender cosas significativas de los datos. Algunas causas comunes son:- Los datos no son suficientes: proporcionar más datos puede ayudarle.
- Los datos son de mala calidad: compruebe si las imágenes son de baja resolución, si tienen relaciones de aspecto extremas o si las anotaciones son incorrectas.
notEnoughBudget: el presupuesto especificado no es suficiente para el tamaño del conjunto de datos y el tipo de modelo que está entrenando. Especifique un presupuesto mayor.datasetCorrupt: esto significa que las imágenes proporcionadas no son accesibles o el archivo de anotación tiene el formato incorrecto.datasetNotFound: no se puede encontrar el conjunto de datos.unknown: podría tratarse de un problema de backend. Comuníquese con el soporte técnico para la investigación.
¿Qué métricas se usan para evaluar los modelos?
Se usan las métricas siguientes:
- Clasificación de imágenes: Precisión promedio, Precisión con mejor puntuación, Precisión con mejores cinco
- Detección de objetos: Media de precisión promedio @ 30, Media de precisión promedio @ 50, Media de precisión promedio @ 75
¿Por qué se produce un error en el registro del conjunto de datos?
Las respuestas de la API deben ser lo suficientemente informativas. Son las siguientes:
DatasetAlreadyExists: ya existe un conjunto de datos con el mismo nombreDatasetInvalidAnnotationUri: se ha proporcionado un identificador URI no válido entre los identificadores URI de anotación en el momento del registro del conjunto de datos.
¿Cuántas imágenes son necesarias para una calidad razonable, buena o superior del modelo?
Aunque los modelos Florence tienen una gran capacidad de aprendizaje con pocas tomas (pueden logran un gran rendimiento del modelo con una disponibilidad de datos limitada), en general, más datos hacen que el modelo entrenado sea mejor y más sólido. Algunos escenarios requieren pocos datos (como clasificar una manzana si se la compara con un plátano), pero otros requieren más (como detectar 200 tipos de insectos en un bosque pluvial). Esto hace que no sean tan fácil darle una única recomendación.
Si su presupuesto para el etiquetado de datos es limitado nuestro flujo de trabajo recomendado es repetir estos pasos:
Recopile
Nimágenes por clase, dondeNimágenes es un número sencillo para recopilar (por ejemplo,N=3).Entrene un modelo y pruébelo en el conjunto de evaluación.
Si el rendimiento del modelo es:
- Suficientemente bueno (el rendimiento supera sus expectativas, o es muy similar al del experimento anterior pero con menos datos recopilados): deténgase aquí y use este modelo.
- No es bueno (el rendimiento sigue por debajo de sus expectativas, o es mejor que el experimento anterior con menos datos recopilados con un margen razonable):
- Recopile más imágenes para cada clase (un número que sea fácil de recopilar) y vuelva al paso 2.
- Si observa que el rendimiento no mejora más después de algunas iteraciones, podría deberse a:
- este problema no está bien definido o es demasiado difícil. Comuníquese con nosotros para un análisis personalizado del caso.
- los datos de entrenamiento pueden ser de baja calidad: compruebe si hay anotaciones incorrectas o imágenes de píxeles muy bajos.
¿Cuánto presupuesto de entrenamiento debo especificar?
Debe especificar el límite superior del presupuesto que está dispuesto a consumir. Image Analysis usa un sistema de ML automatizado en su backend para probar diferentes modelos y recetas de entrenamiento para encontrar el mejor modelo para su caso de uso. Cuanto más presupuesto tenga, mayor será la posibilidad de encontrar un mejor modelo.
El sistema de ML automatizado también se detiene automáticamente si concluye que no es necesario probar más, incluso si todavía queda presupuesto. Por tanto, no siempre agota el presupuesto especificado. Le garantizamos que no se le facturará por encima del presupuesto especificado.
¿Puedo controlar los hiperparámetros o usar mis propios modelos en el entrenamiento?
No, el servicio de personalización de modelos de Image Analysis usa un sistema de entrenamiento de ML automatizado con poco código que controla la búsqueda de hiperparámetros y la selección del modelo base en el backend.
¿Puedo exportar mi modelo después del entrenamiento?
La API de predicción solo se admite a través del servicio en la nube.
¿Por qué falla la evaluación de mi modelo de detección de objetos?
Estos son los posibles motivos:
internalServerError: se ha producido un error desconocido. Vuelva a intentarlo más tarde.modelNotFound: no se ha encontrado el modelo especificado.datasetNotFound: no se ha encontrado el conjunto de datos especificado.datasetAnnotationsInvalid: se ha producido un error al intentar descargar o analizar las anotaciones de la segmentación de referencia (ground truth) asociadas al conjunto de datos de prueba.datasetEmpty: el conjunto de datos de prueba no contenía ninguna anotación de segmentación de referencia.
¿Cuál es la latencia esperada para las predicciones con modelos personalizados?
No se recomienda usar modelos personalizados para los entornos críticos para la empresa debido a una posible latencia alta. Cuando los clientes entrenan modelos personalizados en Vision Studio, esos modelos pertenecen al recurso de Visión de Azure AI en el que se entrenaron y el cliente puede realizar llamadas a esos modelos mediante la API Analyze Image. Cuando realizan estas llamadas, el modelo personalizado se carga en la memoria y se inicializa la infraestructura de predicción. Mientras esto sucede, los clientes pueden experimentar una latencia mayor de la esperada al recibir resultados de predicción.
Seguridad y privacidad de datos
Al igual que sucede con todas las instancias de servicios de Azure AI, los desarrolladores que usan la personalización de modelos de Image Analysis deben estar al tanto de las directivas de Microsoft sobre los datos de clientes. Para más información, consulte la página de servicios de Azure AI en Microsoft Trust Center.