Supervisión de flujos de datos
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
Después de haber completado la compilación y depuración del flujo de datos, desea programarlo para ejecutarse según una programación en el contexto de una canalización. Puede programar la canalización mediante Desencadenadores. Para probar y depurar el flujo de datos de una canalización, puede usar el botón Depurar de la cinta de opciones de la barra de herramientas o la opción Desencadenar ahora del Generador de canalizaciones para comenzar una ejecución única con la que probar el flujo de datos dentro del contexto de la canalización.
Cuando se ejecuta la canalización, puede supervisar la canalización y todas las actividades contenidas en la canalización, incluida la actividad de Data Flow. Seleccione el icono de supervisión en el panel izquierdo de la interfaz de usuario. Puede ver una pantalla similar a la siguiente. Los iconos resaltados permiten profundizar en las actividades de la canalización, incluidas las actividades de Data Flow.

Se muestran estadísticas en este nivel, así como los tiempos de ejecución y estado. El identificador de ejecución en el nivel de actividad es diferente al del nivel de canalización. El identificador de ejecución en el nivel anterior es para la canalización. Al seleccionar el icono de las gafas, se obtienen detalles de la ejecución del flujo de datos.

En la vista de supervisión del nodo gráfico, puede ver una versión simplificada de solo lectura del gráfico de flujo de datos. Para ver la vista de detalles con nodos de gráfico más grandes que incluyen etiquetas de la fase de transformación, use el control deslizante de zoom en el lado derecho del lienzo. También puede usar el botón de búsqueda del lado derecho para buscar partes de la lógica de flujo de datos en el gráfico.
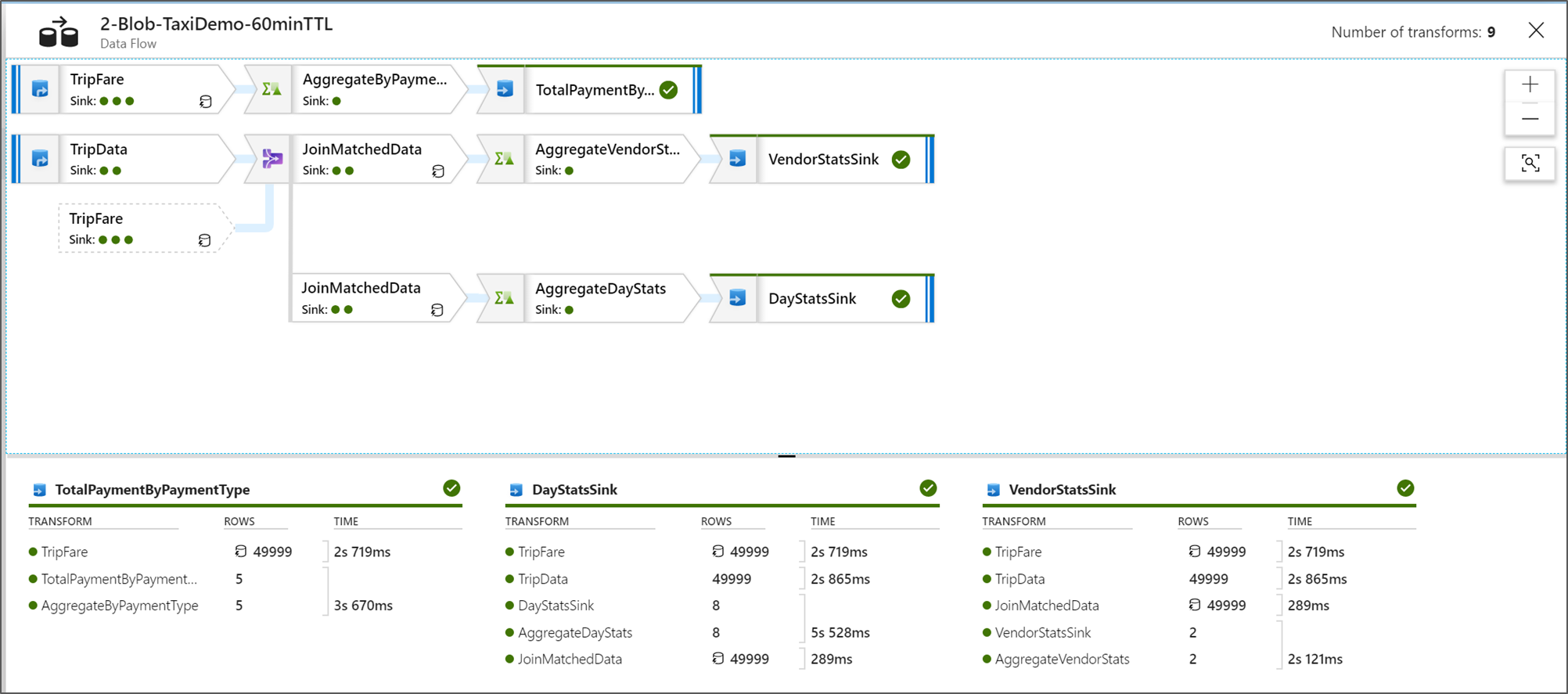
Visualización de planes de ejecución de Data Flow
Cuando se ejecuta Data Flow en Spark, el servicio determina las rutas de acceso de código óptimo según la integridad del flujo de datos. Además, las rutas de ejecución pueden producirse en distintos nodos de escalabilidad horizontal y particiones de datos. Por lo tanto, el gráfico de supervisión representa el diseño del flujo, teniendo en cuenta la ruta de acceso de ejecución de las transformaciones. Al seleccionar los nodos individuales, puede ver "fases" que representan el código que se ejecutó en el clúster. Los intervalos y recuentos que ve representan esos grupos o fases en lugar de los pasos individuales del diseño.

Al seleccionar el espacio abierto de la ventana de supervisión, las estadísticas del panel inferior muestran los recuentos de filas y el tiempo de cada receptor y las transformaciones que dieron lugar a los datos de receptor de linaje de transformación.
Cuando se seleccionan transformaciones individuales, recibe más comentarios en el panel derecho que muestra estadísticas de partición, recuentos de columna, sesgo (con qué uniformidad se distribuyen los datos entre particiones) y curtosis (cuántos picos tienen los datos).
Ordenar por tiempo de procesamiento ayuda a identificar qué fases del flujo de datos tardaron más tiempo.
Para buscar qué transformaciones dentro de cada fase tardaron más tiempo, ordene por tiempo de procesamiento más alto.
Las *filas escritas también se pueden ordenar como una manera de identificar qué flujos dentro del flujo de datos escriben la mayoría de los datos.
Al seleccionar el receptor en la vista del nodo, puede ver el linaje de columna. Hay tres métodos diferentes que las columnas acumulan a lo largo de su flujo de datos para colocarse en el receptor. Son las siguientes:
- Calculado: Use la columna para el procesamiento condicional o dentro de una expresión en el flujo de datos, pero no la coloque en el receptor.
- Derivada: se trata de una columna nueva que ha generado en el flujo, es decir, no estaba en el origen.
- Asignada: la columna procede del origen y usted la está asignando a un campo de receptor.
- Estado del flujo de datos: el estado actual de la ejecución.
- Tiempo de inicio del clúster: la cantidad de tiempo necesaria para adquirir el entorno de proceso de Spark JIT para la ejecución del flujo de datos.
- Número de transformaciones: el número de pasos de transformación que se ejecutan en el flujo

Diferencias entre tiempo total de procesamiento de receptores y tiempo de procesamiento de la transformación
Cada fase de transformación incluye un tiempo total para que se complete, y el tiempo de ejecución de todas las particiones se suma. Al seleccionar el receptor, aparece "Tiempo de procesamiento del receptor". Este valor incluye el total del tiempo de transformación más el tiempo de E/S que se tarda en escribir los datos en el almacén de destino. La diferencia entre el tiempo de procesamiento del receptor y el total de la transformación es el tiempo de E/S para escribir los datos.
También puede ver el tiempo detallado del paso de transformación de cada partición si abre la salida JSON desde la actividad de flujo de datos en la vista de supervisión de la canalización. El archivo JSON contiene el tiempo en milisegundos de cada partición, mientras que la vista de supervisión de la experiencia de usuario es un intervalo agregado de las particiones sumadas:
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
Tiempo de procesamiento del receptor
Cuando seleccione un icono de transformación del receptor en el mapa, el panel deslizante de la derecha muestra un punto de datos adicional denominado "Tiempo de posprocesamiento" en la parte inferior. Esta es la cantidad de tiempo que se dedica a ejecutar el trabajo en el clúster de Spark después de cargar, transformar y escribir los datos. Esta cantidad puede incluir el cierre de grupos de conexiones, el apagado de controladores, la eliminación de archivos, la fusión de archivos, etc. Al realizar acciones en el flujo, como "migrar archivos" y "enviar a un solo archivo", es probable que se muestre un aumento en el valor de tiempo de posprocesamiento.
- Duración de la fase de escritura: el tiempo para escribir los datos en una ubicación de almacenamiento provisional para Synapse SQL.
- Duración de SQL de operación de tabla: el tiempo dedicado a mover datos de tablas temporales a la tabla de destino.
- Duración de SQL previo y posterior: el tiempo empleado en ejecutar comandos SQL previos y posteriores.
- Duración de los comandos previos y posteriores: el tiempo dedicado a ejecutar cualquier operación previa o posterior para el origen o los receptores basados en archivos. Por ejemplo, mover o eliminar archivos después del procesamiento.
- Duración de la combinación: el tiempo empleado en combinar el archivo, los archivos de combinación se usan para los receptores basados en archivos al escribir en un solo archivo o cuando se usa el "nombre de archivo como datos de columna". Si se dedica mucho tiempo a esta métrica, debe evitar el uso de estas opciones.
- Tiempo de la fase: la cantidad total de tiempo empleado en Spark para completar la operación como una fase.
- Almacenamiento provisional temporal estable: nombre de la tabla temporal que usan los flujos de datos para almacenar datos en la base de datos.
Filas de error
La habilitación del control de filas de error en el receptor de flujo de datos se reflejará en la salida de supervisión. Cuando se establece el receptor en "Notificar éxito cuando hay error", la salida de supervisión muestra el número de filas correctas y con error al seleccionar el nodo de supervisión de receptores.

Si selecciona "Notificar error en caso de error", la misma salida se muestra solo en el texto de salida de la supervisión de la actividad. Esto se debe a que la actividad de flujo de datos devuelve un error de ejecución y la vista de supervisión detallada no está disponible.

Iconos de supervisión
Este icono significa que los datos de transformación se almacenaron en caché en el clúster, por lo que los intervalos y la ruta de acceso de ejecución se han tenido en cuenta:

También ve los iconos de círculo verde en la transformación. Representan un recuento del número de receptores en los que fluyen los datos.