Transformaciones de búsqueda en el flujo de datos de asignación
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Los flujos de datos están disponibles en las canalizaciones Azure Data Factory y Azure Synapse. Este artículo se aplica a los flujos de datos de asignación. Si carece de experiencia con las transformaciones, consulte el artículo de introducción Transformación de datos mediante flujos de datos de asignación.
Utilice la transformación búsqueda para hacer referencia a los datos de otro origen en una secuencia de flujo de datos. La transformación búsqueda anexa columnas de los datos coincidentes a los datos de origen.
Una transformación búsqueda es similar a una combinación externa izquierda. Todas las filas del flujo principal existirán en el flujo de salida con columnas adicionales de la secuencia de búsqueda.
Configuración
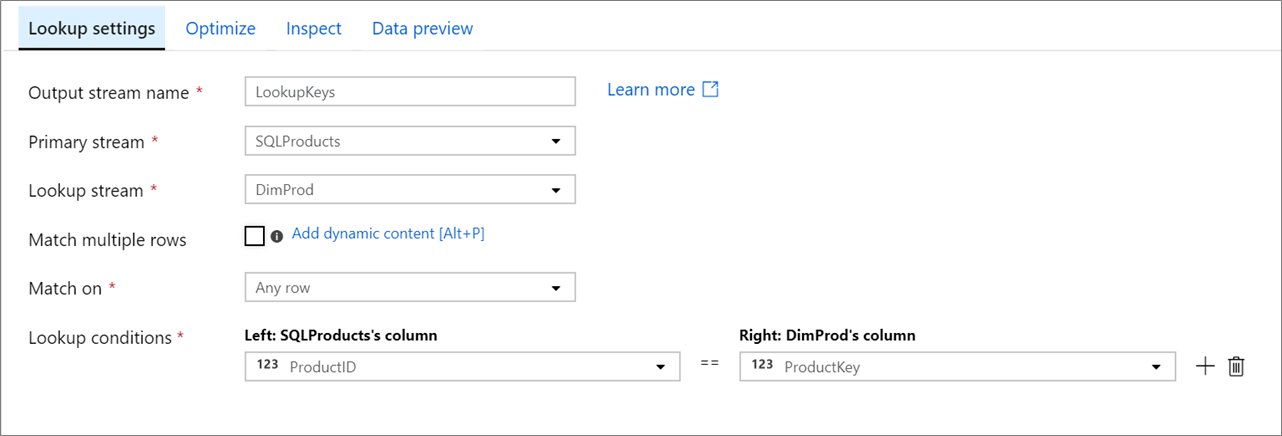
Flujo principal: El flujo de datos entrante. Este flujo es equivalente a la parte izquierda de una combinación.
Secuencia de búsqueda: Los datos que se anexan al flujo principal. Los datos que se agregan están determinados por las condiciones de búsqueda. Este flujo es equivalente a la parte derecha de una combinación.
Coincidencia con varias filas: Si está habilitada, una fila con varias coincidencias en el flujo principal devolverá varias filas. De lo contrario, solo se devolverá una sola fila en función de la condición de coincidencia.
Coincidencia en: solo es visible si no está habilitada la opción "Coincidencia con varias filas". Elija si desea buscar coincidencias en cualquier fila, la primera coincidencia o la última coincidencia. Se recomienda cualquier fila a medida que se ejecuta la más rápida. Si se selecciona la primera o la última fila, se le pedirá que especifique las condiciones de organización.
Condiciones de búsqueda: Elija las columnas en las que desea buscar coincidencias. Si se cumple la condición de igualdad, las filas se considerarán una coincidencia. Mantenga el puntero y seleccione 'columna calculada' para extraer un valor mediante el lenguaje de expresiones de flujo de datos.
Todas las columnas de ambas secuencias se incluyen en los datos de salida. Para quitar las columnas duplicadas o no deseadas, agregue una transformación de selección después de la transformación búsqueda. También se pueden quitar o cambiar el nombre de las columnas en una transformación de receptor.
Combinaciones no equivalentes
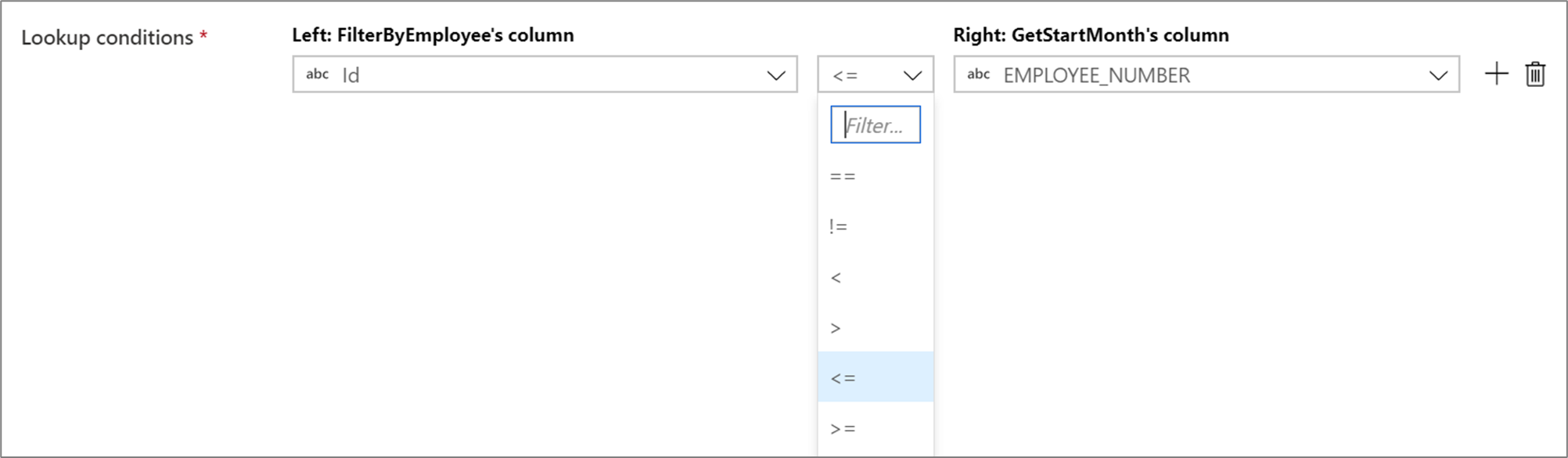
Para usar un operador condicional como no es igual a (! =) o mayor que (>) en las condiciones de búsqueda, cambie la lista desplegable de operadores entre las dos columnas. Las combinaciones no equivalentes requieren que al menos uno de los dos flujos se difundan mediante la retransmisión fija en la pestaña Optimizar.
Analizar filas coincidentes
Después de la transformación de búsqueda, se puede usar la función isMatch() para ver si la búsqueda coincide con las filas individuales.
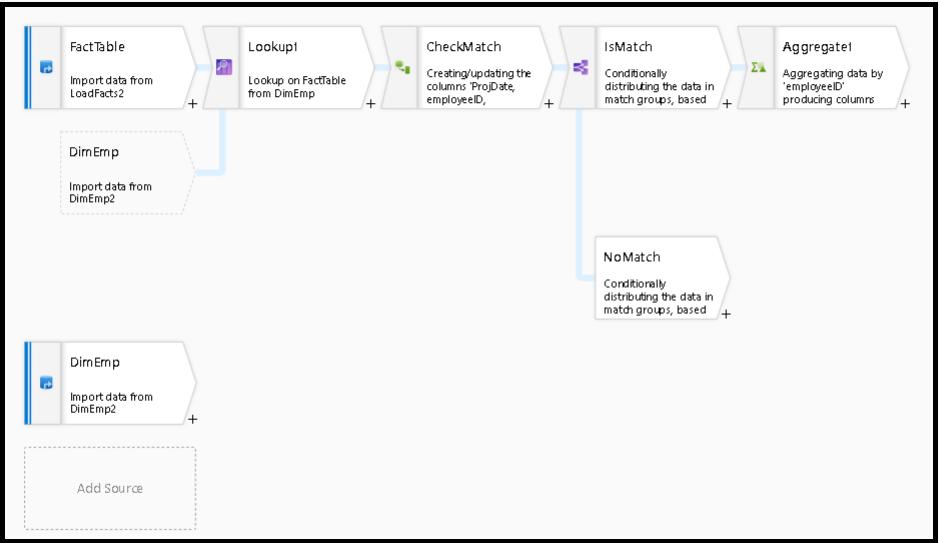
Un ejemplo de este patrón es usar la transformación división condicional para dividirla en la función isMatch(). En el ejemplo anterior, las filas coincidentes pasan por el flujo anterior y las filas no coincidentes fluyen a través del flujo de NoMatch.
Probar condiciones de búsqueda
Cuando pruebe la transformación de búsqueda con la vista previa de datos en modo de depuración, use un conjunto pequeño de datos conocidos. Cuando se realiza un muestreo de filas de un conjunto de filas grande, no se puede predecir qué filas y claves se leerán para las pruebas. El resultado es no determinista, lo que significa que las condiciones de combinación pueden no devolver ninguna coincidencia.
Optimización de difusión
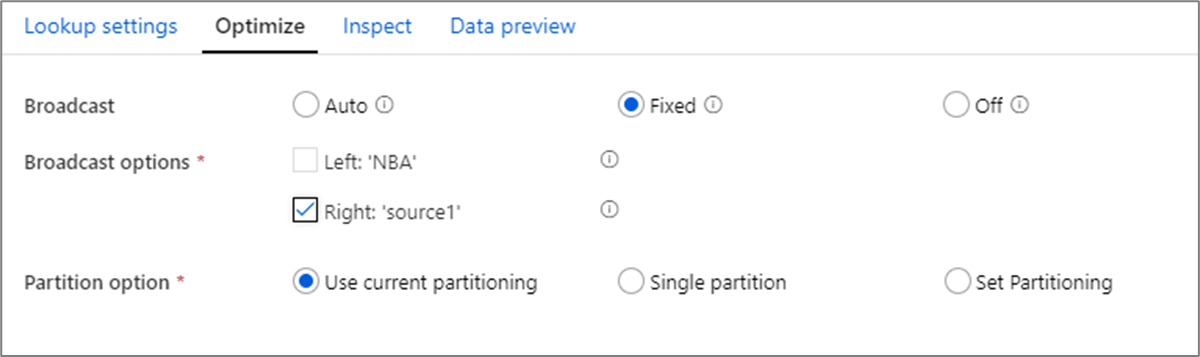
En las combinaciones, búsquedas y transformaciones Existe, si uno o ambos flujos de datos caben en la memoria del nodo de trabajo, puede optimizar el rendimiento al habilitar la opción Difusión. De forma predeterminada, el motor de Spark decidirá automáticamente si difundir o no una parte. Para elegir manualmente la parte que se va a difundir, seleccione Fijo.
No se recomienda deshabilitar la difusión a través de la opción Desactivado a menos que las combinaciones experimenten errores de tiempo de espera.
Búsqueda en caché
Si está realizando varias búsquedas más pequeñas en el mismo origen, un receptor y una búsqueda en caché puede ser un caso de uso mejor que la transformación de la búsqueda. Algunos ejemplos comunes en los que un receptor de caché puede ser mejor son buscar un valor máximo en un almacén de datos y buscar coincidencias de códigos de error en una base de datos de mensajes de error. Para obtener más información, consulte los temas sobre los receptores de caché y las búsquedas almacenadas en caché.
Script de flujo de datos
Sintaxis
<leftStream>, <rightStream>
lookup(
<lookupConditionExpression>,
multiple: { true | false },
pickup: { 'first' | 'last' | 'any' }, ## Only required if false is selected for multiple
{ desc | asc }( <sortColumn>, { true | false }), ## Only required if 'first' or 'last' is selected. true/false determines whether to put nulls first
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <lookupTransformationName>
Ejemplo
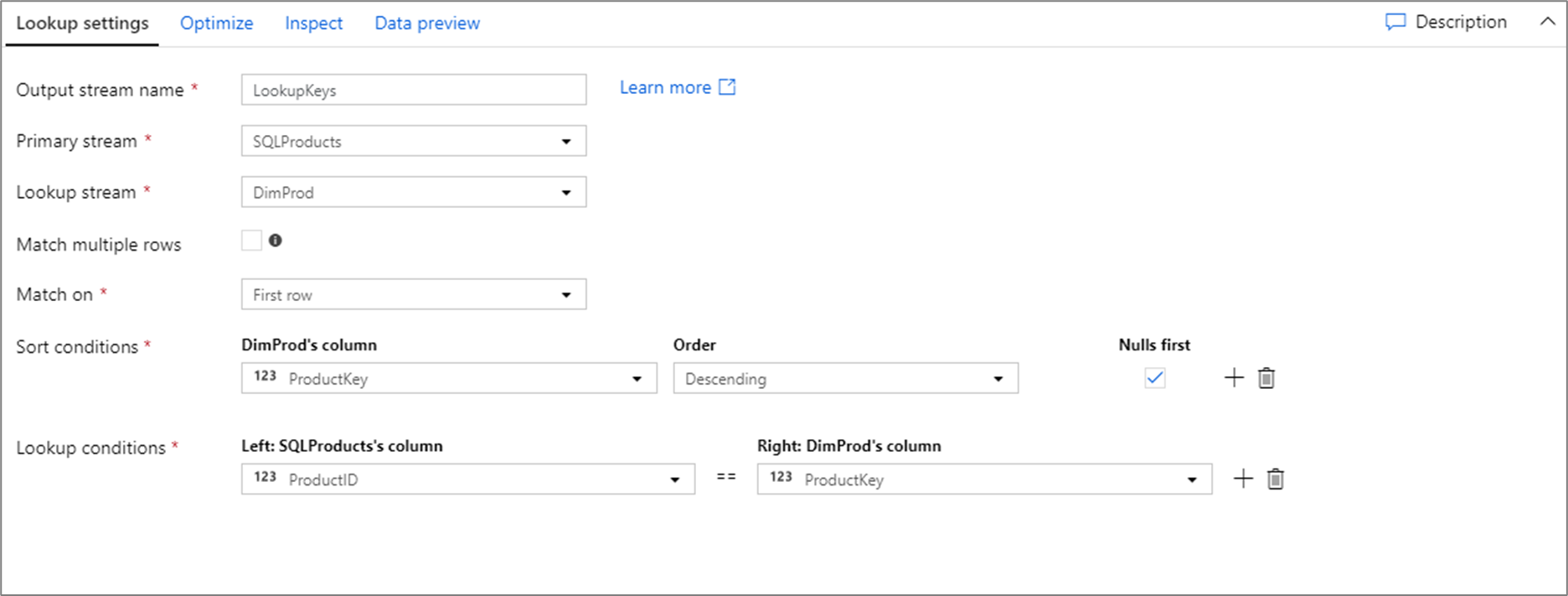
El script de flujo de datos para la configuración de búsqueda anterior se encuentra en el siguiente fragmento de código.
SQLProducts, DimProd lookup(ProductID == ProductKey,
multiple: false,
pickup: 'first',
asc(ProductKey, true),
broadcast: 'auto')~> LookupKeys
Contenido relacionado
- Las transformaciones combinación y existencia toman múltiples entradas de flujo
- Use una transformación de división condicional con
isMatch()para dividir las filas en valores coincidentes y no coincidentes
Comentaris
Properament: al llarg del 2024 eliminarem gradualment GitHub Issues com a mecanisme de retroalimentació del contingut i el substituirem per un nou sistema de retroalimentació. Per obtenir més informació, consulteu: https://aka.ms/ContentUserFeedback.
Envieu i consulteu els comentaris de