Copia masiva de varias tablas mediante Azure Data Factory en Azure Portal
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga más información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial se muestra cómo puede copiar varias tablas de Azure SQL Database a Azure Synapse Analytics. Además, puede aplicar el mismo patrón en otros escenarios de copia. Por ejemplo, para copiar tablas de SQL Server u Oracle a Azure SQL Database, Azure Synapse Analytics o Azure Blob, o bien para copiar diferentes rutas de acceso de tablas de blob a tablas de Azure SQL Database.
Nota
Si no está familiarizado con Azure Data Factory, consulte Introducción a Azure Data Factory.
A grandes rasgos, este tutorial incluye los pasos siguientes:
- Creación de una factoría de datos.
- Creación de los servicios vinculados de Azure SQL Database, Azure Synapse Analytics y Azure Storage.
- Creación de los conjuntos de datos de Azure SQL Database y Azure Synapse Analytics.
- Cree una canalización para buscar las tablas que se deben copiar y otra canalización para realizar la operación de copia real.
- Inicio de la ejecución de una canalización.
- Supervisión de las ejecuciones de canalización y actividad.
En este tutorial se usa Azure Portal. Para obtener información sobre el uso de otras herramientas o SDK para crear una factoría de datos, consulte los inicios rápidos.
Flujo de trabajo de un extremo a otro
En este escenario, hay una serie de tablas de Azure SQL Database que desea copiar a Azure Synapse Analytics. Esta es la secuencia lógica de pasos del flujo de trabajo que se realiza en las canalizaciones:

- La primera canalización busca la lista de tablas que debe copiarse en los almacenes de datos del receptor. También puede mantener una tabla de metadatos que muestre todas las tablas que se deben copiar en el almacén de datos receptor. A continuación, la canalización desencadena otra canalización, que itera en todas las tablas de la base de datos y realiza la operación de copia de datos.
- La segunda canalización realiza la copia real. Toma la lista de tablas como un parámetro. Para cada tabla de la lista, copie la tabla específica de Azure SQL Database a la tabla correspondiente de Azure Synapse Analytics con la copia almacenada provisionalmente mediante Blob Storage y PolyBase a fin de obtener el mejor rendimiento. En este ejemplo, la primera canalización pasa la lista de tablas como un valor para el parámetro.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
- Cuenta de Azure Storage. La cuenta de Azure Storage se usa como almacenamiento de blobs de almacenamiento provisional en la operación de copia masiva.
- Azure SQL Database. Esta base de datos contiene los datos de origen. Cree una base de datos en SQL Database con los datos de ejemplo de Adventure Works LT siguiendo el artículo Creación de una base de datos en Azure SQL Database. En este tutorial se copiarán todas las tablas de esta base de datos de ejemplo a una de Azure Synapse Analytics.
- Azure Synapse Analytics. Este almacén de datos contiene los datos que se copian de SQL Database. Si no tiene un área de trabajo de Azure Synapse Analytics, consulte el artículo Introducción a Azure Synapse Analytics para conocer los pasos para crear una.
Servicios de Azure para acceder a SQL Server
Para SQL Database y Azure Synapse Analytics, permita que los servicios de Azure accedan a SQL Server. Asegúrese de que la opción Permitir que los servicios y recursos de Azure accedan a este servidor esté activada para el servidor. Esta configuración permite al servicio Data Factory leer datos de Azure SQL Database y escribir datos en Azure Synapse Analytics.
Para comprobar y activar esta configuración, vaya al servidor > Seguridad > Firewalls y redes virtuales, y >establezca la opción Permitir que los servicios y recursos de Azure accedan a este servidor en Activada.
Crear una factoría de datos
Inicie el explorador web Microsoft Edge o Google Chrome. Actualmente, la interfaz de usuario de Data Factory solo se admite en los exploradores web Microsoft Edge y Google Chrome.
Vaya a Azure Portal.
A la izquierda del menú de Azure Portal, seleccione Crear un recurso>Integración>Data Factory.
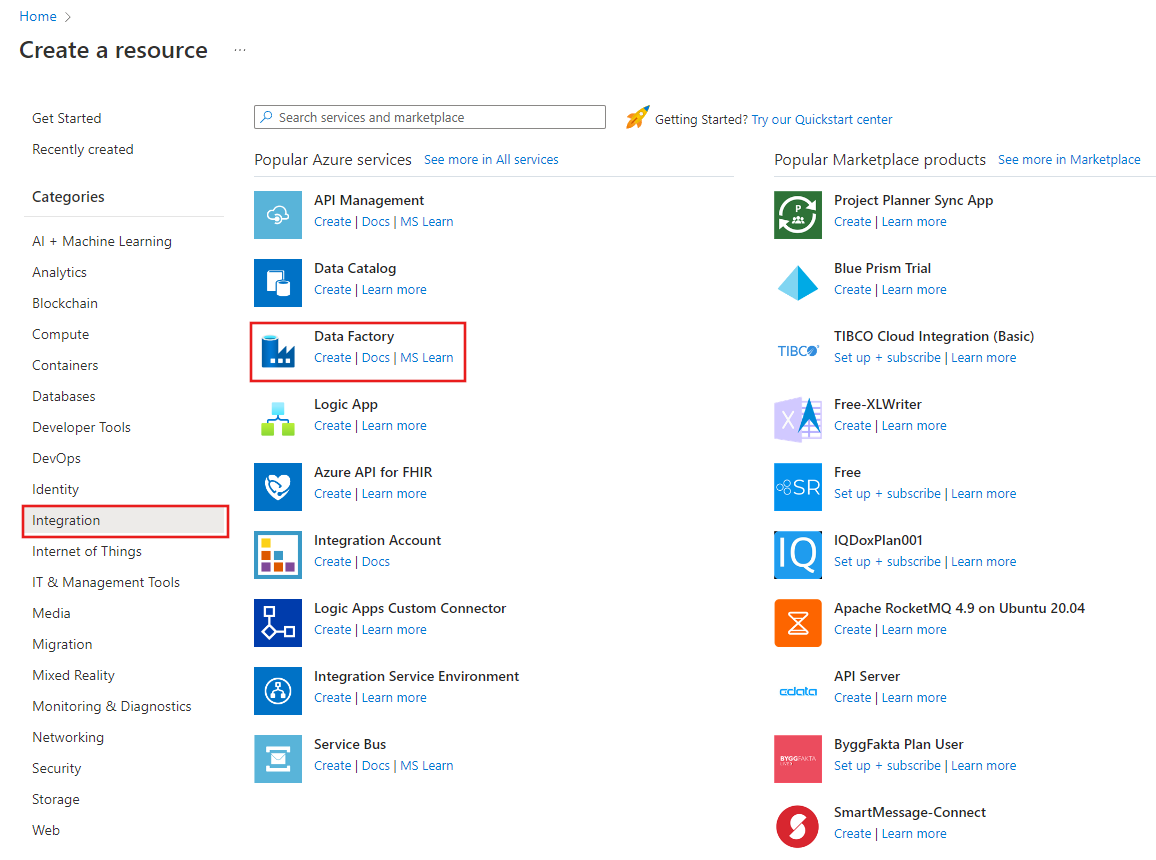
En la página Nueva factoría de datos, escriba ADFTutorialBulkCopyDF como nombre.
El nombre de la instancia de Azure Data Factory debe ser único de forma global. Si ve el siguiente error en el campo del nombre, cambie el nombre de la factoría de datos (por ejemplo, yournameADFTutorialBulkCopyDF). Consulte el artículo Azure Data Factory: reglas de nomenclatura para conocer las reglas de nomenclatura de los artefactos de Data Factory.
Data factory name "ADFTutorialBulkCopyDF" is not availableSeleccione la suscripción de Azure donde desea crear la factoría de datos.
Para el grupo de recursos, realice uno de los siguientes pasos:
Seleccione en primer lugar Usar existentey después un grupo de recursos de la lista desplegable.
Seleccione Crear nuevoy escriba el nombre de un grupo de recursos.
Para obtener más información sobre los grupos de recursos, consulte Uso de grupos de recursos para administrar los recursos de Azure.
Seleccione V2 para la versión.
Seleccione la ubicación de Data Factory. Para una lista de las regiones de Azure en las que Data Factory está disponible actualmente, seleccione las regiones que le interesen en la página siguiente y expanda Análisis para poder encontrar Data Factory: Productos disponibles por región. Los almacenes de datos (Azure Storage, Azure SQL Database, etc.) y los procesos (HDInsight, etc.) que usa la factoría de datos pueden encontrarse en otras regiones.
Haga clic en Crear.
Una vez que finalice la creación, seleccione Ir al recurso para ir a la página de Data Factory.
Seleccione Abrir en el icono Abrir Azure Data Factory Studio para iniciar la aplicación de interfaz de usuario de Data Factory en una pestaña independiente.
Crear servicios vinculados
Los servicios vinculados se crean para vincular los almacenes de datos y los procesos con una factoría de datos. Un servicio vinculado tiene la información de conexión que usa el servicio Data Factory para conectarse al almacén de datos en el runtime.
En este tutorial se vincularán los almacenes de datos de Azure SQL Database, Azure Synapse Analytics y Azure Blob Storage a la factoría de datos. El almacén de datos de origen es el de Azure SQL Database. Azure Synapse Analytics es el almacén de datos receptor o de destino. Azure Blob Storage sirve para almacenar provisionalmente los datos antes de cargarlos en Azure Synapse Analytics mediante PolyBase.
Creación del servicio vinculado de Azure SQL Database de origen
En este paso, creará un servicio vinculado para vincular la base de datos de Azure SQL Database con la factoría de datos.
Abra la pestaña Administrar en el panel izquierdo.
En la página Servicios vinculados, seleccione +Nuevo para crear un nuevo servicio vinculado.
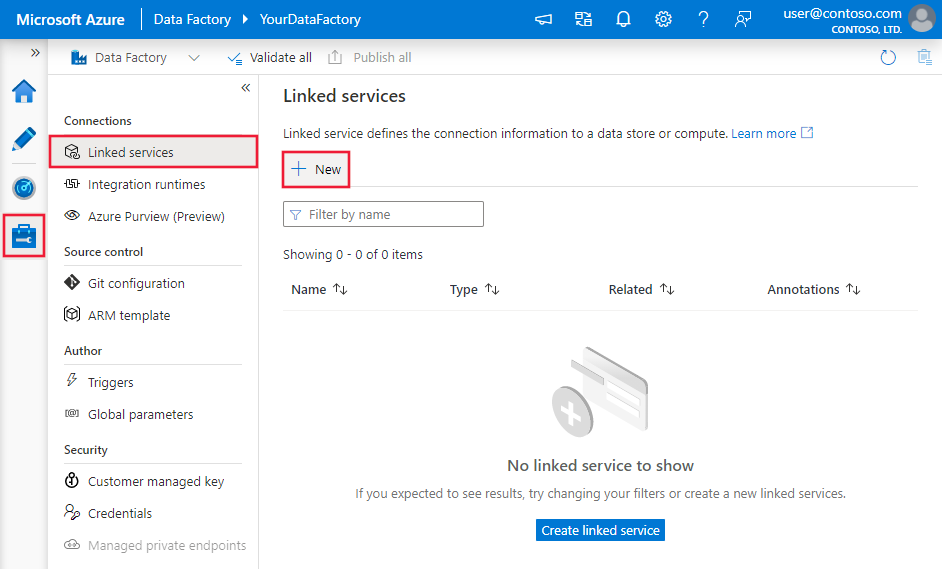
En la ventana New Linked Service (Nuevo servicio vinculado), seleccione Azure SQL Database y haga clic en Continue (Continuar).
En la ventana New Linked Service (Azure SQL Database) [Nuevo servicio vinculado (Azure SQL Database)], realice los siguientes pasos:
a. Escriba AzureSqlDatabaseLinkedService en Name (Nombre).
b. Seleccione el servidor nombre de servidor
c. En Database name (Nombre de base de datos), seleccione su base de datos.
d. Escriba el nombre del usuario para conectarse a la base de datos.
e. Escriba la contraseña del usuario.
f. Para probar la conexión a la base de datos con la información indicada, haga clic en Test connection (Prueba de conexión).
g. Haga clic en Create (Crear) para guardar el servicio vinculado.
Creación del servicio vinculado receptor de Azure Synapse Analytics
En la pestaña Connections (Conexiones), haga clic en + New (+ Nuevo) en la barra de herramientas de nuevo.
En la ventana Nuevo servicio vinculado, seleccione Azure Synapse Analytics y haga clic en Continuar.
En la ventana New Linked Service (Azure Synapse Analytics) (Nuevo servicio vinculado [Azure Synapse Analytics]), siga estos pasos:
a. Escriba AzureSqlDWLinkedService en Name (Nombre).
b. Seleccione el servidor nombre de servidor
c. En Database name (Nombre de base de datos), seleccione su base de datos.
d. En User name (Nombre de usuario), escriba un nombre de usuario para conectarse a la base de datos.
e. En Password, escriba la contraseña del usuario.
f. Para probar la conexión a la base de datos con la información indicada, haga clic en Test connection (Prueba de conexión).
g. Haga clic en Crear.
Creación del servicio vinculado de Azure Storage de almacenamiento provisional
En este tutorial, debe usar Azure Blob Storage como un área de almacenamiento provisional para habilitar PolyBase a fin de mejorar el rendimiento de copia.
En la pestaña Connections (Conexiones), haga clic en + New (+ Nuevo) en la barra de herramientas de nuevo.
En la ventana New Linked Service (Nuevo servicio vinculado), seleccione Azure Blob Storage y haga clic en Continue (Continuar).
En la ventana New Linked Service (Azure Blob Storage) [Nuevo servicio vinculado (Azure Blob Storage)], realice los siguientes pasos:
a. Escriba AzureStorageLinkedService en Name (Nombre).
b. Seleccione la cuenta de Azure Storage de Storage account name (Nombre de la cuenta de Storage).c. Haga clic en Crear.
Creación de conjuntos de datos
En este tutorial creará los conjuntos de datos de origen y recepción, que especifican la ubicación de almacenamiento de los datos.
El conjunto de datos de entrada AzureSqlDatabaseDataset hace referencia a AzureSqlDatabaseLinkedService. El servicio vinculado especifica la cadena de conexión para conectarse a la base de datos. El conjunto de datos especifica el nombre de la base de datos y la tabla que contienen los datos de origen.
El conjunto de datos de salida AzureSqlDWDataset hace referencia a AzureSqlDWLinkedService. El servicio vinculado especifica la cadena de conexión para conectarse a Azure Synapse Analytics. El conjunto de datos especifica la base de datos y la tabla donde se copian los datos.
En este tutorial, las tablas de origen y destino SQL no están codificadas en las definiciones de los conjuntos de datos. En su lugar, la actividad ForEach (Para cada uno) pasa el nombre de la tabla en tiempo de ejecución a la actividad de copia.
Creación de un conjunto de datos de la instancia de SQL Database de origen
Seleccione la pestaña Autor en el panel izquierdo.
Seleccione el signo + (Más) en el panel izquierdo y, después, seleccione Conjunto de datos.

En la ventana New Dataset (Nuevo conjunto de datos), seleccione Azure SQL Database y luego seleccione Continue (Continuar).
En la ventana Set properties (Establecer propiedades), en Name (Nombre), escriba AzureSqlDatabaseDataset. En Linked service (Servicio vinculado), seleccione AzureSqlDatabaseLinkedService. A continuación, haga clic en Aceptar.
Cambie a la pestaña Connection (Conexión) y seleccione cualquier tabla para Table (Tabla). Esta tabla es ficticia. Especifique una consulta en el conjunto de datos de origen al crear una canalización. La consulta se utilizará para extraer datos de la base de datos. Como alternativa, puede hacer clic en la casilla Edit (Editar) y escribir dbo.dummyName como nombre de la tabla.
Creación de un conjunto de datos para la instancia receptora de Azure Synapse Analytics
Haga clic en el signo + (más) en el panel izquierdo y en Dataset (Conjunto de datos).
En la ventana New Dataset (Nuevo conjunto de datos), seleccione Azure Synapse Analytics (Azure Synapse Analytics ) y haga clic en Continue (Continuar).
En la ventana Set properties (Establecer propiedades), en Name (Nombre), escriba AzureSqlDWDataset. En Linked service (Servicio vinculado), seleccione AzureSqlDWLinkedService. A continuación, haga clic en Aceptar.
Vaya a la pestaña Parameters (Parámetros), haga clic en + New (+ Nuevo) y escriba DWTableName como nombre del parámetro. Haga clic de nuevo en + New (+ Nuevo) y escriba DWSchema como nombre del parámetro. Si copia y pega este nombre desde la página, asegúrese de que no haya ningún carácter de espacio final al final de DWTableName y DWSchema.
Cambie a la pestaña Connection (Conexión),
En Table (Tabla), active la opción Edit (Editar). Seleccione el primer cuadro de entrada y haga clic en el vínculo Add dynamic content (Agregar contenido dinámico) debajo. En la página Add Dynamic Content (Agregar contenido dinámico), haga clic en DWSchema en Parameters (Parámetros), que rellena automáticamente el cuadro de texto de expresión superior
@dataset().DWSchemay, luego, haga clic en Finish (Finalizar).
Seleccione el segundo cuadro de entrada y haga clic en el vínculo Add dynamic content (Agregar contenido dinámico). En la página Add Dynamic Content (Agregar contenido dinámico), haga clic en DWTAbleName en Parameters (Parámetros), que rellena automáticamente el cuadro de texto de expresión superior
@dataset().DWTableNamey, luego, haga clic en Finish (Finalizar).La propiedad tableName del conjunto de datos se establece en los valores que se pasan como argumentos de los parámetros DWTableName y DWTableName. La actividad ForEach (Para cada uno) recorre en iteración una lista de tablas y las pasa una a una a la actividad de copia.
Creación de canalizaciones
En este tutorial, creará dos canalizaciones: IterateAndCopySQLTables y GetTableListAndTriggerCopyData.
La canalización GetTableListAndTriggerCopyData lleva a cabo dos acciones:
- Busca la tabla del sistema de Azure SQL Database para obtener la lista de tablas que se copiará.
- Desencadena la canalización IterateAndCopySQLTables para realizar la copia de datos real.
La canalización IterateAndCopySQLTables toma una lista de tablas como parámetro. Para cada tabla de la lista, copia los datos de la tabla de Azure SQL Database a Azure Synapse Analytics mediante la copia almacenada provisionalmente y PolyBase.
Creación de la canalización IterateAndCopySQLTables
En el panel izquierdo, haga clic en el signo + (más) y en Pipeline (Canalización).

En el panel General, en Propiedades, especifique IterateAndCopySQLTables en Nombre. A continuación, contraiga el panel; para ello, haga clic en el icono Propiedades en la esquina superior derecha.
Cambie a la pestaña Parameters (Parámetros) y realice las siguientes acciones:
a. Haga clic en + Nuevo.
b. Escriba tableList en el parámetro Name (Nombre).
c. Seleccione Matriz como tipo.
En el cuadro de herramientas Activities (Actividades), expanda Iteration & Conditions (Iteraciones y condiciones), arrastre la actividad ForEach (Para cada uno) y colóquela en la superficie del diseñador de canalizaciones. También puede buscar actividades en el cuadro de herramientas Activities (Actividades).
a. En la pestaña General de la parte inferior escriba IterateSQLTables como Nombre.
b. Cambie a la pestaña Settings (Configuración), haga clic en el cuadro de entrada Items (Elementos) y, finalmente, haga clic en el vínculo Add dynamic content (Agregar contenido dinámico) que aparece a continuación.
c. En la página Add dynamic content (Agregar contenido dinámico), contraiga las secciones System Variables (Variables del sistema) y Functions (Funciones), y haga clic en la tableList (Lista de tabla) bajo Parameters (Parámetros), que rellenará automáticamente el cuadro de texto de expresiones de la parte superior como
@pipeline().parameter.tableList. Haga clic en Finalizar.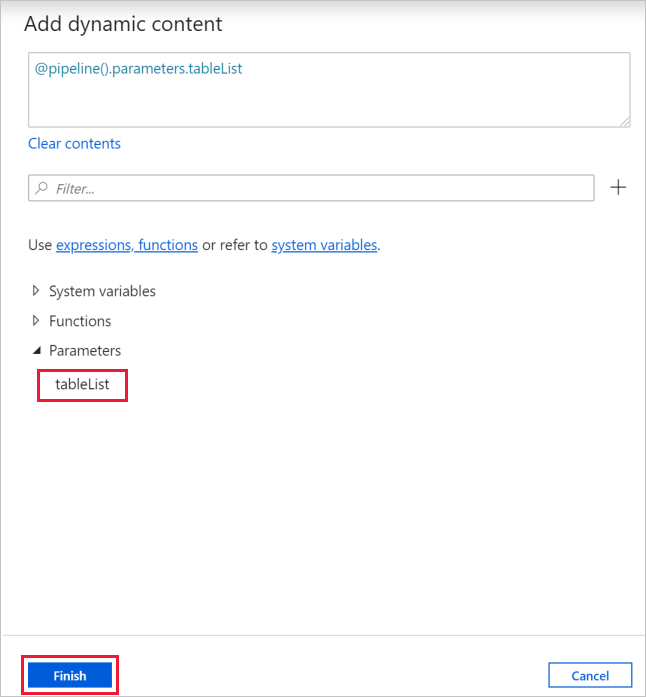
d. Cambie a la pestaña Activities (Actividades), haga clic en el icono de lápiz para agregar una actividad secundaria a la actividad ForEach.

En el cuadro de herramientas Activities (Actividades), expanda Move & Transfer (Mover y transferir), arrastre la actividad Copy data (Copiar datos) y colóquela en la superficie del diseñador de canalizaciones. Tenga en cuenta el menú de la ruta de navegación de la parte superior. IterateAndCopySQLTable es el nombre de la canalización y IterateSQLTables es el nombre de la actividad ForEach. El diseñador está en el ámbito de la actividad. Para volver al editor de canalización desde el editor de la actividad ForEach (Para cada uno), puede hacer clic en el vínculo del menú de la ruta de navegación.

Cambie a la pestaña Source (Origen) y realice los pasos siguientes:
Seleccione AzureSqlDatabaseDataset en Source Dataset (Conjunto de datos de origen).
Seleccione la opción Query (Consulta) en Use query (Usar consulta).
Haga clic en el cuadro de entrada Query (Consulta) -> seleccione el vínculo Agregar contenido dinámico que aparece a continuación -> escriba la siguiente expresión para Query (Consulta) -> seleccione Finalizar.
SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]
Cambie a la pestaña Sink (Receptor) y realice los pasos siguientes:
Seleccione AzureSqlDWDataset en Sink Dataset (Conjunto de datos receptor).
Haga clic en el cuadro de entrada VALUE del parámetro DWTableName -> seleccione Add dynamic content (Agregar contenido dinámico) que aparece a continuación, escriba la expresión
@item().TABLE_NAMEcomo script, -> seleccione Finish (Finalizar).Haga clic en el cuadro de entrada de VALUE del parámetro DWSchema,> seleccione Add dynamic content (Agregar contenido dinámico) a continuación, escriba la expresión
@item().TABLE_SCHEMAcomo script > seleccione Finish (Finalizar).Como método de copia, seleccione PolyBase.
Desactive la opción Use type default (Usar tipo predeterminado).
En la opción de tabla, el valor predeterminado es "none". Si no tiene tablas creadas previamente en la instancia de Azure Synapse Analytics del receptor, habilite la opción Auto create table (Crear tabla automáticamente) y la actividad de copia creará automáticamente las tablas en función de los datos de origen. Para más información, consulte Creación automática de tablas de receptores.
Haga clic en el cuadro de entrada Script previo a la copia ->> seleccione el vínculo Agregar contenido dinámico> que aparece a continuación ->> escriba la siguiente expresión como script -> seleccione Finalizar.
IF EXISTS (SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]) TRUNCATE TABLE [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]
Cambie a la pestaña Settings (Configuración) y realice los pasos siguientes:
- Active la casilla de Enable Staging (Habilitar almacenamiento provisional).
- Seleccione AzureStorageLinkedService como Store Account Linked Service (Servicio vinculado a la cuenta de almacenamiento).
Para comprobar la configuración de la canalización, haga clic en Validar en la barra de herramientas de la canalización. Asegúrese de que no haya errores de validación. Para cerrar el informe de validación de la canalización, haga clic en los corchetes angulares dobles >>.
Creación de la canalización GetTableListAndTriggerCopyData
Esta canalización realiza dos acciones:
- Busca la tabla del sistema de Azure SQL Database para obtener la lista de tablas que se copiará.
- Desencadena la canalización "IterateAndCopySQLTables" para realizar la copia de datos real.
Estos son los pasos para crear la canalización:
En el panel izquierdo, haga clic en el signo + (más) y en Pipeline (Canalización).
En el panel General, en Properties (Propiedades), cambie el nombre de la canalización por GetTableListAndTriggerCopyData.
En el cuadro de herramientas Activities (Actividades), expanda General (General), arrastre la actividad Lookup (Búsqueda) a la superficie del diseñador de canalizaciones y realice los pasos siguientes:
- Escriba LookupTableList en Name (Nombre).
- En Description (Descripción), escriba Retrieve the table list from my database (Recuperar la lista de tablas de mi base de datos).
Cambie a la pestaña Settings (Configuración) y realice los pasos siguientes:
Seleccione AzureSqlDatabaseDataset en Source Dataset (Conjunto de datos de origen).
Seleccione Query (Consulta) en Use query (Usar consulta).
Escriba la siguiente consulta SQL en el campo Query (Consulta).
SELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.TABLES WHERE TABLE_TYPE = 'BASE TABLE' and TABLE_SCHEMA = 'SalesLT' and TABLE_NAME <> 'ProductModel'Desactive la casilla del campo First row only (Solo la primera fila).

Arrastre la actividad Execute Pipeline (Ejecutar canalización) del cuadro de herramientas de actividades y colóquela en la superficie del diseñador de canalizaciones; después, establezca el nombre en TriggerCopy.
Para conectar la actividad Lookup (Búsqueda) a la actividad Execute Pipeline (Ejecutar canalización), arrastre el cuadro verde vinculado a la actividad de búsqueda a la izquierda de la actividad Execute Pipeline (Ejecución de canalización).

Cambie a la pestaña Settings (Configuración) de la actividad Execute Pipeline (Ejecutar canalización) y realice los pasos siguientes:
Seleccione IterateAndCopySQLTables en Invoked pipeline (Canalización invocada).
Desactive la casilla Wait on completion (Esperar a que se complete).
En la sección Parameters (Parámetros), haga clic en el cuadro de entrada en VALUE > seleccione Add dynamic content (Agregar contenido dinámico) a continuación, escriba > como valor del nombre de tabla
@activity('LookupTableList').output.valueseleccione >Finish(Finalizar). Estamos configurando la lista de resultados de la actividad de búsqueda como entrada de la segunda canalización. La lista de resultados contiene la lista de tablas cuyos datos deben copiarse en el destino.
Para comprobar la canalización, haga clic en Validate (Comprobar) en la barra de herramientas. Confirme que no haya errores de comprobación. Para cerrar Pipeline Validation Report (Informe de comprobación de la canalización), haga clic en >>.
Para publicar entidades (conjuntos de datos, canalizaciones, etc.) en el servicio Data Factory, haga clic en Publicar todo en la parte superior de la ventana. Espere hasta que la publicación se realice correctamente.
Desencadenamiento de una ejecución de la canalización
Vaya a la canalización GetTableListAndTriggerCopyData, haga clic en Add Trigger (Agregar desencadenador) y haga clic en Trigger Now (Desencadenar ahora).
Confirme la ejecución en la página Pipeline run (Ejecución de canalización) y, a continuación, seleccione Finish (Finalizar).
Supervisión de la ejecución de la canalización
Vaya a la pestaña Monitor (Supervisar). Haga clic en Refresh (Actualizar) hasta que vea las ejecuciones de las canalizaciones de la solución. Continúe la actualización de la lista hasta que vea el estado Succeeded (Correcto).
Para ver las ejecuciones de actividad asociadas a la canalización GetTableListAndTriggerCopyData, haga clic en el vínculo de nombre de canalización de esa canalización. Debería ver dos ejecuciones de actividad para esta ejecución de canalización.

Para ver la salida de la actividad Lookup (Búsqueda), haga clic en el vínculo Output (Salida) junto a la actividad en la columna ACTIVITY NAME (NOMBRE DE ACTIVIDAD). La ventana Output (Salida) se puede maximizar y restaurar. Después de la revisión, haga clic en la X para cerrar la ventana Output (Salida).
{ "count": 9, "value": [ { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Customer" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Product" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductModelProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductCategory" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Address" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "CustomerAddress" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderDetail" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderHeader" } ], "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US)", "effectiveIntegrationRuntimes": [ { "name": "DefaultIntegrationRuntime", "type": "Managed", "location": "East US", "billedDuration": 0, "nodes": null } ] }Para volver a la vista Pipeline Runs (Ejecuciones de canalización), haga clic en el vínculo All Pipeline runs (Todas las ejecuciones de canalización) en la parte superior del menú de la ruta de navegación. Haga clic en el vínculo IterateAndCopySQLTables, bajo la columna PIPELINE NAME (NOMBRE DE CANALIZACIÓN), para ver las ejecuciones de actividad de la canalización. Tenga en cuenta que hay una ejecución de la actividad Copy (Copiar) para cada tabla de la salida de la actividad Lookup (Búsqueda).
Confirme que los datos se han copiado en la instancia de destino de Azure Synapse Analytics que ha usado en este tutorial.
Contenido relacionado
En este tutorial, realizó los pasos siguientes:
- Creación de una factoría de datos.
- Creación de los servicios vinculados de Azure SQL Database, Azure Synapse Analytics y Azure Storage.
- Creación de los conjuntos de datos de Azure SQL Database y Azure Synapse Analytics.
- Cree una canalización para buscar las tablas que se deben copiar y otra canalización para realizar la operación de copia real.
- Inicio de la ejecución de una canalización.
- Supervisión de las ejecuciones de canalización y actividad.
Vaya al tutorial siguiente para obtener información sobre cómo copiar datos de forma incremental de un origen a un destino: