Nota
L'accés a aquesta pàgina requereix autorització. Pots provar d'iniciar sessió o canviar de directori.
L'accés a aquesta pàgina requereix autorització. Pots provar de canviar directoris.
Nota
En esta página se usan ejemplos JSON de definiciones de directiva. El nuevo formulario de directiva ofusca la mayoría de las definiciones de directiva JSON mediante menús desplegables y otros elementos de la interfaz de usuario. Las reglas de directiva y la lógica siguen siendo las mismas, pero los usuarios pueden configurar definiciones sin escribir código JSON. Si no desea usar el nuevo formulario, puede desactivar la configuración Nuevo formulario en la parte superior de la página de directiva.
Esta página es una referencia para las definiciones de directiva de proceso, incluida una lista de atributos de directiva disponibles y tipos de limitación. También hay directivas de ejemplo a las que puede hacer referencia para casos de uso comunes.
¿Qué son las definiciones de directiva?
Las definiciones de directiva son reglas de directiva individuales expresadas en JSON.
Una definición puede agregar una regla a cualquiera de los atributos controlados con la API de clústeres de . Por ejemplo, estas definiciones establecen un tiempo de autoterminación predeterminado, prohíben a los usuarios usar grupos y aplican el uso de Photon:
{
"autotermination_minutes": {
"type": "unlimited",
"defaultValue": 4320,
"isOptional": true
},
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"runtime_engine": {
"type": "fixed",
"value": "PHOTON",
"hidden": true
}
}
Solo puede haber una limitación por atributo. La ruta de acceso de un atributo refleja el nombre del atributo de API. Para atributos anidados, la ruta de acceso concatena los nombres de los atributos anidados mediante puntos. Los atributos que no están definidos en una definición de directiva no se limitarán.
Configuración de definiciones de directiva mediante el nuevo formulario de directiva
El nuevo formulario de directiva permite configurar definiciones de directiva mediante menús desplegables y otros elementos de la interfaz de usuario. Esto significa que los administradores pueden escribir directivas sin tener que aprender ni hacer referencia a la sintaxis de la directiva.
Las definiciones de directiva JSON todavía se admiten en el nuevo formulario. Se pueden agregar al campo JSON personalizado en Opciones avanzadas.
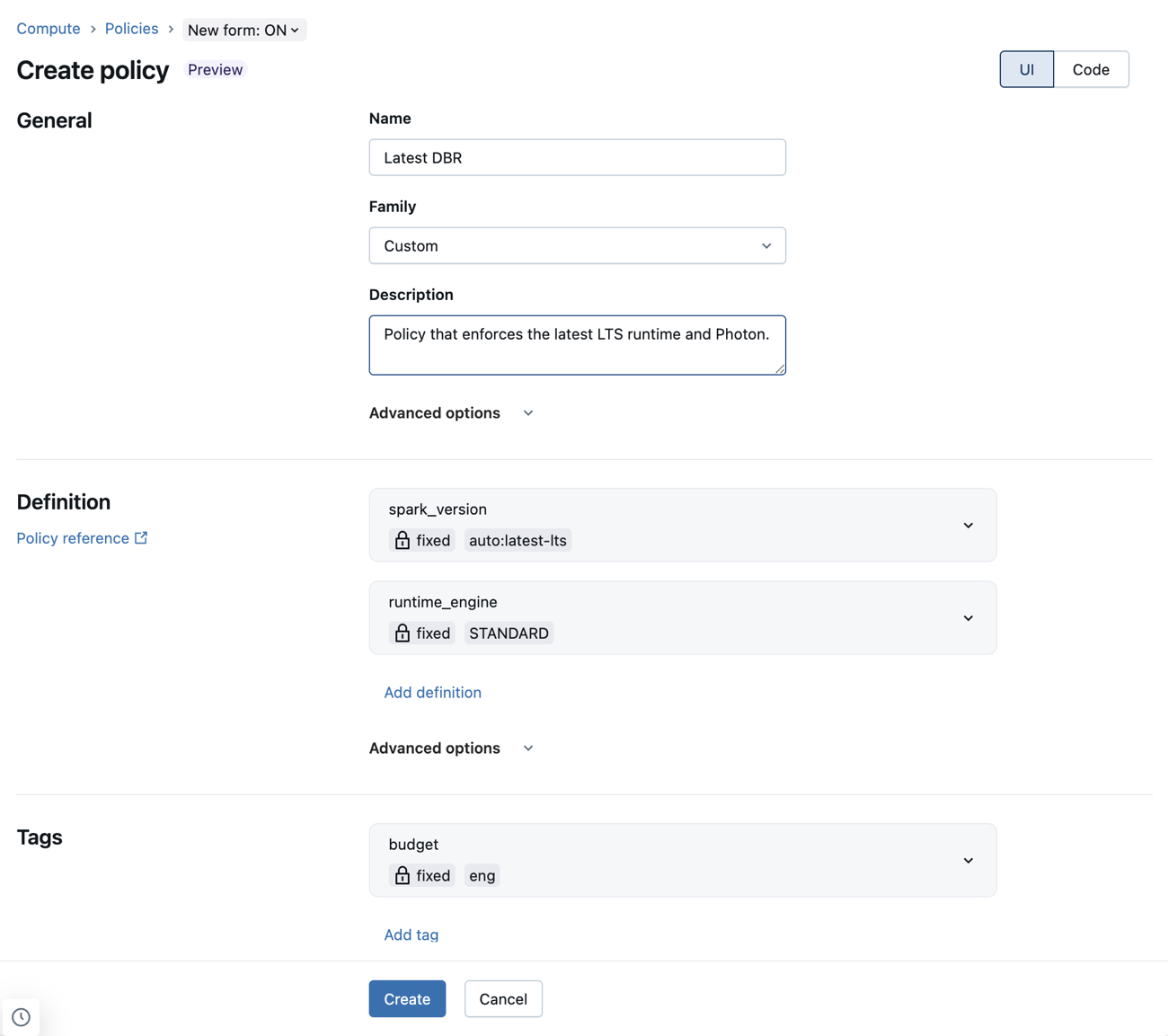
Limitaciones conocidas mediante el nuevo formulario de directiva
Si la nueva forma de directiva de proceso no admite una directiva, las definiciones incompatibles aparecerán en el campo JSON personalizado de la sección Opciones avanzadas . Para los campos siguientes, solo se admite un subconjunto de directivas válidas:
-
workload_type: la directiva debe definir y
workload_type.clients.notebooksworkload_type.clients.jobs. Cada una de estas reglas debe corregirse entrueofalse. -
dbus_per_hour: solo se admiten las directivas de intervalo que especifiquen
maxValuey no especifiquenminValue. -
ssh_public_keys: solo se admiten directivas fijas. Las
ssh_public_keysdirectivas no deben omitir ningún índice. Por ejemplo,ssh_public_keys.0, ,ssh_public_keys.1ssh_public_keys.2es válido, perossh_public_keys.0,ssh_public_keys.2,ssh_public_keys.3no es válido. -
cluster_log_conf:
cluster_log_conf.pathno puede ser una lista de permitidos ni una lista de bloqueados. -
init_scripts: las directivas indexadas (es decir,
init_scripts.0.volumes.destination) deben corregirse. Las directivas comodín (es decir,init_scripts.*.volumes.destination) deben estar prohibidas. Las directivas indexadas no deben omitir ningún índice.
Atributos compatibles
Las directivas admiten todos los atributos controlados con la API de clústeres. El tipo de restricciones que puede colocar en los atributos puede variar según su tipo y relación con los elementos de la interfaz de usuario. No se pueden usar directivas para definir permisos de proceso.
También puede usar directivas para establecer las DTU máximas por hora y tipo de clúster. Consulte las rutas de atributos virtuales .
En la tabla siguiente se enumeran las rutas de acceso de atributos de directiva admitidas:
| Ruta de acceso al atributo | Tipo | Descripción |
|---|---|---|
autoscale.max_workers |
número opcional | Cuando está oculto, quita el campo número máximo de trabajo de la interfaz de usuario. |
autoscale.min_workers |
número opcional | Cuando se oculta, quita el campo número mínimo de trabajo de la interfaz de usuario. |
autotermination_minutes |
number | Un valor de 0 no representa ninguna terminación automática. Si está oculto, quita la casilla de terminación automática y la entrada de valor de la interfaz de usuario. |
azure_attributes.availability |
cuerda / cadena | Controla si el uso del proceso usa instancias a petición o de acceso puntual (SPOT_AZURE, ON_DEMAND_AZURE o SPOT_WITH_FALLBACK_AZURE). |
azure_attributes.first_on_demand |
number | Controla el número de nodos de clúster que usan instancias a petición, empezando por el nodo de controlador. Por ejemplo, un valor de 1 establece el nodo del controlador en "a petición". Un valor de 2 establece el nodo de controlador y un nodo de trabajo en "a petición". |
azure_attributes.spot_bid_max_price |
number | Controla el precio máximo para las instancias de spot de Azure. |
cluster_log_conf.path |
cuerda / cadena | Dirección URL de destino de los archivos de registro. |
cluster_log_conf.type |
cuerda / cadena | Tipo de destino del registro.
DBFS y VOLUMES son los únicos valores aceptables. |
cluster_name |
cuerda / cadena | Nombre del clúster. |
custom_tags.* |
cuerda / cadena | Controle valores de etiqueta específicos anexando el nombre de etiqueta, por ejemplo: custom_tags.<mytag>. |
data_security_mode |
cuerda / cadena | Establece el modo de acceso del clúster. El catálogo de Unity requiere SINGLE_USER o USER_ISOLATION (modo de acceso estándar en la interfaz de usuario). Un valor de NONE significa que no hay ninguna característica de seguridad habilitada. |
docker_image.basic_auth.password |
cuerda / cadena | Contraseña de la autenticación básica de la imagen de Databricks Container Services. |
docker_image.basic_auth.username |
cuerda / cadena | Nombre de usuario de la autenticación básica de la imagen de Databricks Container Services. |
docker_image.url |
cuerda / cadena | Controle la dirección URL de la imagen de Databricks Container Services. Cuando se oculta, quita la sección Databricks Container Services de la interfaz de usuario. |
driver_node_type_id |
cadena opcional | Cuando se oculta, quita la selección del tipo de nodo de controlador de la interfaz de usuario. |
driver_node_type_flexibility.alternate_node_type_ids |
cuerda / cadena | Especifica los tipos de nodo alternativos para el nodo de controlador. Solo se admiten directivas fijas. Consulte Tipos de nodo flexibles. |
enable_local_disk_encryption |
boolean | Establézcalo en true para habilitar o false para deshabilitar y cifrar los discos que están conectados localmente al clúster (como se especifica a través de la API). |
init_scripts.*.workspace.destination
init_scripts.*.volumes.destination
init_scripts.*.abfss.destination
init_scripts.*.file.destination
|
cuerda / cadena |
* hace referencia al índice del script init de la matriz de atributos. Consulte Escritura de directivas para atributos de matriz. |
instance_pool_id |
cuerda / cadena | Controla el grupo que utilizan los nodos de trabajo si driver_instance_pool_id también está definido o, en caso contrario, para todos los nodos de clúster. Si usa grupos para nodos de trabajo, también debe usar grupos para el nodo de controlador. Si está oculto, quita la selección de grupo de la interfaz de usuario. |
driver_instance_pool_id |
cuerda / cadena | Si se especifica, configura un grupo diferente para el nodo de controlador que para los nodos de trabajo. Si no se especifica, hereda instance_pool_id. Si usa grupos para nodos de trabajo, también debe usar grupos para el nodo de controlador. Cuando se oculta, elimina la selección del grupo de conductores en la interfaz de usuario. |
is_single_node |
boolean | Cuando se configura en true, el sistema de computación debe estar configurado como un único nodo. Este atributo solo se admite cuando el usuario usa el formulario simple. |
node_type_id |
cuerda / cadena | Cuando se oculta, quita la selección del tipo de nodo de trabajo de la interfaz de usuario. |
worker_node_type_flexibility.alternate_node_type_ids |
cuerda / cadena | Especifica los tipos de nodo alternativos para los nodos de trabajo. Solo se admiten políticas fijas. Consulte Tipos de nodo flexibles. |
num_workers |
número opcional | Cuando se oculta, quita la especificación de número de trabajo de la interfaz de usuario. |
runtime_engine |
cuerda / cadena | Determina si el clúster usa Photon o no. Los valores posibles son PHOTON o STANDARD. |
single_user_name |
cuerda / cadena | Controla qué usuarios o grupos se pueden asignar al recurso de proceso. |
spark_conf.* |
cadena opcional | Controla valores de configuración específicos anexando el nombre de clave de configuración, por ejemplo: spark_conf.spark.executor.memory. |
spark_env_vars.* |
cadena opcional | Controla valores específicos de las variables de entorno de Spark anexando la variable de entorno, por ejemplo: spark_env_vars.<environment variable name>. |
spark_version |
cuerda / cadena | El nombre de la versión de la imagen de Spark tal como se especifica mediante la API (Databricks Runtime). También puede usar valores de directiva especiales que seleccionen dinámicamente Databricks Runtime. Vea Valores de directiva especiales para la selección de Databricks Runtime. |
use_ml_runtime |
boolean | Controla si se debe usar una versión de ML del entorno de ejecución de Databricks. Este atributo solo se admite cuando el usuario usa el formulario simple. |
workload_type.clients.jobs |
boolean | Definir si el recurso de cómputo puede ser utilizado para tareas. Consulte Impedir que el proceso se use con trabajos. |
workload_type.clients.notebooks |
boolean | Define si el recurso de proceso se puede usar con cuadernos. Consulte Impedir que el proceso se use con trabajos. |
Rutas de atributos virtuales
En esta tabla se incluyen dos atributos sintéticos adicionales admitidos por las directivas. Si usa el nuevo formulario de directiva, estos atributos se pueden establecer en la sección Opciones avanzadas .
| Ruta de acceso al atributo | Tipo | Descripción |
|---|---|---|
dbus_per_hour |
number | Atributo calculado que representa el número máximo de DTU que un recurso puede usar cada hora, incluido el nodo de controlador. Esta métrica es una manera directa de controlar el costo en el nivel de proceso individual. Use con limitación de intervalo. |
cluster_type |
cuerda / cadena | Representa el tipo de clúster que se puede crear:
Permitir o bloquear los tipos especificados de cómputo que se van a crear a partir de la directiva. Si no se permite el valor all-purpose, la directiva no se muestra en la interfaz de usuario de proceso de creación de todo el propósito. Si no se permite el valor job, la directiva no se muestra en la interfaz de usuario de proceso del trabajo de creación. |
Tipos de nodo flexibles
Los atributos de tipos de nodo flexibles permiten especificar tipos de nodo alternativos que el recurso de proceso puede usar si el tipo de nodo principal no está disponible. Estos atributos tienen requisitos de directiva especiales:
- Solo se admiten directivas fijas. No se permiten todos los demás tipos de directiva y se rechazarán en el momento de la creación de la directiva.
- Una cadena vacía de la directiva se asigna a una lista vacía de tipos de nodo alternativos, lo que deshabilita de forma eficaz los tipos de nodo flexibles.
Corrección a una lista específica de tipos de nodo
A diferencia de los campos de la API de Clústeres correspondientes que usan una matriz de cadenas, los atributos de la política de cómputo usan un valor de cadena único que codifica la matriz de tipo de nodo en forma de lista separada por comas. Por ejemplo:
{
"worker_node_type_flexibility.alternate_node_type_ids": {
"type": "fixed",
"value": "nodeA,nodeB"
}
}
Si usa la API de clústeres para crear un recurso de proceso con una directiva asignada, Databricks recomienda no establecer los worker_node_type_flexibility campos o driver_node_type_flexibility . Si establece estos campos, los tipos de nodo y el orden de la matriz deben coincidir exactamente con la lista separada por comas de la política o, de lo contrario, no se puede crear el recurso de cómputo. Por ejemplo, la definición de directiva anterior se establecería como:
"worker_node_type_flexibility": {
"alternate_node_type_ids": ["nodeA", "nodeB"]
}
Deshabilitación de tipos de nodo flexibles
Para deshabilitar los tipos de nodo flexibles, establezca el valor en una cadena vacía. Por ejemplo:
{
"worker_node_type_flexibility.alternate_node_type_ids": {
"type": "fixed",
"value": ""
}
}
Valores de directiva especiales para la selección de Databricks Runtime
El atributo spark_version admite valores especiales que se asignan dinámicamente a una versión de Databricks Runtime basada en el conjunto actual de versiones admitidas de Databricks Runtime.
Los siguientes valores se pueden usar en el atributo spark_version:
-
auto:latest: se asigna a la versión más reciente de Databricks Runtime (disponibilidad general). -
auto:latest-ml: se asigna a la versión más reciente de Databricks Runtime ML. -
auto:latest-lts: se asigna a la versión más reciente de Databricks Runtime de soporte técnico a largo plazo (LTS). -
auto:latest-lts-ml: se asigna a la versión más reciente de Databricks Runtime ML de LTS. -
auto:prev-major: se asigna a la segunda versión más reciente de Databricks Runtime de disponibilidad general. Por ejemplo, siauto:latestes 14.2,auto:prev-majores 13.3. -
auto:prev-major-ml: se asigna a la segunda versión más reciente de Databricks Runtime ML de disponibilidad general. Por ejemplo, siauto:latestes 14.2,auto:prev-majores 13.3. -
auto:prev-lts: se asigna a la segunda versión más reciente de Databricks Runtime de LTS. Por ejemplo, siauto:latest-ltses 13.3,auto:prev-ltses 12.2. -
auto:prev-lts-ml: se asigna a la segunda versión más reciente de Databricks Runtime ML de LTS. Por ejemplo, siauto:latest-ltses 13.3,auto:prev-ltses 12.2.
Nota
El uso de estos valores no hace que el proceso se actualice automáticamente cuando se publique una nueva versión en tiempo de ejecución. Un usuario debe editar explícitamente el proceso para que cambie la versión de Databricks Runtime.
Tipos de directivas admitidas
En esta sección se incluye una referencia para cada uno de los tipos de directiva disponibles. Hay dos categorías de tipos de directiva: directivas fijas y directivas de limitación.
Las directivas fijas impiden la configuración del usuario en un atributo. Los dos tipos de directivas fijas son:
Limitar directivas limita las opciones de un usuario para configurar un atributo. Las directivas de limitación también permiten establecer valores predeterminados y hacer que los atributos sean opcionales. Consulte Campos de directiva de limitación adicional.
Las opciones para limitar directivas son:
- Directiva de lista de permitidos
- Política de lista de bloqueados
- Directiva de expresión regular
- Directiva de rango
- Directiva ilimitada
directiva fija
Las directivas fijas limitan el atributo al valor especificado. Para los valores de atributo que no sean numéricos y booleanos, el valor debe representarse mediante o convertirse en una cadena.
Con directivas fijas, también puede ocultar el atributo de la interfaz de usuario estableciendo el campo hidden en true.
interface FixedPolicy {
type: "fixed";
value: string | number | boolean;
hidden?: boolean;
}
Esta política de ejemplo fija la versión de Databricks Runtime y oculta el campo de la interfaz de usuario:
{
"spark_version": { "type": "fixed", "value": "auto:latest-lts", "hidden": true }
}
Política prohibida
Una directiva prohibida impide que los usuarios configuren un atributo. Las directivas prohibidas solo son compatibles con atributos opcionales.
interface ForbiddenPolicy {
type: "forbidden";
}
Esta directiva prohíbe adjuntar grupos al proceso para los nodos de trabajo. Los grupos también están prohibidos para el nodo de controlador, porque driver_instance_pool_id hereda la directiva.
{
"instance_pool_id": { "type": "forbidden" }
}
Directiva de lista de permitidos
Una directiva de lista de permitidos especifica una lista de valores entre los que el usuario puede elegir al configurar un atributo.
interface AllowlistPolicy {
type: "allowlist";
values: (string | number | boolean)[];
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
Este ejemplo de lista de permitidos permite al usuario seleccionar entre dos versiones de Databricks Runtime:
{
"spark_version": { "type": "allowlist", "values": ["13.3.x-scala2.12", "12.2.x-scala2.12"] }
}
Directiva de lista de bloqueados
La directiva de lista de bloqueados enumera los valores no permitidos. Dado que los valores deben ser coincidencias exactas, es posible que esta directiva no funcione según lo previsto cuando el atributo sea leniento en la forma en que se representa el valor (por ejemplo, permitir espacios iniciales y finales).
interface BlocklistPolicy {
type: "blocklist";
values: (string | number | boolean)[];
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
En este ejemplo se impide que el usuario seleccione 7.3.x-scala2.12 como Databricks Runtime.
{
"spark_version": { "type": "blocklist", "values": ["7.3.x-scala2.12"] }
}
Directiva de expresión regular
Una política de expresión regular limita los valores disponibles a aquellos que coinciden con la expresión regular. Por motivos de seguridad, asegúrese de que la expresión regular esté anclada al principio y al final del valor de cadena.
interface RegexPolicy {
type: "regex";
pattern: string;
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
En este ejemplo se limitan las versiones de Databricks Runtime entre las que puede seleccionar un usuario:
{
"spark_version": { "type": "regex", "pattern": "13\\.[3456].*" }
}
Directiva de rango
Una directiva de intervalo limita el valor a un intervalo especificado mediante los campos minValue y maxValue. El valor debe ser un número decimal.
Los límites numéricos deben representarse como un valor de punto flotante doble. Para indicar la falta de un límite específico, puede omitir minValue o maxValue.
interface RangePolicy {
type: "range";
minValue?: number;
maxValue?: number;
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
En este ejemplo se limita la cantidad máxima de trabajos a 10:
{
"num_workers": { "type": "range", "maxValue": 10 }
}
Directiva ilimitada
La directiva ilimitada se usa para hacer que los atributos sean necesarios o para establecer el valor predeterminado en la interfaz de usuario.
interface UnlimitedPolicy {
type: "unlimited";
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
En este ejemplo se agrega la etiqueta COST_BUCKET al proceso:
{
"custom_tags.COST_BUCKET": { "type": "unlimited" }
}
Para establecer un valor predeterminado para una variable de configuración de Spark, pero también permitir omitirlo (quitarlo):
{
"spark_conf.spark.my.conf": { "type": "unlimited", "isOptional": true, "defaultValue": "my_value" }
}
Campos adicionales de políticas de limitación
Para limitar los tipos de directiva, puede especificar dos campos adicionales:
-
defaultValue: un valor que se rellena automáticamente en la interfaz de usuario de proceso de creación. -
isOptional: una directiva de limitación en un atributo hace que sea necesaria automáticamente. Para que el atributo sea opcional, establezca el campoisOptionalentrue.
Nota
Los valores predeterminados no se aplican automáticamente al proceso creado con la API de clústeres. Para aplicar valores predeterminados mediante la API, agregue el parámetro apply_policy_default_values a la definición de proceso y establézcalo en true.
Esta directiva de ejemplo especifica el valor predeterminado id1 para el grupo de nodos de trabajo, pero lo hace opcional. Al crear el proceso, puede seleccionar un grupo diferente o elegir no usar uno. Si driver_instance_pool_id no se define en la directiva o al crear el proceso, se utiliza el mismo grupo para los nodos de trabajo y el nodo de controlador.
{
"instance_pool_id": { "type": "unlimited", "isOptional": true, "defaultValue": "id1" }
}
Escritura de directivas para atributos de matriz
Puede especificar directivas para los atributos de matriz de dos maneras:
- Limitaciones genéricas para todos los elementos de matriz. Estas limitaciones utilizan el carácter comodín
*en la ruta de acceso a la directiva. - Limitaciones específicas de un elemento de matriz en un índice específico. Estas limitaciones utilizan un número en la ruta de acceso.
Nota
Los atributos de tipos flexibles de nodos (worker_node_type_flexibility.alternate_node_type_ids y driver_node_type_flexibility.alternate_node_type_ids) son campos de tipo array en la API de clústeres, pero no siguen el patrón de rutas de acceso comodín o indexadas documentado aquí. Estos atributos requieren una sola regla de directiva que especifica la lista completa como una cadena separada por comas. Consulte Tipos de nodo flexibles para obtener más información.
Por ejemplo, para el atributo de matriz init_scripts, las rutas de acceso genéricas comienzan con init_scripts.* y las rutas de acceso específicas con init_scripts.<n>, donde <n> es un índice entero en la matriz (a partir de 0).
Puede combinar limitaciones genéricas y específicas, en cuyo caso la limitación genérica se aplica a cada elemento de matriz que no tiene una limitación específica. En cada caso solo se aplicará una limitación de directiva.
En las secciones siguientes se muestran ejemplos de ejemplos comunes que usan atributos de matriz.
Requerir entradas específicas de inclusión
No puede requerir valores específicos sin especificar el orden. Por ejemplo:
{
"init_scripts.0.volumes.destination": {
"type": "fixed",
"value": "<required-script-1>"
},
"init_scripts.1.volumes.destination": {
"type": "fixed",
"value": "<required-script-2>"
}
}
Requerir un valor fijo de toda la lista
{
"init_scripts.0.volumes.destination": {
"type": "fixed",
"value": "<required-script-1>"
},
"init_scripts.*.volumes.destination": {
"type": "forbidden"
}
}
No permitir el uso por completo
{
"init_scripts.*.volumes.destination": {
"type": "forbidden"
}
}
Permitir entradas que siguen restricciones específicas
{
"init_scripts.*.volumes.destination": {
"type": "regex",
"pattern": ".*<required-content>.*"
}
}
Corrección de un conjunto específico de scripts de inicialización
En el caso de las rutas de acceso init_scripts, la matriz puede contener una de varias estructuras para las que pueda ser necesario controlar todas las variantes en función del caso de uso. Por ejemplo, para requerir un conjunto específico de scripts de inicialización y no permitir cualquier variante de la otra versión, puede usar el siguiente patrón:
{
"init_scripts.0.volumes.destination": {
"type": "fixed",
"value": "<volume-paths>"
},
"init_scripts.1.volumes.destination": {
"type": "fixed",
"value": "<volume-paths>"
},
"init_scripts.*.workspace.destination": {
"type": "forbidden"
},
"init_scripts.*.abfss.destination": {
"type": "forbidden"
},
"init_scripts.*.file.destination": {
"type": "forbidden"
}
}
Ejemplos de directivas
En esta sección se incluyen ejemplos de directivas que puede usar como referencias para crear sus propias directivas. También puede usar las familias de directivas de proporcionadas por Azure Databricks como plantillas para casos de uso de directivas comunes.
- Política informática general
- Definición de límites en el proceso de canalizaciones declarativas de Spark de Lakeflow
- Directiva simple de tamaño medio
- Directiva de solo trabajo
- Directiva de metastore externo
- Impedir que el proceso se use con trabajos
- Quitar la directiva de escalado automático
- Cumplimiento de etiquetas personalizadas
Política de computación general
Una política de computación de uso general diseñada para guiar a los usuarios y restringir algunas funciones, al tiempo que requiere etiquetas, restringiendo el número máximo de instancias y aplicando el tiempo de espera.
{
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"spark_version": {
"type": "regex",
"pattern": "12\\.[0-9]+\\.x-scala.*"
},
"node_type_id": {
"type": "allowlist",
"values": ["Standard_L4s", "Standard_L8s", "Standard_L16s"],
"defaultValue": "Standard_L16s_v2"
},
"driver_node_type_id": {
"type": "fixed",
"value": "Standard_L16s_v2",
"hidden": true
},
"autoscale.min_workers": {
"type": "fixed",
"value": 1,
"hidden": true
},
"autoscale.max_workers": {
"type": "range",
"maxValue": 25,
"defaultValue": 5
},
"autotermination_minutes": {
"type": "fixed",
"value": 30,
"hidden": true
},
"custom_tags.team": {
"type": "fixed",
"value": "product"
}
}
Definir límites en el cálculo de canalizaciones declarativas Lakeflow Spark
Nota
Al utilizar políticas para configurar el cómputo de las canalizaciones declarativas de Spark de Lakeflow, Databricks recomienda aplicar una sola política tanto al cómputo de default como al de maintenance.
Para configurar una directiva para un proceso de canalización, cree una directiva con el campo cluster_type establecido en dlt. En el siguiente ejemplo se crea una política mínima para una computación de canalizaciones declarativas de Lakeflow Spark.
{
"cluster_type": {
"type": "fixed",
"value": "dlt"
},
"num_workers": {
"type": "unlimited",
"defaultValue": 3,
"isOptional": true
},
"node_type_id": {
"type": "unlimited",
"isOptional": true
},
"spark_version": {
"type": "unlimited",
"hidden": true
}
}
Política simple de tamaño mediano
Permite a los usuarios crear un proceso de tamaño mediano con una configuración mínima. El único campo necesario en el momento de la creación es el nombre del proceso; el resto es fijo y oculto.
{
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"spark_conf.spark.databricks.cluster.profile": {
"type": "forbidden",
"hidden": true
},
"autoscale.min_workers": {
"type": "fixed",
"value": 1,
"hidden": true
},
"autoscale.max_workers": {
"type": "fixed",
"value": 10,
"hidden": true
},
"autotermination_minutes": {
"type": "fixed",
"value": 60,
"hidden": true
},
"node_type_id": {
"type": "fixed",
"value": "Standard_L8s_v2",
"hidden": true
},
"driver_node_type_id": {
"type": "fixed",
"value": "Standard_L8s_v2",
"hidden": true
},
"spark_version": {
"type": "fixed",
"value": "auto:latest-ml",
"hidden": true
},
"custom_tags.team": {
"type": "fixed",
"value": "product"
}
}
Directiva de solo trabajo
Permite a los usuarios crear un proceso de trabajo para ejecutar trabajos. Los usuarios no pueden crear computación de uso general con esta directiva.
{
"cluster_type": {
"type": "fixed",
"value": "job"
},
"dbus_per_hour": {
"type": "range",
"maxValue": 100
},
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"num_workers": {
"type": "range",
"minValue": 1
},
"node_type_id": {
"type": "regex",
"pattern": "Standard_[DLS]*[1-6]{1,2}_v[2,3]"
},
"driver_node_type_id": {
"type": "regex",
"pattern": "Standard_[DLS]*[1-6]{1,2}_v[2,3]"
},
"spark_version": {
"type": "unlimited",
"defaultValue": "auto:latest-lts"
},
"custom_tags.team": {
"type": "fixed",
"value": "product"
}
}
Directiva de metastore externo
Permite a los usuarios crear un proceso con un metastore definido por el administrador ya adjunto. Esto resulta útil para permitir a los usuarios crear su propio cómputo sin necesidad de configuración adicional.
{
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionURL": {
"type": "fixed",
"value": "jdbc:sqlserver://<jdbc-url>"
},
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionDriverName": {
"type": "fixed",
"value": "com.microsoft.sqlserver.jdbc.SQLServerDriver"
},
"spark_conf.spark.databricks.delta.preview.enabled": {
"type": "fixed",
"value": "true"
},
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionUserName": {
"type": "fixed",
"value": "<metastore-user>"
},
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionPassword": {
"type": "fixed",
"value": "<metastore-password>"
}
}
Impedir que el proceso se use con trabajos
Esta política impide que los usuarios utilicen los recursos de computación para ejecutar trabajos. Los usuarios solo podrán usar el cómputo con portátiles.
{
"workload_type.clients.notebooks": {
"type": "fixed",
"value": true
},
"workload_type.clients.jobs": {
"type": "fixed",
"value": false
}
}
Eliminación de la directiva de escalado automático
Esta directiva deshabilita el escalado automático y permite al usuario establecer el número de trabajos dentro de un intervalo determinado.
{
"num_workers": {
"type": "range",
"maxValue": 25,
"minValue": 1,
"defaultValue": 5
}
}
Cumplimiento de etiquetas personalizadas
Para agregar una regla de etiqueta de proceso a una directiva, use el atributo custom_tags.<tag-name>.
Por ejemplo, cualquier usuario que use esta directiva debe rellenar una etiqueta de COST_CENTER con 9999, 9921 o 9531 para que se inicie el proceso:
{ "custom_tags.COST_CENTER": { "type": "allowlist", "values": ["9999", "9921", "9531"] } }