Nota
L'accés a aquesta pàgina requereix autorització. Pots provar d'iniciar sessió o canviar de directori.
L'accés a aquesta pàgina requereix autorització. Pots provar de canviar directoris.
En esta página se explica cómo Azure Databricks usa Lakeguard para aplicar el aislamiento de usuario en entornos de proceso compartidos y un control de acceso específico en el proceso dedicado.
¿Qué es Lakeguard?
Lakeguard es un conjunto de tecnologías en Databricks que aplican el aislamiento de código y el filtrado de datos para que varios usuarios puedan compartir el mismo recurso de proceso de forma segura y rentable, y acceder a los datos con controles de acceso específicos implementados en el proceso que ofrecen acceso a máquinas con privilegios.
¿Cómo funciona Lakeguard?
En entornos de proceso compartidos, como el proceso clásico estándar, el proceso sin servidor y los almacenes de SQL, Lakeguard aísla el código de usuario del motor de Spark y de otros usuarios. Este diseño permite a muchos usuarios compartir los mismos recursos de proceso al tiempo que mantienen límites estrictos entre usuarios, el controlador de Spark y los ejecutores.
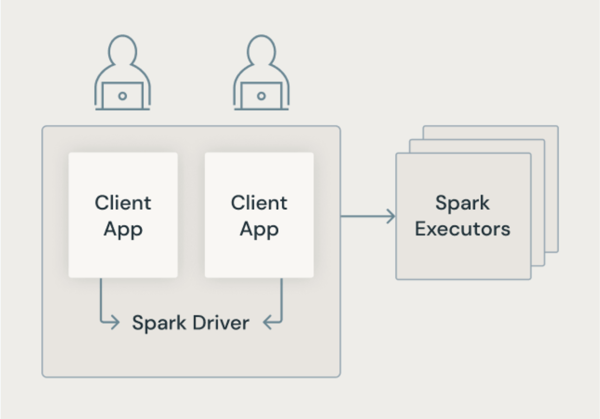
Arquitectura de Spark clásica
En la imagen siguiente se muestra cómo en la arquitectura tradicional de Spark, las aplicaciones de usuario comparten una JVM con acceso con privilegios a la máquina subyacente.
Arquitectura de Lakeguard
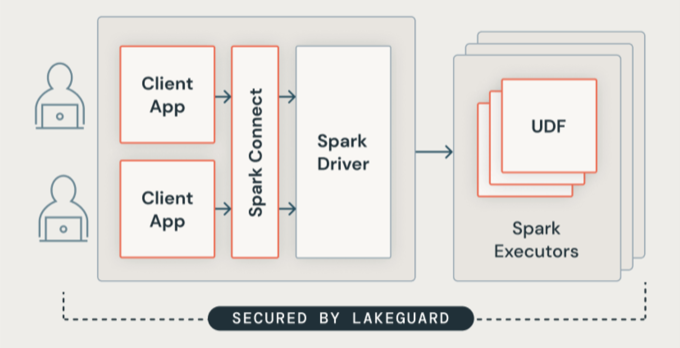
Lakeguard aísla todo el código de usuario mediante contenedores seguros. Esto permite que varias cargas de trabajo se ejecuten en el mismo recurso de proceso, a la vez que se mantiene un aislamiento estricto entre los usuarios.
Aislamiento de cliente spark
Lakeguard aísla las aplicaciones cliente del controlador spark y entre sí mediante dos componentes clave:
Spark Connect: Lakeguard usa Spark Connect (introducido con Apache Spark 3.4) para desacoplar las aplicaciones cliente del controlador. Las aplicaciones cliente y los controladores ya no comparten la misma JVM o classpath. Esta separación impide el acceso a datos no autorizados. Este diseño también impide que los usuarios accedan a los datos resultantes de la captura excesiva cuando las consultas incluyen filtros de nivel de fila o de columna.
Nota:
Spark Connect aplaza el análisis y la resolución de nombres al tiempo de ejecución, lo que puede cambiar el comportamiento del código. Consulte Comparación de Spark Connect con Spark clásico.
Espacio aislado de contenedores: cada aplicación cliente se ejecuta en su propio entorno de contenedor aislado. Esto impide que el código de usuario acceda a los datos de otros usuarios o a la máquina subyacente. El espacio aislado usa técnicas de aislamiento basadas en contenedores para crear límites seguros entre los usuarios.
Aislamiento de UDF
De forma predeterminada, los ejecutores de Spark no aíslan las UDF. Esa falta de aislamiento puede permitir que las UDF escriban archivos o accedan a la máquina subyacente.
Lakeguard aísla el código definido por el usuario, incluidas las UDF, en los ejecutores de Spark mediante:
- Espacio aislado del entorno de ejecución en ejecutores de Spark.
- Aislar el tráfico de red de salida de las UDF para evitar el acceso externo no autorizado.
- Replicar el entorno de cliente en el espacio aislado de UDF para que los usuarios puedan acceder a las bibliotecas necesarias.
Este aislamiento se aplica a las UDF en proceso estándar y a UDF de Python en almacenamientos de SQL y proceso sin servidor.