Nota
L'accés a aquesta pàgina requereix autorització. Podeu provar d'iniciar la sessió o de canviar els directoris.
L'accés a aquesta pàgina requereix autorització. Podeu provar de canviar els directoris.
El control de acceso específico permite restringir el acceso a datos específicos mediante vistas, filtros de fila y máscaras de columna. En esta página se explica cómo se usa la computación sin servidor para aplicar controles de acceso detallados en recursos de computación dedicados.
Nota:
La computación dedicada es una computación de propósito general o para trabajos configurada con el modo de acceso Dedicated (anteriormente llamado modo de acceso para un solo usuario). Consulte Modos de acceso.
Requisitos
Para usar recursos dedicados para consultar una vista o una tabla con controles de acceso detallados:
- El recurso de proceso dedicado debe estar en Databricks Runtime 15.4 LTS o superior.
- El área de trabajo debe estar habilitada para el proceso sin servidor.
Si el recurso de proceso dedicado y el área de trabajo cumplen estos requisitos, el filtrado de datos se ejecuta automáticamente.
Funcionamiento del filtrado de datos en un entorno de cómputo dedicado
Cada vez que una consulta accede a un objeto de base de datos con controles de acceso específicos, el recurso de proceso dedicado pasa la consulta al proceso sin servidor del área de trabajo para realizar el filtrado de datos. A continuación, los datos filtrados se transfieren entre la computación sin servidor y la dedicada, utilizando archivos temporales en el almacenamiento interno en la nube del área de trabajo.
Azure Databricks transfiere los datos filtrados mediante Cloud Fetch, una funcionalidad que escribe conjuntos de resultados temporales en el almacenamiento interno del área de trabajo ( raíz de DBFS del área de trabajo). Azure Databricks realiza automáticamente la recolección de basura de estos archivos, marcándolos para su eliminación tras 24 horas y eliminándolos permanentemente tras 24 horas adicionales.
Esta funcionalidad se aplica a los siguientes objetos de base de datos:
- Vistas dinámicas
- Tablas con filtros de fila o máscaras de columna
-
Vistas creadas sobre tablas en las que el usuario no tiene el
SELECTprivilegio - Vistas materializadas
- Tablas de streaming
En el diagrama siguiente, un usuario tiene el SELECT privilegio en table_1, view_2y table_w_rls, que tiene aplicados filtros de fila. El usuario no tiene el SELECT privilegio en table_2, al que hace referencia view_2.

El recurso de cálculo dedicado maneja completamente la consulta en table_1, ya que no se requiere ningún filtrado. Las consultas en view_2 y table_w_rls requieren el filtrado de datos para devolver los datos a los que el usuario tiene acceso. Estas consultas se controlan mediante la funcionalidad de filtrado de datos en el proceso sin servidor.
Compatibilidad con operaciones de escritura
En Databricks Runtime 16.3 y versiones posteriores, puede escribir en tablas que tengan aplicados filtros de fila o máscaras de columna mediante estas opciones:
- El comando SQL MERGE INTO, que puede usar para lograr la funcionalidad
INSERT,UPDATEyDELETE. - Operación de fusión Delta.
- La API
DataFrame.write.mode("append").
Para lograr la funcionalidad de INSERT, UPDATE y DELETE, puede usar una tabla de almacenamiento provisional y las cláusulas MERGE INTO y WHEN MATCHED de la instrucción WHEN NOT MATCHED.
A continuación se muestra un ejemplo de un UPDATE con MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET
t.column1 = s.column1,
t.column2 = s.column2;
A continuación se muestra un ejemplo de un INSERT con MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN NOT MATCHED THEN
INSERT (id, column1, column2) VALUES (s.id, s.column1, s.column2);
A continuación se muestra un ejemplo de DELETE mediante MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s ON t.id = s.id
WHEN MATCHED AND s.some_column = TRUE THEN DELETE;
Compatibilidad con DDL, SHOW, DESCRIBE y otros comandos
En Databricks Runtime 17.1 y versiones posteriores, puede usar los siguientes comandos en combinación con objetos con control de acceso detallado en un entorno de cálculo dedicado:
- Instrucciones DDL
- Instrucciones SHOW
- Describir instrucciones
- OPTIMIZE
- DESCRIBE HISTORY
- FSCK REPAIR TABLE (Databricks Runtime 17.2 y versiones posteriores)
Si es necesario, estos comandos se ejecutan automáticamente en proceso sin servidor.
No se admiten algunos comandos, incluidos VACCUM, RESTOREy REORG TABLE.
Costos de proceso sin servidor
Se cobra a los clientes por los recursos de cómputo sin servidor que realizan operaciones de filtrado de datos. Para obtener información sobre los precios, consulte Niveles de plataforma y complementos.
Los usuarios con acceso pueden consultar la tabla system.billing.usage para ver cuánto se les ha cobrado. Por ejemplo, la consulta siguiente desglosa los costos de proceso por usuario:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Visualización del rendimiento de las consultas cuando se activa el filtrado de datos
La interfaz de usuario de Spark para el proceso dedicado muestra las métricas que puede usar para comprender el rendimiento de las consultas. Para cada consulta que se ejecuta en el recurso de proceso, la pestaña SQL/Dataframe muestra la representación del grafo de consulta. Si se ha utilizado una consulta al filtrar los datos, la interfaz de usuario muestra un nodo de operador RemoteSparkConnectScan en la parte inferior del gráfico. Ese nodo muestra las métricas que se pueden usar para investigar el rendimiento de las consultas. Consulte Visualización de la información de proceso en la interfaz de usuario de Spark.
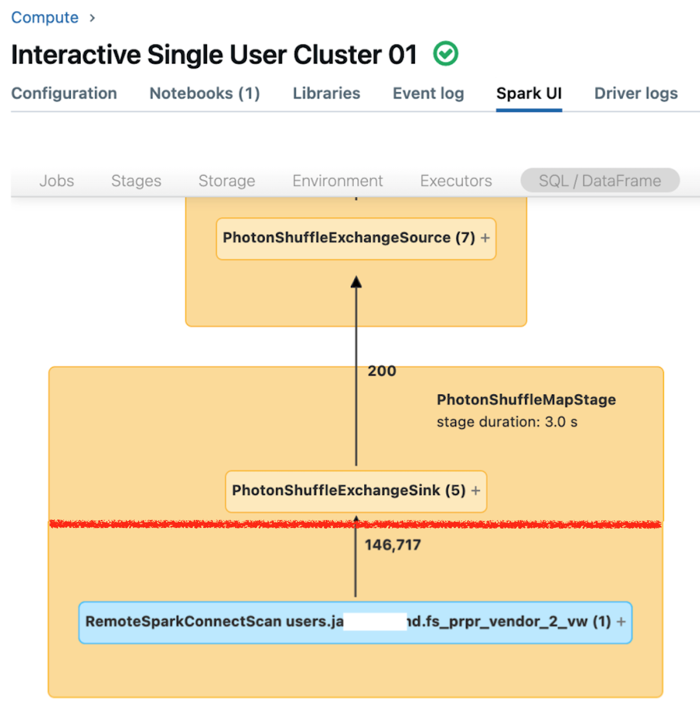
Expanda el nodo de operador RemoteSparkConnectScan para ver las métricas que permiten responder preguntas como las siguientes:
- ¿Cuánto tiempo ha tardado el filtrado de datos? Vea "tiempo total de ejecución remota".
- ¿Cuántas filas han quedado después del filtrado de datos? Vea "salida de filas".
- ¿Cuántos datos (en bytes) se han devuelto de después del filtrado de datos? Vea "tamaño de salida de filas".
- ¿Cuántos archivos de datos se eliminaron por particiones y no tenían que leerse desde el almacenamiento? Vea "Archivos eliminados" y "Tamaño de los archivos eliminados".
- ¿Cuántos archivos de datos no se han podido eliminar y han tenido que leerse desde el almacenamiento? Vea "Archivos leídos" y "Tamaño de los archivos leídos".
- De los archivos que tenían que leerse, ¿cuántos se encontraban ya en la memoria caché? Vea "Tamaño de aciertos de caché" y "Tamaño de errores de caché".
Limitaciones
Se admiten solo lecturas por lotes en tablas de transmisión. Las tablas con filtros de fila o máscaras de columna no admiten trabajos de flujo en computación dedicada.
No se puede modificar el catálogo predeterminado (
spark.sql.catalog.spark_catalog).No se admite
spark.catalog.listColumns(). En su lugar, puede usarSHOW COLUMNS INpara enumerar nombres de columna,SHOW PARTITIONSpara enumerar columnas de partición oDESCRIBE TABLE [EXTENDED [AS JSON]]para obtener una descripción detallada de la tabla.En Databricks Runtime 16.2 y versiones posteriores, no se admiten operaciones de tabla de escritura o actualización en tablas que tengan aplicados filtros de fila o máscaras de columna.
En concreto, no se admiten las operaciones DML, como
INSERT,DELETE,UPDATE,REFRESH TABLEyMERGE. Solo puede leer (SELECT) de estas tablas.En Databricks Runtime 16.3 y versiones posteriores, no se admiten operaciones de tabla de escritura como
INSERT,DELETEyUPDATE, pero se puede realizar medianteMERGE, que se admite.Cuando se usa
DeltaTable.forName()oDeltaTable.forPath()en un cómputo dedicado con tablas habilitadas para FGAC, solo se admitenmerge()ytoDF(). Para otras operaciones de DeltaTable, use en su lugar los comandos SQL correspondientes. Por ejemplo, en lugar dehistory(), useDESCRIBE HISTORYy en lugar declone(), useSHALLOW CLONEoDEEP CLONE.En Databricks Runtime 16.2 y versiones posteriores, las autocombinaciones se bloquean de forma predeterminada cuando se llama al filtrado de datos porque estas consultas pueden devolver diferentes instantáneas de la misma tabla remota. Sin embargo, puede habilitar estas consultas estableciendo
spark.databricks.remoteFiltering.blockSelfJoinsafalseen el equipo en el que está ejecutando estos comandos.En Databricks Runtime 16.3 y versiones posteriores, las instantáneas se sincronizan automáticamente entre los recursos de proceso dedicados y sin servidor. Debido a esta sincronización, las consultas de autocombinación que usan la funcionalidad de filtrado de datos devuelven instantáneas idénticas y están habilitadas de forma predeterminada. Las excepciones son vistas materializadas y las vistas, vistas materializadas y tablas de streaming compartidas mediante el uso compartido de Delta. Para estos objetos, las autocombinaciones se bloquean de forma predeterminada, pero puede habilitar estas consultas estableciendo
spark.databricks.remoteFiltering.blockSelfJoinsen false en el proceso en el que se ejecutan estos comandos.Si habilita consultas de autocombinación para vistas materializadas y cualquier vista, vistas materializadas y tablas de streaming, debe asegurarse de que no haya escrituras simultáneas en los objetos que se van a unir.
- No se admiten imágenes de Docker.
- No hay soporte cuando se utiliza Databricks Container Services.
- Debe abrir los puertos 8443 y 8444 para habilitar el control de acceso detallado en los recursos computacionales dedicados. Consulte Implementación de Azure Databricks en una red virtual de Azure (inserción en red virtual).