Nota
L'accés a aquesta pàgina requereix autorització. Pots provar d'iniciar sessió o canviar de directori.
L'accés a aquesta pàgina requereix autorització. Pots provar de canviar directoris.
En este artículo se describen algunas opciones de depuración disponibles para la aplicación apache Spark:
- Interfaz de usuario de Spark
- Registros de controladores
- Registros del ejecutor
Consulte Diagnóstico de problemas de costo y rendimiento mediante la interfaz de usuario de Spark para consultar el diagnóstico de problemas de costo y rendimiento mediante la interfaz de usuario de Spark.
Interfaz de usuario de Spark
Una vez que inicie un trabajo, la interfaz de usuario de Spark muestra información sobre lo que sucede en la aplicación. Para llegar a la interfaz de usuario de Spark, seleccione el proceso en la página Proceso y, a continuación, haga clic en la pestaña Interfaz de usuario de Spark :
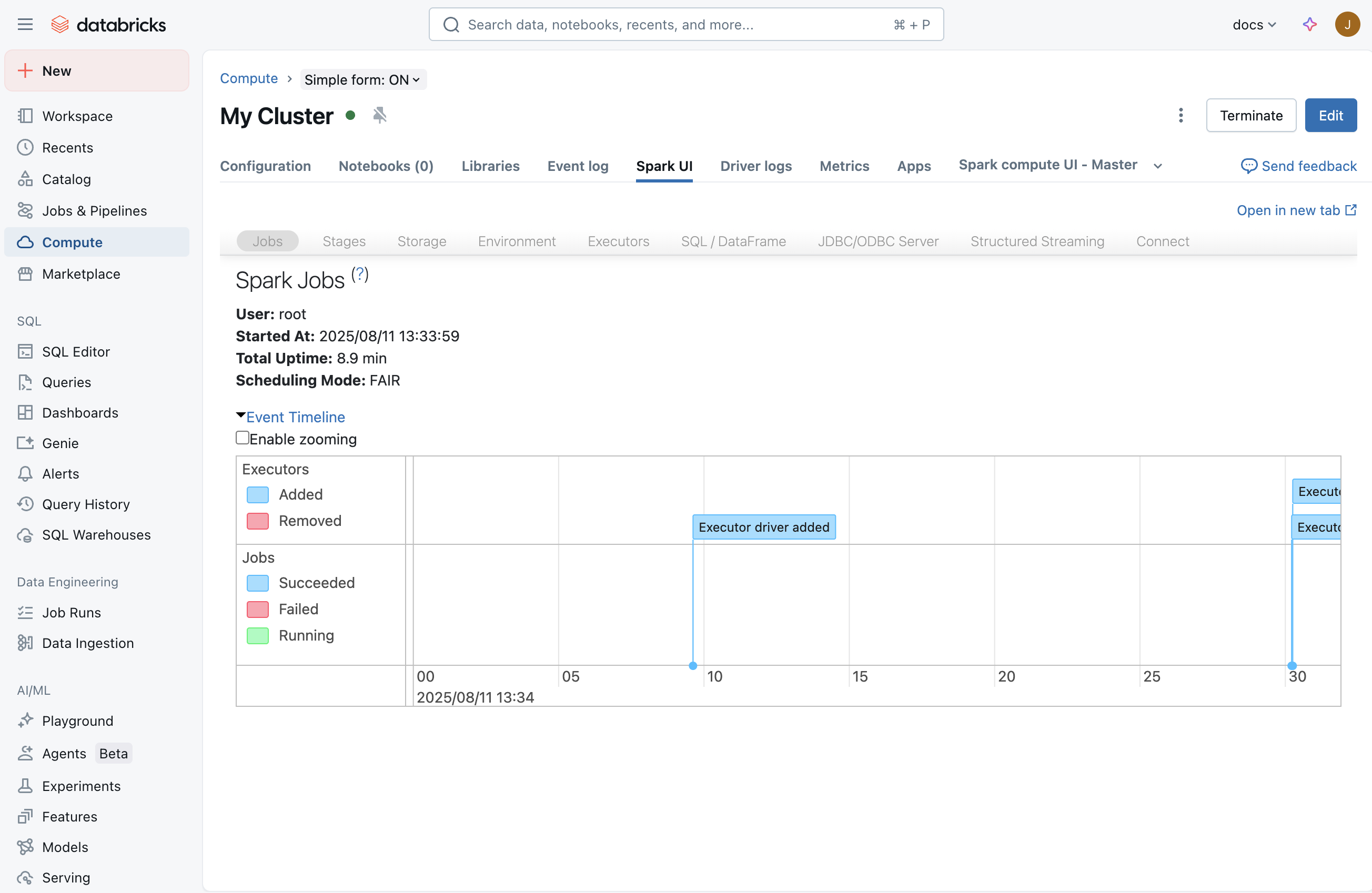
Pestaña Streaming
En la interfaz de usuario de Spark, verá una pestaña Streaming si un trabajo de streaming se ejecuta en el proceso. Si no hay ningún trabajo de streaming en ejecución en este proceso, esta pestaña no está visible. Puede ir directamente a los registros de controladores para obtener información sobre cómo comprobar si hay excepciones que podrían haberse producido al iniciar el trabajo de streaming.
Esta página permite comprobar si la aplicación de streaming recibe eventos de entrada del origen. Por ejemplo, puede ver que el trabajo recibe 1000 eventos por segundo.
Nota:
Para TextFileStream, dado que los archivos son entrada, el número de eventos de entrada siempre es 0. En tales casos, puede consultar la sección Lotes completados del cuaderno para averiguar cómo encontrar más información.
Si tiene una aplicación que recibe varias secuencias de entrada, puede hacer clic en el vínculo Velocidad de entrada que mostrará el número de eventos recibidos para cada receptor.
Tiempo de procesamiento
A medida que desplácese hacia abajo, busque el gráfico de Tiempo de procesamiento. Se trata de uno de los gráficos clave para comprender el rendimiento del trabajo de streaming. Como regla general, es bueno si puede procesar cada lote en un 80 % del tiempo de procesamiento por lotes.
Si el tiempo medio de procesamiento es más cercano o mayor que el intervalo de lote, tendrá una aplicación de streaming que comenzará a poner en cola lo que dará lugar a trabajos pendientes pronto, lo que puede reducir el trabajo de streaming finalmente.
Lotes completados
Al final de la página, verá una lista de todos los lotes completados. En la página se muestran detalles sobre los últimos 1000 lotes completados. En la tabla, puede obtener el número de eventos procesados para cada lote y su tiempo de procesamiento. Si desea obtener más información sobre lo que ha ocurrido en uno de los lotes, puede hacer clic en el vínculo por lotes para ir a la página Detalles del lote .
Página de detalles del lote
La página Detalles de Batch tiene todos los detalles sobre un lote. Dos cosas clave son:
- Entrada: tiene detalles sobre la entrada del lote. En este caso, tiene detalles sobre el tema de Apache Kafka, la partición y los desplazamientos leídos por Spark Structured Streaming para este lote. En el caso de TextFileStream, verá una lista de nombres de archivo leídos para este lote. Esta es la mejor manera de empezar a depurar una aplicación streaming leyendo desde archivos de texto.
- Procesamiento: puede hacer clic en el vínculo al identificador de trabajo, que tiene todos los detalles sobre el procesamiento realizado durante este lote.
Página de detalles de trabajo
La página de detalles del trabajo muestra una visualización de DAG. Esto resulta útil para comprender el orden de las operaciones y las dependencias de cada lote. Por ejemplo, esto podría mostrar que una entrada de lectura por lotes de una secuencia directa de Kafka seguida de una operación de mapa plano y, a continuación, una operación de mapa, y que la secuencia resultante se usó para actualizar un estado global mediante updateStateByKey.
Los cuadros atenuados representan fases omitidas. Spark es lo suficientemente inteligente como para omitir algunas fases si no es necesario volver a calcular. Si los datos se almacenan en puntos de control o se almacenan en caché, Spark omite volver a calcular esas fases. En el ejemplo de streaming anterior, esas fases corresponden a la dependencia de lotes anteriores debido updateStateBykeya . Dado que Spark Structured Streaming controla internamente la secuencia y lee desde el punto de control en lugar de en función de los lotes anteriores, se muestran como fases atenuadas.
En la parte inferior de la página, también encontrará la lista de trabajos que se ejecutaron para este lote. Puede hacer clic en los vínculos de la descripción para profundizar más en la ejecución del nivel de tarea.
Página de detalles de la tarea
Este es el nivel de depuración más granular en el que puede profundizar desde la interfaz de usuario de Spark para una aplicación Spark. Esta página tiene todas las tareas que se ejecutaron para este lote. Si está investigando problemas de rendimiento de la aplicación de streaming, esta página proporciona información como el número de tareas que se ejecutaron y dónde se ejecutaron (en qué ejecutores) y la información de orden aleatorio.
Sugerencia
Asegúrese de que las tareas se ejecutan en varios ejecutores (nodos) del proceso para tener suficiente paralelismo durante el procesamiento. Si tiene un solo receptor, a veces solo un ejecutor puede estar realizando todo el trabajo, aunque tiene más de un ejecutor en su cómputo.
Volcado de subprocesos
Un volcado de subproceso muestra una instantánea de los estados de los subprocesos de una JVM.
Los volcados de subprocesos son útiles para depurar una tarea en ejecución lenta o bloqueada concreta. Para ver el volcado de hilos de una tarea específica en la Spark UI:
- Haga clic en la pestaña Trabajos .
- En la tabla Trabajos, busque el trabajo de destino que corresponde al volcado de subprocesos que desea ver y haga clic en el vínculo de la columna Descripción.
- En la tabla Etapas del trabajo, busque la etapa de destino que corresponde al volcado de subproceso que desea ver y haga clic en el enlace de la columna Descripción.
- En la lista Tareas de la fase, busque la tarea correspondiente al volcado de subproceso que desea ver y anote sus valores ID de tarea e ID de ejecutor.
- Haga clic en la pestaña Ejecutores .
- En la tabla Executors , busque la fila que contiene el valor del identificador del ejecutor que corresponde al valor del identificador del ejecutor que anotó anteriormente. En esa fila, haga clic en el vínculo de la columna Volcado de subprocesos.
- En la tabla Volcado de hilos para el ejecutor, haga clic en la fila donde la columna Nombre del hilo contiene TID seguida del valor Identificador de tarea que anotó anteriormente. (Si la tarea ha terminado de ejecutarse, no encontrará un hilo coincidente). Se muestra el volcado del hilo de la tarea.
Los volcados de subprocesos también son útiles para depurar problemas en los que el controlador parece estar bloqueado (por ejemplo, no se muestran barras de progreso de Spark) o si no se realiza ningún progreso en las consultas (por ejemplo, las barras de progreso de Spark se bloquean en el 100 %). Para ver el volcado de hilos del controlador en la interfaz de usuario de Spark:
- Haga clic en la pestaña Ejecutores .
- En la tabla Ejecutores, en la fila del controlador, haga clic en el vínculo de la columna Volcado de subprocesos. Se muestra el volcado del subproceso del controlador.
Registros de controladores
Los registros de controladores son útiles en los casos siguientes:
- Excepciones: a veces, es posible que no vea la pestaña Streaming en la interfaz de usuario de Spark. Esto se debe a que no se inició el trabajo de streaming debido a alguna excepción. Puede profundizar en los registros del controlador para ver el seguimiento de la pila de la excepción. En algunos casos, es posible que el proceso de transmisión se haya iniciado correctamente. Pero verá que todos los lotes nunca van a la sección Lotes completados. Es posible que todos estén en estado de procesamiento o con errores. En estos casos, los registros de controladores también son útiles para comprender la naturaleza de los problemas subyacentes.
- Impresiones: las instrucciones de impresión como parte del DAG también se muestran en los registros.
Nota:
Quién puede acceder a los registros de controladores depende del modo de acceso del recurso de proceso. Para la computación con el modo estándar de acceso, solo los administradores del área de trabajo pueden acceder a los registros de controladores. Para el proceso con el modo de acceso Dedicado, los administradores de grupo o grupo y área de trabajo dedicados pueden acceder a los registros de controladores.
Registros del ejecutor
Los registros del ejecutor son útiles si ve que ciertas tareas se comportan mal y desea ver los registros de tareas específicas. En la página de detalles de la tarea mostrada anteriormente, puede obtener el ejecutor donde se ejecutó la tarea. Una vez que lo tenga, puede ir a la página de la interfaz de usuario de proceso, haga clic en los nodos # y, a continuación, en el patrón. La página maestra lista a todos los trabajadores. Puede elegir el trabajo en el que se ejecutó la tarea sospechosa y, a continuación, obtener acceso a la salida log4j.
Nota:
Los registros del ejecutor no están disponibles para el proceso con el modo de acceso estándar . Para el cálculo con el modo de acceso dedicado, el usuario o grupo dedicado y los administradores del área de trabajo pueden acceder a los registros del ejecutor.