Nota
L'accés a aquesta pàgina requereix autorització. Pots provar d'iniciar sessió o canviar de directori.
L'accés a aquesta pàgina requereix autorització. Pots provar de canviar directoris.
Importante
Esta característica está en versión preliminar pública.
En esta página se describe cómo usar la clasificación de datos de Databricks en el catálogo de Unity para clasificar y etiquetar automáticamente datos confidenciales en el catálogo.
Los catálogos de datos pueden tener una gran cantidad de datos, a menudo que contienen datos confidenciales conocidos y desconocidos. Es fundamental que los equipos de datos comprendan qué tipo de datos confidenciales existe en cada tabla para que puedan gobernar y democratizar el acceso a estos datos.
Para solucionar este problema, La clasificación de datos de Databricks usa un agente de INTELIGENCIA ARTIFICIAL para clasificar y etiquetar automáticamente tablas en el catálogo. Esto le permite detectar datos confidenciales y aplicar controles de gobernanza sobre los resultados, mediante herramientas como el control de acceso basado en atributos (ABAC) de Unity Catalog. Para obtener una lista de las etiquetas admitidas, consulte Etiquetas de clasificación admitidas.
Con esta característica, puede:
- Clasificar datos: el motor usa un sistema de IA agente para clasificar y etiquetar automáticamente las tablas en el catálogo de Unity.
- Optimización del costo a través del análisis inteligente: el sistema determina de forma inteligente cuándo examinar los datos mediante el catálogo de Unity y el motor de inteligencia de datos. Esto significa que el examen es incremental y optimizado para asegurarse de que todos los datos nuevos se clasifican sin configuración manual.
- Revisar y proteger datos confidenciales: la visualización de los resultados le ayuda a ver los resultados de clasificación y a proteger los datos confidenciales mediante el etiquetado y la creación de directivas de control de acceso para cada clase.
Importante
La clasificación de datos de Databricks usa el almacenamiento predeterminado para almacenar los resultados de clasificación. No se le factura el almacenamiento.
La clasificación de datos de Databricks usa un modelo de lenguaje grande (LLM) para ayudar con la clasificación.
Requisitos
Nota:
La clasificación de datos es una característica de versión preliminar de nivel de área de trabajo y solo puede administrarla un administrador de área de trabajo o cuenta. Para obtener instrucciones, consulte Administración de versiones preliminares de Azure Databricks.
Importante
El modelo que alimenta esta función está disponible mediante las API del modelo de Mosaic AI Serving Foundation. Llama 3.1 tiene licencia bajo la Licencia comunitaria llama 3.1, Copyright © Meta Platforms, Inc. Todos los derechos reservados. Consulte Licencias y términos aplicables para desarrolladores de modelos para obtener más información.
Si los modelos surgen en el futuro que funcionan mejor según las pruebas comparativas internas de Databricks, Databricks puede cambiar los modelos y actualizar la documentación.
- Debe tener habilitada la computación sin servidor. Véase Conexión a la computación sin servidor.
- Para habilitar la clasificación de datos, debe poseer el catálogo o tener privilegios de
USE_CATALOGyMANAGEsobre él. - Para ver la tabla de resultados, debe tener los siguientes permisos:
USE CATALOGyUSE SCHEMA, además deSELECTen la tabla. Consulte La tabla del sistema de resultados.
Uso de la clasificación de datos
Para usar la clasificación de datos en un catálogo:
Vaya al catálogo y haga clic en la pestaña Detalles .
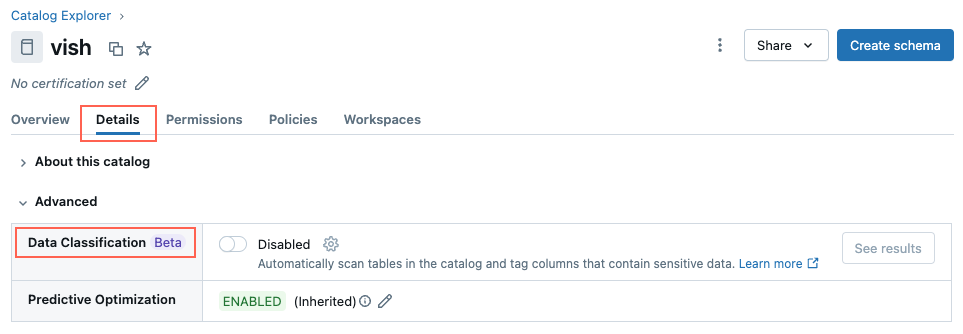
Haga clic en el interruptor Clasificación de datos para habilitarlo.
Aparece el cuadro de diálogo Habilitar clasificación de datos . De forma predeterminada, se incluyen todos los esquemas. Para incluir solo algunos esquemas, selecciónelos en el menú desplegable Esquemas para incluir .
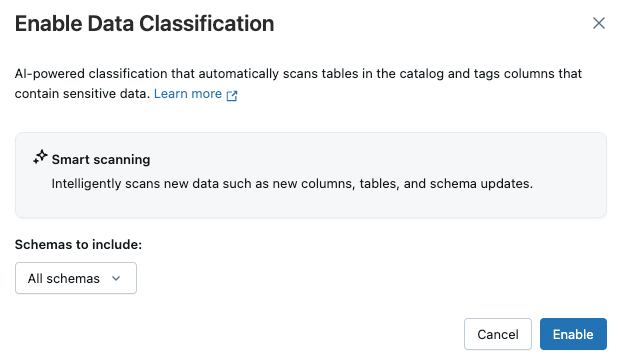
Haga clic en Habilitar.
Esto crea un trabajo en segundo plano que examina incrementalmente todas las tablas del catálogo o esquemas seleccionados.
El motor de clasificación se basa en el examen inteligente para determinar cuándo examinar una tabla. Las nuevas tablas y columnas de un catálogo normalmente se examinan en un plazo de 24 horas a partir de la creación.
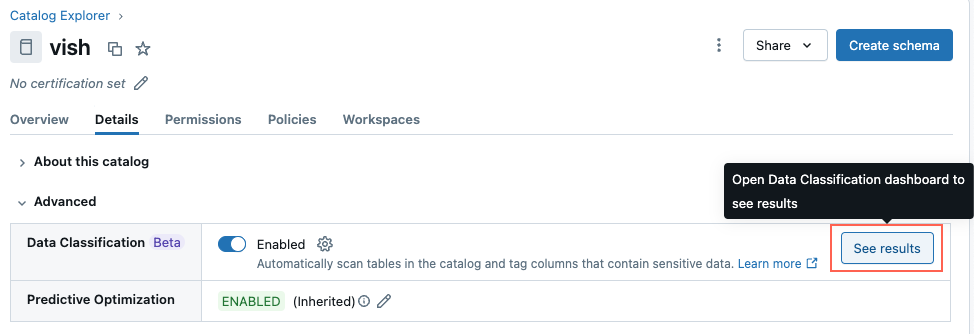
Visualización de los resultados de la clasificación
Para ver los resultados de la clasificación, haga clic en Ver resultados junto al interruptor.
Se abre una página de resultados, en la que se muestran los resultados de clasificación de todas las tablas del catálogo. Para seleccionar otro catálogo, use el selector situado en la parte superior izquierda de la página. Se requiere un almacén SQL sin servidor y se muestra en la esquina superior derecha de la página.
En la página de resultados se enumeran las etiquetas de clasificación identificadas en el catálogo. Las directivas de ABAC existentes que hacen referencia a etiquetas del sistema de clasificación de datos (class.xx) aparecen en la tabla.
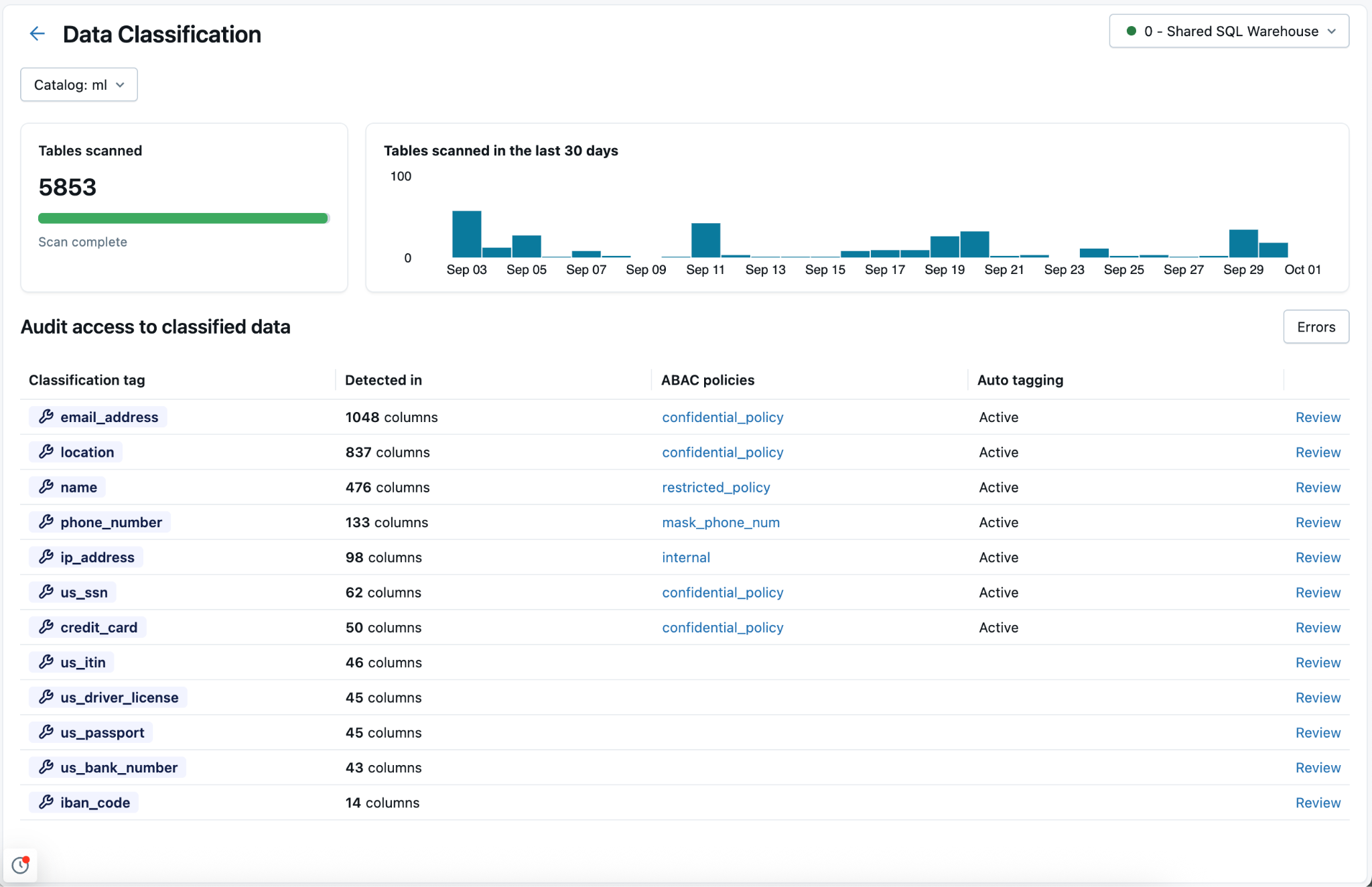
Para revisar los resultados de una etiqueta de clasificación específica, haga clic en Revisar en la columna situada más a la derecha de la fila correspondiente.
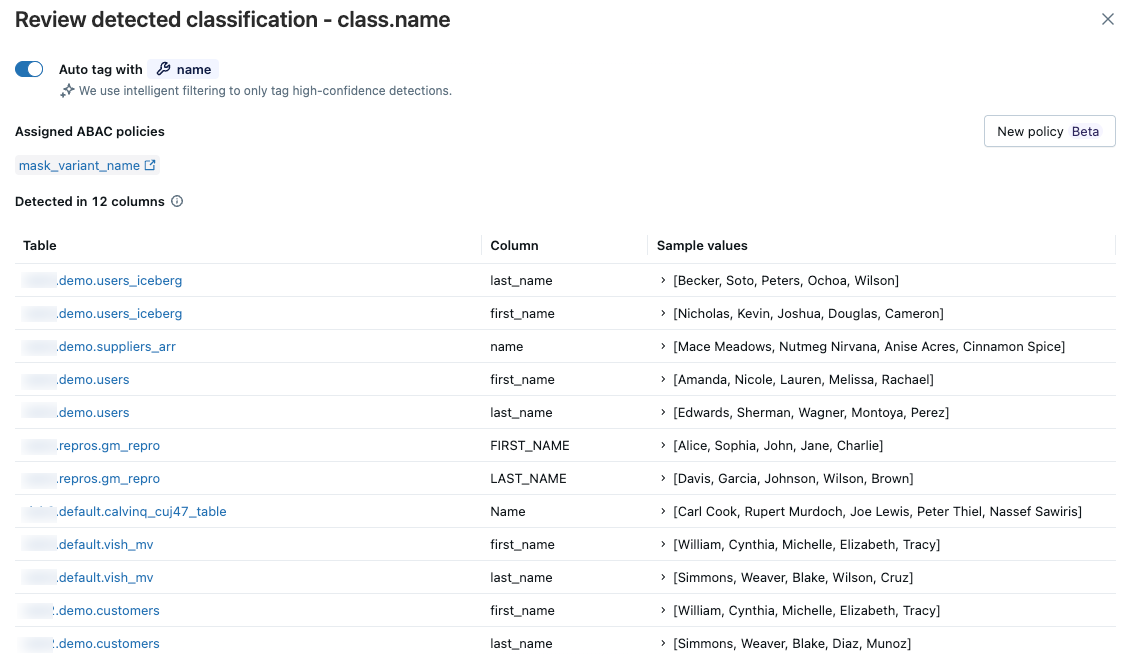
Aparece un panel que muestra las tablas para las que la clasificación de datos ha detectado la etiqueta de clasificación con alta confianza. Revise las tablas, columnas y valores de ejemplo. Los valores de ejemplo solo aparecen si tiene acceso a la tabla de resultados. Consulte La tabla del sistema de resultados.
Si las columnas identificadas coinciden con sus expectativas, puede habilitar el etiquetado automático para la etiqueta de clasificación de este catálogo. Cuando se habilita el etiquetado automático, se etiquetan todas las detecciones existentes y futuras de esta clasificación.
Para habilitar el etiquetado automático, active el interruptor Etiquetado Automático. Más adelante, puede deshabilitar el etiquetado automático con el mismo interruptor. Al deshabilitar el etiquetado, no se aplica ninguna etiqueta futura, pero no se quitan las etiquetas existentes.
Nota:
Al habilitar el etiquetado automático, las etiquetas no se rellenan inmediatamente. Se rellenarán en el siguiente escaneo, que debe entrar en vigor en un plazo de 24 horas. Las clasificaciones posteriores se etiquetarán inmediatamente.
La tabla del sistema de resultados
La clasificación de datos crea una tabla del sistema denominada system.data_classification.results para almacenar los resultados que, de forma predeterminada, solo son accesibles para el administrador de la cuenta. El administrador de la cuenta puede compartir esta tabla. La tabla solo es accesible cuando se utiliza computación sin servidor. Para obtener más información sobre esta tabla, consulte Referencia de tabla del sistema de clasificación de datos.
Importante
La tabla system.data_classification.results de resultados contiene todos los resultados de clasificación en todo el metastore e incluye valores de ejemplo de tablas de cada catálogo. Debe compartir esta tabla únicamente con usuarios que tengan privilegios para ver los resultados de clasificación de todo el metastore, incluidos los valores de muestra.
Los permisos siguientes son necesarios para ver la tabla de resultados: USE CATALOG y USE SCHEMA, además de SELECT en la tabla. Los usuarios con MANAGE o SELECT acceso a un catálogo pueden ver los resultados en la página, pero no pueden ver los valores de ejemplo.
Configuración de controles de gobernanza basados en los resultados de clasificación de datos
Enmascarar datos confidenciales mediante una directiva de ABAC
Databricks recomienda usar el control de acceso basado en atributos (ABAC) de Unity Catalog para crear controles de gobernanza basados en los resultados de la clasificación de datos.
Para crear una directiva, haga clic en Nueva directiva. El formulario de directiva se rellena previamente para enmascarar columnas con la etiqueta de clasificación que se está revisando. Para enmascarar los datos, especifique cualquier función de enmascaramiento registrada en el catálogo de Unity y haga clic en Guardar.
También puede crear una directiva que abarque varias etiquetas de clasificación al cambiar Cuando la columna a cumpla la condición y proporcionando varias etiquetas.
Por ejemplo, para crear una directiva denominada "Confidencial", que enmascara cualquier nombre, correo electrónico o número de teléfono, establezca la condición hasTag("class.name") OR hasTag("class.email_address") OR hasTag("class.phone_number") en .
Detección y eliminación del RGPD
En este cuaderno de ejemplo se muestra cómo puede usar la clasificación de datos para ayudar con la detección y eliminación de datos para el cumplimiento del RGPD.
Detección y eliminación del RGPD mediante el cuaderno de clasificación de datos
Cómo controlar etiquetas incorrectas
Si los datos se etiquetan incorrectamente, puede quitar manualmente la etiqueta. La etiqueta no se volverá a aplicar en exámenes futuros.
Para quitar una etiqueta mediante la interfaz de usuario, vaya a la tabla en el Explorador de catálogos y edite las etiquetas de columna.
Para quitar una etiqueta mediante SQL:
ALTER TABLE catalog.schema.table
ALTER COLUMN col
UNSET TAGS ('class.phone_number', 'class.us_ssn')
Errores de escaneo
Si se producen errores durante el examen, aparece un botón Errores en la esquina superior derecha de la tabla de resultados.
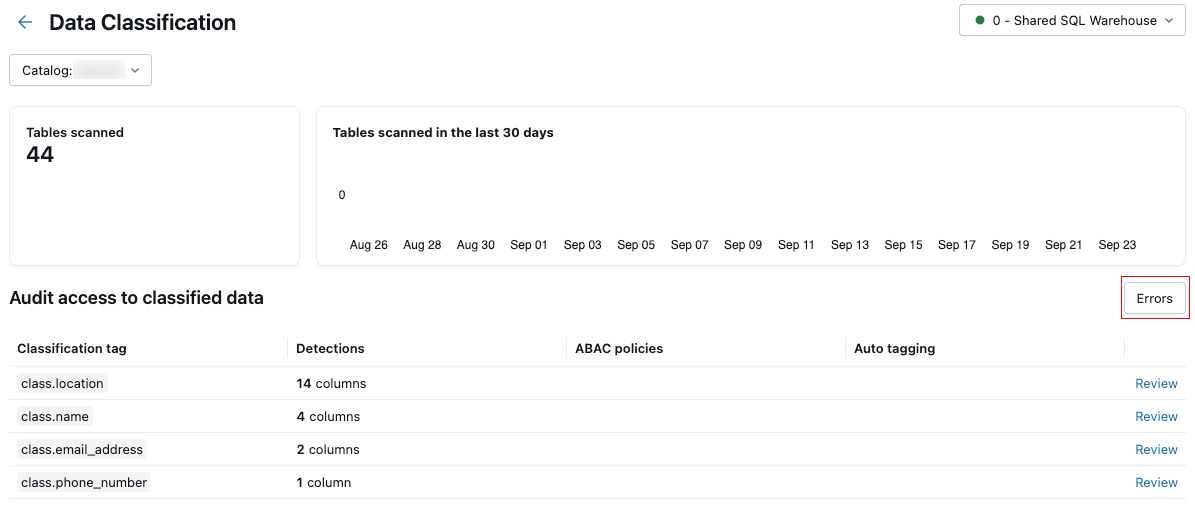
Haga clic en el botón para mostrar las tablas que han producido un error en el examen y los mensajes de error asociados.

De forma predeterminada, los errores que se produjeron para las tablas individuales se omiten y se reintentan el día siguiente.
Ver los gastos de clasificación de datos
Para comprender cómo se factura la clasificación de datos, consulte la página de precios. Puede ver los gastos relacionados con la clasificación de datos ejecutando una consulta o viendo el panel de uso.
Nota:
El examen inicial es más costoso que los exámenes posteriores en el mismo catálogo, ya que esos exámenes son incrementales y normalmente incurren en costos más bajos.
Visualización del uso de la tabla del sistema system.billing.usage
Puede consultar los gastos de clasificación de datos desde system.billing.usage. Los campos created_by y catalog_id se pueden usar opcionalmente para desglosar los costos:
-
created_by: Incluir para ver los costos del usuario que activó el uso. -
catalog_id: Incluya esta opción para ver los costes por catálogo. El identificador de catálogo se muestra en lasystem.data_classification.resultstabla.
Consulta de ejemplo para los últimos 30 días:
SELECT
usage_date,
identity_metadata.created_by,
usage_metadata.catalog_id,
SUM(usage_quantity) AS dbus
FROM
system.billing.usage
WHERE
usage_date >= DATE_SUB(CURRENT_DATE(), 30)
AND billing_origin_product = 'DATA_CLASSIFICATION'
GROUP BY
usage_date,
created_by,
catalog_id
ORDER BY
usage_date DESC,
created_by;
Visualización del uso desde el panel de uso
Si ya tiene un panel de uso configurado en el área de trabajo, puede usarlo para filtrar el uso seleccionando el proyecto de origen de facturación con la etiqueta "Clasificación de datos". Si no tiene configurado un panel de uso, puede importar uno y aplicar el mismo filtrado. Para obtener más información, consulte Paneles de uso.
Etiquetas de clasificación admitidas
En la tabla se enumeran las etiquetas gestionadas por el sistema admitidas por la clasificación de datos.
| Clase | Descripción |
|---|---|
| class.credit_card | Número de tarjeta de crédito |
| class.dirección_correo_electrónico | Dirección de correo electrónico |
| class.iban_code | Número de cuenta bancaria internacional (IBAN) |
| class.ip_address | Dirección de protocolo de Internet (IPv4 o IPv6) |
| class.location | Ubicación |
| class.name | Nombre de una persona |
| class.phone_number // número_de_teléfono | Número de teléfono |
| class.us_bank_number | Número de banco de EE. UU. |
| clase.licencia_conducir_us | Licencia de conducir de EE. UU. |
| class.us_itin | Número de identificación de contribuyente individual de EE. UU. |
| class.pasaporte_eeuu | Pasaporte de EE. UU. |
| class.us_ssn | Número de seguridad social de EE. UU. |
Limitaciones
- No se admiten visualizaciones ni vistas de métricas. Si la vista se basa en tablas existentes, Databricks recomienda clasificar las tablas subyacentes para ver si contienen datos confidenciales.