Nota
L'accés a aquesta pàgina requereix autorització. Pots provar d'iniciar sessió o canviar de directori.
L'accés a aquesta pàgina requereix autorització. Pots provar de canviar directoris.
En esta página se describe cómo leer los datos compartidos con usted mediante el protocolo delta sharing open sharing con tokens de portador. Incluye instrucciones para leer datos compartidos mediante las siguientes herramientas:
- Databricks
- Apache Spark
- Pandas
- Power BI
- Cuadro
- Clientes de Iceberg
En este modelo de uso compartido abierto, se usa un archivo de credenciales, compartido con un miembro del equipo por el proveedor de datos, para obtener acceso de lectura seguro a los datos compartidos. El acceso persiste siempre y cuando las credenciales sean válidas y el proveedor siga compartiendo los datos. Los proveedores administran la expiración y la rotación de credenciales. Las actualizaciones de los datos están disponibles casi en tiempo real. Puede leer y realizar copias de los datos compartidos, pero no puede modificar los datos de origen.
Nota
Si los datos se han compartido con usted mediante Databricks-to-Databricks Delta Sharing, no necesita un archivo de credenciales para acceder a los datos y esta página no se aplica a usted. En su lugar, consulte Leer datos compartidos usando Databricks-to-Databricks Delta Sharing (para destinatarios).
En las secciones siguientes se describe cómo usar los clientes de Azure Databricks, Apache Spark, pandas, Power BI y Iceberg para acceder a los datos compartidos y leerlos mediante el archivo de credenciales. Para obtener una lista completa de los conectores de Delta Sharing e información sobre cómo usarlos, consulte la documentación de orígenes abiertos de Delta Sharing. Si tiene problemas para acceder a los datos compartidos, póngase en contacto con el proveedor de datos.
Antes de empezar
Un miembro de su equipo debe descargar el archivo de credenciales compartido por el proveedor de datos. Consulte Obtener acceso en el modelo de uso compartido abierto.
Deberían usar un canal seguro para compartir ese archivo o su ubicación con usted.
Azure Databricks: lectura de datos compartidos mediante conectores de uso compartido abierto
En esta sección se describe cómo importar un proveedor y cómo consultar los datos compartidos en el Explorador de catálogos o en un cuaderno de Python:
Si el área de trabajo de Azure Databricks está habilitada para el catálogo de Unity, use la interfaz de usuario del proveedor de importación en el Explorador de catálogos. Puede hacer lo siguiente sin necesidad de almacenar o especificar un archivo de credenciales:
- Cree catálogos a partir de recursos compartidos con el clic de un botón.
- Use los controles de acceso del catálogo de Unity para conceder acceso a las tablas compartidas.
- Consulta de datos compartidos mediante la sintaxis estándar del Catálogo de Unity.
Si el área de trabajo de Azure Databricks no está habilitada para el catálogo de Unity, use las instrucciones del cuaderno de Python como ejemplo.
Explorador de catálogos
Permisos necesarios: un administrador de metastore o un usuario que tenga los privilegios CREATE PROVIDER y USE PROVIDER para el metastore de Unity Catalog.
En el área de trabajo de Azure Databricks, haga clic en
 Catálogo para abrir el Explorador de catálogos.
Catálogo para abrir el Explorador de catálogos.En la parte superior del panel Catálogo , haga clic en
 seleccione Delta Sharing.
seleccione Delta Sharing.Como alternativa, en la página Acceso rápido, haga clic en el botón Delta Sharing>.
En la pestaña Compartido conmigo, haga clic en Importar datos.
Escriba el nombre del proveedor.
El nombre no puede incluir espacios.
Cargue el archivo de credenciales que el proveedor ha compartido con usted.
Muchos proveedores tienen sus propias redes de delta Sharing de las que puede recibir recursos compartidos. Para obtener más información, consulte Configuraciones específicas del proveedor.
(Opcional) Escriba un comentario.
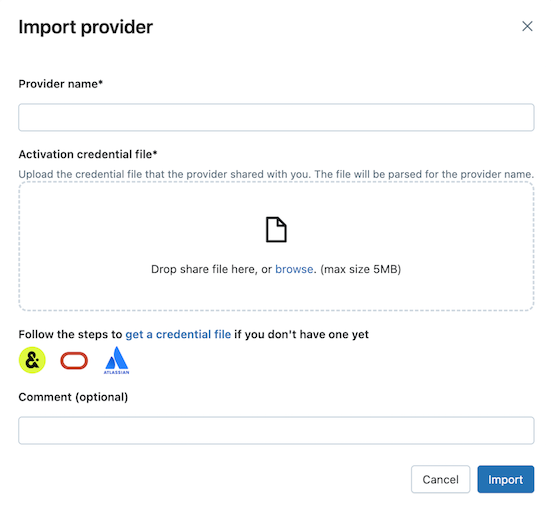
Haga clic en Import.
Cree catálogos a partir de los datos compartidos.
En la pestaña Recursos compartidos, haga clic en Crear catálogo en la fila de recursos compartidos.
Para obtener información sobre el uso de SQL o la CLI de Databricks para crear un catálogo a partir de un recurso compartido, consulte Creación de un catálogo a partir de un recurso compartido.
Conceda acceso a los catálogos.
Consulte ¿Cómo puedo hacer que los datos compartidos estén disponibles para mi equipo? y Administración de permisos para los esquemas, tablas y volúmenes de un catálogo Delta sharing.
Lea los objetos de datos compartidos como haría con cualquier objeto de datos registrado en el Catálogo de Unity.
Para obtener más información y ejemplos, consulte Datos de Access en una tabla o volumen compartidos.
Pitón
Esta sección describe cómo usar un conector de uso compartido abierto para acceder a datos compartidos usando un cuaderno en su área de trabajo de Azure Databricks. Usted u otro miembro del equipo almacenan el archivo de credenciales en Azure Databricks y, a continuación, lo usan para autenticarse en la cuenta de Azure Databricks del proveedor de datos y leer los datos que el proveedor de datos ha compartido con usted.
Nota
En estas instrucciones se supone que el área de trabajo de Azure Databricks no está habilitada para el catálogo de Unity. Si usa Unity Catalog, no es necesario que apunte al archivo de credenciales al leer desde el recurso compartido. Puede leer desde tablas compartidas como lo hace desde cualquier tabla registrada en el catálogo de Unity. Databricks recomienda usar la interfaz de usuario del proveedor de importación en el Explorador de catálogos en lugar de las instrucciones que se proporcionan aquí.
En primer lugar, almacene el archivo de credenciales como un archivo de área de trabajo de Azure Databricks para que los usuarios del equipo puedan acceder a los datos compartidos.
Para importar el archivo de credenciales en el área de trabajo de Azure Databricks, consulte Importación de un archivo.
Conceda a otros usuarios permiso para acceder al archivo haciendo clic en el
 Junto al archivo, después Compartir (permisos). Escriba las identidades de Azure Databricks que deben tener acceso al archivo.
Junto al archivo, después Compartir (permisos). Escriba las identidades de Azure Databricks que deben tener acceso al archivo.Para obtener más información sobre los permisos de archivo, vea ACL de archivo.
Ahora que se almacena el archivo de credenciales, use un cuaderno para enumerar y leer tablas compartidas.
En el área de trabajo de Azure Databricks, haga clic en Nuevo > Cuaderno.
Para más información sobre los cuadernos de Azure Databricks, consulte Cuadernos de Databricks.
Para usar Python o
pandaspara acceder a los datos compartidos, instale el conector delta-sharing de Python. En el editor de cuadernos, pegue el siguiente comando:%sh pip install delta-sharingEjecute la celda.
La
delta-sharingbiblioteca de Python se instala en el clúster si aún no está instalada.Con Python, enumere las tablas del recurso compartido.
En una nueva celda, pegue el siguiente comando. Reemplace la ruta de acceso del área de trabajo por la ruta de acceso del archivo de credenciales.
Cuando se ejecuta el código, Python lee el archivo de credenciales.
import delta_sharing client = delta_sharing.SharingClient(f"/Workspace/path/to/config.share") client.list_all_tables()Ejecute la celda.
El resultado es una matriz de tablas, junto con metadatos para cada tabla. En la salida siguiente se muestran dos tablas:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]Si la salida está vacía o no contiene las tablas que espera, póngase en contacto con el proveedor de datos.
Consulta de una tabla compartida.
Usando Scala:
En una nueva celda, pegue el siguiente comando. Cuando se ejecuta el código, el archivo de credenciales se lee del archivo del área de trabajo.
Reemplace las variables como se muestra a continuación:
-
<profile-path>: la ruta de acceso del archivo de credenciales en el área de trabajo. Por ejemplo,/Workspace/Users/user.name@email.com/config.share. -
<share-name>: valor deshare=para la tabla. -
<schema-name>: valor deschema=para la tabla. -
<table-name>: valor dename=para la tabla.
%scala spark.read.format("deltaSharing") .load("<profile-path>#<share-name>.<schema-name>.<table-name>").limit(10);Ejecute la celda. Cada vez que cargue la tabla compartida, verá datos nuevos del origen.
-
Usando SQL:
Para consultar los datos mediante SQL, cree una tabla local en el área de trabajo a partir de la tabla compartida y, después, consulte la tabla local. Los datos compartidos no se guardan ni almacenan en caché en la tabla local. Cada vez que se consulta la tabla local, se ve el estado actual de los datos compartidos.
En una nueva celda, pegue el siguiente comando.
Reemplace las variables como se muestra a continuación:
-
<local-table-name>: nombre de la tabla local. -
<profile-path>: ubicación del archivo de credenciales. -
<share-name>: valor deshare=para la tabla. -
<schema-name>: valor deschema=para la tabla. -
<table-name>: valor dename=para la tabla.
%sql DROP TABLE IF EXISTS table_name; CREATE TABLE <local-table-name> USING deltaSharing LOCATION "<profile-path>#<share-name>.<schema-name>.<table-name>"; SELECT * FROM <local-table-name> LIMIT 10;Al ejecutar el comando, los datos compartidos se consultan directamente. Como prueba, se consulta la tabla y se devuelven los diez primeros resultados.
-
Si la salida está vacía o no contiene los datos esperados, póngase en contacto con el proveedor de datos.
Apache Spark: Lectura de datos compartidos
Siga estos pasos para acceder a los datos compartidos usando Spark 3.x o superior.
En estas instrucciones se supone que tiene acceso al archivo de credenciales compartido por el proveedor de datos. Consulte Obtener acceso en el modelo de uso compartido abierto.
Importante
Asegúrese de que Apache Spark puede acceder al archivo de credenciales mediante una ruta de acceso absoluta. La ruta de acceso puede hacer referencia a un objeto en la nube o a un volumen de catálogo de Unity.
Nota
Si usa Spark en un área de trabajo de Azure Databricks habilitada para el catálogo de Unity y ha usado la interfaz de usuario del proveedor de importación para importar el proveedor y compartir, las instrucciones de esta sección no se aplican a usted. Puede acceder a tablas compartidas igual que haría con cualquier otra tabla registrada en el catálogo de Unity. No es necesario instalar el conector de delta-sharing Python ni proporcionar la ruta de acceso al archivo de credenciales. Consulte Azure Databricks: Lectura de datos compartidos mediante conectores de uso compartido abierto.
Instalación de los conectores de Python y Spark de Delta Sharing
Para acceder a los metadatos relacionados con los datos compartidos, como la lista de tablas compartidas con usted, haga lo siguiente. Este ejemplo utiliza Python.
Instale el conector delta-sharing de Python. Para obtener información sobre las limitaciones del conector de Python, consulte Limitaciones del conector de Python de Delta Sharing.
pip install delta-sharingInstale el conector de Apache Spark.
Enumeración de tablas compartidas mediante Spark
Enumera las tablas del recurso compartido. En el ejemplo siguiente, reemplace <profile-path> por la ubicación del archivo de credenciales.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
El resultado es una matriz de tablas, junto con metadatos para cada tabla. En la salida siguiente se muestran dos tablas:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
Si la salida está vacía o no contiene las tablas que espera, póngase en contacto con el proveedor de datos.
Acceso a datos compartidos mediante Spark
Ejecute lo siguiente, sustituyendo estas variables:
-
<profile-path>: ubicación del archivo de credenciales. -
<share-name>: valor deshare=para la tabla. -
<schema-name>: valor deschema=para la tabla. -
<table-name>: valor dename=para la tabla. -
<version-as-of>: opcional. Versión de la tabla para cargar los datos. Solo funciona si el proveedor de datos comparte el historial de la tabla. Requieredelta-sharing-spark0.5.0 o superior. -
<timestamp-as-of>: opcional. Cargue los datos en la versión anterior o en la marca de tiempo especificada. Solo funciona si el proveedor de datos comparte el historial de la tabla. Requieredelta-sharing-spark0.6.0 o superior.
Pitón
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
Scala
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
Acceso a una fuente de distribución de datos de cambios compartida mediante Spark
Si el historial de la tabla se ha compartido con usted y el cambio de datos (CDF) está habilitado en la tabla de origen, acceda al cambio de datos ejecutando lo siguiente, reemplazando estas variables. Requiere delta-sharing-spark 0.5.0 o superior.
Se debe proporcionar un parámetro de inicio.
-
<profile-path>: ubicación del archivo de credenciales. -
<share-name>: valor deshare=para la tabla. -
<schema-name>: valor deschema=para la tabla. -
<table-name>: valor dename=para la tabla. -
<starting-version>: opcional. Versión inicial de la consulta, inclusiva. Especifíquelo como Long. -
<ending-version>: opcional. Versión final de la consulta, inclusiva. Si no se proporciona la versión final, la API usa la versión de tabla más reciente. -
<starting-timestamp>: opcional. La marca de tiempo inicial de la consulta, se convierte en una versión creada mayor o igual que esta marca de tiempo. Especifíquelo como una cadena con el formatoyyyy-mm-dd hh:mm:ss[.fffffffff]. -
<ending-timestamp>: opcional. La marca de tiempo final de la consulta, esta se convierte en una versión creada inferior o igual a esta marca de tiempo. Especifíquelo como una cadena con el formatoyyyy-mm-dd hh:mm:ss[.fffffffff].
Pitón
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Scala
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Si la salida está vacía o no contiene los datos esperados, póngase en contacto con el proveedor de datos.
Acceso a una tabla compartida mediante Spark Structured Streaming
Si el historial de tablas se comparte con usted, puede transmitir los datos compartidos. Requiere delta-sharing-spark 0.6.0 o superior.
Opciones admitidas:
-
ignoreDeletes: omitir las transacciones que eliminan los datos. -
ignoreChanges: volver a procesar las actualizaciones si los archivos se volvieron a escribir en la tabla de origen debido a una operación de cambio de datos comoUPDATE,MERGE INTO,DELETE(dentro de las particiones) oOVERWRITE. Todavía se pueden emitir filas sin cambios. Por lo tanto, los consumidores de nivel inferior deben poder controlar los duplicados. Las eliminaciones no se propagan de bajada.ignoreChangesenglobaignoreDeletes. Por lo tanto, si usaignoreChanges, la secuencia no se interrumpe mediante eliminaciones o actualizaciones de la tabla de origen. -
startingVersion: la versión de la tabla compartida desde la que se va a iniciar. Desde esta versión (incluida), la fuente de streaming lee todos los cambios en las tablas. -
startingTimestamp: marca de tiempo desde la que empezar. La fuente de transmisión lee todos los cambios de tabla realizados desde la marca de tiempo en adelante (inclusive). Ejemplo:"2023-01-01 00:00:00.0". -
maxFilesPerTrigger: el número de archivos nuevos por considerar en cada microlote. -
maxBytesPerTrigger: la cantidad de datos que se procesan en cada microlote. Esta opción establece un “máximo temporal”, lo que significa que un lote procesa aproximadamente esta cantidad de datos y puede procesar más que el límite para que la consulta de streaming avance en los casos en los que la unidad de entrada más pequeña sea mayor que este límite. -
readChangeFeed: se lee por streaming la fuente de datos modificados de la tabla compartida.
Opciones no admitidas:
Trigger.availableNow
Ejemplos de consultas de Structured Streaming
Scala
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Pitón
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Consulte también conceptos de Structured Streaming.
Lectura de tablas con vectores de eliminación o asignación de columnas habilitada
Importante
Esta característica está en versión preliminar pública.
Los vectores de eliminación son una característica de optimización de almacenamiento que el proveedor puede habilitar en tablas Delta compartidas. Consulte ¿Qué son los vectores de eliminación?.
Azure Databricks también admite la asignación de columnas para tablas Delta. Consulte Cambiar nombre y quitar columnas con la asignación de columnas de Delta Lake.
Si el proveedor ha compartido una tabla con vectores de eliminación o asignación de columna habilitada, puede leer la tabla mediante el proceso que ejecuta delta-sharing-spark 3.1 o superior. Si usa clústeres de Databricks, puede realizar lecturas por lotes mediante un clúster que ejecute Databricks Runtime 14.1 o superior. Las consultas de CDF y streaming requieren Databricks Runtime 14.2 o superior.
Puede realizar consultas por lotes tal como están, ya que pueden resolver automáticamente responseFormat en función de las características de tabla de la tabla compartida.
Para leer una fuente de distribución de datos modificado (CDF) o para realizar consultas de streaming en tablas compartidas con vectores de eliminación o asignación de columnas habilitadas, debe establecer la opción adicional responseFormat=delta.
En los siguientes ejemplos se muestran consultas por lotes, CDF y streaming:
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
Pandas: lectura de datos compartidos
Siga estos pasos para acceder a los datos compartidos en pandas 0.25.3 o superior.
En estas instrucciones se supone que tiene acceso al archivo de credenciales compartido por el proveedor de datos. Consulte Obtener acceso en el modelo de uso compartido abierto.
Nota
Si usa pandas en un área de trabajo de Azure Databricks habilitada para el catálogo de Unity y ha usado la interfaz de usuario del proveedor de importación para importar el proveedor y compartir, las instrucciones de esta sección no se aplican a usted. Puede acceder a tablas compartidas igual que haría con cualquier otra tabla registrada en el catálogo de Unity. No es necesario instalar el conector de delta-sharing Python ni proporcionar la ruta de acceso al archivo de credenciales. Consulte Azure Databricks: Lectura de datos compartidos mediante conectores de uso compartido abierto.
Instale el conector de Python de Delta Sharing
Para acceder a los metadatos relacionados con los datos compartidos, como la lista de tablas compartidas con usted, debe instalar el conector delta-sharing de Python. Para obtener información sobre las limitaciones del conector de Python, consulte Limitaciones del conector de Python de Delta Sharing.
pip install delta-sharing
Listar tablas compartidas usando pandas
Para enumerar las tablas del recurso compartido, ejecute lo siguiente, sustituyendo <profile-path>/config.share por la ubicación del archivo de credenciales.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Si la salida está vacía o no contiene las tablas que espera, póngase en contacto con el proveedor de datos.
Acceso a datos compartidos mediante pandas
Para acceder a los datos compartidos en pandas mediante Python, ejecute lo siguiente y reemplace las variables de la siguiente manera:
-
<profile-path>: ubicación del archivo de credenciales. -
<share-name>: valor deshare=para la tabla. -
<schema-name>: valor deschema=para la tabla. -
<table-name>: valor dename=para la tabla.
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
Acceso a una fuente de distribución de datos de cambios compartida mediante pandas
Para acceder a la fuente de distribución de datos de cambios de una tabla compartida en pandas mediante Python, ejecute lo siguiente, reemplazando las variables como se indica a continuación. Es posible que la fuente de distribución de datos de cambios no esté disponible, dependiendo de si el proveedor de datos compartió o no la fuente de distribución de datos de cambios para la tabla.
-
<starting-version>: opcional. Versión inicial de la consulta, inclusiva. -
<ending-version>: opcional. Versión final de la consulta, inclusiva. -
<starting-timestamp>: opcional. Marca de tiempo inicial de la consulta. Se convierte en una versión creada mayor o igual que esta marca de tiempo. -
<ending-timestamp>: opcional. Marca de tiempo final de la consulta. Se convierte en una versión creada inferior o igual que esta marca de tiempo.
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
Si la salida está vacía o no contiene los datos esperados, póngase en contacto con el proveedor de datos.
Power BI: leer datos compartidos
|El conector de Delta Sharing de Power BI le permite descubrir, analizar y visualizar conjuntos de datos compartidos con usted a través del protocolo abierto de Delta Sharing.
Requisitos
- Power BI Desktop 2.99.621.0 o superior.
- Acceso al archivo de credenciales compartido por el proveedor de datos. Consulte Obtener acceso en el modelo de uso compartido abierto.
Conexión a Databricks
Para conectarse a Azure Databricks usando el conector de Delta Sharing, haga lo siguiente:
- Abra el archivo de credenciales compartido con un editor de texto para recuperar la URL del punto de conexión y el token.
- Abra Power BI Desktop.
- En el menú Obtener datos, busque Delta Sharing.
- Seleccione el conector y haga clic en Conectar.
- Escriba la dirección URL del punto de conexión que copió del archivo de credenciales en el campo Delta Sharing Server URL (Dirección URL de Delta Sharing).
- Opcionalmente, en la pestaña Opciones avanzadas, establezca un límite de filas para el número máximo de filas que puede descargar. De forma predeterminada, se establece en 1 millón de filas.
- Haga clic en OK.
- En Autenticación, copie el token que recuperó del archivo de credenciales en Token de portador.
- Haga clic en Conectar.
Limitaciones del conector de Delta Sharing de Power BI
El conector de Delta Sharing de Power BI tiene las siguientes limitaciones:
- Los datos que carga el conector deben ajustarse a la memoria de la máquina. Para administrar este requisito, el conector limita el número de filas importadas al límite de filas que estableció en la pestaña Opciones avanzadas de Power BI Desktop.
Tableau: leer datos compartidos
El conector Delta Sharing de Tableau le permite descubrir, analizar y visualizar conjuntos de datos que se comparten con usted a través del protocolo abierto Delta Sharing.
Requisitos
- Tableau Desktop y Tableau Server 2024.1 o superior
- Acceso al archivo de credenciales compartido por el proveedor de datos. Consulte Obtener acceso en el modelo de uso compartido abierto.
Conexión a Azure Databricks
Para conectarse a Azure Databricks usando el conector de Delta Sharing, haga lo siguiente:
- Vaya a Tableau Exchange, siga las instrucciones para descargar el Conector de Delta Sharing y colóquelo en una carpeta apropiada del escritorio.
- Abra Tableau Desktop.
- En la página Conectores, busca "Delta Sharing por Databricks".
- Seleccione Cargar archivo compartido y elija el archivo de credenciales compartido por el proveedor.
- Haga clic en Obtener datos.
- En el Explorador de datos, seleccione la tabla.
- Opcionalmente, agregue filtros SQL o límites de fila.
- Haga clic en Obtener datos de tabla.
Limitaciones
Tableau Delta Sharing Connector tiene las siguientes limitaciones:
- Los datos que carga el conector deben ajustarse a la memoria de la máquina. Para administrar este requisito, el conector limita el número de filas importadas al límite de filas establecido en Tableau.
- Todas las columnas se devuelven como tipo
String. - El filtro SQL solo funciona si el servidor Delta Sharing admite predicateHint.
- No se admiten vectores de eliminación.
- No se admite la asignación de columnas.
Clientes de Iceberg: Leer tablas delta compartidas
Importante
Esta característica está en versión preliminar pública.
Use clientes externos de Iceberg, como Snowflake, Trino, Flink y Spark, para leer recursos de datos compartidos con acceso sin copia utilizando la API del Catálogo REST de Apache Iceberg.
Si usa Snowflake, puede usar el archivo de credenciales para generar un comando SQL que le permita leer tablas delta compartidas.
Obtención de credenciales de conexión
Antes de acceder a los recursos de datos compartidos con clientes externos de Iceberg, recopile las siguientes credenciales:
- El punto de conexión del catálogo REST de Iceberg
- Un token de portador válido
- Nombre del recurso compartido
- (Opcional) El espacio de nombres o el nombre del esquema
- (Opcional) El nombre de la tabla
El punto de conexión rest y el token de portador se encuentran en el archivo de credenciales proporcionado por el proveedor de datos. El nombre del recurso compartido, el espacio de nombres y el nombre de tabla se pueden detectar mediante programación con las APIs de Delta Sharing.
En los ejemplos siguientes se muestra cómo obtener las credenciales adicionales. Escriba el punto de conexión, el punto de conexión Iceberg y el Token Bearer del archivo de credenciales, cuando sea necesario:
// List shares
curl -X GET "<endpoint>/shares" \
-H "Authorization: Bearer <bearerToken>"
// List namespaces
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces" \
-H "Authorization: Bearer <bearerToken>"
// List tables
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces/<namespace>/tables" \
-H "Authorization: Bearer <bearerToken>"
Nota
Este método siempre recupera la lista de activos más up-to-date. Sin embargo, requiere acceso a Internet y puede ser más difícil de integrar en entornos sin código.
Configuración del catálogo de Iceberg
Después de obtener las credenciales de conexión necesarias, configure el cliente para que use los puntos de conexión del catálogo REST de Iceberg para crear y consultar tablas.
Para cada compartición, cree una integración de catálogo.
USE ROLE ACCOUNTADMIN; CREATE OR REPLACE CATALOG INTEGRATION <CATALOG_PLACEHOLDER> CATALOG_SOURCE = ICEBERG_REST TABLE_FORMAT = ICEBERG REST_CONFIG = ( CATALOG_URI = '<icebergEndpoint>', WAREHOUSE = '<share_name>', ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS ) REST_AUTHENTICATION = ( TYPE = BEARER, BEARER_TOKEN = '<bearerToken>' ) ENABLED = TRUE;Opcionalmente, agregue
REFRESH_INTERVAL_SECONDSpara mantener actualizados los metadatos. Establezca el valor en función de la frecuencia de actualización del catálogo.REFRESH_INTERVAL_SECONDS = 30Una vez configurado el catálogo, cree una base de datos a partir del catálogo. Esto crea automáticamente todos los esquemas y tablas de ese catálogo.
CREATE DATABASE <DATABASE_PLACEHOLDER> LINKED_CATALOG = ( CATALOG = <CATALOG_PLACEHOLDER> );Para confirmar que el uso compartido ha sido exitoso, realice una consulta en una tabla de la base de datos. Deberías ver los datos compartidos de Azure Databricks.
Si el resultado está vacío o se produce un error, siga estos pasos comunes de solución de problemas:
- Compruebe los privilegios, el estado de generación de las instantáneas y las credenciales REST.
- Póngase en contacto con el proveedor de datos.
- Consulte la documentación específica de su cliente de Iceberg.
Ejemplo: Leer tablas delta compartidas en Snowflake mediante un comando SQL
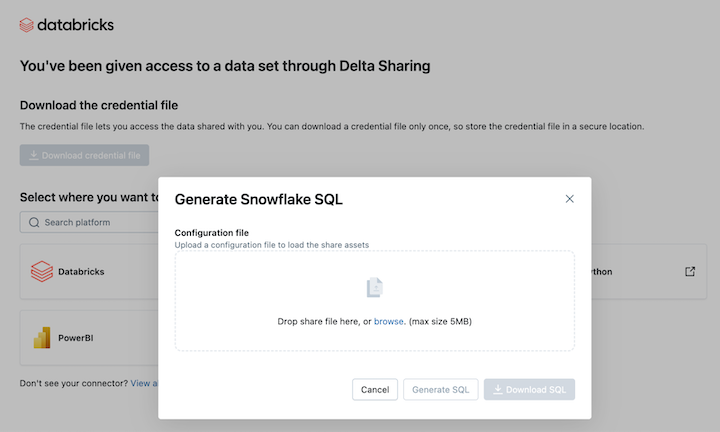
Para leer los recursos de datos compartidos en Snowflake, cargue el archivo de credenciales que descargó y genere el comando SQL necesario:
En el vínculo Activación de Delta Sharing, haga clic en el icono de Snowflake.
En la página de integración de Snowflake, cargue el archivo de credenciales que recibió del proveedor de datos.
Después de cargar la credencial, elija el recurso compartido al que desea acceder en Snowflake.
Haga clic en Generar SQL después de seleccionar los recursos deseados.
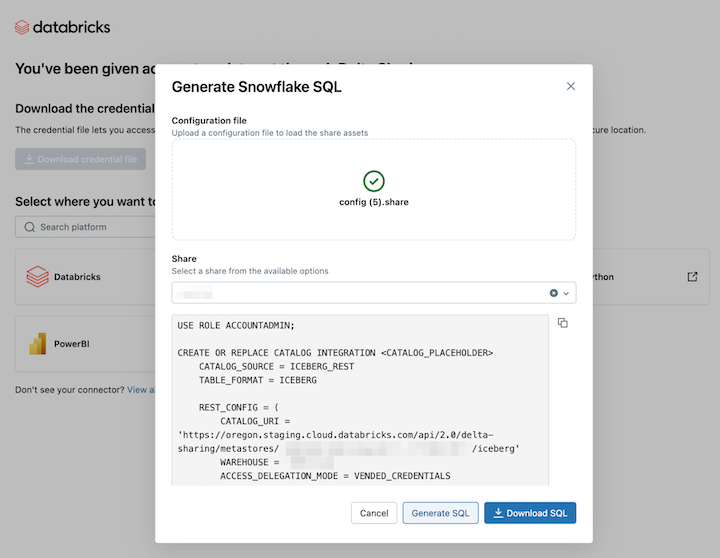
Copie y pegue el CÓDIGO SQL generado en la hoja de cálculo de Snowflake. Reemplace
CATALOG_PLACEHOLDERpor el nombre del catálogo que desea usar yDATABASE_PLACEHOLDERpor el nombre de la base de datos que desea usar.
Limitaciones de Snowflake
La conexión al catálogo REST de Iceberg en Snowflake tiene las siguientes limitaciones:
- El archivo de metadatos no se actualiza automáticamente con la instantánea más reciente. Debe confiar en la actualización automática o en las actualizaciones manuales.
- R2 no es compatible.
- Se aplican todas las limitaciones de cliente de Iceberg .
Limitaciones del cliente de Iceberg
Se aplican las siguientes limitaciones al consultar datos de Delta Sharing desde clientes de Iceberg.
- Al enumerar tablas en un espacio de nombres, si el espacio de nombres contiene más de 100 vistas compartidas, la respuesta se limita a las 100 primeras vistas.
Limitaciones del conector de Python de Delta Sharing
Estas limitaciones son específicas del conector delta sharing de Python:
- El conector de Python delta sharing 1.1.0+ admite consultas de instantáneas en tablas con asignación de columnas, pero no se admiten consultas CDF en tablas con asignación de columnas.
- El conector delta sharing de Python produce un error en las consultas CDF con
use_delta_format=Truesi el esquema ha cambiado durante el intervalo de versiones consultado.
Solicitud de credenciales nuevas
Si la dirección URL de activación de credenciales o las credenciales descargadas se pierden, dañan o ponen en peligro, o sus credenciales expiran sin que el proveedor le envíe unas nuevas, póngase en contacto con el proveedor para solicitar credenciales nuevas.