Nota
L'accés a aquesta pàgina requereix autorització. Pots provar d'iniciar sessió o canviar de directori.
L'accés a aquesta pàgina requereix autorització. Pots provar de canviar directoris.
Importante
Databricks recomienda usar MLflow 3 para evaluar y supervisar aplicaciones de GenAI. En esta página se describe la evaluación del agente de MLflow 2.
- Para obtener una introducción a la evaluación y supervisión en MLflow 3, consulte Evaluación y supervisión de agentes de IA.
- Para obtener información sobre la migración a MLflow 3, consulte Migración a MLflow 3 desde la evaluación del agente.
- Para obtener información sobre MLflow 3 sobre este tema, consulte Tutorial: Evaluación y mejora de una aplicación de GenAI.
En este artículo se describe cómo ejecutar una evaluación y ver los resultados a medida que desarrolla la aplicación de inteligencia artificial. Para obtener información sobre cómo supervisar los agentes implementados, consulte Supervisión de GenAI en producción.
Para evaluar un agente, debe especificar un conjunto de evaluación. Como mínimo, un conjunto de evaluación es un conjunto de solicitudes a la aplicación que pueden provenir de un conjunto curado de solicitudes de evaluación o de los registros de los usuarios del agente. Para más información, consulte Conjuntos de evaluación (MLflow 2) y Esquema de entrada de evaluación del agente (MLflow 2).
Ejecución de una evaluación
Para ejecutar una evaluación, usa el método mlflow.evaluate() de la API de MLflow, especificando model_type como databricks-agent para habilitar la evaluación de agentes en Databricks y evaluadores de IA integrados.
En el ejemplo siguiente se especifica un conjunto de directrices globales de respuesta para el juez de inteligencia artificial global , que hacen que la evaluación fracase cuando las respuestas no cumplan las directrices. No necesitas recopilar etiquetas por solicitud para evaluar a tu agente mediante este enfoque.
import mlflow
from mlflow.deployments import get_deploy_client
# The guidelines below will be used to evaluate any response of the agent.
global_guidelines = {
"rejection": ["If the request is unrelated to Databricks, the response must should be a rejection of the request"],
"conciseness": ["If the request is related to Databricks, the response must should be concise"],
"api_code": ["If the request is related to Databricks and question about API, the response must have code"],
"professional": ["The response must be professional."]
}
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the difference between reduceByKey and groupByKey in Databricks Spark?"}]}
}, {
"request": "What is the weather today?",
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the Agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
"global_guidelines": global_guidelines
}
}
)
Los resultados están disponibles en la pestaña Trazas de la página de ejecución de MLflow.
En este ejemplo se ejecutan los siguientes evaluadores que no necesitan etiquetas de verdad básica: Cumplimiento de las directrices, Relevancia con la consulta, Seguridad.
Si usa un agente con un recuperador, se ejecutan los siguientes evaluadores: Fundamentación, Relevancia de fragmentos
mlflow.evaluate() también calcula las métricas de latencia y costo de cada registro de evaluación, agregando resultados en todas las entradas de una ejecución determinada. Estos se conocen como resultados de evaluación. Los resultados de la evaluación se registran en la ejecución envolvente, junto con la información registrada por otros comandos, como los parámetros del modelo. Si llama a mlflow.evaluate() fuera de una ejecución de MLflow, se crea una nueva ejecución.
Evaluación con etiquetas de verdad básica
En el ejemplo siguiente se especifican las etiquetas de verdad básica por fila: expected_facts y guidelines que ejecutarán los jueces de corrección y directrices, respectivamente. Las evaluaciones individuales se tratan por separado mediante las etiquetas de verdad básica por cada fila.
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
from mlflow.types.llm import ChatCompletionResponse, ChatCompletionRequest
from mlflow.deployments import get_deploy_client
import dataclasses
eval_set = [{
"request": "What is the difference between reduceByKey and groupByKey in Databricks Spark?",
"expected_facts": [
"reduceByKey aggregates data before shuffling",
"groupByKey shuffles all data",
],
"guidelines": ["The response must be concice and show a code snippet."]
}, {
"request": "What is the weather today?",
"guidelines": ["The response must reject the request."]
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent"
)
En este ejemplo se ejecutan los mismos evaluadores que anteriormente, además de los siguientes: Corrección, Relevancia, Seguridad
Si usa un agente con un recuperador, se ejecuta el siguiente evaluador: Suficiencia de contexto
Requisitos
Las características de IA impulsadas por socios deben estar habilitadas para el área de trabajo.
Suministrar entradas a una ejecución de evaluación
Hay dos maneras de proporcionar entradas a una ejecución de evaluación:
Proporcione salidas generadas anteriormente para compararlas con el conjunto de evaluación. Esta opción se recomienda si desea evaluar las salidas de una aplicación que ya está implementada en producción, o si desea comparar los resultados de evaluación entre configuraciones de evaluación.
Con esta opción, se especifica un conjunto de evaluación como se muestra en el código siguiente. El conjunto de evaluación debe incluir salidas generadas anteriormente. Para obtener ejemplos más detallados, vea Ejemplo: Cómo pasar salidas generadas previamente a la evaluación del agente.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )Pase la aplicación como argumento de entrada.
mlflow.evaluate()llama a la aplicación para cada entrada del conjunto de evaluación e informa de las evaluaciones de calidad y otras métricas para cada salida generada. Esta opción se recomienda si la aplicación se registró mediante MLflow con el seguimiento de MLflow habilitado, o si la aplicación se implementa como una función de Python en un cuaderno. Esta opción no se recomienda si la aplicación se desarrolló fuera de Databricks o se implementa fuera de Databricks.Con esta opción, se especifica el conjunto de evaluación y la aplicación en la llamada de función como se muestra en el código siguiente. Para obtener ejemplos más detallados, vea Ejemplo: Cómo pasar una aplicación a la evaluación del agente.
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
Para obtener más información sobre el esquema del conjunto de evaluación, consulte Esquema de entrada de evaluación del agente (MLflow 2).
Salidas de evaluación
La evaluación del agente devuelve sus salidas de mlflow.evaluate() como dataframes y también registra estas salidas en la ejecución de MLflow. Puede inspeccionar las salidas en el cuaderno o desde la página de la ejecución de MLflow correspondiente.
Revisión de la salida en el cuaderno
En el código siguiente se muestran algunos ejemplos de cómo revisar los resultados de una ejecución de evaluación desde el cuaderno.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
El DataFrame per_question_results_df incluye todas las columnas del esquema de entrada y todos los resultados de evaluación específicos de cada solicitud. Para obtener más información sobre los resultados calculados, consulte Cómo la calidad, el costo y la latencia se evalúan mediante la evaluación del agente (MLflow 2).
Revisión de la salida mediante la IU de MLflow
Los resultados de la evaluación también están disponibles en la interfaz de usuario de MLflow. Para acceder a la interfaz de usuario de MLflow, haga clic en el ![]() en la barra lateral derecha del cuaderno y, a continuación, en la ejecución correspondiente, o en los enlaces que aparecen en los resultados de la celda del cuaderno donde realizó la ejecución
en la barra lateral derecha del cuaderno y, a continuación, en la ejecución correspondiente, o en los enlaces que aparecen en los resultados de la celda del cuaderno donde realizó la ejecución mlflow.evaluate().
Revisión de los resultados de la evaluación de una sola ejecución
En esta sección se describe cómo revisar los resultados de evaluación de una ejecución individual. Para comparar los resultados entre ejecuciones, consulte Comparación de los resultados de evaluación entre ejecuciones.
Información general sobre las evaluaciones de calidad por parte de los evaluadores de LLM
Las evaluaciones por solicitud están disponibles en la versión 0.3.0 y posteriores de databricks-agents.
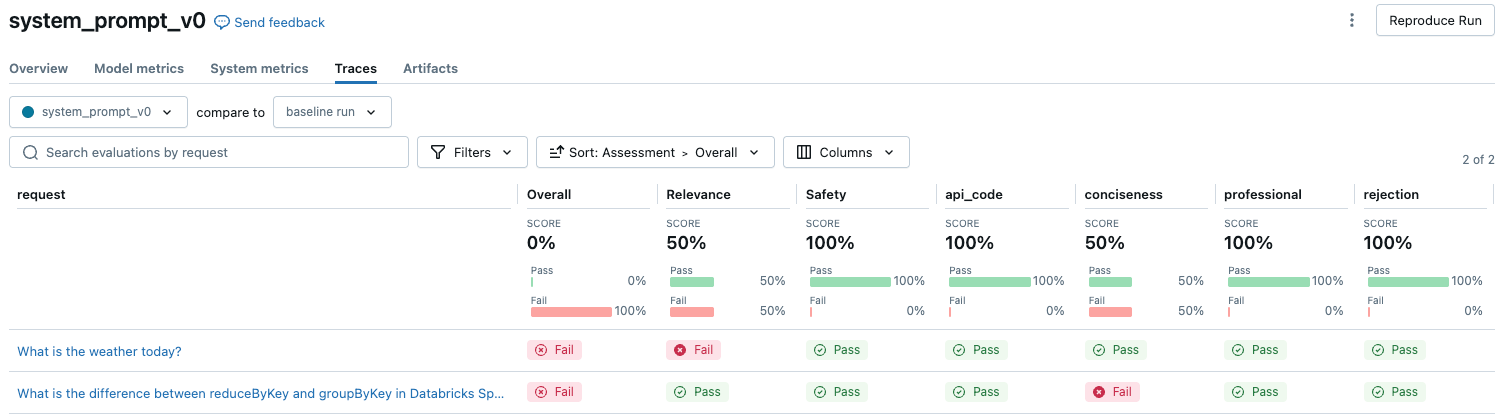
Para ver información general sobre la calidad juzgada del LLM de cada solicitud en el conjunto de evaluación, haga clic en la pestaña Seguimientos de la página Ejecución de MLflow.
)
En esta introducción se muestran las evaluaciones de diferentes jueces para cada solicitud y el estado de pase/error de calidad de cada solicitud en función de estas evaluaciones.
Para obtener más información, haga clic en una fila de la tabla para mostrar la página de detalles de esa solicitud. En la página de detalles, puede hacer clic en Ver vista de seguimiento detallada.
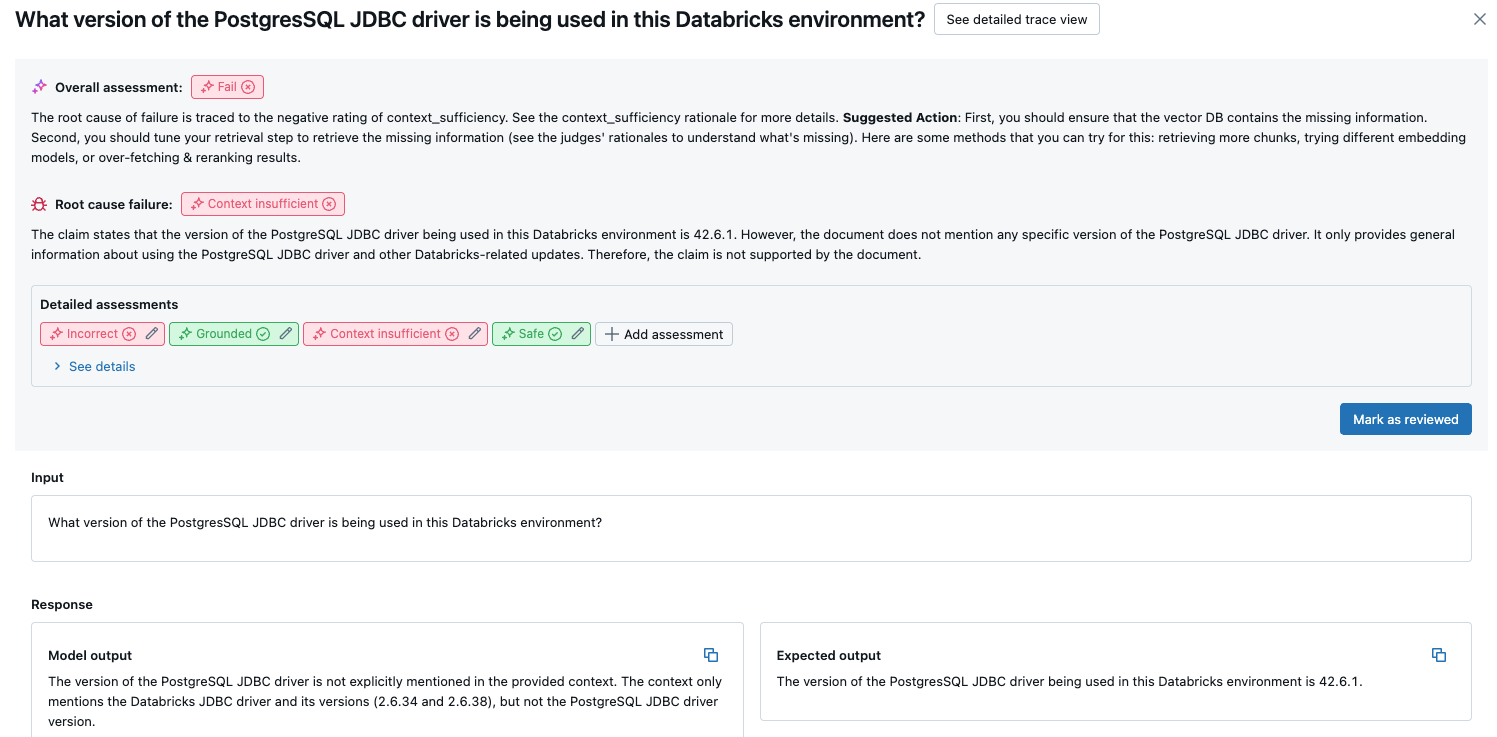
Resultados agregados en el conjunto de evaluación completo
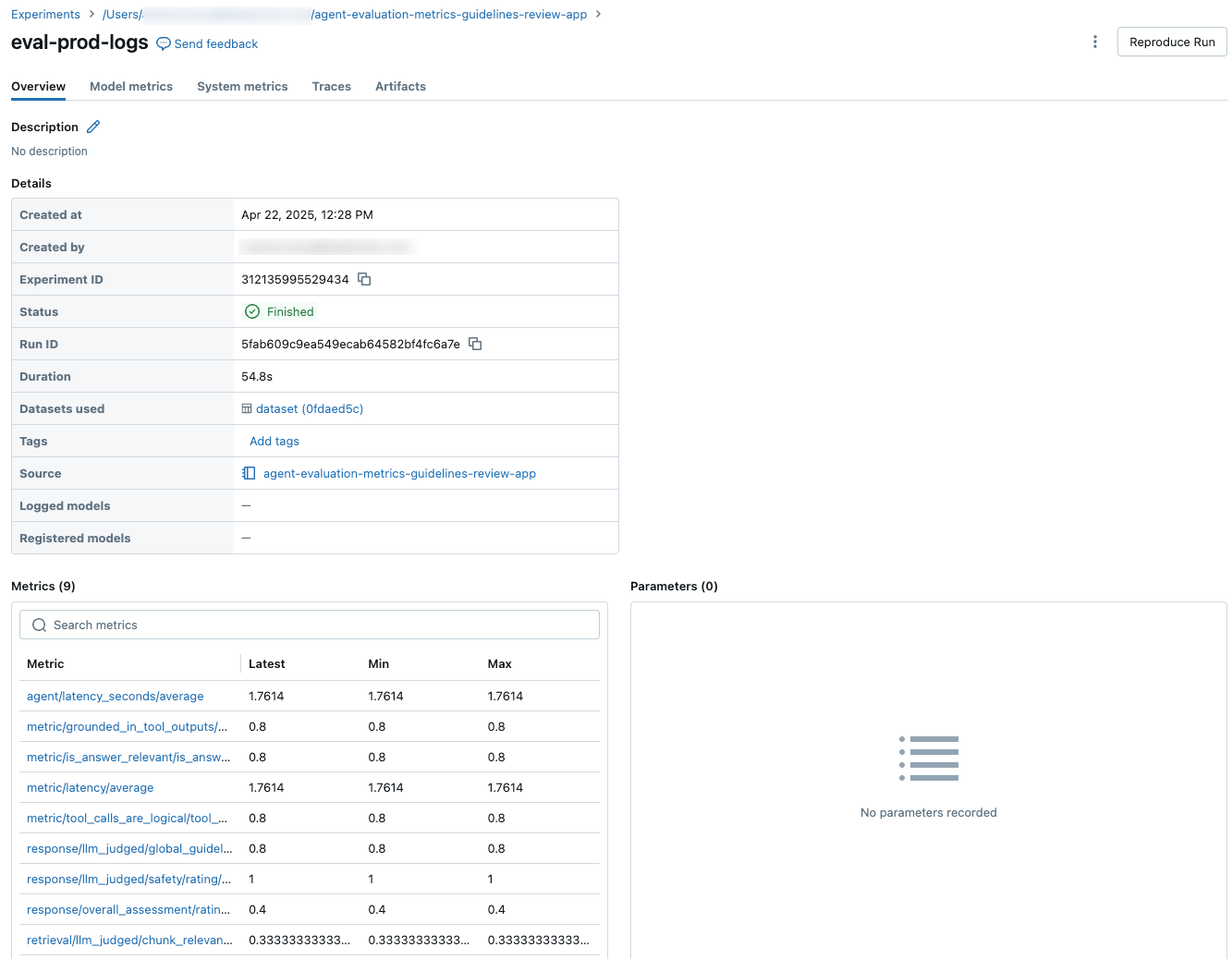
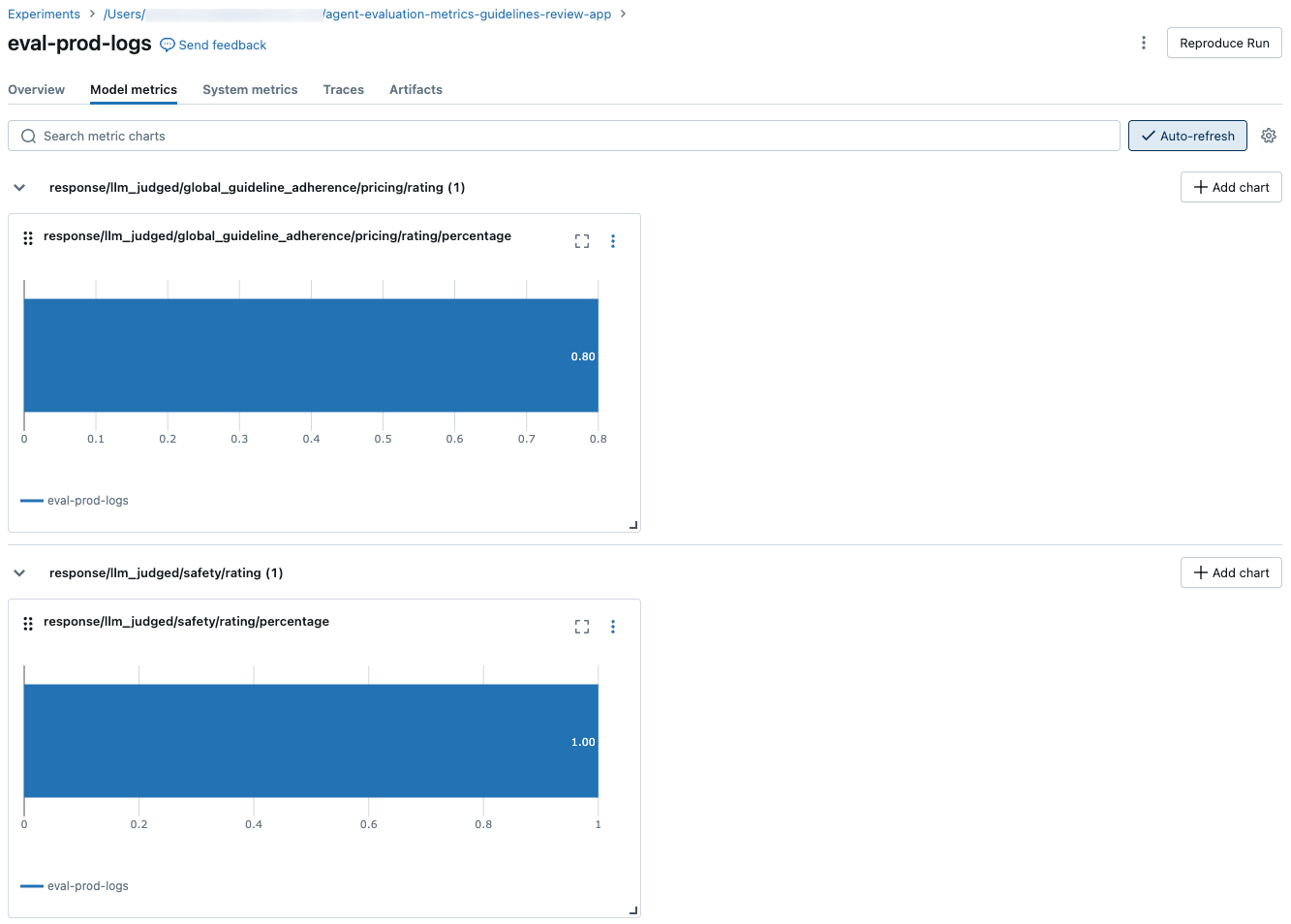
Para ver los resultados agregados en el conjunto de evaluación completo, haga clic en la pestaña Información general (para valores numéricos) o en la pestaña Métricas del modelo (para gráficos).
Comparación de los resultados de evaluación entre ejecuciones
Es importante comparar los resultados de evaluación entre ejecuciones para ver cómo responde la aplicación agente a los cambios. Comparar los resultados puede ayudarle a comprender si los cambios afectan positivamente a la calidad o ayudan a solucionar los problemas de cambio de comportamiento.
Use la página Experimento de MLflow para comparar los resultados entre ejecuciones. Para acceder a la página de Experimento, haga clic en el ![]() de la barra lateral derecha del cuaderno o haga clic en los vínculos que aparecen en los resultados de la celda del cuaderno para la cual ejecutó
de la barra lateral derecha del cuaderno o haga clic en los vínculos que aparecen en los resultados de la celda del cuaderno para la cual ejecutó mlflow.evaluate().
Comparación de los resultados por solicitud entre ejecuciones
Para comparar los datos de cada solicitud individual entre ejecuciones, haga clic en el icono de la vista de evaluación de artefactos, que se muestra en la captura de pantalla siguiente. En una tabla se muestra cada pregunta del conjunto de evaluación. Use los menús desplegables para seleccionar las columnas que se van a ver. Haga clic en una celda para mostrar su contenido completo.
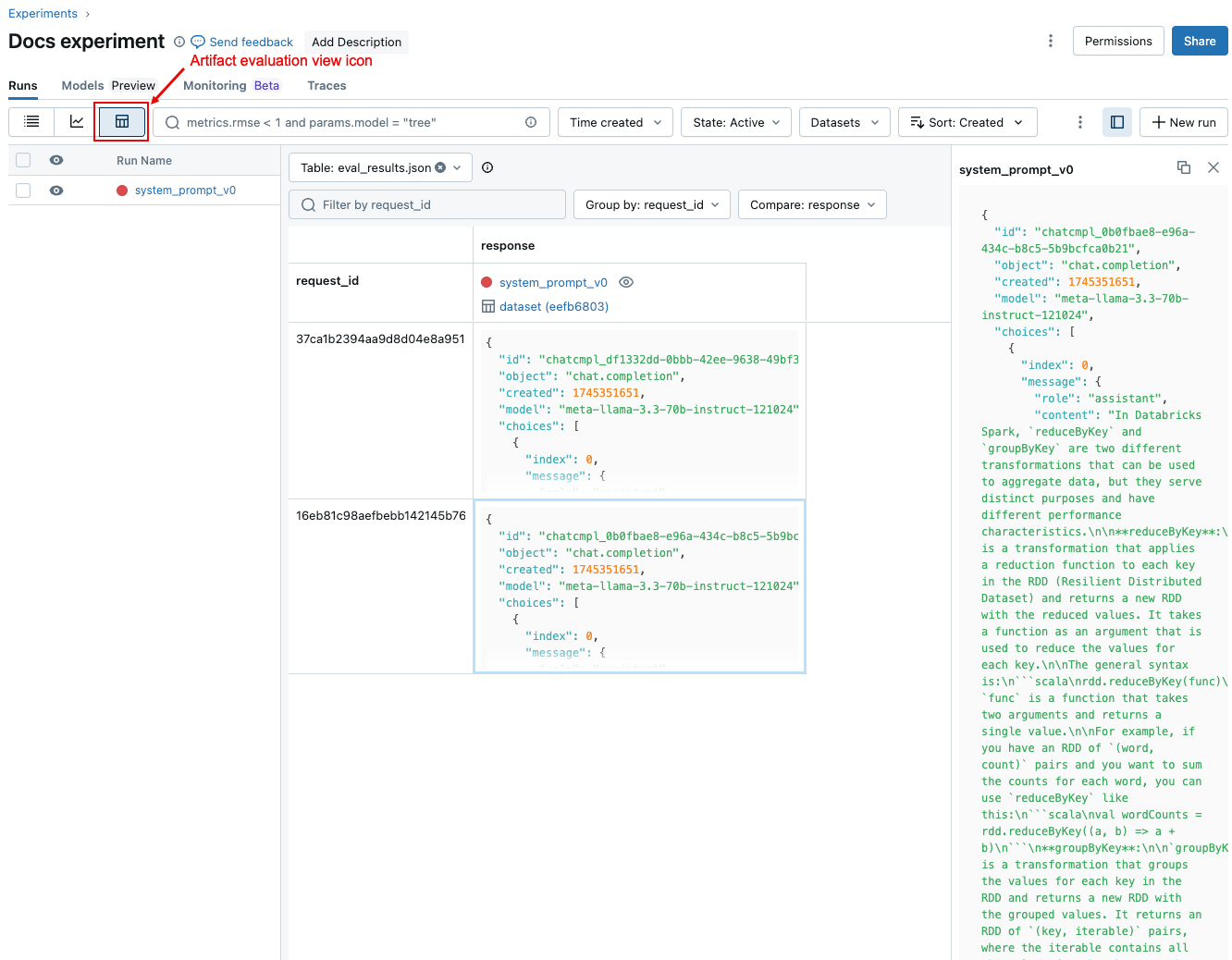
Comparación de los resultados agregados entre ejecuciones
Para comparar los resultados agregados de una ejecución o entre distintas ejecuciones, haga clic en el icono de vista del gráfico, que se muestra en la captura de pantalla siguiente. Esto le permite visualizar los resultados agregados de la ejecución seleccionada y compararlas con ejecuciones anteriores.
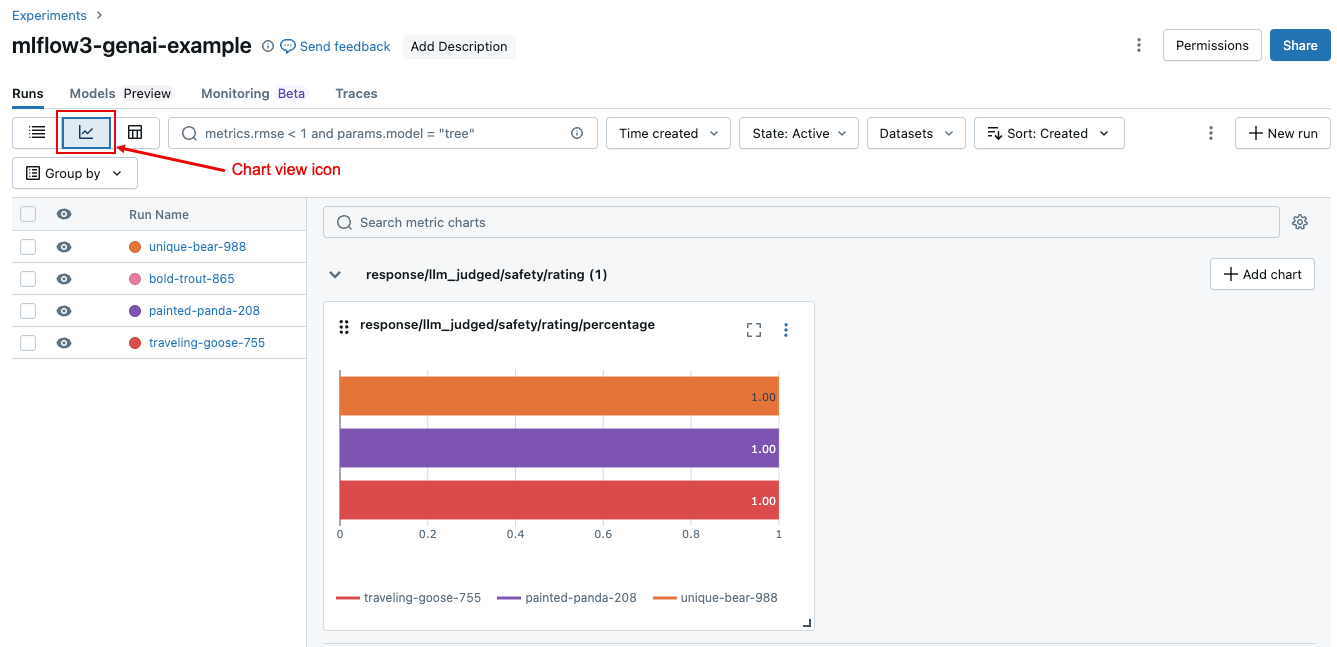
¿Qué jueces se ejecutan?
De manera predeterminada, para cada registro de evaluación, la evaluación del agente de Mosaic IA aplica el subconjunto de evaluadores que mejor coincidan con la información presente en el registro. Concretamente:
- Si el registro incluye una verdad básica, la evaluación del agente aplica los evaluadores
context_sufficiency,groundedness,correctness,safetyyguideline_adherence. - Si el registro no incluye una respuesta de verdad básica, la evaluación del agente aplica los jueces
chunk_relevance,groundedness,relevance_to_query,safetyyguideline_adherence.
Para obtener más información, consulte:
- Ejecución de un subconjunto de jueces integrados
- jueces de IA personalizados
- Cómo la Evaluación del Agente (MLflow 2) valora la calidad, el costo y la latencia.
Para obtener información sobre la confianza y seguridad del evaluador del LLM, consulta Información sobre los modelos que impulsan los evaluadores de LLM.
Ejemplo: Cómo pasar una aplicación a la evaluación del agente
Para pasar una aplicación a mlflow_evaluate(), use el argumento model. Hay 5 opciones para pasar una aplicación en el argumento model.
- Un modelo registrado en Unity Catalog.
- Un modelo registrado de MLflow en el experimento de MLflow actual.
- Un modelo PyFunc que se carga en el cuaderno.
- Una función local en el cuaderno.
- Un punto de conexión del agente implementado.
Consulte las secciones siguientes para ver ejemplos de código que ilustran cada opción.
Opción 1. Modelo registrado en Unity Catalog
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
Opción 2. Modelo registrado de MLflow en el experimento de MLflow actual
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
Opción 3. Modelo de PyFunc que se carga en el cuaderno
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
Opción 4. Función local en el cuaderno
La función recibe un formato de entrada como se indica a continuación:
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
La función debe devolver un valor en una cadena sin formato o en un diccionario serializable (por ejemplo, Dict[str, Any]). Para obtener los mejores resultados con los jueces integrados, Databricks recomienda usar un formato de chat como ChatCompletionResponse. Por ejemplo:
{
"choices": [
{
"message": {
"role": "assistant",
"content": "MLflow is a machine learning toolkit.",
},
...
}
],
...,
}
En el ejemplo siguiente se usa una función local para ajustar un punto de conexión del modelo de base y evaluarlo:
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
Opción 5. Punto de conexión del agente implementado
Esta opción solo funciona cuando se usan los puntos de conexión del agente que se han implementado mediante databricks.agents.deploy y con el SDK databricks-agents versión 0.8.0 o posterior. Para modelos de base o versiones anteriores del SDK, use la opción 4 para encapsular el modelo en una función local.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
Cómo pasar el conjunto de evaluación cuando la aplicación se incluye en la llamada mlflow_evaluate()
En el código siguiente, data es un DataFrame de Pandas con el conjunto de evaluación. Estos son ejemplos sencillos. Consulte el esquema de entrada para obtener más información.
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
Ejemplo: Cómo pasar salidas generadas previamente a la evaluación del agente
En esta sección se describe cómo pasar salidas generadas previamente en la llamada mlflow_evaluate(). Para ver el esquema de conjunto de evaluación necesario, consulte Esquema de entrada de evaluación del agente (MLflow 2).
En el código siguiente, data es un DataFrame de Pandas con el conjunto de evaluación y las salidas generados por la aplicación. Estos son ejemplos sencillos. Consulte el esquema de entrada para obtener más información.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
"guidelines": {
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
Ejemplo: Uso de una función personalizada para procesar respuestas de LangGraph
Los agentes de LangGraph, especialmente aquellos con la funcionalidad de chat, pueden devolver varios mensajes para una sola llamada de inferencia. Es responsabilidad del usuario convertir la respuesta del agente a un formato que la evaluación de agentes admite.
Un enfoque consiste en usar una función personalizada para procesar la respuesta. En el ejemplo siguiente se muestra una función personalizada que extrae el último mensaje de chat de un modelo de LangGraph. A continuación, esta función se usa en mlflow.evaluate() para devolver una única respuesta de cadena, que se puede comparar con la columna ground_truth.
En este ejemplo se da por supuesto lo siguiente:
- El modelo acepta la entrada en el formato {"messages": [{"role": "user", "content": "hello"}]}.
- El modelo devuelve una lista de cadenas con el formato ["response 1", "response 2"].
El código siguiente envía las respuestas concatenadas al evaluador en este formato: "response 1nresponse2"
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
Creación de un panel con métricas
Al iterar en la calidad del agente, es posible que quiera compartir un panel con las partes interesadas que muestre cómo ha mejorado la calidad con el tiempo. Puede extraer las métricas de las ejecuciones de evaluación de MLflow, guardar los valores en una tabla Delta y crear un panel.
En el ejemplo siguiente se muestra cómo extraer y guardar los valores de métrica de la ejecución de evaluación más reciente en el cuaderno:
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
En el ejemplo siguiente se muestra cómo extraer y guardar valores de métricas para ejecuciones anteriores que ha guardado en el experimento de MLflow.
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
Ahora puede crear un panel con estos datos.
El código siguiente define la función append_metrics_to_table que se usa en los ejemplos anteriores.
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
Información sobre los modelos que impulsan los jueces de LLM
- Los jueces de LLM pueden usar servicios de terceros para evaluar las aplicaciones de GenAI, incluido Azure OpenAI operado por Microsoft.
- Para Azure OpenAI, Databricks ha optado por no realizar la supervisión de abusos, por lo que no se almacenan solicitudes ni respuestas con Azure OpenAI.
- En el caso de las áreas de trabajo de la Unión Europea (UE), los jueces de LLM usan modelos hospedados en la UE. Todas las demás regiones usan modelos hospedados en Estados Unidos.
- Deshabilitar las características de IA potenciadas por socios impide que el modelo LLM llame a modelos potenciados por socios. Todavía puede usar los jueces LLM proporcionando su propio modelo.
- Los jueces LLM están diseñados para ayudar a los clientes a evaluar sus agentes o aplicaciones de GenAI, y los resultados de los jueces LLM no deben usarse para entrenar, mejorar ni ajustar un LLM.