Nota
L'accés a aquesta pàgina requereix autorització. Podeu provar d'iniciar la sessió o de canviar els directoris.
L'accés a aquesta pàgina requereix autorització. Podeu provar de canviar els directoris.
En este artículo se proporciona información general de alto nivel sobre la arquitectura de Azure Databricks, incluida su arquitectura empresarial, en combinación con Azure.
Objetos de Databricks
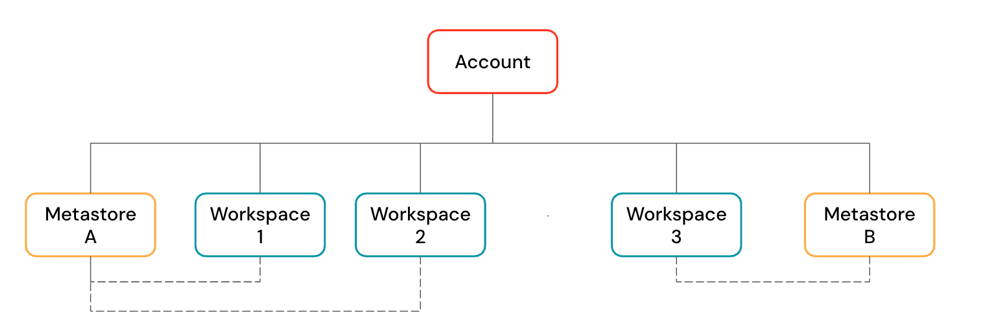
Una cuenta de Azure Databricks es la construcción de nivel superior que se usa para administrar Azure Databricks en toda la organización. En el nivel de cuenta, se administra:
- Identidad y acceso: usuarios, grupos, entidades de servicio y aprovisionamiento de usuarios.
Administración del área de trabajo: cree, actualice y elimine áreas de trabajo en varias regiones.
Administración de metastores del catálogo de Unity: cree y adjunte metastore a áreas de trabajo.
Administración de uso: facturación, cumplimiento y directivas.
Una cuenta puede contener múltiples espacios de trabajo y metastores de Unity Catalog.
Las áreas de trabajo son el entorno de colaboración en el que los usuarios ejecutan cargas de trabajo de proceso, como ingesta, exploración interactiva, trabajos programados y aprendizaje automático.
Los metastores del catálogo de Unity son el sistema de gobernanza central para los recursos de datos, como tablas y modelos de ML. Los datos se organizan en un espacio de nombres de tres niveles dentro de un metastore.
<catalog-name>.<schema-name>.<object-name>
Las tiendas de metadatos están conectadas a áreas de trabajo. Puede vincular un único metastore a varias áreas de trabajo de Azure Databricks en la misma región, lo que proporciona a cada área de trabajo la misma vista de datos. Los controles de acceso a datos se pueden administrar en todas las áreas de trabajo vinculadas.
Arquitectura del área de trabajo
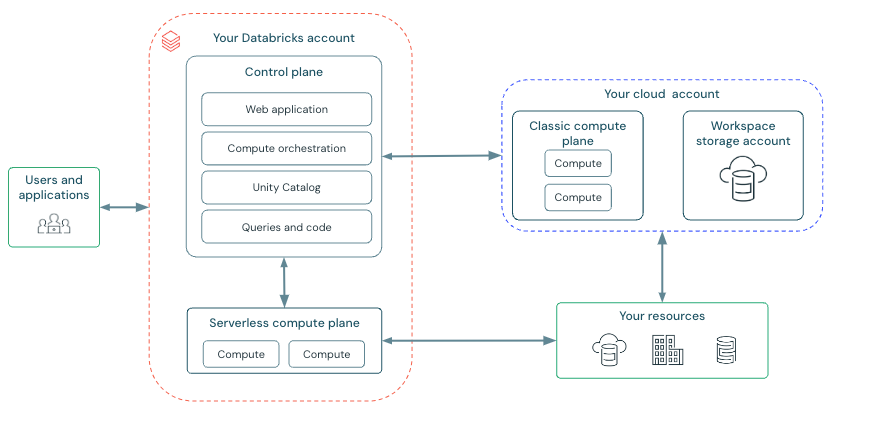
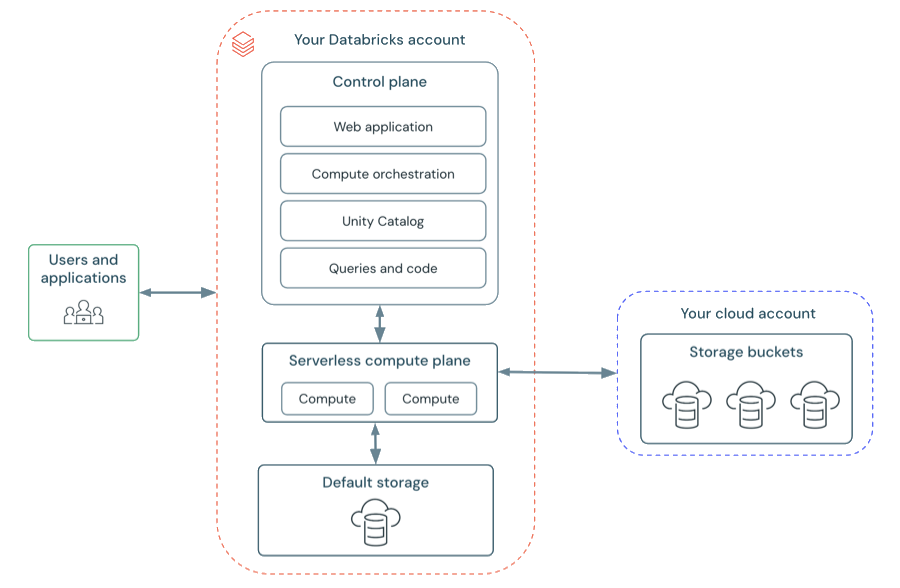
Azure Databricks funciona desde un plano de control y un plano de proceso.
El plano de control incluye los servicios de infraestructura que Azure Databricks gestiona dentro de su cuenta de Azure Databricks. El plano de control se encuentra en la cuenta de Azure Databricks, no en la cuenta en la nube. La aplicación web está en el plano de control.
El plano de procesoes donde se procesan los datos. Hay dos tipos de planos de proceso en función del proceso que use.
- Para el proceso sin servidor, los recursos de proceso sin servidor se ejecutan en un plano de proceso sin servidor en la cuenta de Azure Databricks.
- Para el proceso clásico de cálculos de Azure Databricks, los recursos informáticos se encuentran en su suscripción de Azure en lo que se llama el plano de proceso clásico. Esto hace referencia a la red de la suscripción de Azure y sus recursos.
Para más información sobre el proceso clásico y el proceso sin servidor, consulte Proceso.
Arquitectura del área de trabajo clásica
Nota:
Las áreas de trabajo clásicas se conocen como áreas de trabajo híbridas en Azure Portal.
Las áreas de trabajo clásicas de Azure Databricks tienen una cuenta de almacenamiento asociada conocida como cuenta de almacenamiento del área de trabajo. La cuenta de almacenamiento del área de trabajo está en la suscripción de Azure.
En el diagrama siguiente se describe la arquitectura general de Azure Databricks para las áreas de trabajo clásicas.
Arquitectura del área de trabajo sin servidor
El almacenamiento del área de trabajo en áreas de trabajo sin servidor se almacena en el almacenamiento predeterminado del área de trabajo. También puede conectarse a la cuenta de almacenamiento en la nube para acceder a los datos. En el diagrama siguiente se describe la arquitectura general de las áreas de trabajo sin servidor.
Plano de proceso sin servidor
En el plano de proceso sin servidor, los recursos de proceso de Azure Databricks se ejecutan en una capa de proceso dentro de la cuenta de Azure Databricks. Azure Databricks crea un plano de proceso sin servidor en la misma región de Azure que el plano de proceso clásico del área de trabajo. Usted selecciona esta región al crear un área de trabajo.
Para proteger los datos de los clientes dentro del plano de proceso sin servidor, el proceso sin servidor se ejecuta dentro de un límite de red para el área de trabajo, con varias capas de seguridad para aislar diferentes áreas de trabajo de cliente de Azure Databricks y controles de red adicionales entre clústeres del mismo cliente.
Para obtener más información sobre las redes en el plano de proceso sin servidor, Redes de plano de proceso sin servidor.
Plataforma de cómputo clásica
En el plano de proceso clásico, los recursos de proceso de Azure Databricks se ejecutan en la suscripción de Azure. Los nuevos recursos de proceso se crean dentro de la red virtual de cada área de trabajo en la suscripción de Azure del cliente.
Un plano de proceso clásico tiene aislamiento natural porque se ejecuta en la propia suscripción de Azure de cada cliente. Para más información sobre las redes en el plano de proceso clásico, vea Redes del plano de proceso clásico.
Para obtener soporte técnico regional, consulte Regiones de Azure Databricks.
Almacenamiento del área de trabajo
El almacenamiento del área de trabajo se controla de forma diferente en función del tipo de área de trabajo. Para obtener más información sobre los tipos de área de trabajo, consulte Creación de un área de trabajo.
El almacenamiento del área de trabajo contiene dos categorías de datos: datos del sistema de archivos del área de trabajo y datos del sistema del área de trabajo. Ambos son independientes de sus propios objetos de datos (como las tablas y volúmenes de Unity Catalog).
Datos del sistema de archivos del área de trabajo
El sistema de archivos del área de trabajo almacena los recursos que los usuarios crean y administran a través de la interfaz de usuario de Azure Databricks. Entre ellas se incluyen las siguientes:
- Blocs de notas
- Consultas SQL y cuadros de mando
- Alertas
- Repositorios (carpetas adjuntas a repositorios de Git)
- Bibliotecas (
.whl,.jar) - Archivos de Python, archivos de configuración de YAML y otros archivos pequeños
Para obtener más información sobre los archivos del área de trabajo, consulte ¿Qué son los archivos del área de trabajo?. Para obtener una lista completa de los recursos del área de trabajo, consulte Introducción a los objetos del área de trabajo.
Datos del sistema de área de trabajo
Cada área de trabajo de Azure Databricks también almacena los datos del sistema generados internamente por las características de Azure Databricks. Estos datos son demasiado grandes para almacenar en memoria o bases de datos, o deben conservarse más allá de la duración de un único recurso de proceso. Algunos ejemplos de datos del sistema del área de trabajo son:
- Resultados de la consulta SQL y resultados de consulta almacenados en caché
- Resultados de la ejecución del trabajo
- Revisiones del notebook
- Planes de consulta SQL usados para la observabilidad
- Registros de clúster
Para más información sobre cómo se configura el almacenamiento del área de trabajo para cada tipo de área de trabajo, consulte las secciones siguientes.
Áreas de trabajo sin servidor
Las áreas de trabajo sin servidor usan el almacenamiento predeterminado, que es una ubicación de almacenamiento totalmente administrada para los datos internos del sistema del área de trabajo y los recursos de datos del Catálogo de Unity. Las áreas de trabajo sin servidor también admiten la capacidad de conectarse a las ubicaciones de almacenamiento en la nube para sus propios catálogos, tablas y otros recursos de datos. Consulte Almacenamiento predeterminado en Databricks.
Áreas de trabajo clásicas
Importante
No elimine ni modifique el almacenamiento del área de trabajo en la cuenta en la nube. Un área de trabajo de Azure Databricks depende de sus bases de datos del plano de control y de su almacenamiento de área de trabajo para una operación adecuada. Si se elimina el almacenamiento del área de trabajo, no se puede recuperar el área de trabajo.
En las áreas de trabajo clásicas, los datos del sistema del área de trabajo son distintos de ¿Qué es DBFS?. Aunque ambos pueden residir en la misma cuenta de almacenamiento en la nube en áreas de trabajo clásicas, tienen fines diferentes. La raíz de DBFS es un sistema de archivos accesible para el usuario, mientras que las características de Azure Databricks usan internamente los datos del sistema del área de trabajo.
La cuenta de almacenamiento del área de trabajo contiene lo siguiente:
- Datos del sistema del espacio de trabajo: datos internos generados por las funciones de Azure Databricks
- Catálogo de áreas de trabajo de Unity Catalog: si el área de trabajo se ha habilitado automáticamente para el catálogo de Unity, la cuenta de almacenamiento del área de trabajo contiene el catálogo de áreas de trabajo predeterminado. Todos los usuarios del área de trabajo pueden crear recursos en el esquema predeterminado de este catálogo. Consulte Introducción al catálogo de Unity.
- DBFS (heredado): El directorio raíz de DBFS y los puntos de montaje de DBFS son elementos heredados y podrían deshabilitarse en su área de trabajo. DBFS (Sistema de Archivos de Databricks) es un sistema de archivos distribuido en entornos de Azure Databricks accesible en el
dbfs:/espacio de nombres. Los montajes raíz de DBFS y DBFS están en el espacio de nombresdbfs:/. El almacenamiento y el acceso a datos mediante la raíz de DBFS o montajes de DBFS es un patrón en desuso y no recomendado por Databricks. Para más información, vea ¿Qué es DBFS?.
Para limitar el acceso a la cuenta de almacenamiento del área de trabajo solo desde recursos y redes autorizados, vea Habilitación de la compatibilidad del firewall con la cuenta de almacenamiento del área de trabajo.