Nota
L'accés a aquesta pàgina requereix autorització. Podeu provar d'iniciar la sessió o de canviar els directoris.
L'accés a aquesta pàgina requereix autorització. Podeu provar de canviar els directoris.
Este tutorial le guía por el uso de un cuaderno de Azure Databricks para importar datos de un archivo CSV que contiene datos de nombre del bebé de health.data.ny.gov en el volumen del catálogo de Unity mediante Python, Scala y R. También aprenderá a modificar un nombre de columna, visualizar los datos y guardarlos en una tabla.
Nota:
Si usa Databricks Free Edition, seleccione la pestaña Python para todos los ejemplos de código de este tutorial. Free Edition no admite R ni Scala. Además, Free Edition restringe el acceso saliente a Internet, por lo que debe cargar el archivo CSV mediante la interfaz de usuario del área de trabajo en lugar de descargarlo con código. Consulte el paso 3 para obtener instrucciones detalladas.
Requisitos
Para completar las tareas de este artículo, debe cumplir los siguientes requisitos:
- El área de trabajo debe tener Unity Catalog habilitado. Para obtener información sobre cómo empezar a trabajar con el catálogo de Unity, consulte Introducción al catálogo de Unity. Azure Databricks Free Edition y las áreas de trabajo de evaluación gratuita tienen habilitado Unity Catalog de forma predeterminada.
- Debe tener el privilegio
WRITE VOLUMEen un volumen, el privilegioUSE SCHEMAen el esquema principal y el privilegioUSE CATALOGen el catálogo principal. Los usuarios de Free Edition tienen estos privilegios en el catálogo ydefaultel esquema del área de trabajo de forma predeterminada. - Debe tener permiso para usar un recurso de proceso existente o crear un nuevo recurso de proceso. Consulte Computación o a su administrador de Azure Databricks.
Sugerencia
Para ver un cuaderno completado para este artículo, consulte Importación y visualización de cuadernos de datos.
Paso 1: Crear un nuevo cuaderno
Para crear un cuaderno en el área de trabajo, haga clic en ![]() Nuevo en la barra lateral y a continuación, haga clic en Cuaderno. Se abre un cuaderno en blanco en el área de trabajo.
Nuevo en la barra lateral y a continuación, haga clic en Cuaderno. Se abre un cuaderno en blanco en el área de trabajo.
Para obtener más información sobre cómo crear y administrar cuadernos, consulte Administración de cuadernos.
Paso 2: Definir variables
En este paso, definirá variables para su uso en el cuaderno de ejemplo que cree en este artículo. Necesita los nombres de un catálogo, un esquema y un volumen de Unity Catalog.
Sugerencia
Si no conoce los nombres de catálogo y esquema, haga clic en ![]() Catálogo en la barra lateral. El catálogo del área de trabajo tiene el mismo nombre que tu área de trabajo y aparece en el panel del catálogo. Expándalo para ver los esquemas disponibles. Edición gratuita y los usuarios de prueba gratuita pueden usar el catálogo del área de trabajo y el esquema
Catálogo en la barra lateral. El catálogo del área de trabajo tiene el mismo nombre que tu área de trabajo y aparece en el panel del catálogo. Expándalo para ver los esquemas disponibles. Edición gratuita y los usuarios de prueba gratuita pueden usar el catálogo del área de trabajo y el esquema default.
Si no tiene un volumen, cree uno ejecutando el siguiente comando en una celda del cuaderno (reemplace <catalog_name> y <schema_name> por sus valores):
CREATE VOLUME IF NOT EXISTS <catalog_name>.<schema_name>.my_volume
Copie y pegue el código siguiente en la celda del nuevo cuaderno vacío. Reemplace
<catalog-name>,<schema-name>y<volume-name>por los nombres de catálogo, esquema y volumen de un volumen de Unity Catalog. De manera opcional, reemplace el valortable_namepor un nombre de la tabla de su elección. Guarde los datos del nombre del bebé en esta tabla más adelante en este artículo.Presione
Shift+Enterpara ejecutar la celda y crear una nueva celda en blanco.Pitón
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
Paso 3: Importar archivo CSV
En este paso, importará un archivo CSV que contiene datos de nombre del bebé de health.data.ny.gov al volumen del catálogo de Unity. Elija uno de los métodos siguientes:
- Cargar mediante la interfaz de usuario del área de trabajo: use este método si utiliza Databricks Free Edition o si la descarga de código en la opción B falla con un error de red. Free Edition y otros entornos de proceso sin servidor restringen el acceso saliente a Internet, por lo que debe cargar el archivo desde la máquina local.
- Descargar mediante código : use este método si el entorno de proceso tiene acceso saliente a Internet.
Opción A: Cargar mediante la interfaz de usuario del área de trabajo
- En el equipo local, abra health.data.ny.gov/api/views/jxy9-yhdk/rows.csv en el explorador. El archivo se descarga en el equipo como
rows.csv. - Busque el archivo descargado en el equipo y cámbielo de
rows.csvababy_names.csv. Esto coincide con la variable que definió en elfile_namepaso 2. - Vuelva al área de trabajo de Azure Databricks. En la barra lateral, haga clic en
 Agregar > o cargar datos.
Agregar > o cargar datos. - Haga clic en Cargar archivos en un volumen.
- Haga clic en Examinar y seleccione el
baby_names.csvarchivo, o arrástrelo y colóquelo en el área de carga. - En Volumen de destino, seleccione el volumen que especificó en el paso 2.
- Una vez finalizada la carga, vuelva al cuaderno y continúe con el paso 4.
Para obtener más información sobre cómo cargar archivos, consulte Trabajar con archivos en volúmenes del catálogo de Unity.
Opción B: Descargar mediante código
Copie y pegue el código siguiente en la celda del nuevo cuaderno vacío. Este código copia el archivo
rows.csvdesde health.data.ny.gov en su volumen de Unity Catalog usando el comando Databricks dbutils.Presione
Shift+Enterpara ejecutar la celda y, a continuación, vaya a la celda siguiente.Pitón
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Scala
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
Paso 4: Cargar datos CSV en un DataFrame
En este paso, creará un DataFrame denominado df a partir del archivo CSV que cargó anteriormente en el volumen del catálogo de Unity mediante el método spark.read.csv.
Copie y pegue el código siguiente en la celda del nuevo cuaderno vacío. Este código carga los datos del nombre del bebé en DataFrame
dfdesde el archivo CSV.Presione
Shift+Enterpara ejecutar la celda y, a continuación, vaya a la celda siguiente.Pitón
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")Scala
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
Puede cargar datos de muchos formatos de archivo admitidos.
Paso 5: Visualización de datos desde cuadernos
En este paso, usará el display() método para mostrar el contenido del DataFrame en una tabla del cuaderno y, a continuación, visualizar los datos en un gráfico de nube de palabras en el cuaderno.
Copie y pegue el código siguiente en la nueva celda vacía del cuaderno y, a continuación, haga clic en Ejecutar celda para mostrar los datos de una tabla.
Pitón
display(df)Scala
display(df)R
display(df)Inspeccione los resultados en la tabla.
Junto a la pestaña Tabla, haga clic + y, a continuación, haga clic en Visualización.
En el editor de visualización, haga clic en Tipo de visualización y compruebe que la nube de Word está seleccionada.
En la columna Palabras, compruebe que
First Nameestá seleccionada.En Límite de frecuencias, haga clic en
35.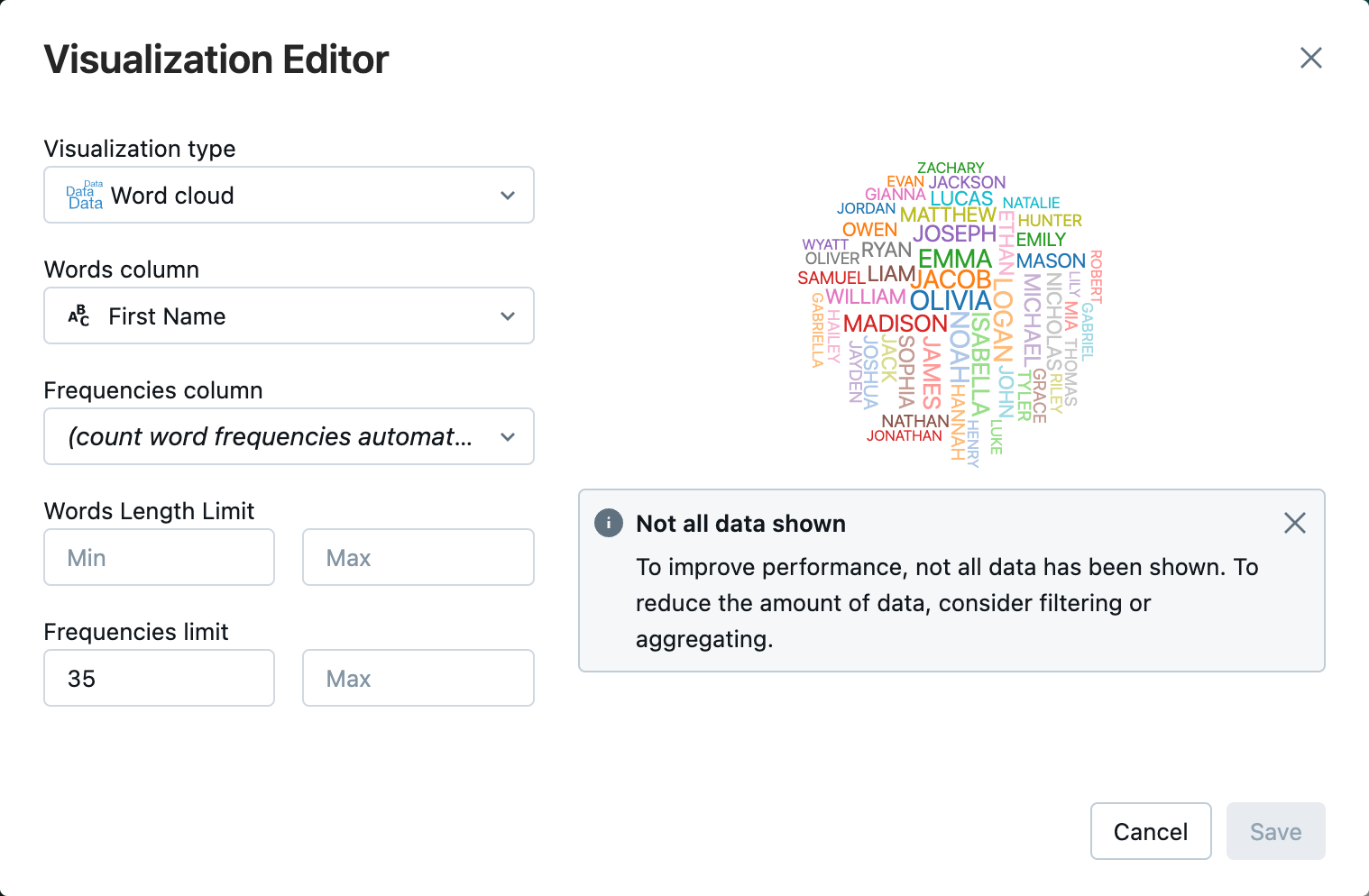
Haga clic en Save(Guardar).
Paso 6: Guardar el DataFrame en una tabla
Importante
Para guardar su DataFrame en el Catálogo Unity, debe tener privilegios de tabla CREATE en el catálogo y el esquema. Para obtener información sobre los permisos en el catálogo de Unity, consulte Privilegios y objetos protegibles en el catálogo de Unity y Administrar privilegios en el catálogo de Unity.
Copie y pegue el código siguiente en una celda de cuaderno vacía. Este código reemplaza un espacio en el nombre de columna. No se permiten caracteres especiales, como espacios, en nombres de columna. Este código usa el método
withColumnRenamed()de Apache Spark.Pitón
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemaScala
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)Copie y pegue el código siguiente en una celda de cuaderno vacía. Este código guarda el contenido del DataFrame en una tabla del catálogo de Unity mediante la variable de nombre de tabla que definió al principio de este artículo.
Pitón
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")Scala
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")Para comprobar que se guardó la tabla, haga clic en Catálogo en la barra lateral izquierda para abrir la interfaz de usuario del Explorador de catálogos. Abra el catálogo y, a continuación, el esquema para comprobar que aparece la tabla.
Haga clic en la tabla para ver el esquema de la tabla en la pestaña Información general.
Haga clic en Datos de ejemplo para ver 100 filas de datos de la tabla.
Importación y visualización de cuadernos de datos
Use uno de los siguientes cuadernos para realizar los pasos descritos en este artículo. Reemplace <catalog-name>, <schema-name> y <volume-name> por los nombres de catálogo, esquema y volumen de un volumen de Unity Catalog. De manera opcional, reemplace el valor table_name por un nombre de la tabla de su elección.
Pitón
Importación de datos desde CSV mediante Python
Scala
Importación de datos desde CSV mediante Scala
R
Importación de datos desde CSV mediante R
Pasos siguientes
- Para obtener información sobre las técnicas de análisis de datos exploratorios (EDA), consulte Tutorial: Técnicas de EDA mediante cuadernos de Databricks.
- Para obtener información sobre cómo crear una canalización de ETL (extracción, transformación y carga), consulte Tutorial: Compilación de una canalización ETL con canalizaciones declarativas de Spark de Lakeflow y Tutorial: Compilación de una canalización de ETL con Apache Spark en la plataforma de Databricks