Nota
L'accés a aquesta pàgina requereix autorització. Pots provar d'iniciar sessió o canviar de directori.
L'accés a aquesta pàgina requereix autorització. Pots provar de canviar directoris.
Las canalizaciones pueden contener muchos conjuntos de datos con muchos flujos para mantenerlos actualizados. Las canalizaciones administran automáticamente las actualizaciones y los clústeres para actualizar de forma eficaz. Sin embargo, hay cierta sobrecarga con la administración de un gran número de flujos y, en ocasiones, esto puede provocar una inicialización mayor de lo esperado o incluso la sobrecarga de administración durante el procesamiento.
Si experimenta retrasos al esperar que se inicien las pipelines activadas, como tiempos de inicialización de más de cinco minutos, considere dividir el procesamiento en varias pipelines, incluso cuando los conjuntos de datos utilicen los mismos datos de origen.
Nota:
Las canalizaciones desencadenadas realizan los pasos de inicialización cada vez que se desencadenan. Las canalizaciones continuas solo realizan los pasos de inicialización cuando se detienen y reinician. Esta sección es más útil para optimizar la inicialización de canalización desencadenada.
Cuándo considerar la posibilidad de dividir una canalización
Hay varios casos en los que la división de una canalización puede ser ventajosa por motivos de rendimiento.
- Las fases
INITIALIZINGySETTING_UP_TABLEStardan más de lo que desea, lo que afecta al tiempo total del proceso. Si se trata de más de 5 minutos, a menudo se mejora dividiendo la canalización. - El controlador que administra el clúster puede convertirse en un cuello de botella al ejecutar más de 30 o 40 tablas de streaming dentro de una sola canalización. Si el controlador no responde, las duraciones de las consultas de streaming aumentarán, lo que afectará al tiempo total de la actualización.
- Es posible que una canalización desencadenada que tenga varios flujos de tabla de streaming no pueda realizar todas las actualizaciones de secuencias paralelizables en paralelo.
Detalles sobre los problemas de rendimiento
En esta sección se describen algunos de los problemas de rendimiento que pueden surgir al tener muchas tablas y flujos en una sola canalización.
Cuellos de botella en las fases de INICIALIZACIÓN y CONFIGURACIÓN_DE_TABLAS.
Las fases iniciales de la ejecución pueden ser un cuello de botella en el rendimiento, en función de la complejidad del pipeline.
Fase DE INICIALIZACIÓN
Durante esta fase, se crean planes lógicos, incluidos los planes para crear el gráfico de dependencias y determinar el orden de las actualizaciones de la tabla.
fase de CONFIGURACIÓN_DE_TABLAS
Durante esta fase, se realizan los siguientes procesos, en función de los planes creados en la fase anterior:
- Validación y resolución de esquemas para todas las tablas definidas en el flujo de trabajo.
- Compile el gráfico de dependencias y determine el orden de ejecución de la tabla.
- Compruebe si cada conjunto de datos está activo en la canalización o es nuevo desde cualquier actualización anterior.
- Cree tablas de transmisión en la primera actualización y, para vistas materializadas, cree vistas temporales o tablas de respaldo que sean necesarias durante cada actualización del proceso de canalización.
Por qué INICIALIZAR y CONFIGURAR_TABLAS pueden tardar más tiempo
Las canalizaciones grandes con muchos flujos para muchos conjuntos de datos pueden tardar más tiempo por varias razones:
- En el caso de las canalizaciones con muchos flujos y dependencias complejas, estas fases pueden tardar más tiempo debido al volumen de trabajo que se va a realizar.
- Las transformaciones complejas, incluyendo las transformaciones
Auto CDC, pueden provocar un cuello de botella en el rendimiento, a causa de las operaciones necesarias para materializar las tablas de acuerdo con las transformaciones definidas. - También hay escenarios en los que un número significativo de flujos puede provocar lentitud, incluso si esos flujos no forman parte de una actualización. Por ejemplo, considere una canalización que tenga más de 700 flujos, de los cuales menos de 50 se actualizan para cada desencadenador, en función de una configuración. En este ejemplo, cada ejecución debe recorrer algunos de los pasos de todas las 700 tablas, obtener los dataframes y, a continuación, seleccionar los que se van a ejecutar.
Cuellos de botella en el controlador
El controlador administra las actualizaciones dentro de la ejecución. Debe ejecutar alguna lógica para cada tabla, para decidir qué instancias de un clúster deben controlar cada flujo. Al ejecutar varias tablas de streaming (más de 30-40) dentro de una sola canalización, el controlador puede convertirse en un cuello de botella para los recursos de CPU, ya que controla el trabajo en todo el clúster.
El controlador también puede encontrarse con problemas de memoria. Esto puede ocurrir con más frecuencia cuando el número de flujos paralelos es de 30 o más. No hay un número específico de flujos o conjuntos de datos que pueden causar problemas de memoria del controlador, pero depende de la complejidad de las tareas que se ejecutan en paralelo.
Los flujos de streaming se pueden ejecutar en paralelo, pero esto requiere que el controlador use memoria y CPU para todas las secuencias simultáneamente. En una canalización desencadenada, el controlador puede procesar un subconjunto de secuencias en paralelo a la vez, para evitar restricciones de memoria y CPU.
En todos estos casos, la división de canalizaciones para que haya un conjunto óptimo de flujos en cada uno puede acelerar el tiempo de inicialización y procesamiento.
Desventajas con canalizaciones divididas
Cuando todos los flujos están dentro de la misma canalización, Lakeflow Spark Declarative Pipelines administra las dependencias automáticamente. Cuando hay varias canalizaciones, debe administrar las dependencias entre canalizaciones.
Dependencias Es posible que tenga una canalización de bajada que dependa de varias canalizaciones ascendentes (en lugar de una). Por ejemplo, si tiene tres canalizaciones,
pipeline_A,pipeline_Bypipeline_C, ypipeline_Cdepende depipeline_Aypipeline_B, quiere quepipeline_Cse actualice solo después de quepipeline_Aypipeline_Bhayan completado sus respectivas actualizaciones. Una manera de abordar esto es organizar las dependencias haciendo que cada canalización sea una tarea en un trabajo con las dependencias correctamente modeladas, de modo quepipeline_Csolo se actualice después de que tantopipeline_Acomopipeline_Bse completen.Concurrencia Es posible que tenga flujos diferentes dentro de una canalización que tarden tiempos muy diferentes en completarse, por ejemplo, si
flow_Ase actualiza en 15 segundos yflow_Btarda varios minutos. Puede resultar útil examinar los tiempos de consulta antes de dividir las canalizaciones y agrupar consultas más cortas.
Planear la división de las canalizaciones
Puede visualizar la división de canalización antes de empezar. Este es un gráfico de una canalización de origen que procesa 25 tablas. Un único origen de datos raíz se divide en 8 segmentos, cada uno de los cuales tiene 2 vistas.
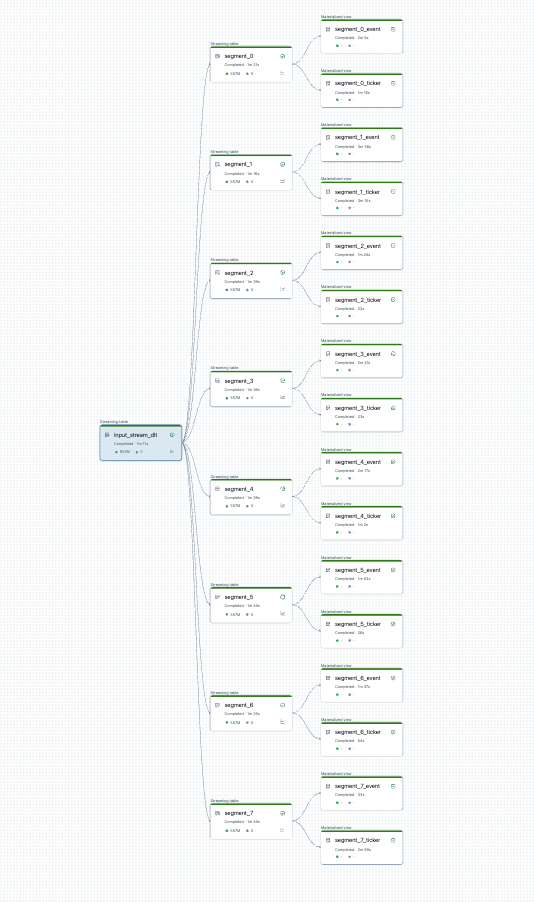
Después de dividir la canalización, hay dos canalizaciones. Uno procesa el origen de datos raíz único, y 4 segmentos con sus vistas asociadas. La segunda canalización procesa los otros 4 segmentos y sus vistas asociadas. La segunda canalización se basa en la primera para actualizar el origen de datos raíz.
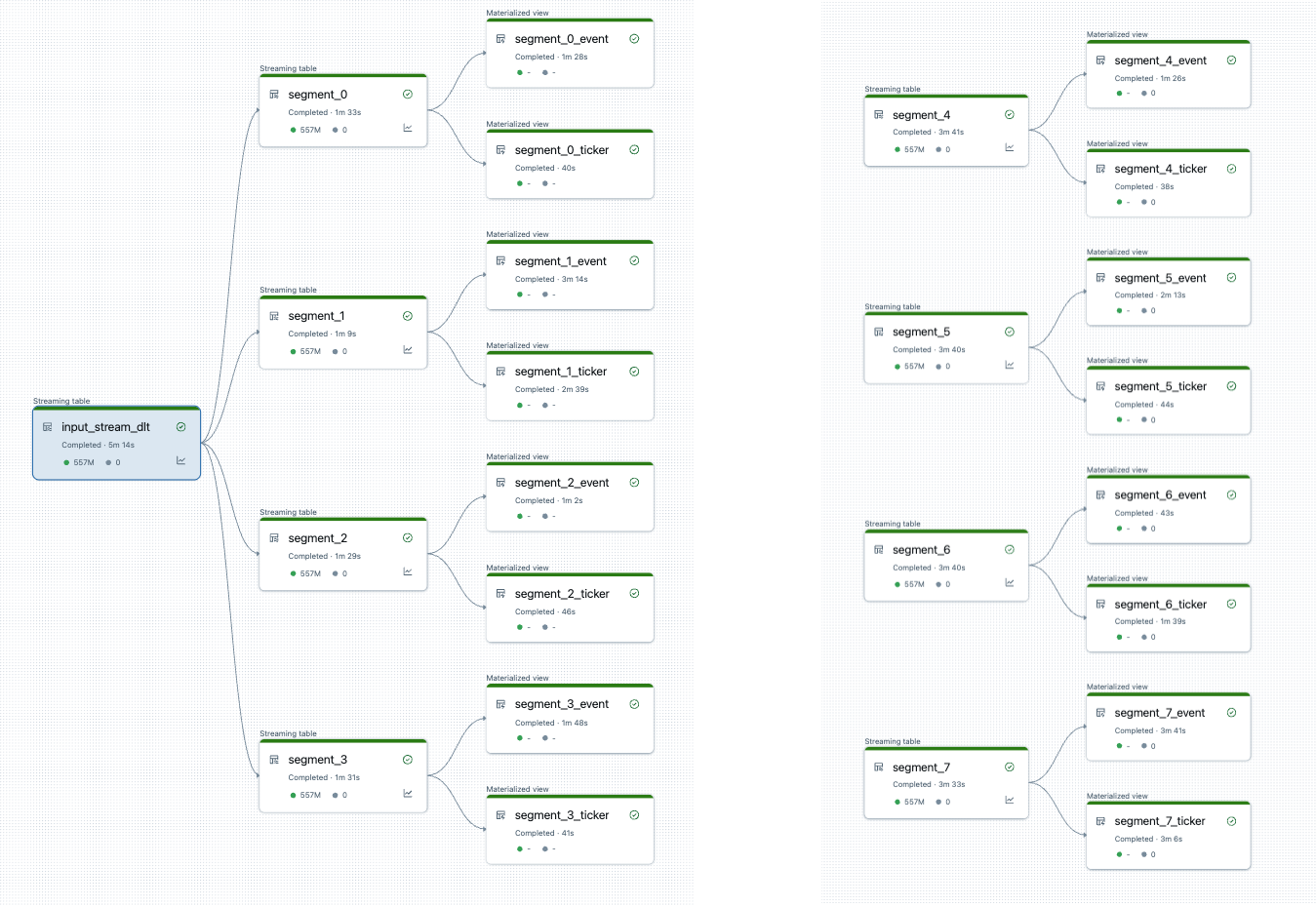
Dividir la canalización sin una actualización completa
Después de planear la división de la canalización, cree todas las nuevas canalizaciones necesarias y mueva tablas entre ellas para equilibrar la carga entre las canalizaciones. Puede mover tablas sin provocar una actualización completa.
Para más información, consulte Movimiento de tablas entre canalizaciones.
Hay algunas limitaciones con este enfoque:
- Las canalizaciones deben estar en el catálogo de Unity.
- Las canalizaciones de origen y destino deben estar dentro del mismo área de trabajo. No se admiten movimientos entre áreas de trabajo.
- La canalización de destino debe crearse y ejecutarse una vez (incluso si se produce un error) antes del traslado.
- No se puede mover una tabla de una canalización que use el modo de publicación predeterminado a uno que use el modo de publicación heredado. Para obtener más información, consulte LIVE schema (legacy).