Nota
L'accés a aquesta pàgina requereix autorització. Podeu provar d'iniciar la sessió o de canviar els directoris.
L'accés a aquesta pàgina requereix autorització. Podeu provar de canviar els directoris.
Databricks Feature Serving hace que los datos de la plataforma de Databricks estén disponibles para los modelos o aplicaciones implementados fuera de Azure Databricks. Los puntos de conexión del servicio de características de Databricks se escalan automáticamente para ajustarse al tráfico en tiempo real y proporcionar un servicio de alta disponibilidad y baja latencia para atender las características. En esta página se describe cómo configurar y usar el servicio de características de Databricks. Para ver un tutorial paso a paso, consulte Ejemplo: Implementación y consulta de una característica que proporciona un punto de conexión.
Cuando se usa Mosaic AI Model Serving para servir un modelo creado mediante características de Databricks, el modelo busca y transforma automáticamente las características de las solicitudes de inferencia. Con el servicio de características de Databricks, puede servir datos estructurados para aplicaciones de generación aumentada de recuperación (RAG), así como características necesarias para otras aplicaciones, como modelos servidos fuera de Databricks o cualquier otra aplicación que requiera características basadas en datos de Unity Catalog.
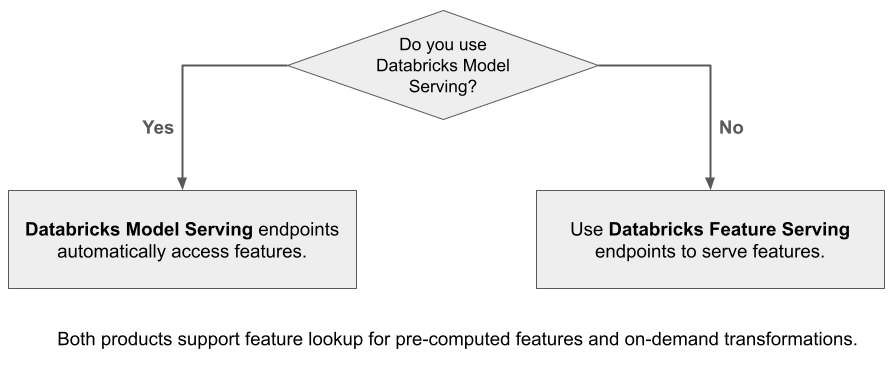
¿Por qué usar Feature Serving?
El servicio de características de Databricks proporciona una única interfaz que ofrece características prematerializadas y a petición. También incluye las siguientes ventajas:
- Simplicidad. Databricks controla la infraestructura. Con una sola llamada API, Databricks crea un entorno de servicio listo para la producción.
- Alta disponibilidad y escalabilidad. Los puntos de conexión del servicio de características de Databricks se escalan y reducen verticalmente automáticamente para ajustarse al volumen de solicitudes de servicio.
- Seguridad. Los puntos de conexión se implementan en un límite de red seguro y usan un proceso dedicado que finaliza cuando el punto de conexión se elimina o se escala a cero.
Requisitos
- Databricks Runtime 14.2 ML o superior.
- Para usar la API de Python, Feature Serving requiere
databricks-feature-engineeringversión 0.1.2 o posterior, que está integrado en Databricks Runtime 14.2 ML. Para versiones anteriores de Databricks Runtime ML, instale manualmente la versión necesaria con%pip install databricks-feature-engineering>=0.1.2. Si usa un cuaderno de Databricks, debe reiniciar el kernel de Python ejecutando este comando en una nueva celda:dbutils.library.restartPython(). - Para usar el SDK de Databricks, el servicio de características requiere
databricks-sdkversión 0.18.0 o posterior. Para instalar manualmente la versión necesaria, use%pip install databricks-sdk>=0.18.0. Si usa un cuaderno de Databricks, debe reiniciar el kernel de Python ejecutando este comando en una nueva celda:dbutils.library.restartPython().
El servicio de características de Databricks proporciona una interfaz de usuario y varias opciones de programación para crear, actualizar, consultar y eliminar puntos de conexión. En este artículo se incluyen instrucciones para cada una de las siguientes opciones:
- Interfaz de usuario de Databricks
- API DE REST
- API de Python
- SDK de Databricks
Para usar la API de REST o el SDK de implementaciones de MLflow, debe tener un token de API de Databricks.
Importante
Como procedimiento recomendado de seguridad para escenarios de producción, Databricks recomienda usar Tokens de OAuth de máquina a máquina para la autenticación durante la producción.
Para pruebas y desarrollo, Databricks recomienda usar un token de acceso personal que pertenezca a entidades de servicio en lugar de usuarios del área de trabajo. Para crear tókenes para entidades de servicio, consulte Administración de tokens de acceso para una entidad de servicio.
Autenticación para Feature Serving
Para obtener información sobre la autenticación, consulte Authorize access to Azure Databricks resources.
Creación de una clase FeatureSpec
Un FeatureSpec es un conjunto definido por el usuario de características y funciones. Puede combinar características y funciones en un FeatureSpec.
FeatureSpecs se almacenan y administran mediante Unity Catalog y aparecen en el Explorador de catálogos.
Las tablas especificadas en un FeatureSpec se deben publicar en una tienda de características en línea o en una tienda en línea de terceros. Consulte Databricks Online Feature Stores.
Debe usar el paquete de databricks-feature-engineering para crear un FeatureSpec.
En primer lugar, defina la función :
from unitycatalog.ai.core.databricks import DatabricksFunctionClient
client = DatabricksFunctionClient()
CATALOG = "main"
SCHEMA = "default"
def difference(num_1: float, num_2: float) -> float:
"""
A function that accepts two floating point numbers, subtracts the second one
from the first, and returns the result as a float.
Args:
num_1 (float): The first number.
num_2 (float): The second number.
Returns:
float: The resulting difference of the two input numbers.
"""
return num_1 - num_2
client.create_python_function(
func=difference,
catalog=CATALOG,
schema=SCHEMA,
replace=True
)
A continuación, puede usar la función en un FeatureSpec.
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates num_1 - num_2.
input_bindings={"num_1": "ytd_spend", "num_2": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
Especificar valores predeterminados
Para especificar valores predeterminados para las características, use el default_values parámetro en .FeatureLookup Vea el ejemplo siguiente:
feature_lookups = [
FeatureLookup(
table_name="ml.recommender_system.customer_features",
feature_names=[
"membership_tier",
"age",
"page_views_count_30days",
],
lookup_key="customer_id",
default_values={
"age": 18,
"membership_tier": "bronze"
},
),
]
Si se cambia el nombre de las columnas de características mediante el rename_outputs parámetro , default_values debe usar los nombres de características cuyo nombre ha cambiado.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
rename_outputs={"materialized_feature_value": "feature_value"},
default_values={
"feature_value": 0
}
)
Crear un punto de conexión
FeatureSpec define el punto de conexión. Para obtener más información, consulte Crear endpoints personalizados para servir modelos, la documentación de la API de Python o la documentación del SDK de Databricks para detalles.
Nota
En el caso de las cargas de trabajo que son sensibles a la latencia o requieren un alto número de consultas por segundo, Model Serving ofrece optimización de rutas en puntos de conexión personalizados para el servicio de modelos, consulte Optimización de rutas en los puntos de conexión de servicio.
SDK de Databricks: Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
API de Python
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
API DE REST
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
Para ver el punto de conexión, haga clic en Servicio en la barra lateral izquierda de la interfaz de usuario de Databricks. Cuando el estado es Listo, el punto de conexión está listo para responder a las consultas. Para obtener más información sobre Mosaic AI Model Serving, consulte Mosaic AI Model Serving.
Guardar el dataframe aumentado en la tabla de inferencia
En el caso de los puntos de conexión creados a partir de febrero de 2025, puede configurar el punto de conexión de servicio del modelo para registrar el DataFrame aumentado que contiene los valores de características buscados y los valores devueltos de función. DataFrame se guarda en la tabla de inferencia para el modelo servido.
Para obtener instrucciones sobre cómo establecer esta configuración, consulte Búsqueda de características de registro DataFrames en tablas de inferencia.
Para obtener información sobre las tablas de inferencia, vea Tablas de inferencia para supervisar y depurar modelos.
Obtener un punto de conexión
Puede usar el SDK de Databricks o la API de Python para obtener los metadatos y el estado de un punto de conexión.
SDK de Databricks: Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
API de Python
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
Obtención del esquema de un punto de conexión
Puede usar el SDK de Databricks o la API REST para obtener el esquema de un punto de conexión. Para obtener más información sobre el esquema del punto de conexión, consulte Obtención de un modelo que atiende el esquema de punto de conexión.
SDK de Databricks: Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
# Create endpoint
endpoint = workspace.serving_endpoints.get_open_api(name="customer-features")
API DE REST
ACCESS_TOKEN=<token>
ENDPOINT_NAME=<endpoint name>
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
Consultar un punto de conexión
Puede usar la API de REST, el SDK de implementaciones de MLflow o la interfaz de usuario de servicio para consultar un punto de conexión.
En el código siguiente se muestra cómo configurar las credenciales y crear el cliente al usar el SDK de implementaciones de MLflow.
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Nota
Como procedimiento recomendado de seguridad, cuando se autentique con herramientas, sistemas, scripts y aplicaciones automatizados, Databricks recomienda usar los tokens de acceso personal pertenecientes a las entidades de servicio en lugar de a los usuarios del área de trabajo. Para crear tókenes para entidades de servicio, consulte Administración de tokens de acceso para una entidad de servicio.
Consulta de un punto de conexión con API
En esta sección se incluyen ejemplos de consulta de un punto de conexión mediante la API de REST o el SDK de implementaciones de MLflow.
SDK de implementaciones de MLflow
Importante
En el ejemplo siguiente se usa la API de predict() del SDK de implementaciones de MLflow. Esta API es Experimental y la definición de la API podría cambiar.
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
API DE REST
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
Consulta de un punto de conexión mediante la interfaz de usuario
Puede consultar un punto de conexión de servicio directamente desde la interfaz de usuario de servicio. La interfaz de usuario incluye ejemplos de código generados que puede usar para consultar el punto de conexión.
En la barra lateral izquierda del área de trabajo de Azure Databricks, haga clic en Serving.
Haga clic en el punto de conexión que desea consultar.
En la parte superior derecha de la pantalla, haga clic en Punto de conexión de consulta.
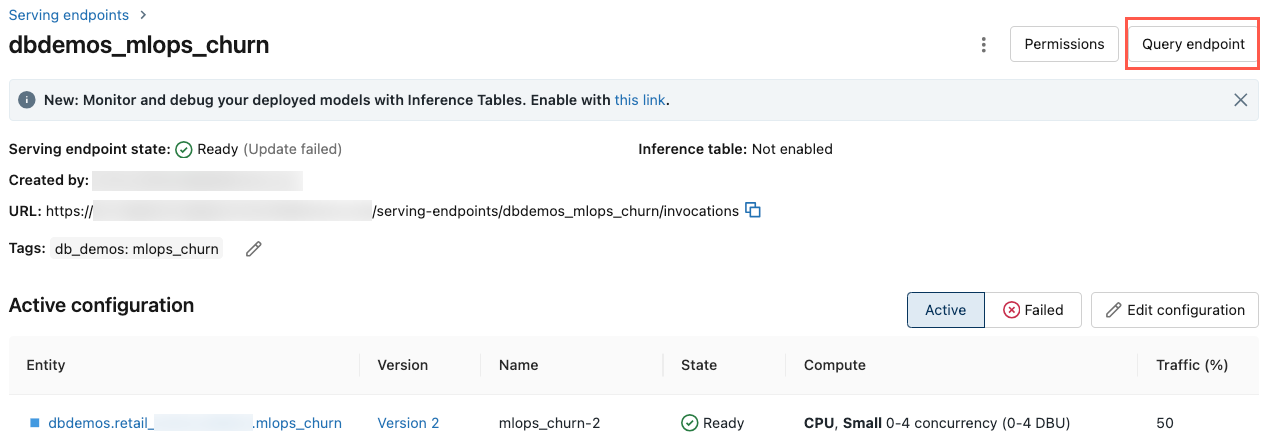
En el cuadro Solicitud, escriba el cuerpo de la solicitud en formato JSON.
Haga clic en Enviar solicitud.
// Example of a request body.
{
"dataframe_records": [
{ "user_id": 1, "ytd_spend": 598 },
{ "user_id": 2, "ytd_spend": 280 }
]
}
El cuadro de diálogo del endpoint de consulta incluye código de ejemplo generado en curl, Python y SQL. Haga clic en las pestañas para ver y copiar el código de ejemplo.
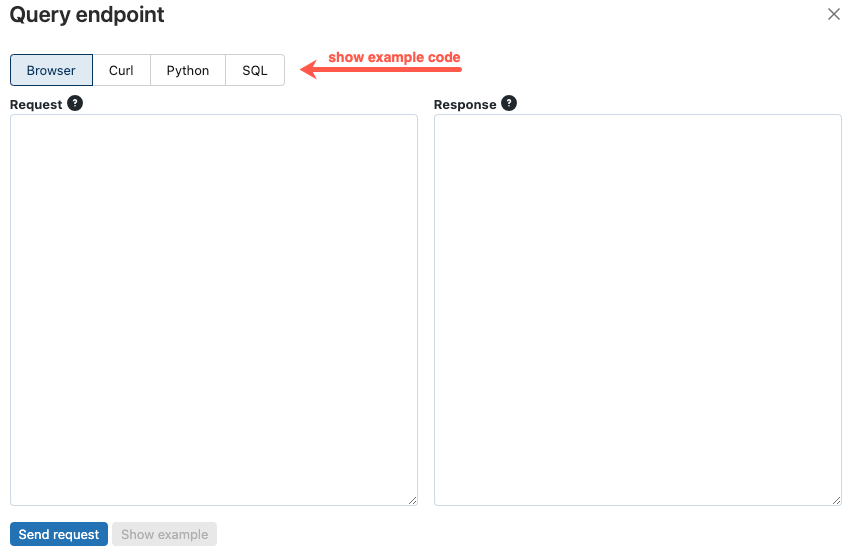
Para copiar el código, haga clic en el icono de copia en la esquina superior derecha del cuadro de texto.
Actualización de un punto de conexión
Importante
Para modificar la configuración de un punto de conexión de Feature Serving (por ejemplo, cambiar la FeatureSpec o el tamaño de la carga de trabajo), use siempre las APIs de actualización descritas en esta sección. No elimine y vuelva a crear el punto de conexión para aplicar los cambios. La eliminación de un punto de conexión activo provoca un tiempo de inactividad inmediato e interrumpe todas las aplicaciones que lo consultan.
Puede actualizar un punto de conexión mediante la API de REST, el SDK de Databricks o la interfaz de usuario de servicio.
Actualización de un punto de conexión con API
SDK de Databricks: Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
API DE REST
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
Actualización de un punto de conexión mediante la interfaz de usuario
Siga estos pasos para usar la interfaz de usuario de servicio:
- En la barra lateral izquierda del área de trabajo de Azure Databricks, haga clic en Serving.
- En la tabla, haga clic en el nombre del punto de conexión que desea actualizar. Aparece la pantalla del punto de conexión.
- En la parte superior derecha de la pantalla, haga clic en Editar punto de conexión.
- En el cuadro de diálogo Editar servicio de punto de conexión, edite la configuración del punto de conexión según sea necesario.
- Haga clic en Actualizar para guardar los cambios.

Eliminar un extremo
Advertencia
Esta acción es irreversible. Al eliminar un punto de conexión de servicio de funciones, se produce un tiempo de inactividad inmediato para cualquier aplicación que lo consulte. Si desea cambiar la configuración del punto de conexión, use Actualizar un punto de conexión en lugar de eliminar y volver a crear el punto de conexión.
Puede eliminar un punto de conexión mediante la API REST, el SDK de Databricks, la API de Python o la interfaz de usuario de servicio.
Eliminación de un punto de conexión con API
SDK de Databricks: Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.delete(name="customer-features")
API de Python
fe.delete_feature_serving_endpoint(name="customer-features")
API DE REST
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
Eliminación de un punto de conexión mediante la interfaz de usuario
Siga estos pasos para eliminar un punto de conexión mediante la interfaz de usuario de servicio:
- En la barra lateral izquierda del área de trabajo de Azure Databricks, haga clic en Serving.
- En la tabla, haga clic en el nombre del punto de conexión que desea eliminar. Aparece la pantalla del punto de conexión.
- En la parte superior derecha de la pantalla, haga clic en el icono de
 y seleccione Eliminar.
y seleccione Eliminar.

Supervisión del estado de un punto de conexión
Para obtener información sobre los registros y métricas disponibles para los puntos de conexión del servicio de características, consulte Supervisión de la calidad del modelo y el estado del punto de conexión.
Control de acceso
Para obtener información sobre los permisos sobre los puntos de conexión de servicio de características, consulte Administración de permisos en un punto de conexión de servicio de modelos.
Cuaderno de ejemplo
En este cuaderno se muestra cómo usar el SDK de Databricks para crear un punto de conexión de Feature Serving mediante Databricks Online Feature Store.