Nota
L'accés a aquesta pàgina requereix autorització. Podeu provar d'iniciar la sessió o de canviar els directoris.
L'accés a aquesta pàgina requereix autorització. Podeu provar de canviar els directoris.
En este artículo se describen los diferentes límites de tiempo que puede encontrar al usar endpoints de servicio de modelos y cómo gestionarlos. Abarca los tiempos de espera de implementación del modelo, los tiempos de espera del lado servidor y los tiempos de espera del lado cliente.
Tiempos de espera para la implementación del modelo
Al implementar un modelo o actualizar una implementación existente mediante Mosaic AI Model Serving, el proceso podría exceder el tiempo de espera por varias razones. La pestaña Eventos de la página del punto de conexión del servicio del modelo registra los mensajes de tiempo de espera. Busque "tiempo de espera agotado" para encontrarlos.
Nota:
El proceso de implementación agota el tiempo de espera si la compilación del contenedor y la implementación del modelo superan una duración determinada que depende de la configuración de carga de trabajo del punto de conexión. Compruebe la configuración antes de implementarla y compárela con las implementaciones correctas anteriores.
La construcción del contenedor no tiene un límite rígido, pero reintenta hasta 3 veces. La implementación después de compilar el contenedor esperará hasta 30 minutos para cargas de trabajo de CPU, 60 minutos para cargas de trabajo pequeñas o medianas de GPU y 120 minutos para cargas de trabajo grandes de GPU antes de que se agote el tiempo de espera.
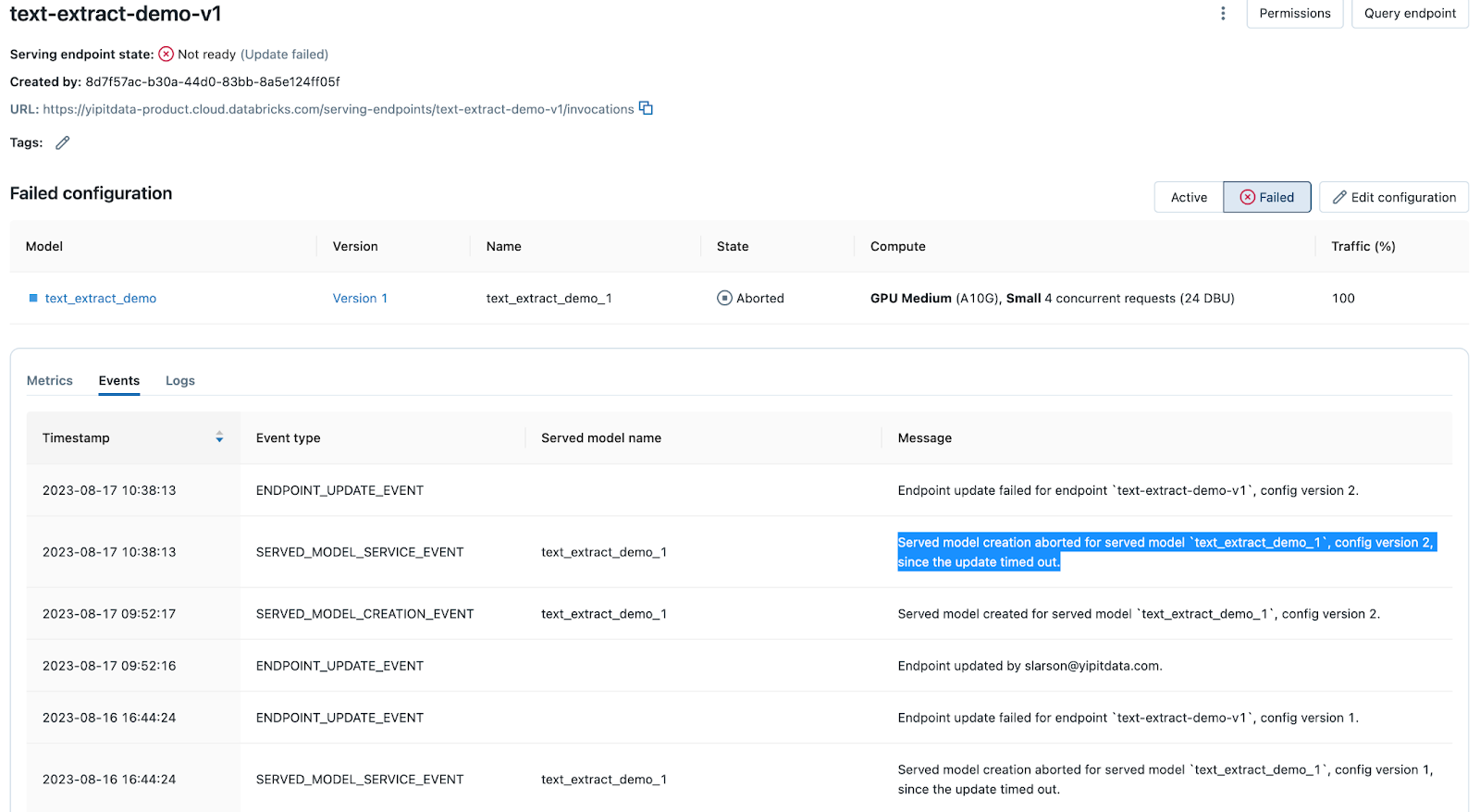
Si encuentra un mensaje tiempo de espera agotado, diríjase a la pestaña Registros y examine los registros de compilación para determinar la causa. Entre los ejemplos se incluyen problemas de dependencia de biblioteca, restricciones de recursos, problemas de configuración, etc.
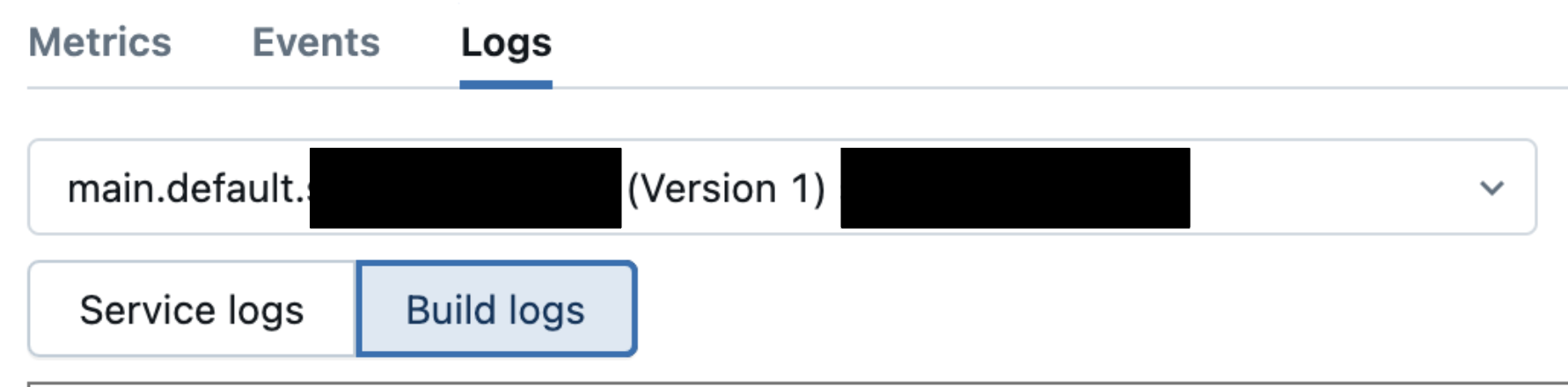
Consulte Depuración después del error de compilación del contenedor.
Tiempos de espera del lado servidor
Si su punto de conexión está en buen estado según las pestañas Eventos y Registros de su punto de conexión de servicio, pero experimenta tiempos de espera al realizar llamadas al punto de conexión, el tiempo de espera podría estar en el lado del servidor. El tiempo de espera predeterminado varía en función del tipo de punto de servicio del modelo. En la tabla siguiente se muestran los tiempos de espera predeterminados del lado servidor para las solicitudes enviadas a los puntos de conexión de servicio del modelo.
| Tipo de punto de conexión | Límite de tiempo de espera de solicitud (segundos) | Notas |
|---|---|---|
| Puntos de conexión de servicio de CPU o GPU | Valor predeterminado 297 | No se puede aumentar este límite. |
| Punto de conexión para el servicio de modelos fundamentales | Valor predeterminado 297 | No se puede aumentar este límite. |
Para determinar si ha experimentado un tiempo de espera del lado del servidor, verifique si sus solicitudes se están agotando antes o después de los límites enumerados anteriormente.
- Si la solicitud falla constantemente en el límite, es probable que se produzca un tiempo de espera del lado del servidor.
- Si se produce un error en la solicitud anterior al límite, puede deberse a problemas de configuración.
- Compruebe los registros de servicio para determinar si hay otros errores.
- Confirme que el modelo ha funcionado localmente, como desde un cuaderno o en solicitudes anteriores en versiones anteriores.
Tiempos de espera del lado cliente: configuración de MLflow
Los tiempos de espera del lado cliente normalmente devuelven mensajes de error que dicen "se agota el tiempo de espera" o 4xx Solicitud incorrecta. Las causas comunes de estos tiempos de espera proceden de configuraciones de variables de entorno de MLflow. A continuación se muestran las variables de entorno de MLflow más comunes para los tiempos de espera. Para obtener la lista completa de variables de tiempo de espera, consulte la documentación de mlflow.environment_variables.
- MLFLOW_HTTP_REQUEST_TIMEOUT: especifica el tiempo de espera en segundos para las solicitudes HTTP de MLflow. Tiempo de espera predeterminado de 120 segundos.
- MLFLOW_HTTP_REQUEST_MAX_RETRIES: especifica el número máximo de reintentos con retroceso exponencial para las solicitudes HTTP de MLflow. El valor predeterminado es de 7 segundos.
Nota:
Los tiempos de espera de solicitud HTTP del lado cliente se establecen en 120 segundos, lo que difiere del tiempo de espera predeterminado del lado servidor de 297 segundos para los puntos de conexión de servicio de CPU y GPU. Ajuste las variables de entorno de MLflow en consecuencia si espera que la carga de trabajo supere el tiempo de espera del lado cliente de 120 segundos.
Realice una de las siguientes acciones para determinar si un tiempo de espera se debe a una configuración de variables de entorno de MLflow:
- Pruebe el modelo localmente mediante entradas de ejemplo, como en un cuaderno, para confirmar que funciona según lo previsto antes de registrar el modelo e implementarlo.
- Examine el tiempo necesario para procesar las solicitudes.
- Si las solicitudes tardan más de lo que permiten los tiempos de espera predeterminados para las variables de entorno de MLflow o si obtiene un mensaje de "tiempo de espera agotado" en el cuaderno. Mensaje de ejemplo de "tiempo de espera agotado" :
Timed out while evaluating the model. Verify that the model evaluates within the timeout.
- Examine el tiempo necesario para procesar las solicitudes.
- Pruebe el punto final del servicio del modelo mediante solicitudes POST.
- Compruebe los registros de servicio para el punto de conexión o las tablas de inferencia si los ha habilitado.
- Si desea usar un modelo personalizado, consulte el esquema de la tabla de inferencia del Catálogo de Unity.
- Si su punto de conexión sirve modelos externos, cargas de trabajo con rendimiento aprovisionado o modelos de agentes, consulte esquema de la tabla de inferencia habilitada para el Gateway de AI de Unity.
- Compruebe los registros de servicio para el punto de conexión o las tablas de inferencia si los ha habilitado.
Configuración de variables de entorno de MLflow
Configure las variables de entorno de MLflow mediante la interfaz de usuario de servicio o mediante programación mediante Python.
Interfaz de usuario de servicio
Puede configurar variables de entorno para una implementación de modelos.
- Seleccione el punto de conexión para el que desea configurar una variable de entorno.
- En la página del punto de conexión, seleccione Editar en la parte superior derecha.
- En "Detalles de la entidad", expanda Configuración avanzada para agregar la variable de entorno de tiempo de espera de MLflow pertinente.
Consulte Adición de variables de entorno de texto sin formato.
Pitón
Puede configurar mediante programación un punto de conexión de servicio de modelo e incluir variables de entorno de MLflow ajustadas mediante Python. En el ejemplo siguiente se ajusta el tiempo de espera máximo a 300 segundos y el número máximo de reintentos en tres.
Para más información sobre la carga útil para configurarlo, consulte la página API de Databricks.
import mlflow.deployments
# Get the deployment client
client = mlflow.deployments.get_deploy_client("databricks")
# Define the configuration with environment variables
config = {
"served_entities": [
{
"name": "sklearn_example-1",
"entity_name": "catalog.schema.model_name",
"entity_version": "1",
"workload_size": "Small",
"workload_type": "CPU",
"scale_to_zero_enabled": True,
"environment_vars": {
"MLFLOW_HTTP_REQUEST_MAX_RETRIES": 3,
"MLFLOW_HTTP_REQUEST_TIMEOUT": 300
}
},
],
"traffic_config": {
"routes": [
{
"served_model_name": "model_name-1",
"traffic_percentage": 100
}
]
}
}
# Create the endpoint with the specified configuration
endpoint = client.create_endpoint(
name="model_name-1",
config=config
)
Tiempos de espera del lado cliente: las API de terceros
Los tiempos de espera del lado cliente normalmente devuelven mensajes de error que dicen "se agota el tiempo de espera" o 4xx Solicitud incorrecta. De forma similar a las configuraciones de MLflow, las API de cliente de terceros pueden provocar tiempos de espera del lado cliente en función de su configuración. Estos pueden afectar a los puntos de conexión del servicio de modelos que constan de canalizaciones que utilizan estas API de cliente de terceros. Consulte modelos de PyFunc personalizados y agentes de esquema personalizados de PyFunc.
De forma similar a las instrucciones de depuración de configuración de MLflow, haga lo siguiente para determinar si un tiempo de espera se debe a las API de cliente de terceros que se usan en la canalización del modelo:
- Pruebe el modelo localmente con entradas de ejemplo en un cuaderno.
- Si ve un mensaje de tiempo de espera excedido en el bloc de notas, ajuste los parámetros pertinentes para la ventana de tiempo de espera del cliente externo.
- Mensaje de ejemplo de "tiempo de espera agotado" :
APITimeoutError: Request timed out.
- Pruebe el punto final del servicio del modelo mediante solicitudes POST.
- Compruebe los registros de servicio para el punto de conexión o las tablas de inferencia si los ha habilitado.
- Si desea usar un modelo personalizado, consulte el esquema de la tabla de inferencia del Catálogo de Unity.
- Si su punto de conexión sirve modelos externos, cargas de trabajo de rendimiento aprovisionado o modelos de agente, consulte el esquema de la tabla de inferencia habilitada por el Gateway de AI de Unity.
- Compruebe los registros de servicio para el punto de conexión o las tablas de inferencia si los ha habilitado.
Ejemplo de cliente de OpenAI
Al establecer un cliente de OpenAI, puede configurar el timeout parámetro para cambiar el tiempo máximo antes de que se agote el tiempo de espera de una solicitud en el lado cliente. El tiempo de espera predeterminado y máximo para un cliente de OpenAI es de 10 minutos.
En el ejemplo siguiente se resalta cómo configurar un tiempo de espera de las API de cliente de terceros.
%pip install openai
dbutils.library.restartPython()
from openai import OpenAI
import os
# How to get your Databricks token: https://docs.databricks.com/en/dev-tools/auth/pat.html
DATABRICKS_TOKEN = os.environ.get('DATABRICKS_TOKEN')
client = OpenAI(
timeout=10, # Number of seconds before client times out
api_key=DATABRICKS_TOKEN,
base_url="<WORKSPACE_URL>/serving-endpoints"
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are an AI assistant"
},
{
"role": "user",
"content": "Tell me about Large Language Models."
}
],
model="model_name",
max_tokens=256
)
Nota:
Para el cliente de OpenAI, puede eludir la limitación de tiempo máximo habilitando streaming.
Otros límites de tiempo de espera
Puntos de conexión inactivos que se calientan
Si un punto de conexión se escala a 0 y recibe una solicitud que lo calienta, podría provocar un tiempo de espera del lado cliente si tarda demasiado en calentarse. Esto puede ser una causa de tiempos de espera en canalizaciones que aprovechan pasos como llamadas a puntos de conexión de rendimiento aprovisionados o índices de búsqueda vectorial, como se mencionó anteriormente.
Tiempo de espera de conexión
Los tiempos de espera de conexión están relacionados con el tiempo que un cliente espera para establecer una conexión con el servidor. Si la conexión no se establece en este momento, el cliente cancela el intento. Es importante tener en cuenta los clientes usados en la canalización del modelo y comprobar los registros de servicio y las tablas de inferencia del endpoint de Model Serving para detectar cualquier tiempo de espera de conexión. La mensajería varía según el servicio.
- Por ejemplo, un SocketTimeout (para la lectura/escritura de un servicio a un extremo de SQL a través de una conexión JDBC) puede verse como el siguiente:
jdbc:spark://<server-hostname>:443;HttpPath=<http-path>;TransportMode=http;SSL=1[;property=value[;property=value]];SocketTimeout=300
- Para encontrarlos, busque mensajes de error que contengan el término "tiempo de espera" o "tiempo de espera".
Límites de tarifas
Varias solicitudes realizadas a través del límite de velocidad de un punto de conexión pueden provocar errores en las solicitudes adicionales. Consulte Límites de recursos y carga para conocer los límites de velocidad en función de los tipos de punto de conexión. Para clientes de terceros, Databricks recomienda revisar la documentación del cliente de terceros que usa.