Nota
L'accés a aquesta pàgina requereix autorització. Pots provar d'iniciar sessió o canviar de directori.
L'accés a aquesta pàgina requereix autorització. Pots provar de canviar directoris.
Importante
Esta característica está en versión preliminar pública.
En este artículo se muestra cómo ejecutar un experimento de previsión sin servidor mediante la interfaz de usuario de entrenamiento de modelos de IA de Mosaico.
Mosaic AI Model Training: El pronóstico simplifica la predicción de datos de series temporales mediante la selección automática del mejor algoritmo e hiperparámetros, todo ello mientras se ejecuta en recursos informáticos totalmente gestionados.
Para comprender la diferencia entre la previsión sin servidor y la previsión de proceso clásica, consulte Previsión sin servidor frente a previsión de proceso clásica.
Requisitos
- Datos de entrenamiento con una columna de serie temporal, guardados como una tabla de Unity Catalog.
- Si el área de trabajo tiene habilitada la puerta de enlace de salida segura (SEG),
pypi.orgdebe agregarse a la lista Dominios permitidos . Consulte Administración de directivas de red para el control de salida sin servidor.
Creación de un experimento de previsión con la interfaz de usuario
Vaya a la página de aterrizaje de Azure Databricks y haga clic en Experimentos en la barra lateral.
En el icono Previsión , seleccione Iniciar entrenamiento.
Seleccione los datos de entrenamiento de una lista de tablas de Catálogo de Unity a las que puede acceder.
-
Columna de tiempo: seleccione la columna que contiene los períodos de tiempo de la serie temporal. Las columnas deben ser de tipo
timestampodate. - Frecuencia de previsión: seleccione la unidad de tiempo que representa la frecuencia de los datos de entrada. Por ejemplo, minutos, horas, días, meses. Esto determina la granularidad de la serie temporal.
- Horizonte de previsión: especifique cuántas unidades de la frecuencia seleccionada se van a predecir en el futuro. Junto con la frecuencia de previsión, esto define las unidades de tiempo y el número de unidades de tiempo que se van a predecir.
Nota:
Para usar el algoritmo Auto-ARIMA , la serie temporal debe tener una frecuencia regular en la que el intervalo entre dos puntos debe ser el mismo en toda la serie temporal. AutoML controla los pasos de tiempo que faltan rellenando esos valores con el valor anterior.
-
Columna de tiempo: seleccione la columna que contiene los períodos de tiempo de la serie temporal. Las columnas deben ser de tipo
Seleccione una columna destino de predicción que quiera predecir el modelo.
Opcionalmente, especifique una tabla de Unity Catalog y una ruta de acceso de datos de predicción para almacenar las previsiones de salida.
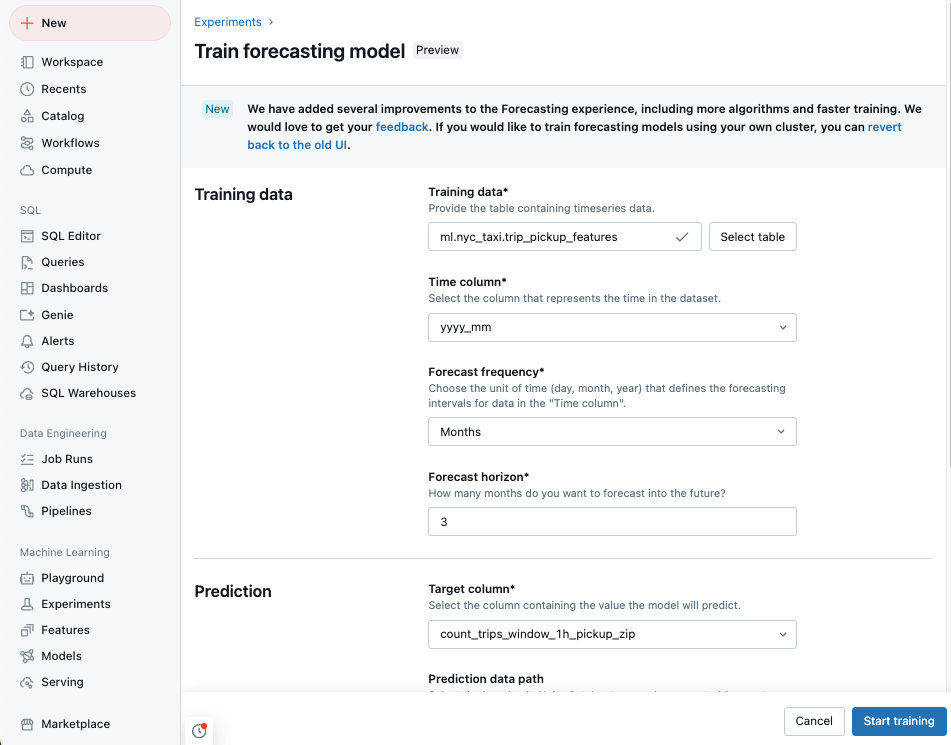
Seleccione una ubicación y un nombre para el registro de modelos del Catálogo Unity.
Opcionalmente, establezca Opciones avanzadas:
- Nombre del experimento: proporcione un nombre del experimento de MLflow.
- Columnas de identificador de serie temporal : para la previsión de varias series, seleccione las columnas que identifican la serie temporal individual. Databricks agrupa los datos por estas columnas como series temporales diferentes y entrena un modelo para cada serie de forma independiente.
- Métrica principal: elija la métrica principal que se usa para evaluar y seleccionar el mejor modelo.
- Marco de entrenamiento: elija los marcos de AutoML que desea explorar.
- Dividir columna: seleccione la columna que contiene la división de datos personalizada. Los valores deben ser "entrenar", "validar", "probar"
- Columna de peso: especifique la columna que se va a usar para ponderar series temporales. Todas las muestras de una serie temporal determinada deben tener el mismo peso. El peso debe estar en el intervalo [0, 10000].
- Región de vacaciones: seleccione la región de vacaciones que se usará como covariante en el entrenamiento del modelo.
- Tiempo de espera: establezca una duración máxima para el experimento de AutoML.
Ejecución del experimento y comprobación de los resultados
Para iniciar el experimento de AutoML, haga clic en Iniciar entrenamiento. En la página de entrenamiento del experimento, puede hacer lo siguiente:
- Detener el experimento en cualquier momento.
- Supervisar las ejecuciones.
- Ir a la página de ejecución de cualquier ejecución.
Además, puede comprobar el estado del experimento a medida que pasa por las siguientes fases:
- Preprocesamiento: Valide y prepare la tabla de entrada mediante la imputación de valores que faltan y la división de datos en conjuntos de entrenamiento, validación y pruebas. El procesamiento automático de generación de características, como la codificación one-hot para variables categóricas, también ocurre durante esta fase.
- Sintonización: Explore diferentes algoritmos de previsión y ajuste de hiperparámetros.
- Adiestramiento: Entrene y evalúe el modelo final con las mejores configuraciones seleccionadas. Registre el modelo en el catálogo de Unity si se especifica una ruta de acceso.
Visualización de resultados o uso del mejor modelo
Una vez completado el entrenamiento, los resultados de la predicción se almacenan en la tabla Delta especificada y el mejor modelo se registra en el catálogo de Unity.
En la página experimentos, elija entre los siguientes pasos:
- Seleccione Ver predicciones para ver la tabla de resultados de previsión.
- Seleccione Cuaderno de inferencia por lotes para abrir un cuaderno generado automáticamente para la inferencia por lotes mediante el mejor modelo.
- Seleccione Crear punto de conexión de servicio para implementar el mejor modelo en un punto de conexión de servicio de modelos.
Previsión sin servidor frente a previsión de proceso clásica
En la tabla siguiente se resumen las diferencias entre la previsión sin servidor y la previsión con el proceso clásico.
| Característica | Previsión sin servidor | Previsión de computación clásica |
|---|---|---|
| Infraestructura de cómputo | Azure Databricks administra la configuración de proceso y optimiza automáticamente el costo y el rendimiento. | Cómputo configurado por el usuario |
| Gobernanza | Modelos y artefactos registrados en el catálogo de Unity | Almacén de archivos del área de trabajo configurado por el usuario |
| Selección del algoritmo | Modelos estadísticos más el algoritmo de red neuronal de aprendizaje profundo DeepAR | Modelos estadísticos |
| Integración del Almacén de características | No está soportado | Soportado |
| Cuadernos generados automáticamente | Cuaderno de inferencia por lotes | Código fuente para todas las pruebas |
| Modelo de un solo clic que atiende la implementación | Compatible | Sin fundamento |
| Divisiones personalizadas de entrenamiento, validación y prueba | Compatible | No está soportado |
| Pesos personalizados para series temporales individuales | Compatible | No está soportado |