Nota
L'accés a aquesta pàgina requereix autorització. Pots provar d'iniciar sessió o canviar de directori.
L'accés a aquesta pàgina requereix autorització. Pots provar de canviar directoris.
Los modelos registrados de MLflow le ayudan a realizar un seguimiento del progreso de un modelo a lo largo de su ciclo de vida. Al entrenar un modelo, use mlflow.<model-flavor>.log_model() para crear un LoggedModel que vinculo toda su información crítica mediante un identificador único. Para aprovechar la eficacia de LoggedModels, empiece a trabajar con MLflow 3.
En el caso de las aplicaciones de GenAI, LoggedModels se puede crear para capturar confirmaciones de Git o conjuntos de parámetros como objetos dedicados que, a continuación, se pueden vincular a seguimientos y métricas. En el aprendizaje profundo y el aprendizaje automático clásico, LoggedModels se generan a partir de ejecuciones de MLflow, que son conceptos existentes en MLflow y se pueden considerar como trabajos que ejecutan código de modelo. Las ejecuciones de entrenamiento generan modelos como salidas y las ejecuciones de evaluación usan modelos existentes como entrada para generar métricas y otra información que puede usar para evaluar el rendimiento de un modelo.
El LoggedModel objeto persiste durante todo el ciclo de vida del modelo, en distintos entornos y contiene vínculos a artefactos como metadatos, métricas, parámetros y el código usado para generar el modelo. El seguimiento de modelos registrados le permite comparar modelos entre sí, buscar el modelo más eficaz y realizar un seguimiento de la información durante la depuración.
Los modelos registrados también se pueden registrar en el registro de modelos del catálogo de Unity, lo que hace que la información sobre el modelo de todos los experimentos y áreas de trabajo de MLflow estén disponibles en una sola ubicación. Para más información, consulte Mejoras del Registro de modelos con MLflow 3.
![]()
Seguimiento mejorado para la inteligencia artificial de generación y los modelos de aprendizaje profundo
Los flujos de trabajo de inteligencia artificial generativa y aprendizaje profundo se benefician especialmente del seguimiento pormenorizados que proporcionan los modelos registrados.
Gen AI: datos de seguimiento y evaluación unificados:
- Los modelos de Gen AI generan métricas adicionales durante la evaluación y la implementación, como los datos de comentarios de los revisores y los seguimientos.
- La
LoggedModelentidad permite consultar toda la información generada por un modelo mediante una sola interfaz.
Aprendizaje profundo: administración eficaz de puntos de control:
- El entrenamiento de aprendizaje profundo crea varios puntos de control, que son instantáneas del estado del modelo en un punto determinado durante el entrenamiento.
- MLflow crea un elemento independiente
LoggedModelpara cada punto de control, que contiene las métricas y los datos de rendimiento del modelo. Esto le permite comparar y evaluar los puntos de control para identificar los modelos de mejor rendimiento de forma eficaz.
Creación de un modelo registrado
Para crear un modelo registrado, use la misma log_model() API que las cargas de trabajo de MLflow existentes. Los fragmentos de código siguientes muestran cómo crear un modelo registrado para la inteligencia artificial generativa, el aprendizaje profundo y los flujos de trabajo de aprendizaje automático tradicionales.
Para obtener ejemplos completos de cuadernos ejecutables, consulte Cuadernos de ejemplo.
Gen AI
El siguiente fragmento de código muestra cómo registrar un agente langChain. Use el log_model() método para el tipo de agente.
# Log the chain with MLflow, specifying its parameters
# As a new feature, the LoggedModel entity is linked to its name and params
model_info = mlflow.langchain.log_model(
lc_model=chain,
name="basic_chain",
params={
"temperature": 0.1,
"max_tokens": 2000,
"prompt_template": str(prompt)
},
model_type="agent",
input_example={"messages": "What is MLflow?"},
)
# Inspect the LoggedModel and its properties
logged_model = mlflow.get_logged_model(model_info.model_id)
print(logged_model.model_id, logged_model.params)
Inicie un trabajo de evaluación y vincule las métricas a un modelo registrado proporcionando el identificador único model_id para el LoggedModel.
# Start a run to represent the evaluation job
with mlflow.start_run() as evaluation_run:
eval_dataset: mlflow.entities.Dataset = mlflow.data.from_pandas(
df=eval_df,
name="eval_dataset",
)
# Run the agent evaluation
result = mlflow.evaluate(
model=f"models:/{logged_model.model_id}",
data=eval_dataset,
model_type="databricks-agent"
)
# Log evaluation metrics and associate with agent
mlflow.log_metrics(
metrics=result.metrics,
dataset=eval_dataset,
# Specify the ID of the agent logged above
model_id=logged_model.model_id
)
Aprendizaje profundo
El siguiente fragmento de código muestra cómo crear modelos registrados durante el entrenamiento de aprendizaje profundo. Utiliza el método log_model() para tu variante de modelo de MLflow.
# Start a run to represent the training job
with mlflow.start_run():
# Load the training dataset with MLflow. We will link training metrics to this dataset.
train_dataset: Dataset = mlflow.data.from_pandas(train_df, name="train")
X_train, y_train = prepare_data(train_dataset.df)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(scripted_model.parameters(), lr=0.01)
for epoch in range(101):
X_train, y_train = X_train.to(device), y_train.to(device)
out = scripted_model(X_train)
loss = criterion(out, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Obtain input and output examples for MLflow Model signature creation
with torch.no_grad():
input_example = X_train[:1]
output_example = scripted_model(input_example)
# Log a checkpoint with metrics every 10 epochs
if epoch % 10 == 0:
# Each newly created LoggedModel checkpoint is linked with its
# name, params, and step
model_info = mlflow.pytorch.log_model(
pytorch_model=scripted_model,
name=f"torch-iris-{epoch}",
params={
"n_layers": 3,
"activation": "ReLU",
"criterion": "CrossEntropyLoss",
"optimizer": "Adam"
},
step=epoch,
signature=mlflow.models.infer_signature(
model_input=input_example.cpu().numpy(),
model_output=output_example.cpu().numpy(),
),
input_example=X_train.cpu().numpy(),
)
# Log metric on training dataset at step and link to LoggedModel
mlflow.log_metric(
key="accuracy",
value=compute_accuracy(scripted_model, X_train, y_train),
step=epoch,
model_id=model_info.model_id,
dataset=train_dataset
)
Aprendizaje automático tradicional
El siguiente fragmento de código muestra cómo registrar un modelo sklearn y vincular las métricas a Logged Model. Utiliza el método log_model() para tu variante de modelo de MLflow.
## Log the model
model_info = mlflow.sklearn.log_model(
sk_model=lr,
name="elasticnet",
params={
"alpha": 0.5,
"l1_ratio": 0.5,
},
input_example = train_x
)
# Inspect the LoggedModel and its properties
logged_model = mlflow.get_logged_model(model_info.model_id)
print(logged_model.model_id, logged_model.params)
# Evaluate the model on the training dataset and log metrics
# These metrics are now linked to the LoggedModel entity
predictions = lr.predict(train_x)
(rmse, mae, r2) = compute_metrics(train_y, predictions)
mlflow.log_metrics(
metrics={
"rmse": rmse,
"r2": r2,
"mae": mae,
},
model_id=logged_model.model_id,
dataset=train_dataset
)
Cuadernos de ejemplo
Para ver cuadernos de ejemplo que ilustran el uso de LoggedModels, vea las páginas siguientes:
Ver modelos y realizar un seguimiento del progreso
Puede ver los modelos registrados en la interfaz de usuario del área de trabajo:
- Vaya a la pestaña Experimentos del área de trabajo.
- Seleccione un experimento. A continuación, seleccione la pestaña Modelos .
Esta página contiene todos los modelos registrados asociados al experimento, junto con sus métricas, parámetros y artefactos.
![]()
Puede generar gráficos para realizar un seguimiento de las métricas entre ejecuciones.
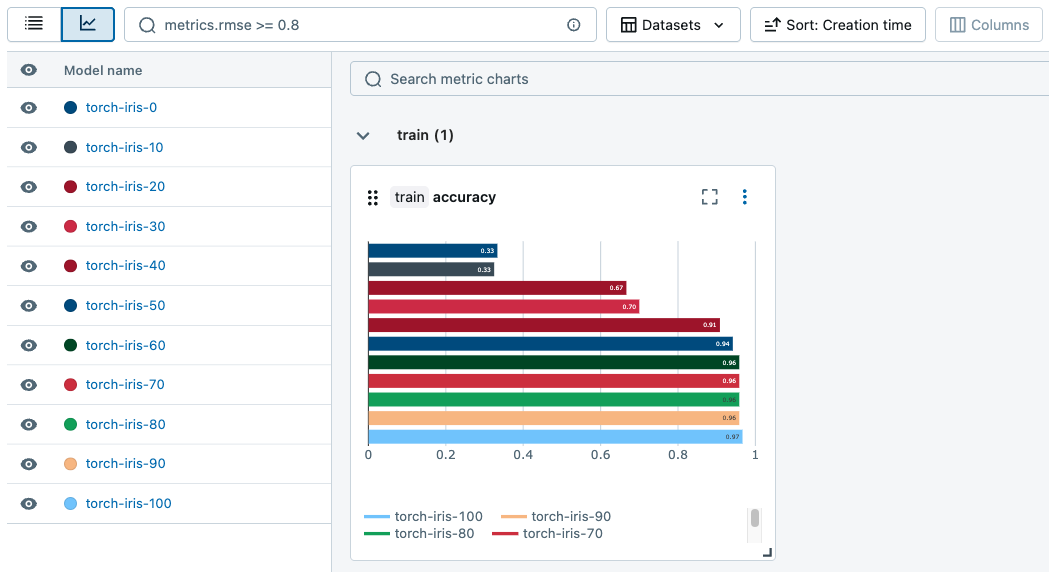
Buscar y filtrar modelos registrados
En la pestaña Modelos , puede buscar y filtrar modelos registrados en función de sus atributos, parámetros, etiquetas y métricas.
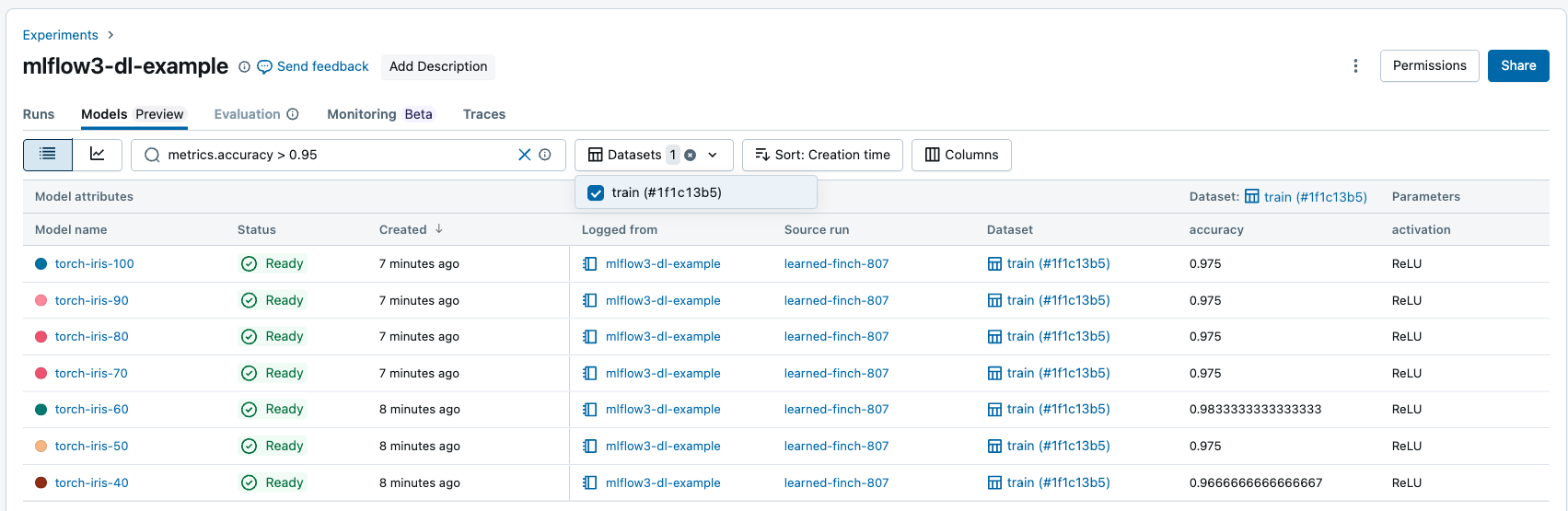
Puede filtrar las métricas en función del rendimiento específico del conjunto de datos y solo se devuelven los modelos con valores de métrica coincidentes en los conjuntos de datos especificados. Si se proporcionan filtros de conjunto de datos sin filtros para métricas, se devuelven modelos con cualquier métrica en esos conjuntos de datos.
Puede filtrar en función de los atributos siguientes:
model_idmodel_namestatusartifact_uri-
creation_time(numérico) -
last_updated_time(numérico)
Use los operadores siguientes para buscar y filtrar atributos, parámetros y etiquetas similares a cadenas:
-
=,!=, ,IN,NOT IN
Use los siguientes operadores de comparación para buscar y filtrar atributos numéricos y métricas:
-
=,!=,>,<, ,>=,<=
Buscar modelos registrados mediante programación
Puede buscar Modelos registrados mediante la API de MLflow:
## Get a Logged Model using a model_id
mlflow.get_logged_model(model_id = <my-model-id>)
## Get all Logged Models that you have access to
mlflow.search_logged_models()
## Get all Logged Models with a specific name
mlflow.search_logged_models(
filter_string = "model_name = <my-model-name>"
)
## Get all Logged Models created within a certain time range
mlflow.search_logged_models(
filter_string = "creation_time >= <creation_time_start> AND creation_time <= <creation_time_end>"
)
## Get all Logged Models with a specific param value
mlflow.search_logged_models(
filter_string = "params.<param_name> = <param_value_1>"
)
## Get all Logged Models with specific tag values
mlflow.search_logged_models(
filter_string = "tags.<tag_name> IN (<tag_value_1>, <tag_value_2>)"
)
## Get all Logged Models greater than a specific metric value on a dataset, then order by that metric value
mlflow.search_logged_models(
filter_string = "metrics.<metric_name> >= <metric_value>",
datasets = [
{"dataset_name": <dataset_name>, "dataset_digest": <dataset_digest>}
],
order_by = [
{"field_name": metrics.<metric_name>, "dataset_name": <dataset_name>,"dataset_digest": <dataset_digest>}
]
)
Para más información y parámetros de búsqueda adicionales, consulte la documentación de la API de MLflow 3.
Búsqueda se ejecuta por entradas y salidas del modelo
Puede buscar ejecuciones por identificador de modelo para devolver todas las ejecuciones que tienen el modelo registrado como entrada o salida. Para obtener más información sobre la sintaxis de la cadena del filtro, consulte Filtrado de ejecuciones.
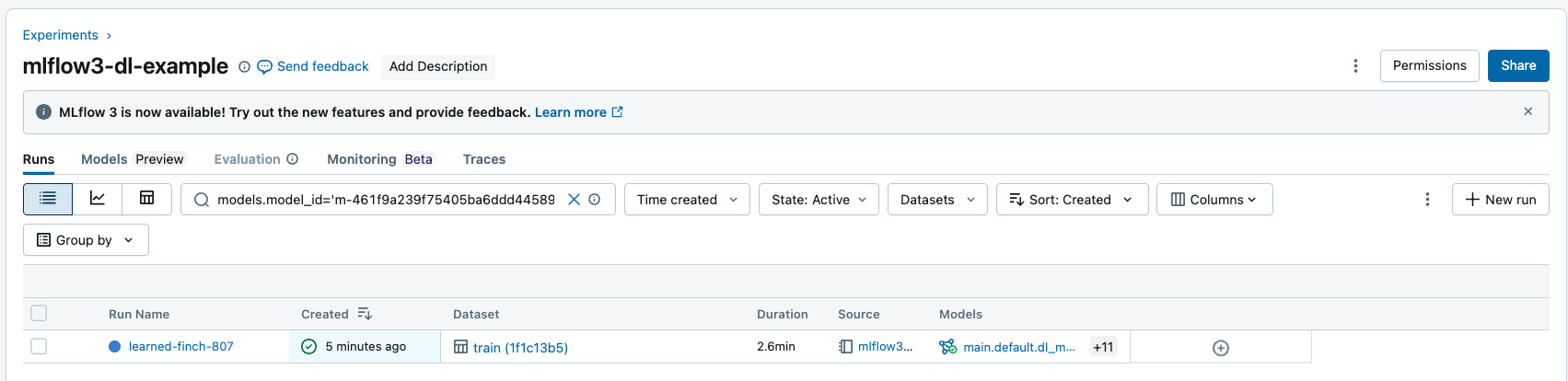
Puede buscar ejecuciones mediante la API de MLflow:
## Get all Runs with a particular model as an input or output by model id
mlflow.search_runs(filter_string = "models.model_id = <my-model-id>")
Pasos siguientes
Para más información sobre otras nuevas características de MLflow 3, consulte los siguientes artículos: