Conceptos de ingesta basada en manifiesto
La ingesta de archivos basada en manifiesto proporciona a los usuarios finales y sistemas un mecanismo sólido para cargar metadatos sobre los conjuntos de datos en la instancia de Azure Data Manager for Energy. El sistema indexa estos metadatos y permite al usuario final buscar en los conjuntos de datos.
La ingesta de archivos basada en manifiesto es una ingesta opaca que no analiza ni entiende el contenido del archivo. Crea un registro de metadatos basado en el manifiesto y hace que el registro se pueda buscar.
¿Qué es un manifiesto?
Un manifiesto es un documento JSON que tiene una estructura predefinida para capturar entidades definidas como "kind", es decir, registradas como esquemas con el servicio Schema: Definiciones de esquema conocido (WKS).
Puede encontrar un documento json de manifiesto de ejemplo aquí.
El esquema de manifiesto tiene contenedores para los siguientes Tipos de grupo de OSDU®:
- ReferenceData (cero o más): conjunto de valores permitidos que otros campos de datos (maestros o de transacción) usarán. Algunos ejemplos son Unidad de medida (pies), Moneda, etc.
- MasterData (cero o más): origen único de datos empresariales básicos que se usan en varios sistemas, aplicaciones o procesos. Algunos ejemplos son Pozos y Perforaciones
- WorkProduct (WP) (uno; debe existir si se cargan WorkProductComponents): un límite de sesión o recopilación (proyecto, estudio) abarca un conjunto de entidades que se deben procesar en conjunto. Por ejemplo, puede tomar la ingesta de una o varias recopilaciones de registros.
- WorkProductComponents (WPC) (cero o más; debe existir si se cargan conjuntos de datos): unidad de contenido de datos empresariales con tipo, más pequeña y de uso independiente transferida como parte de un producto de trabajo (una recopilación de elementos ingeridos juntos). Por lo general, cada componente de producto de trabajo (WPC) usa datos de referencia, pertenece a algunos datos maestros y mantiene una referencia a los conjuntos de datos. Ejemplo: Registros de pozos, errores, documentos
- Conjuntos de datos (cero o más; debe existir si se cargan registros de WorkProduct y WorkProductComponent): cada componente de producto de trabajo (WPC) consta de uno o varios contenedores de datos, conocidos como "conjuntos de datos".
Los datos del manifiesto se cargan en una secuencia determinada:
- Matriz "ReferenceData" (si se rellena).
- Matriz "MasterData" (si se rellena).
- La estructura "Datos" se procesa por última vez (si se rellena). Dentro de la propiedad "Datos", el procesamiento se realiza en el orden siguiente:
- matriz "Conjuntos de datos"
- matriz "WorkProductComponents"
- "WorkProduct".
Se ordenan todas las matrices. si hay interdependencias, los elementos dependientes deben colocarse detrás de sus destinos de relación, por ejemplo, un registro Well de datos maestros debe colocarse en la matriz "MasterData" antes de su Wellbores.
Flujo de trabajo de ingesta de archivos basado en manifiestos
La instancia de Azure Data Manager for Energy tiene compatibilidad integrada con el flujo de trabajo de ingesta de archivos basado en manifiesto. Osdu_ingest DAG de Airflow está preconfigurado en la instancia.
Componentes de flujo de trabajo de ingesta de archivos basados en manifiesto
El flujo de trabajo de ingesta de archivos basado en manifiesto consta de los siguientes componentes:
- Servicio de flujo de trabajo: Un servicio contenedor que se ejecuta sobre el motor de flujo de trabajo de Airflow.
- Motor Airflow:: Un motor de orquestación de flujo de trabajo que ejecuta flujos de trabajo registrados como DAG (Gráficos Acíclicos dirigidos). Airflow es el motor de flujo de trabajo elegido por la OSDU® comunidad para organizar y ejecutar flujos de trabajo de ingesta. Airflow no se expone directamente, sino que se accede a sus características a través del servicio de flujo de trabajo.
- Servicio de almacenamiento: Un servicio que se usa para guardar los registros de metadatos del manifiesto en la plataforma de datos.
- Servicio Schema: Servicio que administra esquemas definidos por OSDU® en la plataforma de datos. Se hace referencia a los esquemas durante la ingesta de archivos basada en manifiesto.
- Servicio de derechos: Un servicio que administra los grupos de acceso. Este servicio se usa durante la ingesta para comprobar los permisos de ingesta. También se usa durante la recuperación del registro de metadatos para validar escrituras de "lectura".
- Servicio legal: Un servicio que valida el cumplimiento a través de etiquetas legales.
- El servicio de búsqueda se usa para realizar la comprobación de integridad referencial durante el proceso de ingesta del manifiesto.
Requisitos previos
Antes de ejecutar el flujo de trabajo de ingesta de archivos basado en manifiesto, los clientes deben asegurarse de que las cuentas de usuario que ejecutan el flujo de trabajo tengan acceso a los servicios principales (Búsqueda, Almacenamiento, Esquema, Derecho y Legal) y el servicio Workflow (vea Roles de derechos para obtener más información). Como parte del aprovisionamiento de instancias de Azure Data Manager for Energy, los esquemas estándar de OSDU® y los datos de referencia asociados se cargan previamente. Los clientes deben asegurarse de que la cuenta de usuario utilizada para ingerir los manifiestos se incluye en los propietarios adecuados y las ACL de visores. Los clientes deben asegurarse de que los manifiestos están configurados con etiquetas legales correctas, propietarios y visores ACL, datos de referencia, etc.
Secuencia de flujo de trabajo
En la ilustración siguiente se proporciona el flujo de trabajo de ingesta de archivos basado en manifiesto: 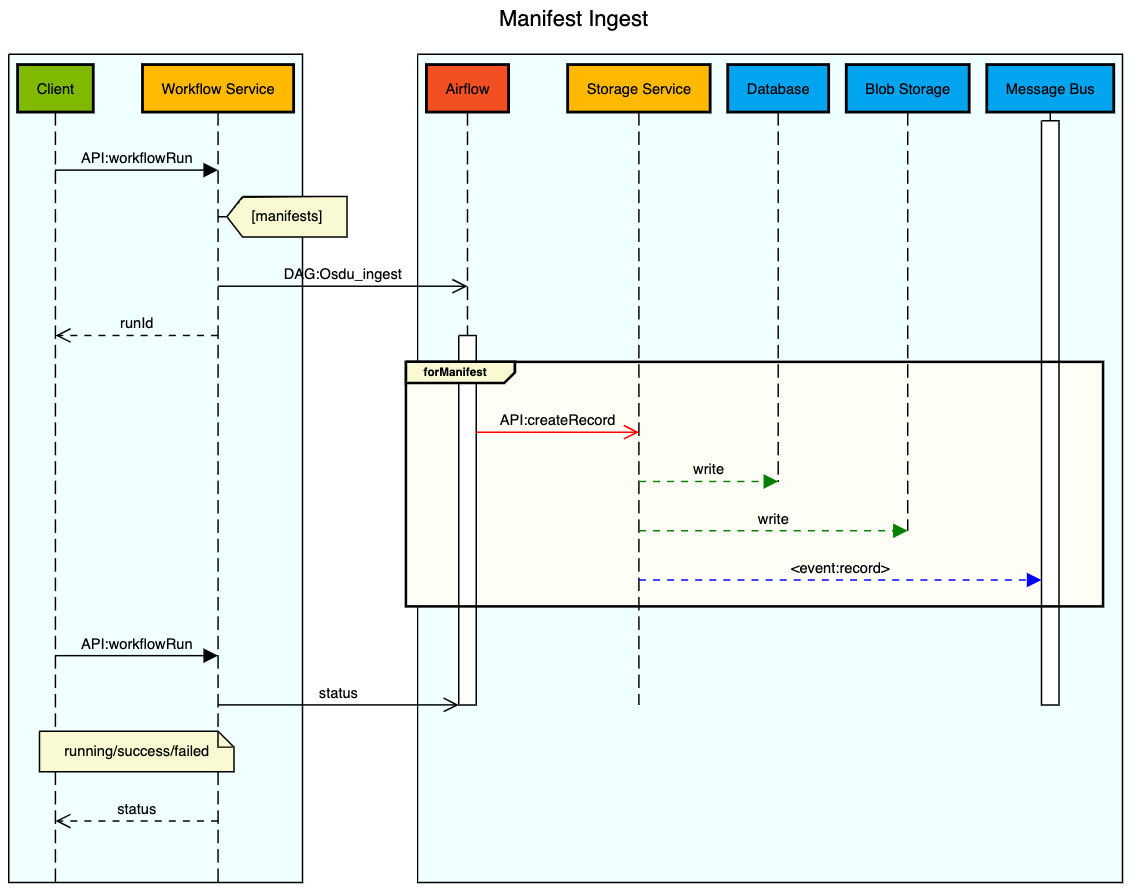
Un usuario envía un manifiesto al Workflow Service mediante el nombre del flujo de trabajo de ingesta de manifiestos ("Osdu_ingest"). Si la solicitud es adecuada y el usuario está autorizado para ejecutar el flujo de trabajo, el servicio de flujo de trabajo carga el manifiesto e inicia el flujo de trabajo de ingesta de manifiestos.
El servicio de flujo de trabajo ejecuta una serie de manifiestos syntax validation como la estructura del manifiesto y la validación de atributos según el esquema definido y comprueba si hay atributos de esquema obligatorios. A continuación, el sistema realiza referential integrity validation entre componentes del producto de trabajo y conjuntos de datos. Por ejemplo, si existen los datos primarios a los que se hace referencia.
Una vez que las validaciones se realizan correctamente, el sistema procesa el contenido en el almacenamiento escribiendo cada entidad válida en la plataforma de datos mediante la API del servicio de almacenamiento.
OSDU® es una marca comercial de The Open Group.