Escalado automático de clústeres de Azure HDInsight en AKS
Nota:
Retiraremos Azure HDInsight en AKS el 31 de enero de 2025. Antes del 31 de enero de 2025, deberá migrar las cargas de trabajo a Microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo. Los clústeres restantes de la suscripción se detendrán y quitarán del host.
Solo el soporte técnico básico estará disponible hasta la fecha de retirada.
Importante
Esta funcionalidad actualmente está en su versión preliminar. En Términos de uso complementarios para las versiones preliminares de Microsoft Azure encontrará más términos legales que se aplican a las características de Azure que están en versión beta, en versión preliminar, o que todavía no se han lanzado con disponibilidad general. Para más información sobre esta versión preliminar específica, consulte la Información de Azure HDInsight sobre la versión preliminar de AKS. Para plantear preguntas o sugerencias sobre la característica, envíe una solicitud en AskHDInsight con los detalles y síganos para obtener más actualizaciones sobre Comunidad de Azure HDInsight.
El ajuste de tamaño de cualquier clúster para satisfacer el rendimiento del trabajo y administrar los costos con antelación siempre es complicado y difícil de determinar. Una de las ventajas lucrativas de la construcción de una casa de lago de datos a través de la nube es su elasticidad, lo que significa usar la característica de escalado automático para maximizar el uso de los recursos a mano. El escalado automático con Kubernetes es una clave para establecer un ecosistema optimizado para costos. Con patrones de uso variados en cualquier empresa, podría haber variaciones en las cargas de clúster a lo largo del tiempo que podrían dar lugar a que los clústeres se aprovisionan bajo aprovisionamiento (rendimiento excesivo) o sobreaprovisionados (costos innecesarios debido a los recursos inactivos).
La característica de escalado automático que se ofrece en HDInsight en AKS puede aumentar o disminuir automáticamente el número de nodos de trabajo del clúster. El escalado automático usa las métricas del clúster y la directiva de escalado que usan los clientes.
Esta característica es adecuada para cargas de trabajo críticas, que pueden tener
- Patrones de tráfico variables o imprevisibles y requieren acuerdos de nivel de servicio en alto rendimiento y escalado o
- Programación predeterminada para que los nodos de trabajo necesarios estén disponibles para ejecutar correctamente los trabajos en el clúster.
El escalado automático con HDInsight en clústeres de AKS hace que los clústeres sean rentables y elásticos en Azure.
Con el escalado automático, los clientes pueden reducir verticalmente los clústeres sin afectar a las cargas de trabajo. Se habilita con funcionalidades avanzadas, como la retirada y el período de refrigeración correctos. Estas funcionalidades permiten a los usuarios tomar decisiones informadas sobre la adición y eliminación de nodos en función de la carga actual del clúster.
Cómo funciona
Esta característica funciona escalando el número de nodos dentro de los límites preestablecidos en función de las métricas del clúster o una programación definida de operaciones de escalado vertical y reducción vertical. Hay dos tipos de condiciones para desencadenar eventos de escalado automático: desencadenadores basados en umbrales para varias métricas de rendimiento del clúster (denominada escalado basado en carga) y desencadenadores basados en tiempo (denominado escalado basado en programación).
El escalado basado en cargas cambia el número de nodos del clúster, dentro de un intervalo establecido, para garantizar el uso de CPU óptimo y minimizar el costo de ejecución.
El escalado basado en programación cambia el número de nodos del clúster en función de una programación de operaciones de escalado y reducción vertical.
Nota:
La escala automática no admite cambiar el tipo de SKU de un clúster existente.
Compatibilidad con el clúster
En la tabla siguiente se describen los tipos de clúster compatibles con la característica de escalado automático y lo que está disponible o planeado.
| Carga de trabajo | Basado en carga | Basado en programación |
|---|---|---|
| Flink | Planeado | Sí |
| Trino | Sí** | Sí** |
| Spark | Sí** | Sí** |
**La retirada correcta se puede configurar.
Métodos de escalado
Escalado basado en programación:
Cuando se espera que los trabajos se ejecuten según programaciones fijas y durante una duración predecible o cuando se prevé un uso bajo durante horas específicas del día por ejemplo, entornos de prueba y desarrollo en horas posteriores al trabajo, trabajos de fin de día.

Escala basada en carga:
Cuando los patrones de carga fluctúan sustancialmente y impredeciblemente durante el día, por ejemplo, ordenan el procesamiento de datos con fluctuaciones aleatorias en los patrones de carga en función de varios factores.

Con la nueva opción configurar la regla de escalado, ahora puede personalizar las reglas de escalado.
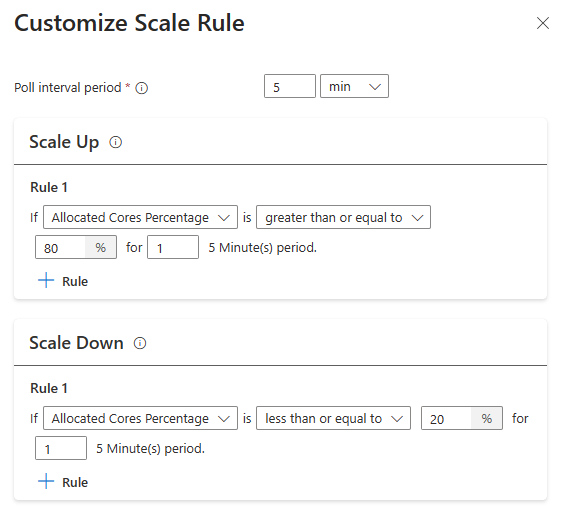

Sugerencia
- Las reglas de escalado vertical tienen prioridad cuando se desencadenan una o varias reglas. Incluso si solo una de las reglas para escalar verticalmente sugiere que el clúster está infraaprovisionado, el clúster intentará escalar verticalmente. Para que se produzca una reducción vertical, no se debe desencadenar ninguna regla de escalado vertical.


Condiciones de escalado basado en la carga
Cuando se detectan las condiciones siguientes, el escalado automático emite una solicitud de escalado.
| Escalabilidad vertical | Reducción vertical |
|---|---|
| Los núcleos asignados son mayores que el 80 % durante el intervalo de sondeo de 5 minutos (período de comprobación de 1 minuto) | Los núcleos asignados son menores o iguales que el 20 % para el intervalo de sondeo de 5 minutos (período de comprobación de 1 minuto) |
Para escalar verticalmente, el escalado automático emite una solicitud de escalado vertical para agregar el número necesario de nodos. El escalado vertical se basa en el número de nodos de trabajo nuevos que son necesarios para satisfacer los requisitos de CPU y memoria actuales. Este valor se limita al número máximo de nodos de trabajo establecidos.
Para reducir verticalmente, el escalado automático emite una solicitud para quitar algunos nodos. Las consideraciones de reducción vertical incluyen el número de pods por nodo, los requisitos actuales de CPU y memoria y los nodos de trabajo, que son candidatos para la eliminación en función de la ejecución actual del trabajo. En primer lugar, la operación de reducción vertical retira los nodos y, luego, los quita del clúster.
Importante
El motor de reglas de escalado automático vacía de forma proactiva los eventos antiguos cada 30 minutos para optimizar la memoria del sistema. Como resultado, existe un límite máximo de 30 minutos en el intervalo de regla de escalado. Para garantizar el desencadenador coherente y confiable de las acciones de escalado, es imperativo establecer el intervalo de regla de escalado en un valor menor que el límite. Al cumplir esta guía, puede garantizar un proceso de escalado suave y eficaz, a la vez que administra eficazmente los recursos del sistema.
Métricas del clúster
El escalado automático supervisa continuamente el clúster y recopila las siguientes métricas para la escalabilidad automática basada en carga:
Métricas de clúster disponibles con fines de escalado
| Métrica | Descripción |
|---|---|
| Porcentaje de núcleos disponibles | El número total de núcleos disponibles en el clúster en comparación con el número total de núcleos del clúster. |
| Porcentaje de memoria disponible | Memoria total (en MB) disponible en el clúster en comparación con la cantidad total de memoria del clúster. |
| Porcentaje de núcleos asignados | El número total de núcleos asignados en el clúster en comparación con el número total de núcleos del clúster. |
| Porcentaje de memoria asignada | Cantidad de memoria asignada en el clúster en comparación con la cantidad total de memoria del clúster. |
De forma predeterminada, las métricas anteriores se comprueban cada 300 segundos, también se puede configurar al personalizar el intervalo de sondeo con la opción personalizar la escalabilidad automática. El escalado automático toma decisiones de escalado vertical o reducción vertical en función de estas métricas.
Nota:
De forma predeterminada, la escala automática usa la calculadora de recursos predeterminada para YARN para Apache Spark. El escalado basado en carga está disponible para clústeres de Apache Spark.
Retirada correcta
Las empresas necesitan formas de lograr la escala de petabyte con el escalado automático y retirar los recursos correctamente cuando ya no sean necesarios. En este escenario, la característica de retirada correcta resulta útil.
La retirada correcta permite que los trabajos se completen incluso después de que el escalado automático haya desencadenado la retirada de los nodos de trabajo. Esta característica permite que los nodos se sigan aprovisionando hasta que se completen los trabajos.
Trino: Los trabajadores tienen habilitada la retirada correcta de forma predeterminada. El coordinador permite finalizar el trabajo para finalizar sus tareas durante un período de tiempo configurado antes de quitar el trabajo del clúster. Puede configurar el tiempo de espera mediante el parámetro nativo de Trino
shutdown.grace-period, o en la página de configuración del servicio Azure Portal.Apache Spark: El escalado vertical puede afectar o detener cualquier trabajo en ejecución del clúster. Si habilita la configuración de retirada correcta en Azure Portal, incorpora la retirada correcta de nodos de YARN y garantiza que cualquier trabajo en curso en un nodo de trabajo se complete antes de que el nodo se quite del clúster de HDInsight en AKS.
Período de esporádico
Para evitar operaciones de escalado vertical continuo, el motor de escalado automático espera un intervalo configurable antes de iniciar otro conjunto de operaciones de escalado vertical. El valor predeterminado se establece en 180 segundos
Nota:
- En las reglas de escalado personalizadas, ningún desencadenador de regla puede tener un intervalo de desencadenador superior a 30 minutos. Después de que se produzca un evento de escalado automático, la cantidad de tiempo que se debe esperar antes de aplicar otra directiva de escalado.
- El período de acceso esporádico debe ser mayor que el intervalo de directiva, por lo que las métricas del clúster pueden restablecerse.
Introducción
Para que el escalado automático funcione, es necesario asignar el propietario o colaborador del permiso a MSI (que se usa durante la creación del clúster) en el nivel de clúster, mediante IAM en el panel izquierdo.
Consulte la siguiente ilustración y los pasos enumerados sobre cómo agregar la asignación de roles

Selecciona Agregar asignación de roles,
- Tipo de asignación: Roles de administrador con privilegios
- Rol: Propietario o colaborador
- Miembros: elija Identidad administrada y seleccione la Identidad administrada asignada por el usuario, que se dio durante la fase de creación del clúster.
- Asigne el rol.

Creación de un clúster con escalado automático basado en programación
Una vez creado el grupo de clústeres, cree un nuevo clúster con la carga de trabajo deseada (en el tipo de clúster) y complete los demás pasos como parte del proceso de creación normal del clúster.
En la pestaña Configuración, habilite el botón escalado automático.
Seleccione Escalado automático basado en programación
Seleccione la zona horaria y haga clic en + Agregar regla
Seleccione los días de la semana en que se deberá aplicar la condición nueva.
Edite la hora en que debería aplicarse la condición y el número de nodos a los que se debe escalar el clúster.

Nota:
- El usuario debe tener el rol de “propietario” o “colaborador” en la MSI del clúster para que el escalado automático funcione.
- El valor predeterminado define el tamaño inicial del clúster cuando se crea.
- La diferencia entre dos programaciones se establece de forma predeterminada en 30 minutos.
- El valor de hora sigue el formato de 24 horas
- En el caso de una ventana continua de más de 24 horas a lo largo de los días, es necesario establecer la programación de escalado automático en días y el escalado automático supone 23:59 como 00:00 (con el mismo número de nodos) que abarca entre 22:00 y 23:59, 00:00 a 02:00 como 22:00 a 02:00.
- Las programaciones se establecen en hora universal coordinada (UTC), de forma predeterminada. Siempre puede actualizar a la zona horaria correspondiente a la zona horaria local en la lista desplegable disponible. Cuando se está en una zona horaria que observa el horario de verano, la programación no se ajusta automáticamente, se le pedirá que administre las actualizaciones de programación según corresponda.

Creación de un clúster con escalado automático basado en carga
Una vez creado el grupo de clústeres, cree un nuevo clúster con la carga de trabajo deseada (en el tipo de clúster) y complete los demás pasos como parte del proceso de creación normal del clúster.
En la pestaña Configuración, habilite el botón escalado automático.
Seleccione Escalado automático basado en carga
En función del tipo de carga de trabajo, tiene opciones para agregar tiempo de espera de retirada correcta, período de enfriamiento
Seleccione el mínimo y máximo de nodos y, si es necesario, configurar las reglas de escalado para personalizar el escalado automático según sus necesidades.

Sugerencia
- La suscripción tiene una cuota de capacidad para cada región. El número total de núcleos de los nodos principales y el máximo de nodos de trabajo no puede superar la cuota de capacidad. Sin embargo, esta cuota tiene un límite flexible; sencillamente puede crear una incidencia de soporte técnico en cualquier momento para que la aumenten.
- Si supera el límite total de cuota de núcleos, recibirá un mensaje de error que indica
The maximum node count you can select is {maxCount} due to the remaining quota in the selected subscription ({remaining} cores). - Las reglas de escalado vertical tienen prioridad cuando se desencadenan una o varias reglas. Incluso si solo una de las reglas para escalar verticalmente sugiere que el clúster está infraaprovisionado, el clúster intentará escalar verticalmente. Para que se produzca una reducción vertical, no se debe desencadenar ninguna regla de escalado vertical.
- En la versión preliminar pública, HDInsight en AKS admite hasta 500 nodos en un clúster.

Creación de un clúster con una plantilla del Administrador de recursos
Escalado automático basado en programación
Puede crear un clúster de HDInsight en AKS con escalado automático basado en programación mediante una plantilla de Azure Resource Manager agregando una escalabilidad automática a clusterProfile:> sección autoscaleProfile.
El nodo de escalado automático contiene una periodicidad que tiene una zona horaria y una programación que describe cuándo tiene lugar el cambio. Para obtener una plantilla completa de Resource Manager, vea JSON de ejemplo
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "ScheduleBased",
"gracefulDecommissionTimeout": 60,
"scheduleBasedConfig": {
"schedules": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday"
],
"startTime": "09:00",
"endTime": "10:00",
"count": 2
},
{
"days": [
"Sunday",
"Saturday"
],
"startTime": "12:00",
"endTime": "22:00",
"count": 5
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "22:00",
"endTime": "23:59",
"count": 6
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "00:00",
"endTime": "05:00",
"count": 6
}
],
"timeZone": "UTC",
"defaultCount": 110
}
}
}
Sugerencia
- Es necesario establecer programaciones no conflictivas mediante implementaciones de ARM para evitar errores de operación de escalado.
Escalado automático basado en carga
Puede crear un clúster de HDInsight en AKS con escalado automático basado en carga mediante una plantilla de Azure Resource Manager agregando una escalabilidad automática a clusterProfile:> sección autoscaleProfile.
El nodo de escalado automático contiene
- un intervalo de sondeo, un período de enfriamiento,
- retirada correcta,
- nodos mínimo y máximo,
- reglas de umbral estándar,
- escalado de métricas que describen cuándo tiene lugar el cambio.
Para obtener una plantilla completa de Resource Manager, vea JSON de ejemplo como se indica a continuación
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "LoadBased",
"gracefulDecommissionTimeout": 60,
"loadBasedConfig": {
"minNodes": 2,
"maxNodes": 157,
"pollInterval": 300,
"cooldownPeriod": 180,
"scalingRules": [
{
"actionType": "scaleup",
"comparisonRule": {
"threshold": 80,
"operator": " greaterThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
},
{
"actionType": "scaledown",
"comparisonRule": {
"threshold": 20,
"operator": " lessThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
}
]
}
}
}
Mediante la API de REST
Para habilitar o deshabilitar la escalabilidad automática en un clúster en ejecución mediante la API REST, realice una solicitud PATCH al punto de conexión de escalado automático: https://management.azure.com/subscriptions/{{USER_SUB}}/resourceGroups/{{USER_RG}}/providers/Microsoft.HDInsight/clusterpools/{{CLUSTER_POOL_NAME}}/clusters/{{CLUSTER_NAME}}?api-version={{HILO_API_VERSION}}
- Use los parámetros adecuados en la carga de solicitud. La carga json podría usarse para habilitar el escalado automático.
- Use la carga (autoscaleProfile: null) o use la marca (habilitada, false) para deshabilitar el escalado automático.
- Consulte los ejemplos JSON mencionados en el paso anterior para obtener referencia.
Pausar escalado automático para un clúster en ejecución
Hemos introducido la característica de pausa en escalado automático. Ahora, mediante Azure Portal, puede pausar el escalado automático en un clúster en ejecución. En el diagrama siguiente se muestra cómo seleccionar la pausa y reanudar la escalabilidad automática

Puede reanudar una vez que desee reanudar las operaciones de escalado automático.

Sugerencia
Cuando se configuran varias programaciones y se pausa la escalabilidad automática, no se desencadena la programación siguiente. El recuento de nodos sigue siendo el mismo, incluso si los nodos están en un estado retirado.
Copiar configuraciones de escalado automático
Con Azure Portal, ahora puede copiar las mismas configuraciones de escalado automático para una misma forma de clúster en el grupo de clústeres, puede usar esta característica y exportar o importar las mismas configuraciones.

Supervisión de actividades de escalado automático
Estado del clúster
El estado del clúster que se muestra en Azure Portal puede ayudarle a supervisar las actividades de escalado automático. Todos los mensajes de estado del clúster que puede ver se explican en la lista.
| Estado del clúster | Descripción |
|---|---|
| Correcto | El clúster funciona normalmente. Todas las actividades anteriores de escalado automático se han completado correctamente. |
| Aceptado | Se acepta la operación de clúster (por ejemplo: escalado vertical), esperando a que se complete la operación. |
| Con errores | Esto significa que se produjo un error en una operación actual debido a algún motivo, es posible que el clúster no funcione. |
| Canceled | La operación actual se cancela. |

Para ver el número actual de nodos en el clúster, vaya al gráfico Tamaño del clúster en la página de información general del clúster.

Historial de operaciones
Puede ver el historial de escalado y reducción verticales del clúster como parte de las métricas del clúster. También puede enumerar todas las acciones de escalado durante el último día, semana u otro período.

Recursos adicionales