Cambios significativos en HDInsight 4.0 y ventajas
HDInsight 4.0 tiene varias ventajas con respecto a HDInsight 3.6. Aquí le proporcionamos información general sobre las novedades de HDInsight 4.0.
| # | Componente OSS | Versión de HDInsight 4.0 | Versión de HDInsight 3.6 |
|---|---|---|---|
| 1 | Apache Hadoop | 3.1.1 | 2.7.3 |
| 2 | HBase Apache | 2.1.6 | 1.1.2 |
| 3 | Apache Hive | 3.1.0 | 1.2.1, 2.1 (LLAP) |
| 4 | Apache Kafka | 2.1.1, 2.4(GA) | 1.1 |
| 5 | Apache Phoenix | 5 | 4.7.0 |
| 6 | Spark de Apache | 2.4.4, 3.0.0 (versión preliminar) | 2.2 |
| 7 | Apache TEZ | 0.9.1 | 0.7.0 |
| 8 | Apache ZooKeeper | 3.4.6 | 3.4.6 |
| 9 | Apache Kafka | 2.1.1, 2.4.1 (versión preliminar) | 1.1 |
| 10 | Apache Ranger | 1.1.0 | 0.7.0 |
Cargas de trabajo y características
Hive
- Características avanzadas
- Administración de cargas de trabajo de LLAP
- LLAP admite conectores JDBC, Druid y Kafka
- Características mejoradas de SQL: restricciones y valores predeterminados
- Claves suplentes
- Esquema de información.
- Ventaja de rendimiento
- Almacenamiento en caché de resultados: el almacenamiento en caché de los resultados de la consulta permite reutilizar un resultado de consulta previamente calculado
- Vistas materializadas dinámicas: Precomputación de resúmenes
- Mejoras de rendimiento de ACID V2 tanto en el formato de almacenamiento como en el motor de ejecución
- Seguridad
- Cumplimiento normativo del RGPD habilitado en transacciones de Apache Hive
- Autorización de ejecución de UDF de Hive en ranger
HBase
- Características avanzadas
- Procedimiento 2. El procedimiento V2 o procv2 es un marco actualizado para ejecutar operaciones administrativas de HBase de varios pasos.
- Ruta de acceso de lectura y escritura totalmente fuera del montón.
- Compactaciones en memoria
- El clúster de HBase admite ADLS Gen2 Premium
- Ventaja de rendimiento
- Escrituras aceleradas usa discos administrados SSD premium de Azure para mejorar el rendimiento del registro de escritura previa (WAL) de Apache HBase.
- Seguridad
- Protección de ambos índices secundarios, que incluyen Local y Global
Kafka
- Características avanzadas
- Distribución de particiones de Kafka en dominios de error de Azure
- Compatibilidad de compresión Zstd
- Reequilibrio incremental del consumidor de Kafka
- Compatibilidad con MirrorMaker 2.0
- Ventaja de rendimiento
- Rendimiento mejorado de agregaciones en ventanas en flujos de Kafka
- Mejora de la resiliencia de los intermediarios al reducir el consumo de memoria de la conversión de mensajes
- Mejoras del protocolo de replicación para la conmutación por error líder rápida
- Seguridad
- Control de acceso para la creación de temas específicos o prefijo de tema
- Comprobación del nombre de host para evitar ataques de tipo man-in-the-middle de configuración ssl
- Soporte de cifrado mejorado con una implementación más rápida de Transport Layer Security (TLS) y CRC32C
Spark
- Características avanzadas
- Soporte de transmisión estructurada para ORC
- Capacidad de integración con la nueva característica del catálogo de Metastore
- Soporte de transmisión estructurada para la biblioteca de Hive Streaming
- Escritura transparente en el almacén de Hive
- Spark Cruise: un sistema de reutilización automática de cálculos para Spark.
- Ventaja de rendimiento
- Almacenamiento en caché de resultados: el almacenamiento en caché de los resultados de la consulta permite reutilizar un resultado de consulta previamente calculado
- Vistas materializadas dinámicas: Precomputación de resúmenes
- Seguridad
- Cumplimiento normativo del RGPD habilitado para transacciones de Spark
Detección y reparación de particiones de Hive
Hive detecta y sincroniza automáticamente los metadatos de la partición en Metastore de Hive.
La discover.partitions propiedad de tabla habilita y deshabilita la sincronización del sistema de archivos con particiones. En las tablas externas con particiones, esta propiedad está habilitada (true) de forma predeterminada.
Cuando el servicio metastore de Hive (HMS) se inicia en modo de servicio remoto, un subproceso en segundo plano(PartitionManagementTask) se programa periódicamente cada 300 s (configurable a través de metastore.partition.management.task.frequency config), el cual busca tablas con discover.partitions la propiedad de tabla establecida en true y realiza msck la reparación en modo de sincronización.
Si la tabla es una tabla transaccional, se obtiene el bloqueo exclusivo para esa tabla antes de realizar msck repair. Con esta propiedad de tabla, MSCK REPAIR TABLE table_name SYNC PARTITIONS ya no es necesaria la ejecución manual.
Suponiendo que tenga una tabla externa creada con una versión de Hive que no admite la detección de particiones, habilite la detección de particiones para la tabla.
ALTER TABLE exttbl SET TBLPROPERTIES ('discover.partitions' = 'true');
Configure la sincronización de particiones para que ocurra cada 10 minutos expresados en segundos: en Ambari > Hive > Configs,set metastore.partition.management.task.frequency a 3600 o más.
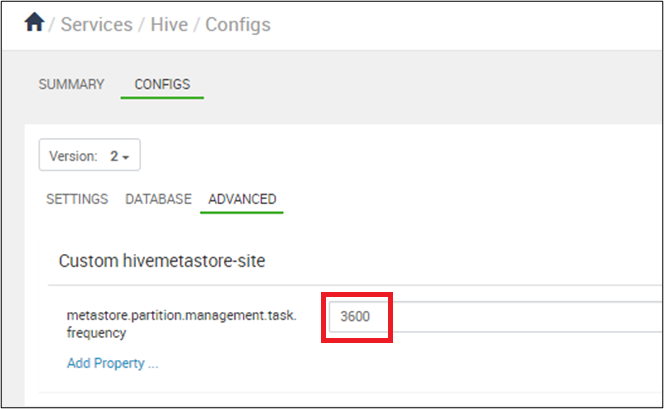
Advertencia
Con la management.task ejecución cada 10 minutos, habrá presión sobre la DTU del servidor SQL.
Puede verificar el resultado desde el Microsoft Azure Portal.
Hive suprime los metadatos y los datos correspondientes en cualquier partición creada después del período de retención. El tiempo de retención se expresa mediante un número y el siguiente carácter o caracteres. Hive suprime los metadatos y los datos correspondientes en cualquier partición creada después del período de retención. El tiempo de retención se expresa mediante un número y los siguientes caracteres.
ms (milliseconds)
s (seconds)
m (minutes)
d (days)
Para configurar un período de retención de partición durante una semana.
ALTER TABLE employees SET TBLPROPERTIES ('partition.retention.period'='7d');
Los metadatos de partición y los datos reales de los empleados de Hive se suprimen automáticamente después de una semana.
Hive 3
Optimizaciones de rendimiento disponibles en Hive 3
Vectorización OLAP Reducción Dinámica Semijoin Soporte de Parquet para vectorización con LLAP Caché de consultas automáticas.
Nuevas características de SQL
Vistas Materializadas Claves Suplentes Restricciones CachedStore.
Vectorización OLAP
La vectorización permite a Hive procesar un lote completo de filas en lugar de procesarlas una a una. Cada lote suele ser una matriz de tipos primitivos. Las operaciones se realizan en todo el vector de columna, lo que mejora las canalizaciones de instrucciones y el uso de la memoria caché. Ejecución vectorizada de PTF, acumulación y agrupación de conjuntos.
Reducción Semijoin dinámica
Mejora considerablemente el rendimiento de las combinaciones selectivas. Crea un filtro de Bloom desde un lado de la combinación y filtra las filas desde el otro lado. Omite el examen y la evaluación adicional de las filas que no calificarían la combinación.
Compatibilidad con Parquet para vectorización con LLAP
La ejecución de consultas vectoriales es una característica que reduce considerablemente el uso de la CPU para las operaciones de consulta típicas, como
- Escaneos
- filters
- aggregate
- combinaciones
La vectorización también se implementa para el formato ORC. Spark también usa Whole Stage Codegen y esta vectorización (para Parquet) desde Spark 2.0. Se ha agregado la columna timestamp para la vectorización y el formato parquet en LLAP.
Advertencia
Las escrituras de Parquet son lentas cuando la conversión a tiempos con zona desde la marca de tiempo. Para más información, consulte aquí.
Caché automática de consultas
- Con
hive.query.results.cache.enabled=true, cada consulta que se ejecuta en Hive 3 almacena su resultado en una memoria caché. - Si cambia la tabla de entrada, Hive expulsa datos no válidos de la memoria caché. Por ejemplo, si realiza la agregación y cambia la tabla base, las consultas que se ejecutan con más frecuencia permanecen en la memoria caché, pero se expulsan las consultas obsoletas.
- La caché de resultados de la consulta solo funciona con tablas administradas porque Hive no puede realizar un seguimiento de los cambios en una tabla externa.
- Si combina tablas externas y administradas, Hive vuelve a ejecutar la consulta completa. La caché de resultados de la consulta funciona con tablas ACID. Si actualiza una tabla ACID, Hive vuelve a ejecutar la consulta automáticamente.
- Puede habilitar y deshabilitar la caché de resultados de la consulta desde la línea de comandos. Es posible que quiera hacerlo para depurar una consulta.
- Deshabilite la caché de resultados de la consulta estableciendo el parámetro siguiente en false:
hive.query.results.cache.enabled=false - Hive almacena la caché de resultados de la consulta en
/tmp/hive/__resultcache__/. De forma predeterminada, Hive asigna 2 GB para la caché de resultados de la consulta. Puede cambiar esta configuración configurando el siguiente parámetro en bytes:hive.query.results.cache.max.size - Cambios en el procesamiento de consultas: durante la compilación de consultas, compruebe la memoria caché de resultados para ver si ya tiene los resultados de la consulta. Si hay un acierto de caché, el plan de consulta se establece en un
FetchTaskque lee de la ubicación almacenada en caché.
Error durante la ejecución de consultas:
Parquet DataWriteableWriter se basa en NanoTimeUtils para convertir un objeto marca de tiempo en un valor binario. Esta consulta llama a toString() en el objeto marca de tiempo y, a continuación, analiza la cadena.
- Si la memoria caché de resultados se puede usar para esta consulta
- La consulta se
FetchTasklee desde el directorio de resultados almacenados en caché. - No se requieren tareas de clúster.
- La consulta se
- Si no se puede usar la caché de resultados, ejecute las tareas del clúster como normales
- Compruebe si los resultados de la consulta que se han calculado son aptos para agregarlos a la caché de resultados.
- Si los resultados se pueden almacenar en caché, los resultados temporales generados para la consulta se guardan en la caché de resultados. Es posible que tenga que realizar pasos aquí para asegurarse de que la limpieza de la consulta no elimina el directorio de resultados de la consulta.
Características de SQL
Vistas materializadas
La implementación inicial introducida en Apache Hive 3.0.0 se centra en la introducción de vistas materializadas y la reescritura automática de consultas en función de esas materializaciones en el proyecto. Las vistas materializadas se pueden almacenar de forma nativa en Hive o en otros controladores de almacenamiento personalizados (ORC) y pueden aprovechar sin problemas nuevas características de Hive interesantes, como la aceleración de LLAP.
Para obtener más información, consulte Hive - Vistas materializadas : Microsoft Tech Community
Claves suplentes
Use la SURROGATE_KEY función integrada definida por el usuario (UDF) para generar automáticamente identificadores numéricos para las filas a medida que escribe datos en una tabla. Las claves suplentes generadas pueden reemplazar claves compuestas anchas y múltiples.
Hive solo admite las claves suplentes en las tablas ACID. La tabla que desea combinar mediante claves suplentes no puede tener tipos de columna que necesiten la conversión. Estos tipos de datos deben ser primitivos, como INT o STRING.
Las combinaciones que usan las claves generadas son más rápidas que las combinaciones mediante cadenas. El uso de claves generadas no fuerza los datos en un solo nodo por un número de fila. Puede generar claves como abstracciones de claves naturales. Las claves suplentes tienen una ventaja sobre los UUID, que son más lentos y probabilísticos.
SURROGATE_KEY UDF genera un id. único para cada fila que inserte en una tabla.
Genera claves basadas en el entorno de ejecución en un sistema distribuido, que incluye muchos factores, como
- Estructuras de datos internas
- Estado de una tabla
- Último identificador de transacción.
La generación de claves suplentes no requiere ninguna coordinación entre las tareas de proceso. La UDF no toma ningún argumento, o dos argumentos son
- Bits de identificador de escritura
- Bits de identificador de tarea
Restricciones
Restricciones SQL para aplicar la integridad de los datos y mejorar el rendimiento. El optimizador usa la información de restricción para tomar decisiones inteligentes. Las restricciones pueden hacer que los datos sean predecibles y fáciles de localizar.
| Restricciones | Descripción |
|---|---|
| Comprobar | Limita el intervalo de valores que puede colocar en una columna. |
| PRIMARY KEY | Identifica cada fila de una tabla mediante un identificador único. |
| FOREIGN KEY | Identifica una fila de otra tabla mediante un identificador único. |
| CLAVE ÚNICA | Comprueba que los valores almacenados en una columna son diferentes. |
| NOT NULL | Garantiza que una columna no se puede establecer en NULL. |
| ENABLE | Garantiza que todos los datos entrantes se ajustan a la restricción. |
| DISABLE | No garantiza que todos los datos entrantes se ajusten a la restricción. |
| VALIDATEC | enumera que todos los datos existentes de la tabla se ajustan a la restricción. |
| NOVALIDATE | No comprueba que todos los datos existentes de la tabla se ajusten a la restricción |
| APLICADO | Se asigna a ENABLE NOVALIDATE. |
| NO APLICADO | Se asigna a DISABLE NOVALIDATE. |
| RELY | Especifica que se cumple una restricción; usado por el optimizador para aplicar más optimizaciones. |
| NORELY | Especifica que no cumple una restricción. |
Para obtener más información, vea https://cwiki.apache.org/confluence/display/Hive/Supported+Features%3A++Apache+Hive+3.1.
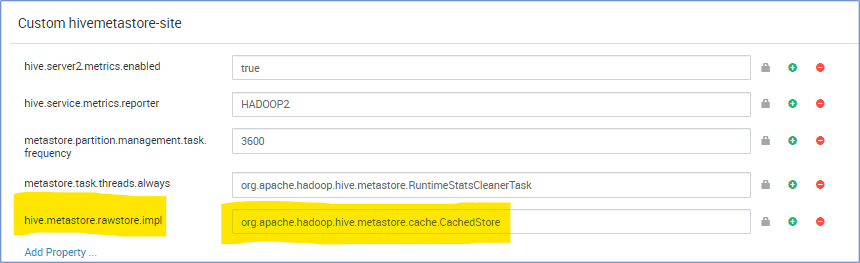
Metastore CachedStore
La operación de metastore de Hive tarda mucho tiempo y, por tanto, ralentiza la compilación de Hive. En algún caso extremo, tarda más tiempo que el tiempo de ejecución de la consulta real. Especialmente, encontramos que la latencia de la base de datos en la nube es alta y el 90 % del tiempo de ejecución de consultas total está esperando operaciones de base de datos SQL de metastore. En función de esta observación, se mejora el rendimiento de la operación de metastore, si tenemos una estructura de memoria que almacena en caché el resultado de la consulta de la base de datos.
hive.metastore.rawstore.impl=org.apache.hadoop.hive.metastore.cache.CachedStore
Guía de solución de problemas
La guía de solución de problemas de HDInsight 3.6 a 4.0 para cargas de trabajo de Hive proporciona respuestas a problemas comunes que surgen al migrar cargas de trabajo de Hive de HDInsight 3.6 a HDInsight 4.0.
Referencias
Hive 3.1.0
HBase 2.1.6
https://apache.googlesource.com/hbase/+/ba26a3e1fd5bda8a84f99111d9471f62bb29ed1d/RELEASENOTES.md
Hadoop 3.1.1
Información adicional
Comentaris
Properament: al llarg del 2024 eliminarem gradualment GitHub Issues com a mecanisme de retroalimentació del contingut i el substituirem per un nou sistema de retroalimentació. Per obtenir més informació, consulteu: https://aka.ms/ContentUserFeedback.
Envieu i consulteu els comentaris de