Seguimiento de experimentos de aprendizaje automático de Azure Databricks con MLflow y Azure Machine Learning
MLflow es una biblioteca de código abierto para administrar el ciclo de vida de los experimentos de aprendizaje automático. Puede usar MLflow para integrar Azure Databricks con Azure Machine Learning para asegurarse de obtener lo mejor de ambos productos.
En este artículo, aprenderá lo siguiente:
- Las bibliotecas necesarias para usar MLflow con Azure Databricks y Azure Machine Learning.
- Cómo realizar un seguimiento de las ejecuciones de Azure Databricks con MLflow en Azure Machine Learning.
- Cómo registrar modelos con MLflow para registrarlos en Azure Machine Learning.
- Cómo implementar y consumir modelos registrados en Azure Machine Learning.
Requisitos previos
- Instale el paquete
azureml-mlflow, que controla la conectividad con Azure Machine Learning, incluida la autenticación. - Un área de trabajo y un clúster de Azure Databricks.
- Cree un área de trabajo de Azure Machine Learning.
Cuadernos de ejemplo
En Entrenamiento de modelos en Azure Databricks y su implementación en Azure Machine Learning se muestra cómo entrenar modelos en Azure Databricks e implementarlos en Azure Machine Learning. También se explica cómo controlar los casos en los que además se quiere realizar el seguimiento de los experimentos y modelos con la instancia de MLflow en Azure Databricks y aprovechar Azure Machine Learning para la implementación.
Instalar bibliotecas
Para instalar las bibliotecas en el clúster, vaya a la pestaña Libraries (Bibliotecas) y seleccione Install New (Instalar nuevo).
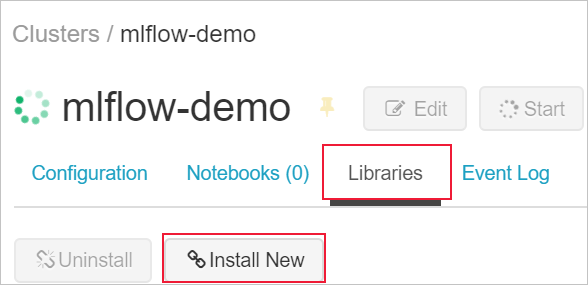
En el campo Package (Paquete), escriba azureml-mlflow y, luego, seleccione Install (Instalar). Repita este paso según sea necesario para instalar otros paquetes adicionales en el clúster para el experimento.
Seguimiento de las ejecuciones de Azure Databricks con MLflow
Azure Databricks se puede configurar para realizar un seguimiento de los experimentos mediante MLflow de dos maneras:
- Seguimiento tanto en el área de trabajo de Azure Databricks como en el área de trabajo de Azure Machine Learning (seguimiento dual)
- Seguimiento exclusivo en Azure Machine Learning
De manera predeterminada, el seguimiento dual se configura automáticamente al vincular el área de trabajo de Azure Databricks.
Seguimiento dual en Azure Databricks y Azure Machine Learning
La vinculación del área de trabajo de ADB con el área de trabajo de Azure Machine Learning le permite realizar un seguimiento de los datos del experimento en el área de trabajo de Azure Machine Learning y el área de trabajo de Azure Databricks al mismo tiempo. Esto se conoce como seguimiento dual.
Advertencia
Por el momento, no se admite el seguimiento dual en una área de trabajo de Azure Machine Learning habilitada para el vínculo privado. Configure el seguimiento exclusivo con el área de trabajo de Azure Machine Learning en su lugar.
Advertencia
Por el momento, Microsoft Azure operado por 21Vianet no admite el seguimiento dual. Configure el seguimiento exclusivo con el área de trabajo de Azure Machine Learning en su lugar.
Para vincular el área de trabajo de ADB con un área de trabajo de Azure Machine Learning nueva o existente:
- Inicie sesión en el portal de Azure.
- Vaya a la página Información general del área de trabajo de ADB.
- Seleccione el botón Link Azure Machine Learning workspace (Vincular el área de trabajo de Azure Machine Learning) en la parte inferior derecha.

Después de vincular el área de trabajo de Azure Databricks con el área de trabajo de Azure Machine Learning, se establece automáticamente el seguimiento de MLflow Tracking en los siguientes lugares:
- El área de trabajo vinculada de Azure Machine Learning.
- El área de trabajo ADB original.
Después, puede usar MLflow en Azure Databricks de la misma manera que acostumbra a usarlo. En el ejemplo siguiente, se establece el nombre del experimento como se hace habitualmente en Azure Databricks y se empiezan a registrar algunos parámetros:
import mlflow
experimentName = "/Users/{user_name}/{experiment_folder}/{experiment_name}"
mlflow.set_experiment(experimentName)
with mlflow.start_run():
mlflow.log_param('epochs', 20)
pass
Nota
Al contrario que el seguimiento, no se admite el registro de modelos al mismo tiempo en Azure Machine Learning y Azure Databricks. Debe usarse uno u otro. Lea la sección Registro de modelos en el registro con MLflow para obtener más información.
Seguimiento exclusivo en el área de trabajo de Azure Machine Learning
Si prefiere administrar los experimentos con seguimiento en una ubicación centralizada, puede establecer el seguimiento de MLflow para que solo realice el seguimiento en el área de trabajo de Azure Machine Learning. Esta configuración tiene la ventaja de habilitar una forma más sencilla para la implementación con las opciones de implementación de Azure Machine Learning.
Advertencia
En el caso del área de trabajo de Azure Machine Learning habilitada para Private Link, debe implementar Azure Databricks en su propia red (inyección de red virtual) a fin de garantizar la conectividad adecuada.
Debe configurar el URI de seguimiento de MLflow para que apunte exclusivamente a Azure Machine Learning, como se muestra en el ejemplo siguiente:
Configurar URI de seguimiento
Obtenga el URI de seguimiento del área de trabajo:
SE APLICA A:
 Extensión de ML de la CLI de Azure v2 (actual)
Extensión de ML de la CLI de Azure v2 (actual)Inicie sesión y configure el área de trabajo:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Puede obtener el URI de seguimiento mediante el comando
az ml workspace:az ml workspace show --query mlflow_tracking_uri
Configuración del URI de seguimiento:
A continuación, el método
set_tracking_uri()apunta el URI de seguimiento de MLflow a ese URI.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)Sugerencia
Al trabajar en entornos compartidos, como un clúster de Azure Databricks, un clúster de Azure Synapse Analytics o similar, resulta útil establecer la variable
MLFLOW_TRACKING_URIde entorno en el nivel de clúster para configurar automáticamente el URI de seguimiento de MLflow para que apunte a Azure Machine Learning para todas las sesiones que se ejecutan en el clúster en lugar de hacerlo por sesión.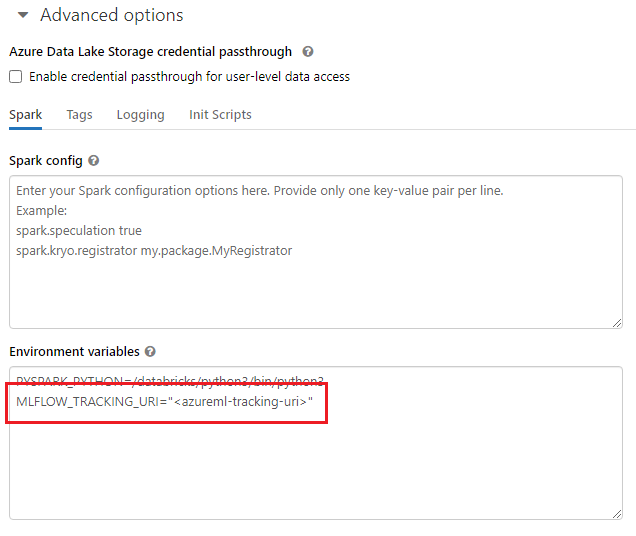
Una vez configurada la variable de entorno, se realizará un seguimiento de cualquier experimento que se ejecute en dicho clúster en Azure Machine Learning.
Configurar la autenticación
Una vez configurado el seguimiento, también deberá configurar cómo se debe realizar la autenticación en el área de trabajo asociada. De forma predeterminada, el complemento de Azure Machine Learning para MLflow realizará la autenticación interactiva abriendo el explorador predeterminado para solicitar las credenciales. Consulte Configuración de MLflow para Azure Machine Learning: Configuración de la autenticación para otras formas de configurar la autenticación para MLflow en áreas de trabajo de Azure Machine Learning.
En el caso de los trabajos interactivos en los que hay un usuario conectado a la sesión, puede confiar en la autenticación interactiva y, por tanto, no es necesario realizar ninguna otra acción.
Advertencia
La autenticación interactiva del explorador bloqueará la ejecución del código al solicitar las credenciales. No es una opción adecuada para la autenticación en entornos desatendidos, como trabajos de entrenamiento. Se recomienda configurar otro modo de autenticación.
En aquellos escenarios en los que se requiere la ejecución desatendida, tendrá que configurar una entidad de servicio para comunicarse con Azure Machine Learning.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Sugerencia
Al trabajar en entornos compartidos, es aconsejable configurar estas variables de entorno en el proceso. Como procedimiento recomendado, puede administrarlos como secretos en una instancia de Azure Key Vault siempre que sea posible. Por ejemplo, en Azure Databricks puede usar secretos en variables de entorno como se indica a continuación en la configuración del clúster: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}. Consulte Referencia a un secreto en una variable de entorno para obtener información sobre cómo hacerlo en Azure Databricks o consulte documentación similar en la plataforma.
Nombres de experimento en Azure Machine Learning
Cuando MLflow está configurado para hacer un seguimiento de experimentos exclusivamente en el área de trabajo de Azure Machine Learning, la convención de nomenclatura de los experimentos debe seguir la que utiliza Azure Machine Learning. En Azure Databricks, los experimentos se denominan con la ruta de acceso de donde se guarda el experimento, como /Users/alice@contoso.com/iris-classifier. Sin embargo, en Azure Machine Learning, debe proporcionar el nombre del experimento directamente. Como en el ejemplo anterior, el mismo experimento tomaría directamente el nombre iris-classifier:
mlflow.set_experiment(experiment_name="experiment-name")
Seguimiento de parámetros, métricas y artefactos
Después, puede usar MLflow en Azure Databricks de la misma manera que acostumbra a usarlo. Para obtener más información, consulte Registro y visualización de métricas y archivos de registro.
Registro de modelos en MLflow
Una vez que un modelo está entrenado, puede registrarlo en el servidor de seguimiento con el método mlflow.<model_flavor>.log_model(). <model_flavor> hace referencia al marco asociado al modelo. Conozca qué tipos de modelos se admiten. En el ejemplo siguiente, se está registrando un modelo creado con la biblioteca MLLib de Spark:
mlflow.spark.log_model(model, artifact_path = "model")
Merece la pena mencionar que el tipo spark no corresponde al hecho de que estemos entrenando un modelo en un clúster de Spark, sino al marco de entrenamiento que se ha utilizado (puede entrenar perfectamente un modelo mediante TensorFlow con Spark y, por tanto, el tipo que se debería usar sería tensorflow).
Los modelos se registran dentro de la ejecución de la que se hace el seguimiento. Esto significa que los modelos están disponibles en Azure Databricks y Azure Machine Learning (valor predeterminado) o exclusivamente en Azure Machine Learning si se ha configurado el URI de seguimiento para que apunte a él.
Importante
Observe que aquí no se ha especificado el parámetro registered_model_name. Lea la sección Registro de modelos en el registro con MLflow para obtener más información sobre las implicaciones de este parámetro y cómo funciona el Registro.
Registro de modelos en el registro con MLflow
Al contrario que el seguimiento, los registros de modelos no pueden funcionar al mismo tiempo en Azure Databricks y Azure Machine Learning. Debe usarse uno u otro. De forma predeterminada, se usa el área de trabajo de Azure Databricks para los registros de modelos, a menos que decida establecer MLflow Tracking para que solo realice el seguimiento en el área de trabajo de Azure Machine Learning, en cuyo caso, el registro de modelos será esa área de trabajo.
A continuación, teniendo en cuenta que usa la configuración predeterminada, la siguiente línea registrará un modelo durante las ejecuciones correspondientes de Azure Databricks y Azure Machine Learning, pero solo lo registrará en Azure Databricks:
mlflow.spark.log_model(model, artifact_path = "model",
registered_model_name = 'model_name')
Si no existe un modelo registrado con el nombre, el método registra un modelo nuevo, crea la versión 1 y devuelve un objeto MLflow ModelVersion.
Si ya existe un modelo registrado con el nombre, el método crea una versión del modelo y devuelve el objeto de versión.
Uso del Registro de Azure Machine Learning con MLflow
Si quiere usar el Registro de modelos de Azure Machine Learning en lugar de Azure Databricks, se recomienda configurar MLflow Tracking para que realice solamente un seguimiento en el área de trabajo de Azure Machine Learning. Esto evitará la ambigüedad sobre dónde se registran los modelos y simplifica la complejidad.
Pero si quiere seguir usando las funciones de seguimiento dual, pero registrar los modelos en Azure Machine Learning, puede indicar a MLflow que use de Azure Machine Learning para los registros de modelos mediante la configuración del URI de registro de modelos de MLflow. Este URI tiene exactamente el mismo formato y el mismo valor que el URI de seguimiento de MLflow.
mlflow.set_registry_uri(azureml_mlflow_uri)
Nota
El valor de azureml_mlflow_uri se obtuvo de la misma manera que se ha explicado en Establecimiento del seguimiento de MLflow para que solo realice el seguimiento en el área de trabajo de Azure Machine Learning
Para obtener un ejemplo completo sobre este escenario, vea el ejemplo Entrenamiento de modelos en Azure Databricks y su implementación en de Azure Machine Learning.
Implementación y consumo de modelos registrados en Azure Machine Learning
Los modelos registrados en el servicio de Azure Machine Learning con MLflow se pueden consumir como:
Un punto de conexión de Azure Machine Learning (en tiempo real y por lotes): esta implementación permite aprovechar la funcionalidad de implementación de Azure Machine Learning para la inferencia en tiempo real y por lotes en Azure Container Instances (ACI), Azure Kubernetes (AKS) o en nuestros puntos de conexión de Managed Inference.
Objetos de modelo de MLFlow o UDF de Pandas, que se pueden usar en cuadernos de Azure Databricks en canalizaciones de streaming o por lotes.
Implementación de modelos en puntos de conexión de Azure Machine Learning
Puede aprovechar el complemento azureml-mlflow para implementar un modelo en el área de trabajo de Azure Machine Learning. Consulte la página Implementación de modelos de MLflow para obtener información completa sobre cómo implementar modelos en los distintos destinos.
Importante
Los modelos deben registrarse en el registro de Azure Machine Learning para poder implementarlos. Si resulta que los modelos están registrados en la instancia de MLflow dentro de Azure Databricks, tendrá que registrarlos de nuevo en Azure Machine Learning. Si es así, vea el ejemplo Entrenamiento de modelos en Azure Databricks y su implementación en de Azure Machine Learning
Implementación de modelos en ADB para la puntuación por lotes con UDF
Puede elegir clústeres de Azure Databricks para la puntuación por lotes. Al aprovechar MLflow, puede resolver cualquier modelo del registro al que está conectado. Normalmente utilizará uno de los dos siguientes métodos:
- Si el modelo se entrenó y creó con bibliotecas de Spark (como
MLLib), usemlflow.pyfunc.spark_udfpara cargar un modelo y usarlo como UDF de Pandas de Spark para puntuar nuevos datos. - Si el modelo no se ha entrenado o compilado con bibliotecas de Spark, use
mlflow.pyfunc.load_modelomlflow.<flavor>.load_modelpara cargar el modelo en el controlador del clúster. Tenga en cuenta que, de esta manera, cualquier distribución de trabajo o paralelización que quiera que se produzca en el clúster debe organizarla usted. Además, tenga en cuenta que MLflow no instala ninguna biblioteca que el modelo requiera para ejecutarse. Esas bibliotecas deben instalarse en el clúster antes de ejecutarlo.
En el ejemplo siguiente se muestra cómo cargar un modelo desde el registro denominado uci-heart-classifier y usarlo como UDF de Pandas de Spark para puntuar nuevos datos.
from pyspark.sql.types import ArrayType, FloatType
model_name = "uci-heart-classifier"
model_uri = "models:/"+model_name+"/latest"
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
Sugerencia
Consulte Carga de modelos desde el Registro para obtener más formas de hacer referencia a modelos desde el Registro.
Una vez cargado el modelo, puede usarlo para puntuar nuevos datos:
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Limpieza de recursos
Si quiere conservar el área de trabajo de Azure Databricks, pero ya no necesita el área de trabajo de Azure Machine Learning, puede eliminar esta última. Esta acción desvinculará el área de trabajo de Azure Databricks y el área de trabajo de Azure Machine Learning.
Si no tiene pensado usar los artefactos o las métricas registradas en el área de trabajo, la funcionalidad para eliminarlos de forma individual no está disponible en este momento. Por ello, deberá eliminar el grupo de recursos que contiene la cuenta de almacenamiento y el área de trabajo para no incurrir en cargos:
En Azure Portal, seleccione Grupos de recursos a la izquierda del todo.
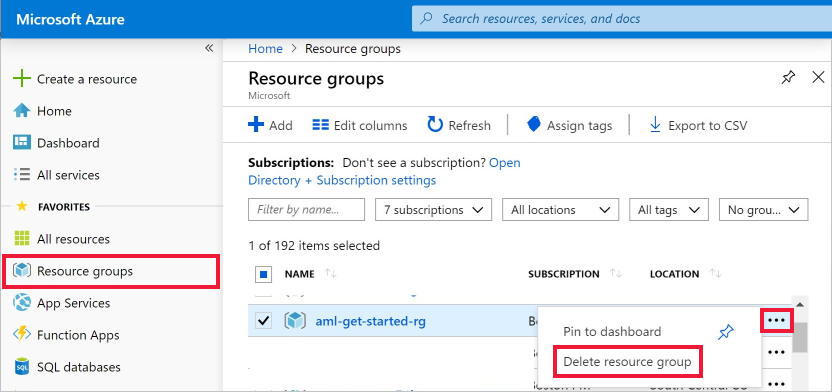
En la lista, seleccione el grupo de recursos que creó.
Seleccione Eliminar grupo de recursos.
Escriba el nombre del grupo de recursos. A continuación, seleccione Eliminar.
Pasos siguientes
Comentaris
Properament: al llarg del 2024 eliminarem gradualment GitHub Issues com a mecanisme de retroalimentació del contingut i el substituirem per un nou sistema de retroalimentació. Per obtenir més informació, consulteu: https://aka.ms/ContentUserFeedback.
Envieu i consulteu els comentaris de