Cómo usar Apache Spark (con tecnología de Azure Synapse Analytics) en la canalización de aprendizaje automático (en desuso)
SE APLICA A: Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
Advertencia
La integración de Azure Synapse Analytics con Azure Machine Learning, disponible en el SDK de Python v1, está en desuso. Los usuarios todavía pueden usar el área de trabajo de Synapse, registrada con Azure Machine Learning como servicio vinculado. Sin embargo, ya no se puede registrar una nueva área de trabajo de Synapse con Azure Machine Learning como servicio vinculado. Se recomienda usar el proceso de Spark sin servidor y los grupos de Synapse Spark conectados, disponibles en la CLI v2 y el SDK de Python v2. Para más información, visite https://aka.ms/aml-spark.
En este artículo, aprenderá a usar grupos de Apache Spark, con tecnología de Azure Synapse Analytics como destino de proceso en un paso de preparación de datos en una canalización de Azure Machine Learning. Aprenderá cómo una sola canalización puede usar recursos de proceso adecuados para el paso concreto, por ejemplo, la preparación de datos o el entrenamiento. También aprenderá a preparar los datos para el paso de Spark y cómo pasa al siguiente paso.
Requisitos previos
Cree un área de trabajo de Azure Machine Learning que contenga todos los recursos de canalización.
Configure su entorno de desarrollo para instalar el SDK de Azure Machine Learning o use una instancia de proceso de Azure Machine Learning con el SDK ya instalado.
Creación de un área de trabajo de Azure Synapse Analytics y de un grupo de Apache Spark. Para obtener más información, visite Inicio rápido: Creación de un grupo de Apache Spark sin servidor mediante Synapse Studio
Vinculación del área de trabajo de Azure Machine Learning y el área de trabajo de Azure Synapse Analytics
Los grupos de Apache Spark se crean y administran en las áreas de trabajo de Azure Synapse Analytics. Para integrar un grupo de Apache Spark en un área de trabajo de Azure Machine Learning, debe crear un vínculo al área de trabajo de Azure Synapse Analytics. Una vez que vincule el área de trabajo de Azure Machine Learning y las áreas de trabajo de Azure Synapse Analytics, puede asociar un grupo de Apache Spark con
SDK de Python, como se explica más adelante
Plantilla de Azure Resource Manager (ARM). Para obtener más información, visite Ejemplo de plantilla de ARM
- Puede usar la línea de comandos para seguir la plantilla de ARM, agregar el servicio vinculado y conectar el grupo de Apache Spark con este ejemplo de código:
az deployment group create --name --resource-group <rg_name> --template-file "azuredeploy.json" --parameters @"azuredeploy.parameters.json"
Importante
Para vincular correctamente el área de trabajo de Synapse, debe tener el rol Propietario en ella. Compruebe el acceso en Azure Portal.
El servicio vinculado recibirá una identidad asignada por el sistema (SAI) en el momento de la creación. A esta SAI del servicio vinculado se le debe asignar el rol "Administrador de Apache Spark de Synapse" desde Synapse Studio, para que pueda enviar el trabajo de Spark (consulte Administración de asignaciones de roles de RBAC de Synapse en Synapse Studio).
También debe proporcionar al usuario del área de trabajo de Azure Machine Learning el rol "colaborador" desde el portal de administración de recursos de Azure.
Recuperación del vínculo entre el área de trabajo de Azure Synapse Analytics y el área de trabajo de Azure Machine Learning
Este código muestra cómo recuperar servicios vinculados en el área de trabajo:
from azureml.core import Workspace, LinkedService, SynapseWorkspaceLinkedServiceConfiguration
ws = Workspace.from_config()
for service in LinkedService.list(ws) :
print(f"Service: {service}")
# Retrieve a known linked service
linked_service = LinkedService.get(ws, 'synapselink1')
En primer lugar, Workspace.from_config() accede al área de trabajo de Azure Machine Learning mediante la configuración del archivo config.json. (Para obtener más información, visite Crear un archivo de configuración del área de trabajo). A continuación, el código imprime todos los servicios vinculados disponibles en el área de trabajo. Finalmente, LinkedService.get() recupera un servicio vinculado denominado 'synapselink1'.
Conexión del grupo de Apache Spark como destino de proceso de Azure Machine Learning
Para usar el grupo de Apache Spark para realizar un paso de la canalización de aprendizaje automático, debe conectarlo como objeto ComputeTarget en el paso de canalización, tal y como se muestra en este ejemplo de código:
from azureml.core.compute import SynapseCompute, ComputeTarget
attach_config = SynapseCompute.attach_configuration(
linked_service = linked_service,
type="SynapseSpark",
pool_name="spark01") # This name comes from your Synapse workspace
synapse_compute=ComputeTarget.attach(
workspace=ws,
name='link1-spark01',
attach_configuration=attach_config)
synapse_compute.wait_for_completion()
El código primero configura el SynapseCompute. El argumento linked_service es el objeto LinkedService que creó o recuperó en el paso anterior. El argumento type debe ser SynapseSpark. El argumento pool_name de SynapseCompute.attach_configuration() debe coincidir con el de un grupo existente en el área de trabajo de Azure Synapse Analytics. Para más información sobre la creación de un grupo de Apache Spark en el área de trabajo de Azure Synapse Analytics, visite Inicio rápido: creación de un grupo de Apache Spark sin servidor mediante Synapse Studio. El tipo attach_config es ComputeTargetAttachConfiguration.
Después de crear la configuración, cree un ComputeTarget de aprendizaje automático pasando el Workspace, los valores de ComputeTargetAttachConfiguration y el nombre por el que desea hacer referencia al proceso dentro del área de trabajo de Machine Learning. La llamada a ComputeTarget.attach() es asincrónica, por lo que el ejemplo se bloquea hasta que se completa la llamada.
Creación de un elemento SynapseSparkStep que usa el grupo de Apache Spark vinculado
El trabajo de Spark del grupo de Apache Spark del cuaderno de ejemplo define una canalización de aprendizaje automático simple. En primer lugar, el cuaderno define un paso de preparación de datos, con tecnología del synapse_compute definido en el paso anterior. A continuación, el cuaderno define un paso de entrenamiento con tecnología de un destino de proceso más adecuado para el entrenamiento. El cuaderno de ejemplo usa la base de datos de supervivencia del Titanic para mostrar la entrada y salida de los datos. Realmente no limpia los datos ni crea un modelo predictivo. Dado que este ejemplo no implica realmente el entrenamiento, el paso de entrenamiento usa un recurso de proceso económico basado en CPU.
Los datos fluyen a una canalización de aprendizaje automático a través de objetos DatasetConsumptionConfig, que pueden contener conjuntos de archivos o datos tabulares. Los datos a menudo proceden de archivos de Blob Storage en un almacén de datos del área de trabajo. Este ejemplo de código muestra el código típico que crea la entrada para una canalización de aprendizaje automático:
from azureml.core import Dataset
datastore = ws.get_default_datastore()
file_name = 'Titanic.csv'
titanic_tabular_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, file_name)])
step1_input1 = titanic_tabular_dataset.as_named_input("tabular_input")
# Example only: it wouldn't make sense to duplicate input data, especially one as tabular and the other as files
titanic_file_dataset = Dataset.File.from_files(path=[(datastore, file_name)])
step1_input2 = titanic_file_dataset.as_named_input("file_input").as_hdfs()
En el ejemplo de código se supone que el archivo Titanic.csv está en el almacenamiento de blobs. El código muestra cómo leer ambos archivos como un TabularDataset y un FileDataset. Este código solo sirve como demostración, ya que sería confuso duplicar las entradas o interpretar un único origen de datos de dos maneras: como un recurso que contiene la tabla y simplemente como un archivo.
Importante
Para usar un FileDataset como entrada, necesita una versión azureml-core de al menos 1.20.0. Puede especificar esto con la clase Environment, como se describe más adelante. Cuando se complete un paso, puede almacenar los datos de salida, como se muestra en este ejemplo de código:
from azureml.data import HDFSOutputDatasetConfig
step1_output = HDFSOutputDatasetConfig(destination=(datastore,"test")).register_on_complete(name="registered_dataset")
En este ejemplo de código, el datastore almacenaría los datos en un archivo denominado test. Los datos estarían disponibles en el área de trabajo de Machine Learning como un Dataset con el nombre registered_dataset.
Además de los datos, un paso de canalización puede tener dependencias de Python por paso. Además, los objetos SynapseSparkStep individuales también pueden especificar su configuración precisa de Azure Synapse Apache Spark. Para mostrar esto, el siguiente ejemplo de código especifica que la versión del paquete de azureml-core debe ser al menos 1.20.0. Como se mencionó anteriormente, este requisito del paquete de azureml-core es necesario para usar FileDataset como entrada.
from azureml.core.environment import Environment
from azureml.pipeline.steps import SynapseSparkStep
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core>=1.20.0")
step_1 = SynapseSparkStep(name = 'synapse-spark',
file = 'dataprep.py',
source_directory="./code",
inputs=[step1_input1, step1_input2],
outputs=[step1_output],
arguments = ["--tabular_input", step1_input1,
"--file_input", step1_input2,
"--output_dir", step1_output],
compute_target = 'link1-spark01',
driver_memory = "7g",
driver_cores = 4,
executor_memory = "7g",
executor_cores = 2,
num_executors = 1,
environment = env)
Este código especifica un solo paso en la canalización de Azure Machine Learning. El valor environment de este código establece una versión de azureml-core específica y el código puede agregar otras dependencias de conda o pip según sea necesario.
El SynapseSparkStep comprime y carga el subdirectorio ./code desde el equipo local. Ese directorio se vuelve a crear en el servidor de proceso y el paso ejecuta el script dataprep.py desde ese directorio. Los inputs y outputs de ese paso son los objetos step1_input1, step1_input2 y step1_output descritos anteriormente. La forma más sencilla de acceder a esos valores dentro del script dataprep.py es asociarlos con el parámetro arguments con nombre.
El siguiente conjunto de argumentos para los constructores SynapseSparkStep controla Apache Spark. El parámetro compute_target es el objeto 'link1-spark01' que asociamos anteriormente como destino de proceso. Los otros parámetros especifican la memoria y los núcleos que nos gustaría usar.
El cuaderno de ejemplo usa este código para dataprep.py:
import os
import sys
import azureml.core
from pyspark.sql import SparkSession
from azureml.core import Run, Dataset
print(azureml.core.VERSION)
print(os.environ)
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--tabular_input")
parser.add_argument("--file_input")
parser.add_argument("--output_dir")
args = parser.parse_args()
# use dataset sdk to read tabular dataset
run_context = Run.get_context()
dataset = Dataset.get_by_id(run_context.experiment.workspace,id=args.tabular_input)
sdf = dataset.to_spark_dataframe()
sdf.show()
# use hdfs path to read file dataset
spark= SparkSession.builder.getOrCreate()
sdf = spark.read.option("header", "true").csv(args.file_input)
sdf.show()
sdf.coalesce(1).write\
.option("header", "true")\
.mode("append")\
.csv(args.output_dir)
Este script de "preparación de datos" no realiza ninguna transformación de datos real, pero muestra cómo recuperarlos, convertirlos en una trama de datos de Spark y manipularlos de forma básica en Apache Spark. Para buscar la salida en el estudio de Azure Machine Learning, abra el trabajo secundario, elija la pestaña Salidas y registros y abra el archivo logs/azureml/driver/stdout, como se muestra en esta captura de pantalla:
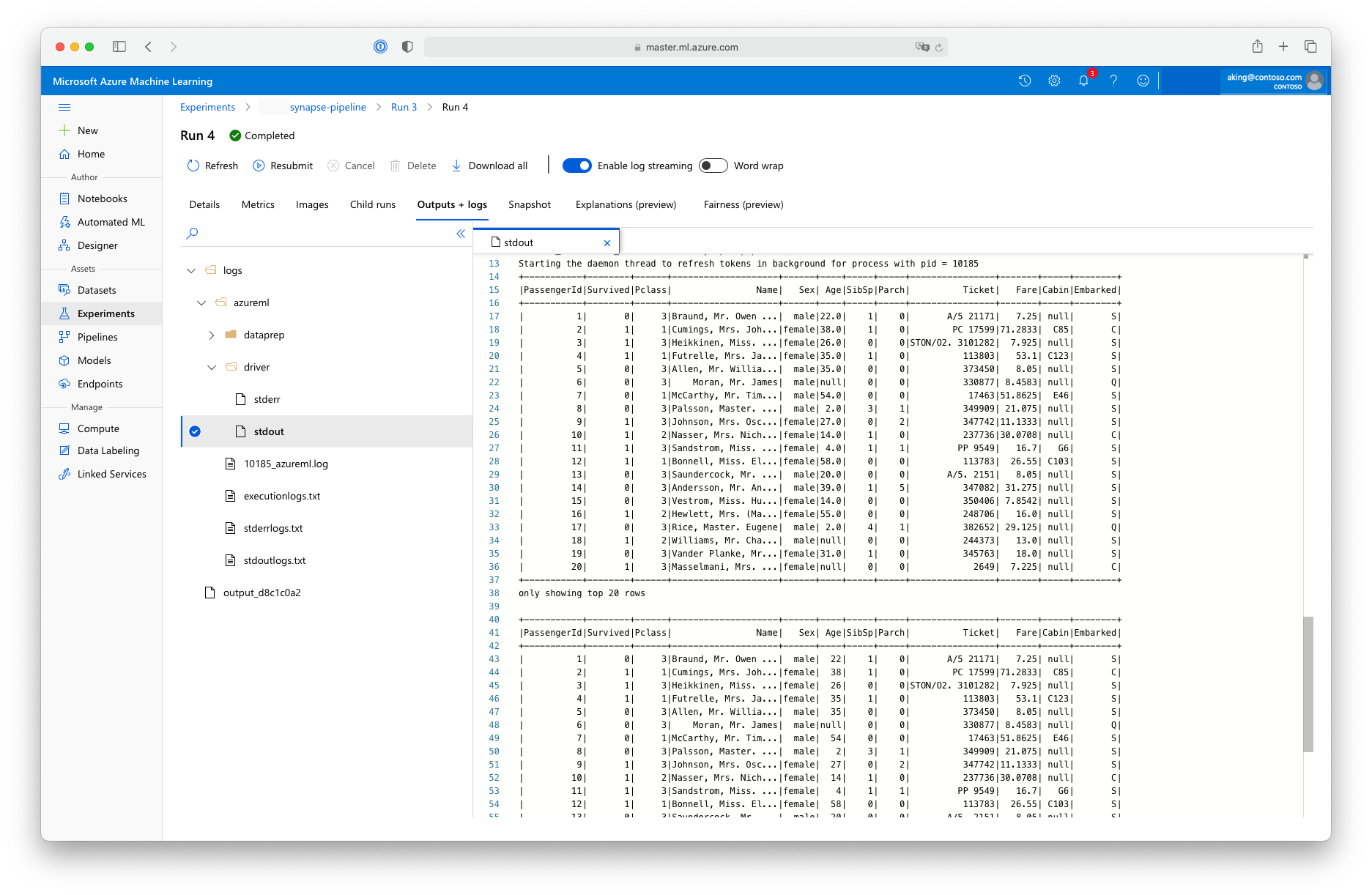
Uso de SynapseSparkStep en una canalización
En el siguiente ejemplo se usa la salida de SynapseSparkStep creada en la sección anterior. Otros pasos de la canalización pueden tener sus propios entornos únicos y pueden ejecutarse en distintos recursos de proceso adecuados para la tarea en cuestión. El cuaderno de ejemplo ejecuta el "paso de entrenamiento" en un clúster de CPU pequeño:
from azureml.core.compute import AmlCompute
cpu_cluster_name = "cpucluster"
if cpu_cluster_name in ws.compute_targets:
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
print('Found existing cluster, use it.')
else:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2', max_nodes=1)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
print('Allocating new CPU compute cluster')
cpu_cluster.wait_for_completion(show_output=True)
step2_input = step1_output.as_input("step2_input").as_download()
step_2 = PythonScriptStep(script_name="train.py",
arguments=[step2_input],
inputs=[step2_input],
compute_target=cpu_cluster_name,
source_directory="./code",
allow_reuse=False)
Este código crea el nuevo recurso de proceso si es necesario. A continuación, convierte el resultado de step1_output en la entrada del paso de entrenamiento. La opción as_download() significa que los datos se mueven al recurso de proceso, lo que da lugar a un acceso más rápido. Si los datos eran tan grandes que no encajaban en el disco duro de proceso local, tendría que usar la opción de as_mount() para transmitir los datos con el sistema de archivos FUSE. El parámetro compute_target de este segundo paso es 'cpucluster', no el recurso 'link1-spark01' que usó en el paso de preparación de datos. En este paso se usa un programa sencillo, el script train.py, en lugar del script dataprep.py que usó en el paso anterior. El cuaderno de ejemplo tiene detalles del script train.py.
Después de definir todos los pasos, puede crear y ejecutar la canalización.
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(workspace=ws, steps=[step_1, step_2])
pipeline_run = pipeline.submit('synapse-pipeline', regenerate_outputs=True)
Este código crea una canalización que consta del paso de preparación de datos en grupos de Apache Spark con tecnología de Azure Synapse Analytics (step_1) y el paso de entrenamiento (step_2). Azure examina las dependencias de datos entre los pasos para calcular el gráfico de ejecución. En este caso, solo hay una dependencia sencilla. Aquí, step2_input necesariamente requiere step1_output.
La llamada pipeline.submit crea, si es necesario, un experimento denominado synapse-pipeline e inicia asincrónicamente un trabajo dentro de él. Los pasos individuales dentro de la canalización se ejecutan como trabajos secundarios de este trabajo principal y la página Experimentos de Studio puede supervisar y revisar esos pasos.
Pasos siguientes
Comentaris
Properament: al llarg del 2024 eliminarem gradualment GitHub Issues com a mecanisme de retroalimentació del contingut i el substituirem per un nou sistema de retroalimentació. Per obtenir més informació, consulteu: https://aka.ms/ContentUserFeedback.
Envieu i consulteu els comentaris de