Tutorial: Entrenamiento e implementación de un modelo de clasificación de imágenes con un ejemplo de Jupyter Notebook
SE APLICA A: SDK de Python azureml v1
SDK de Python azureml v1
En este tutorial, entrenará un modelo de aprendizaje automático en los recursos de proceso remotos. Usará el flujo de trabajo de entrenamiento e implementación de Azure Machine Learning en un cuaderno de Jupyter Notebook en Python. A continuación, puede utilizar el cuaderno como plantilla para entrenar su propio modelo de Machine Learning con sus propios datos.
En este tutorial se entrena una regresión logística simple con el conjunto de datos de MNIST y scikit-learn con Azure Machine Learning. MNIST es un conjunto de datos popular que consta de 70 000 imágenes en escala de grises. Cada imagen es un dígito escrito a mano de 28×28 píxeles, que representa un número de 0 a 9. El objetivo es crear un clasificador multiclase para identificar el dígito que representa una imagen determinada.
Aprenda a realizar las siguientes acciones:
- Descargar un conjunto de datos y observar los datos.
- Entrenar un modelo de clasificación de imágenes y métricas de registro mediante MLflow.
- Implementar el modelo para realizar inferencias en tiempo real.
Requisitos previos
- Complete el artículo de inicio rápido: introducción al servicio Azure Machine Learning para:
- Cree un área de trabajo.
- Crear una instancia de proceso basada en la nube para utilizarla en el entorno de desarrollo.
Ejecución de un cuaderno desde el área de trabajo
Azure Machine Learning incluye un servidor de cuadernos en la nube del área de trabajo para obtener una experiencia sin instalación y configurada previamente. Si prefiere tener control sobre su entorno, los paquetes y las dependencias, use su propio entorno.
Clonación de la carpeta de un cuaderno
Complete la configuración del experimento siguiente y ejecute los pasos de Azure Machine Learning Studio. Esta interfaz consolidada incluye herramientas de aprendizaje automático para realizar escenarios de ciencia de datos para los profesionales de ciencia de datos con conocimientos de todos los niveles.
Inicie sesión en Azure Machine Learning Studio.
Seleccione la suscripción y el área de trabajo que ha creado.
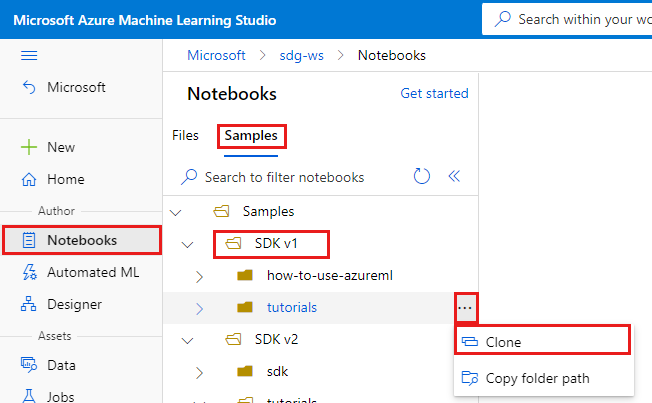
Seleccione Notebooks en la parte izquierda.
Seleccione la pestaña Ejemplos en la parte superior.
Abra la carpeta SDK v1.
Seleccione el botón "..." a la derecha de la carpeta tutorials (tutoriales) y Clone (Clonar).
En una lista de carpetas se muestran los usuarios que acceden al área de trabajo. Seleccione la carpeta donde se va a clonar la carpeta tutorials.
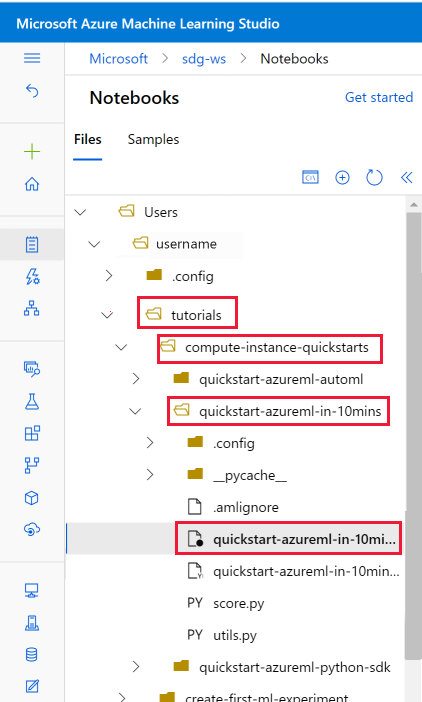
Apertura del cuaderno clonado
Abra la carpeta tutorials que se acaba de clonar en la sección User files.
Seleccione el archivo quickstart-azureml-in-10mins.ipynb de la carpeta tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins.
Instalar paquetes
Una vez que se ejecuta la instancia de proceso y aparece el kernel, agregue una nueva celda de código para instalar los paquetes necesarios para este tutorial.
En la parte superior del cuaderno, agregue una celda de código.
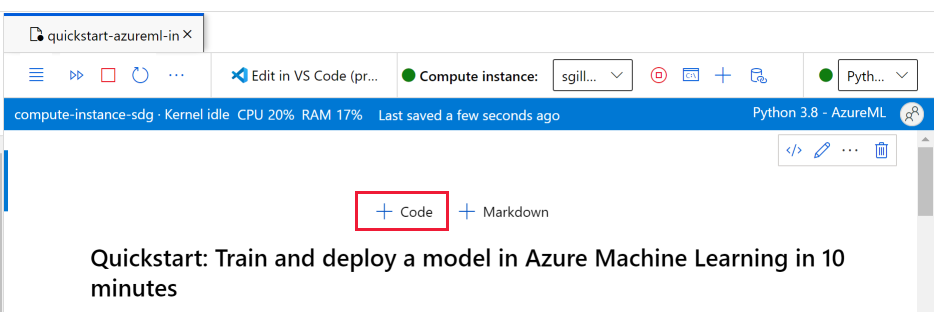
Agregue los valores siguientes a la celda y, a continuación, ejecute la celda, mediante la herramienta Ejecutar o mediante Mayús+Entrar.
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
Es posible que vea algunas advertencias de instalación. Se pueden ignorar con seguridad.
Ejecución del cuaderno
Este tutorial y el archivo utils.py que lo acompaña también está disponible en GitHub si desea usarlo en su propio entorno local. Si no usa la instancia de proceso, agregue %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib a la instalación anterior.
Importante
El resto de este artículo contiene el mismo contenido que se ve en el cuaderno.
Cambie ahora al cuaderno de Jupyter Notebook si desea ejecutar el código a medida que lee. Para ejecutar una sola celda de código en un cuaderno, haga clic en la celda y presione Mayús + Entrar. O bien, ejecute el cuaderno completo, para lo que debe elegir Ejecutar todo en la barra de herramientas superior.
Importar datos
Antes de entrenar un modelo, deberá comprender los datos que usa para entrenarlo. En esta sección, aprenderá a:
- Descargar el conjunto de datos de MNIST
- Mostrar algunas imágenes de ejemplo
Use Azure Open Datasets para obtener los archivos de datos de MNIST sin procesar. Azure Open Datasets son conjuntos de datos públicos mantenidos que puede usar para agregar características de escenarios específicos a soluciones de aprendizaje automático a fin de obtener mejores modelos. Cada conjunto de datos tiene una clase correspondiente, MNIST en este caso, para recuperar los datos de maneras diferentes.
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
Observe los datos
Cargue los archivos comprimidos en matrices numpy. A continuación, use matplotlib para trazar 30 imágenes aleatorias del conjunto de datos con sus etiquetas sobre ellas.
Tenga en cuenta que este paso requiere una función load_data, incluida en un archivo utils.py. Este archivo está ubicado en la misma carpeta que este cuaderno. La función load_data sencillamente analiza los archivos comprimidos en matrices de numpy.
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
El código muestra un conjunto aleatorio de imágenes con sus etiquetas, parecido a este:

Entrenamiento del modelo y métricas de registro con MLflow
Entrene el modelo con el código siguiente. Este código usa el registro automático de MLflow para realizar un seguimiento de las métricas y los artefactos del modelo de registro.
Va a usar el clasificador LogisticRegression del marco de SciKit Learn para clasificar los datos.
Nota:
El entrenamiento del modelo tarda aproximadamente 2 minutos en completarse.
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
Visualización de un experimento
En el menú izquierdo de Azure Machine Learning Studio, seleccione Trabajos y, a continuación, seleccione el trabajo (azure-ml-in10-mins-tutorial). Un trabajo es una agrupación de varias ejecuciones de un script determinado o un fragmento de código. Se pueden agrupar varios trabajos como un experimento.
La información de la ejecución se almacena en ese trabajo. Si el nombre no existe al enviar un trabajo, si selecciona la ejecución, verá varias pestañas que contienen métricas, registros, explicaciones, etc.
Control de versiones de los modelos con el registro de modelos
Puede usar el registro del modelo para almacenar y controlar las versiones de los modelos en su área de trabajo. Los modelos registrados se identifican por el nombre y la versión. Cada vez que registra un modelo con el mismo nombre que uno existente, el registro incrementa la versión. El código siguiente registra y versiona el modelo que entrenó anteriormente. Una vez que ejecute la siguiente celda de código, verá el modelo en el Registro seleccionando Modelos en el menú izquierdo de Estudio de Azure Machine Learning.
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
Implementar el modelo para inferencias en tiempo real
En esta sección aprenderá a implementar un modelo para que una aplicación pueda consumir (inferenciar) el modelo a través de REST.
Creación de la configuración de implementación
La celda de código obtiene un entorno seleccionado, que especifica todas las dependencias necesarias para hospedar el modelo (por ejemplo, los paquetes como scikit-learn). Además, se crea una configuración de implementación, que especifica la cantidad de proceso necesaria para hospedar el modelo. En este caso, el proceso tiene 1 CPU y 1 GB de memoria.
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-1.0"
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
Implementación de un modelo
En esta celda de código siguiente se implementa el modelo en la instancia de contenedor de Azure.
Nota:
La implementación tarda aproximadamente 3 minutos en completarse. Pero puede que tarde más en estar disponible para su uso, quizás 15 minutos.**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
El archivo de script de puntuación al que se hace referencia en el código anterior se puede encontrar en la misma carpeta que este cuaderno, y tiene dos funciones:
- Una función
initque se ejecuta una vez cuando se inicia el servicio: en esta función normalmente se obtiene el modelo del registro y se establecen variables globales. - Una función
run(data)que se ejecuta cada vez que se realiza una llamada al servicio. En esta función, normalmente se formatearán los datos de entrada, se ejecutará una predicción y se genera el resultado previsto.
Ver punto de conexión
Una vez implementado correctamente el modelo, puede ver el punto de conexión en Puntos de conexión en el menú izquierdo de Estudio de Azure Machine Learning. Verá el estado del punto de conexión (correcto o incorrecto), los registros y el consumo (cómo las aplicaciones pueden consumir el modelo).
Prueba del servicio de modelos
Puede probar el modelo mediante el envío de una solicitud HTTP sin procesar para probar el servicio web.
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
Limpieza de recursos
Si no va a seguir usando este modelo, elimine el servicio de modelo con:
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
Si desea controlar aún más el costo, detenga la instancia de proceso seleccionando el botón "Detener proceso" junto a la lista desplegable Proceso. Vuelva a iniciar la instancia de proceso la próxima vez que la necesite.
Eliminar todo el contenido
Siga estos pasos para eliminar el área de trabajo de Azure Machine Learning y todos los recursos de proceso.
Importante
Los recursos que creó pueden usarse como requisitos previos para otros tutoriales y artículos de procedimientos de Azure Machine Learning.
Si no va a usar ninguno de los recursos que ha creado, elimínelos para no incurrir en cargos:
En Azure Portal, seleccione Grupos de recursos a la izquierda del todo.
En la lista, seleccione el grupo de recursos que creó.
Seleccione Eliminar grupo de recursos.
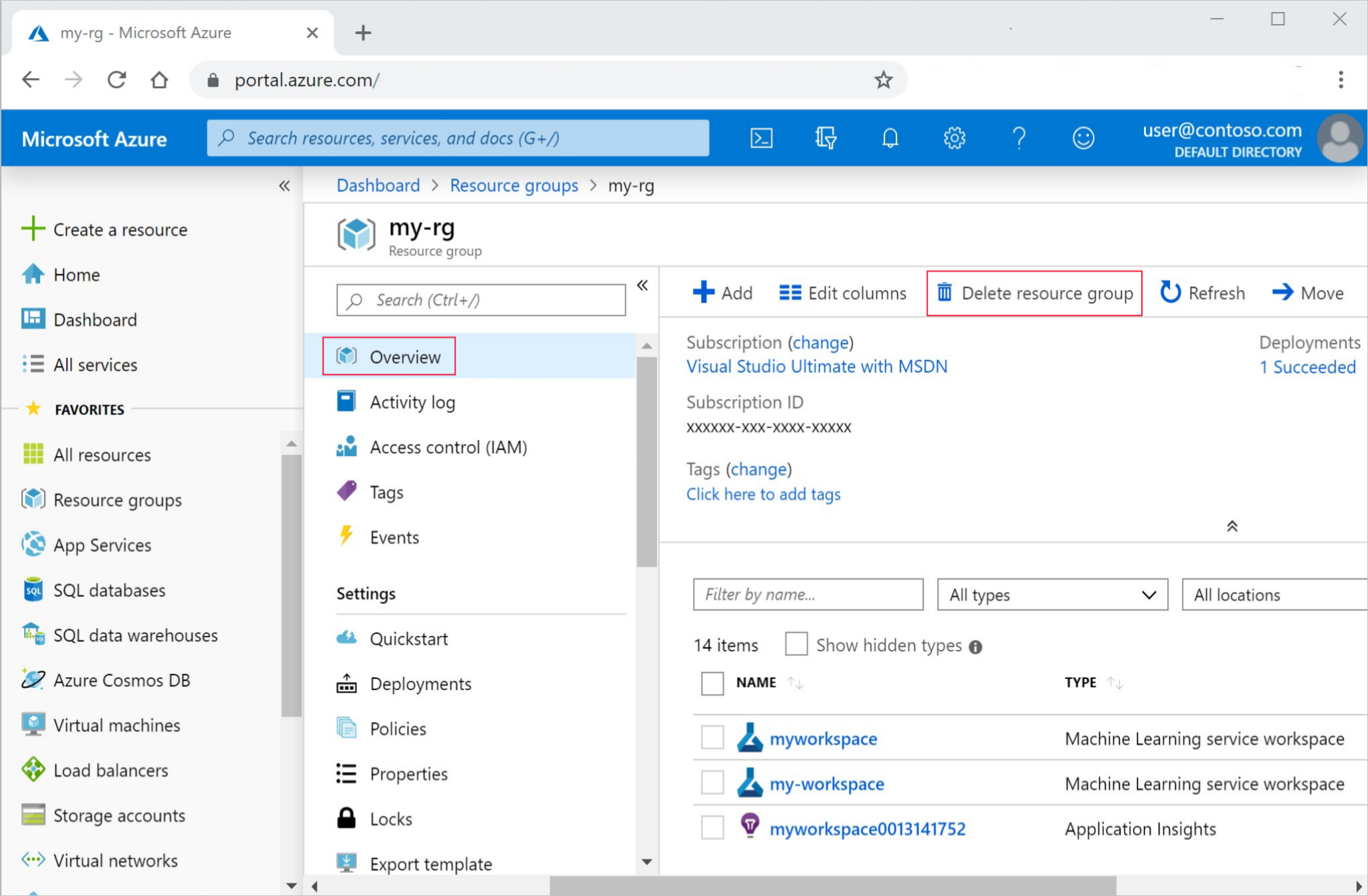
Escriba el nombre del grupo de recursos. A continuación, seleccione Eliminar.
Recursos relacionados
- Más información sobre todas las opciones de implementación de Azure Machine Learning.
- Obtenga información sobre cómo autenticarse en el modelo implementado.
- Realización de predicciones sobre grandes cantidades de datos asincrónicamente.
- Supervise los modelos de Azure Machine Learning con Application Insights.
Comentaris
Properament: al llarg del 2024 eliminarem gradualment GitHub Issues com a mecanisme de retroalimentació del contingut i el substituirem per un nou sistema de retroalimentació. Per obtenir més informació, consulteu: https://aka.ms/ContentUserFeedback.
Envieu i consulteu els comentaris de