Tutorial: Optimización de la indexación mediante la API de inserción
La búsqueda de Azure AI admite dos enfoques básicos para importar datos en un índice de búsqueda: insertar los datos en el índice mediante programación o extraer en los datos apuntando un indexador de Búsqueda de Azure AI en un origen de datos compatible.
En este tutorial, se explica cómo indexar los datos de forma eficaz utilizando el modelo de inserción mediante la creación de solicitudes por lotes y el uso de una estrategia de reintento de retroceso exponencial. Puede descargar y ejecutar la aplicación de ejemplo. En este artículo, se explican los aspectos fundamentales de la aplicación y los factores que se deben tener en cuenta a la hora de indexar datos.
En este tutorial se usa C# y la biblioteca Azure.Search.Documents del SDK de Azure para .NET para realizar las tareas siguientes:
- Creación de un índice
- Prueba de varios tamaños de lote para determinar cuál es el más eficaz
- Indexación de lotes de forma asincrónica
- Uso de varios subprocesos para aumentar las velocidades de indexación
- Uso de una estrategia de reintento de retroceso exponencial para volver a probar los documentos con errores
Requisitos previos
Este tutorial requiere los siguientes servicios y herramientas:
Suscripción a Azure. En caso de no tener ninguna, puede crear una gratis.
Visual Studio, cualquier edición. Se han probado código de ejemplo e instrucciones en la edición Community Edition gratuita.
Descarga de archivos
El código fuente de este tutorial se encuentra en la carpeta optimize-data-indexing/v11 del repositorio Azure-Samples/azure-search-dotnet-scale GitHub.
Aspectos importantes
Los factores que afectan a las velocidades de indexación se enumeran a continuación. Para más información, consulte Indexar grandes conjuntos de datos.
- Nivel de servicio y el número de particiones o réplicas: agregar particiones o actualizar el nivel aumenta las velocidades de indexación.
- Complejidad del esquema de índice: agregar campos y propiedades de campo reduce las velocidades de indexación. Los índices más pequeños se indexan más rápido.
- Tamaño de Lote: el tamaño óptimo del lote varía en función del esquema de índice y del conjunto de datos.
- Número de subprocesos o trabajos: un único subproceso no aprovecha al máximo las velocidades de indexación.
- Estrategia de reintento: una estrategia de reintentos de retroceso exponencial es un procedimiento recomendado para una indexación óptima.
- Velocidades de transferencia de datos de red: las velocidades de transferencia de datos pueden ser un factor de limitación. Indexe los datos desde su entorno de Azure para aumentar las velocidades de transferencia de datos.
Paso 1: Creación de un servicio de Búsqueda de Azure AI
Para completar este tutorial, necesita un servicio de Búsqueda de Azure AI, que puede crear en Azure Portalo buscar un servicio existente en la suscripción actual. Se recomienda usar el mismo nivel que tiene previsto utilizar en producción para que pueda probar y optimizar con precisión las velocidades de indexación.
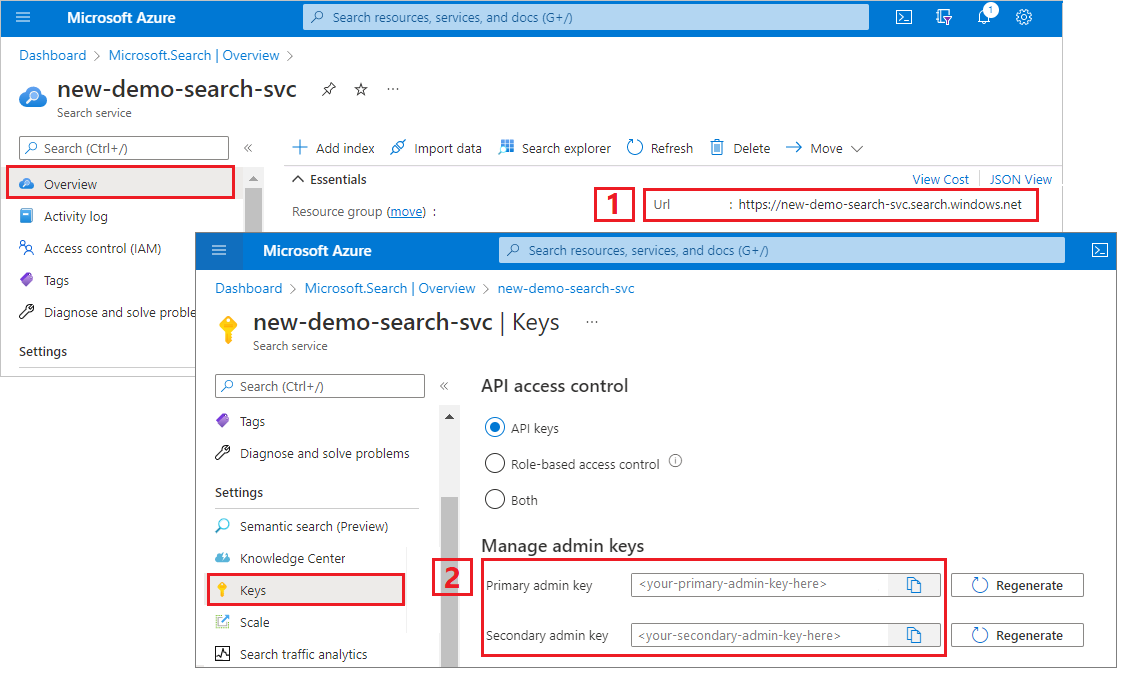
Obtención de una clave de administrador y una dirección URL para Azure AI Search
En este tutorial se usa la autenticación basada en claves. Copie una clave de API de administrador para pegarla en el archivo appsettings.json.
Inicie sesión en Azure Portal. Obtenga la dirección URL del punto de conexión del servicio de búsqueda en la página deInformación general. Un punto de conexión de ejemplo podría ser similar a
https://mydemo.search.windows.net.En Configuración>Claves, obtenga una clave de administrador para tener derechos completos en el servicio. Se proporcionan dos claves de administrador intercambiables para lograr la continuidad empresarial, por si necesitara sustituir una de ellas. Puede usar la clave principal o secundaria en las solicitudes para agregar, modificar y eliminar objetos.
Paso 2: Configuración del entorno
Inicie Visual Studio y abra OptimizeDataIndexing. sln.
En el Explorador de soluciones, abra appsettings.json para proporcionar la información de conexión del servicio.
{
"SearchServiceUri": "https://{service-name}.search.windows.net",
"SearchServiceAdminApiKey": "",
"SearchIndexName": "optimize-indexing"
}
Paso 3: Explorar el código
Una vez que actualice appSettings. json, el programa de ejemplo de OptimizeDataIndexing. sln debería estar listo para la compilación y ejecución.
Este código se deriva de la sección C# de Inicio rápido: búsqueda de texto completo mediante los SDK de Azure. Encontrará información más detallada sobre los conceptos básicos de trabajar con SDK para .NET en ese artículo.
Esta sencilla aplicación de consola de C#/.NET realiza las siguientes tareas:
- Crea un nuevo índice basado en la estructura de datos de la clase
Hotelde C# (que también hace referencia a la claseAddress). - Pruebas de varios tamaños de lote para determinar cuál es el más eficaz
- Indexación de datos de forma asincrónica
- Uso de varios subprocesos para aumentar las velocidades de indexación
- Uso de una estrategia de reintento de retroceso exponencial para reintentar los elementos con errores
Antes de ejecutar el programa, dedique unos minutos a examinar el código y las definiciones de índice de este ejemplo. El código pertinente aparece en varios archivos:
- Hotel.cs y Dirección.cs contienen el esquema que define el índice
- DataGenerator.cs contiene una clase simple para facilitar la creación de grandes cantidades de datos de Hotel.
- ExponentialBackoff.cs contiene código para optimizar el proceso de indexación, tal y como se describe en este artículo
- Program.cs contiene funciones que crean y eliminan el índice de Azure AI Search, indexa lotes de datos y prueba diferentes tamaños de lote.
creación del índice
Este programa de ejemplo usa el SDK de .Azure para NET para definir y crear un índice de Búsqueda de Azure AI. Aprovecha la clase FieldBuilder para generar una estructura de índice a partir de una clase de modelo de datos de C#.
El modelo de datos se define mediante la clase Hotel, que también contiene referencias a la clase Address. FieldBuilder explora en profundidad varias definiciones de clase para generar una estructura de datos compleja para el índice. Se usan etiquetas de metadatos para definir los atributos de cada campo (por ejemplo, si permiten hacer búsquedas o clasificaciones).
Los siguientes fragmentos de código del archivo Hotel.cs muestran cómo se pueden especificar un campo único y una referencia a otra clase de modelo de datos.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
En el archivo Program.cs, el índice se define con un nombre y una colección de campos generados por el método FieldBuilder.Build(typeof(Hotel)) y se crea como sigue:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Generar datos
Una clase simple se implementa en el archivo DataGenerator.cs para generar datos con fines de prueba. La única finalidad de esta clase es facilitar la generación de un gran número de documentos con un identificador único para la indexación.
Para obtener una lista de los 100 000 hoteles con identificadores únicos, debe ejecutar las líneas de código siguientes:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
Hay dos tamaños de hotel disponibles para las pruebas de este ejemplo: pequeño y grande.
El esquema del índice tiene un efecto en las velocidades de indexación. Por este motivo, tiene sentido convertir esta clase para generar datos que coincidan mejor con el esquema de índice previsto después de terminar este tutorial.
Paso 4: Probar tamaños de lote
Azure AI Search admite las siguientes API para cargar uno o varios documentos en un índice:
La indexación de documentos en lotes mejora significativamente el rendimiento de la indexación. Estos lotes pueden ser de hasta 1000 documentos o hasta 16 MB por lote.
Determinar el tamaño de lote óptimo para los datos es un aspecto fundamental de la optimización de las velocidades de indexación. Los dos principales aspectos que influyen en el tamaño de lote óptimo son:
- El esquema del índice
- El tamaño de los datos
Dado que el tamaño de lote óptimo depende del índice y los datos, el mejor enfoque consiste en probar distintos tamaños de lote para determinar cuál ofrece mayores velocidades de indexación en su caso.
La siguiente función muestra un enfoque sencillo para probar los tamaños de lote.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Dado que no todos los documentos tienen el mismo tamaño (aunque en este ejemplo sí lo tengan), calcularemos el tamaño de los datos que se van a enviar al servicio de búsqueda. Puede hacerlo mediante la siguiente función que primero convierte el objeto en json y, a continuación, determina su tamaño en bytes. Esta técnica nos permite determinar qué tamaños de lote son más eficaces en términos de MB/s y de velocidades de indexación.
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
La función requiere un SearchClient, así como el número de intentos que deseamos probar con cada tamaño de lote. Dado que puede haber variabilidad en los tiempos de indexación de cada lote, pruebe cada lote tres veces de manera predeterminada para que los resultados sean más significativos estadísticamente.
await TestBatchSizesAsync(searchClient, numTries: 3);
Al ejecutar la función, debería ver una salida en la consola como en el ejemplo siguiente:

Identifique el tamaño de lote más eficaz y utilice ese tamaño de lote en el siguiente paso del tutorial. Es posible que vea una valor estable en MB/s para distintos tamaños de lote.
Paso 5: Indexar los datos
Ahora que identificó el tamaño del lote que quiere usar, el siguiente paso es comenzar a indexar los datos. Para indexar los datos de forma eficaz, este ejemplo:
- usa varios subprocesos o trabajos
- implementa una estrategia de reintento de retroceso exponencial
Quite la marca de comentario de las líneas 41 a 49 y vuelva a ejecutar el programa. En esta ejecución, el ejemplo genera y envía lotes de documentos, hasta 100 000 si ejecuta el código sin cambiar los parámetros.
Uso de varios subprocesos o trabajos
Para aprovechar al máximo las velocidades de indexación de Búsqueda de Azure AI, use varios subprocesos para enviar solicitudes de indexación por lotes de forma simultánea al servicio.
Varias de las consideraciones clave mencionadas anteriormente pueden afectar al número óptimo de subprocesos. Puede modificar este ejemplo y probar diferentes números de subprocesos para determinar cuál es el número óptimo de subprocesos en su caso. Sin embargo, siempre que tenga varios subprocesos que se ejecuten simultáneamente, se deberían poder aprovechar al máximo la mayoría de las ventajas de eficiencia.
A medida que aumenta las solicitudes que alcanzan el servicio de búsqueda, puede encontrarse con códigos de estado HTTP que indican que la solicitud no se completó correctamente. Durante la indexación, dos de los códigos de estado HTTP comunes son:
- Servicio 503 No disponible: este error significa que el sistema está bajo carga pesada y la solicitud no se puede procesar en este momento.
- Estado múltiple 207: este error significa que algunos documentos se realizaron correctamente, pero al menos un error.
Implementación de una estrategia de reintento de retroceso exponencial
Si se produce un error, las solicitudes deberán reintentarse utilizando una estrategia de reintento de retroceso exponencial.
El SDK de Búsqueda de Azure AI para .NET reintenta automáticamente las solicitudes 503 y otras que hayan dado error, pero es preciso que implemente su propia lógica para reintentar las solicitudes 207. Las herramientas de código abierto, como Polly, pueden ser útiles en una estrategia de reintento.
En este ejemplo, implementamos una estrategia propia de reintento de retroceso exponencial. Para empezar, definimos algunas variables, como maxRetryAttempts y delay inicial de una solicitud con error:
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
Los resultados de la operación de indexación se almacenan en la variable IndexDocumentResult result. Esta variable es importante porque permite comprobar si se produjo un error en algún documento del lote, como se muestra en el ejemplo siguiente. Si se produce un error parcial, se crea un nuevo lote basado en el identificador de los documentos con errores.
También se detectarán las excepciones de RequestFailedException, ya que indican que la solicitud ha generado un error y debe volver a intentarse.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Desde aquí, encapsula el código de retroceso exponencial en una función para que se pueda llamar fácilmente.
A continuación, se crea otra función para administrar los subprocesos activos. Para simplificar las cosas, esa función no se incluye aquí, pero se puede ver en ExponentialBackoff.cs. Es posible llamar a la función mediante el siguiente comando, donde hotels son los datos que queremos cargar, 1000 es el tamaño del lote y 8 es el número de subprocesos simultáneos:
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
Al ejecutar la función, debería ver una salida:

Cuando un lote de documentos genera error, se imprime el error indicado y se reintenta el lote:
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
Una vez la función se ha ejecutado, puede comprobar si todos los documentos se han agregado al índice.
Paso 6: Explorar el índice
Puede explorar el índice de búsqueda rellenado después de que el programa se haya ejecutado mediante programación o mediante el Explorador de búsqueda en el portal.
Mediante programación
Hay dos opciones principales para comprobar el número de documentos en un índice: la API de recuento de documentos y la API de obtención de estadísticas de índice. Ambas rutas requieren tiempo para procesar, por lo que no se extrañe si el número de documentos devueltos es inicialmente inferior al esperado.
Documentos de recuento
La operación de recuento de documentos obtiene el número de documentos en un índice de búsqueda:
long indexDocCount = await searchClient.GetDocumentCountAsync();
Obtención de estadísticas de índice
La operación de obtención de estadísticas de índice devuelve un número de documentos para el índice actual, junto con el uso del almacenamiento. Las estadísticas de índice tardan más tiempo que el recuento de documentos en actualizarse.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Azure portal
En Azure Portal, en el panel de navegación izquierdo, busque el índice de optimización de la indexación en la listaíndices .

El recuento de documentos y el tamaño de almacenamiento se basan en la API de obtención de estadísticas y pueden tardar varios minutos en actualizarse.
Restablecer y volver a ejecutar
En las primeras etapas experimentales de desarrollo, el enfoque más práctico para la iteración de diseño es eliminar los objetos de Azure AI Search y permitir que el código vuelva a generarlos. Los nombres de los recursos son únicos. La eliminación de un objeto permite volver a crearlo con el mismo nombre.
El código de ejemplo de este tutorial comprueba los índices existentes y los elimina para que el usuario pueda volver a ejecutar su código.
Puede usar el portal para eliminar los índices.
Limpieza de recursos
Cuando trabaje con su propia suscripción, al final de un proyecto, es recomendable eliminar los recursos que ya no necesite. Los recursos que se dejan en ejecución pueden costarle mucho dinero. Puede eliminar los recursos de forma individual o eliminar el grupo de recursos para eliminar todo el conjunto de recursos.
Puede encontrar y administrar recursos en el portal, mediante el vínculo Todos los recursos o Grupos de recursos en el panel de navegación izquierdo.
Paso siguiente
Para más información sobre la indexación de datos de grandes cantidades, pruebe el siguiente tutorial.