¿Qué desea saber sobre Service Fabric?
Azure Service Fabric es una plataforma de sistemas distribuidos que facilita el empaquetamiento, la implementación y la administración de microservicios escalables y confiables. Sin embargo, Service Fabric tiene un área expuesta de gran tamaño, y hay mucho por aprender. En este artículo se proporciona una sinopsis de Service Fabric y se describen los conceptos principales, los modelos de programación, el ciclo de vida de la aplicación, las pruebas, los clústeres y la supervisión del estado. Lea Información general y ¿Qué son los microservicios? para obtener una introducción y conocer cómo se puede utilizar Service Fabric para crear microservicios. Este artículo no contiene una lista completa de contenido, pero incluye vínculos a información general y artículos de introducción de cada área de Service Fabric.
Conceptos principales
Terminología de Service Fabric, Modelo de aplicación y Modelos de programación admitidos ofrecen varios conceptos y descripciones, pero estos son los conceptos básicos.
- Clúster de Service Fabric: en este vínculo verá un vídeo de entrenamiento para obtener una introducción a la arquitectura de Service Fabric y sus conceptos básicos y explorar muchas características de Service Fabric.
- Conceptos del entorno de ejecución: en este vínculo verá un vídeo de entrenamiento para comprender los conceptos del entorno de ejecución y los procedimientos recomendados de Service Fabric.
- Conceptos del tipo de diseño: en este vínculo verá un vídeo de entrenamiento para comprender la aplicación, el empaquetado y la implementación; terminología clave, abstracciones y conceptos de Service Fabric.
Tiempo de diseño: tipo de servicio, paquete y manifiesto de servicio, tipo de aplicación, paquete y manifiesto de aplicación
Un tipo de servicio es el nombre o versión asignados a los paquetes de código, paquetes de datos y paquetes de configuración de un servicio. Esto se define en un archivo ServiceManifest.xml. Además, se compone de las opciones de configuración del servicio y el código ejecutable que se cargan en tiempo de ejecución, y los datos estáticos que el servicio consume.
Un paquete de servicio es un directorio de disco que contiene el archivo ServiceManifest.xml del tipo de servicio, que hace referencia al código, los datos estáticos y los paquetes de configuración del tipo de servicio. Por ejemplo, un paquete de servicio puede hacer referencia al código, a los datos estáticos y a los paquetes de configuración que conforman un servicio de base de datos.
Un tipo de aplicación es el nombre o versión asignados a una colección de tipos de servicios. Esto se define en un archivo ApplicationManifest.xml.
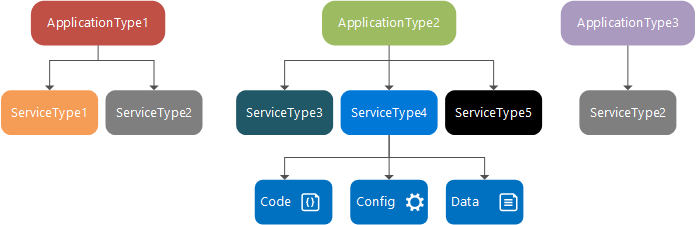
El paquete de aplicación es un directorio de disco que contiene el archivo ApplicationManifest.xml del tipo de aplicación, que hace referencia a los paquetes de servicio para cada tipo de servicio que compone el tipo de aplicación. Por ejemplo, un paquete de aplicación de un tipo de aplicación de correo electrónico puede contener referencias a un paquete de servicios de cola, un paquete de servicios de front-end y un paquete de servicios de base de datos.
Los archivos en el directorio del paquete de aplicación se copian en el almacén de imágenes del clúster de Service Fabric. Después, puede crear una aplicación con nombre a partir de este tipo de aplicación y ejecutarla después en el clúster. Después de crear una aplicación con nombre, se pude crear un servicio con nombre desde uno de los tipos de servicio del tipo de aplicación.
Tiempo de ejecución: clústeres y nodos, aplicaciones con nombre, servicios con nombre, particiones y réplicas
Un clúster de Service Fabric es un conjunto de máquinas físicas o virtuales conectadas a la red, en las que se implementan y administran los microservicios. Los clústeres pueden escalar a miles de equipos.
Cada una de las máquinas físicas o virtuales que forman parte de un clúster se denominan nodo. A cada nodo se le asigna un nombre de nodo (una cadena). Los nodos tienen características como las propiedades de colocación. Cada máquina física o virtual tiene un servicio de Windows de inicio automático, FabricHost.exe, que empieza a ejecutarse en el arranque y luego inicia dos ejecutables: Fabric.exe y FabricGateway.exe. Estos dos ejecutables conforman el nodo. En los escenarios de prueba o desarrollo, se pueden hospedar varios nodos en un solo equipo o máquina virtual mediante la ejecución de varias instancias de Fabric.exe y FabricGateway.exe.
Una aplicación con nombre es una colección de servicios con nombre que realizan una o varias funciones determinadas. Un servicio realiza una función completa e independiente (puede iniciarse y ejecutarse independientemente de otros servicios) y se compone de código, configuración y datos. Una vez que un paquete de aplicación se copia en el almacén de imágenes, se crea una instancia de la aplicación en el clúster especificando el tipo de aplicación del paquete de aplicación (mediante su nombre o versión). A cada instancia del tipo de aplicación se le asigna un nombre de identificador URI similar a fabric:/MyNamedApp. En un clúster se pueden crear varias aplicaciones con nombre de un único tipo de aplicación. También se pueden crear aplicaciones con nombre de diferentes tipos de aplicación. Cada aplicación con nombre se administra de manera independiente y tiene versiones independientes.
Después de crear una aplicación con nombre puede crear una instancia de uno de sus tipos de servicio (un servicio con nombre) en el clúster, especificando el tipo de servicio (con su nombre o versión). A cada instancia del tipo de servicio se le asigna un nombre de URI cuyo ámbito es el URI de su aplicación con nombre. Por ejemplo, si crea un servicio con nombre "MyDatabase" en la aplicación con nombre "MyNamedApp", el URI será similar al siguiente: fabric:/MyNamedApp/MyDatabase. En una aplicación con nombre, puede crear uno o varios servicios con nombre. Todos los servicios con nombre pueden tener su propio esquema de partición y cuentas de instancia o réplica.
Hay dos tipos de servicios: con y sin estado. Los servicio sin estado no almacenan el estado dentro del servicio. Los servicios sin estado no tienen almacenamiento persistente en absoluto no almacenan el estado persistente en un servicio de almacenamiento externo como Azure Storage, Azure SQL Database o Azure Cosmos DB. Un servicio con estado almacena el estado dentro del servicio y usa modelos de programación Reliable Collections o Reliable Actors para administrar el estado.
Al crear un servicio con nombre, especifique un esquema de partición. Los servicios con grandes cantidades de estado dividen los datos entre las particiones. Cada partición es responsable de una parte de todo el estado del servicio, que se reparte entre los nodos del clúster.
En el siguiente diagrama se muestra la relación entre aplicaciones e instancias de servicio, particiones y réplicas.
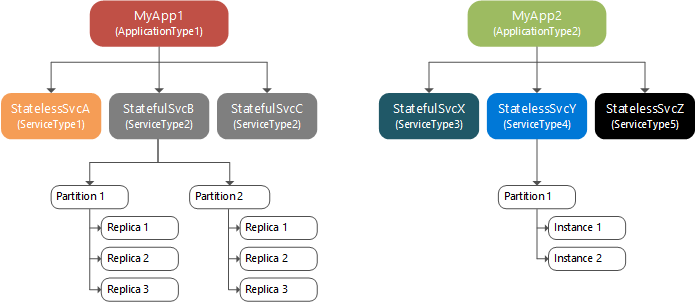
Creación de particiones, escalado y disponibilidad
La creación de particiones no es exclusiva de Service Fabric. Una forma conocida de partición es la partición de datos o particionamiento. Los servicios con estado que tienen grandes cantidades de estados dividen los datos entre las particiones. Cada partición es responsable de una parte de todo el estado del servicio.
Las réplicas de cada partición se reparten entre los nodos del clúster, lo que permite escalar el estado del servicio con nombre. A medida que los datos crecen, las particiones también crecen y Service Fabric vuelve a equilibrar las particiones entre los nodos, a fin de usar los recursos de hardware con eficacia. Si agrega nuevos nodos al clúster, Service Fabric reequilibrará las réplicas de la partición entre en el número aumentado de nodos. El rendimiento general de la aplicación mejora y se reduce la contención para el acceso a la memoria. Si los nodos del clúster no se usan de forma eficaz, puede reducir su número de nodos. Service Fabric vuelve a reequilibrar las réplicas de la partición entre el número reducido de nodos para aprovechar mejor el hardware de cada nodo.
Dentro de una partición, los servicios con nombre sin estado tienen instancias, mientras que los servicios con nombre con estado tienen réplicas. Normalmente, los servicios con nombre sin estado solo tienen una partición, ya que no tienen un estado interno (si bien hay excepciones). Las instancias de la partición proporcionan disponibilidad. Si se produce un error en una instancia, otras instancias seguirán operando con normalidad y luego Service Fabric crea una nueva instancia. Los servicios con nombre con estado mantienen su estado dentro de las réplicas y cada partición tiene su propio conjunto de réplicas. Las operaciones de lectura y escritura se realizan en una réplica (denominada principal). Los cambios en el estado debidos a las operaciones de escritura se replican en muchas otras réplicas (denominadas secundarias activas). Si se produce algún error en una réplica, Service Fabric creará una nueva réplica a partir de las réplicas existentes.
Microservicios de Service Fabric con estado y sin estado
Service Fabric permite compilar aplicaciones que constan de microservicios o contenedores. Los microservicios sin estado (como puertas de enlace de protocolo y servidores proxy web) no mantienen un estado mutable fuera de una petición y de su respuesta del servicio. Los roles de trabajo de Azure Cloud Services son un ejemplo de servicio sin estado. Los microservicios con estado (como cuentas de usuario, bases de datos, dispositivos, carros de la compra y colas) mantienen un estado mutable y autoritativo más allá de la petición y su respuesta. Actualmente, las aplicaciones de escala de Internet se componen de una combinación de microservicios con estado y sin estado.
Una diferencia clave con Service Fabric es la gran importancia que da a la creación de servicios con estado, ya sea con los modelos de programación integrados o con servicios con estado en contenedores. En los escenarios de aplicación, se describen aquellos donde se usan servicios con estado.
¿Por qué tener microservicios con estado con otros sin estado? Las dos razones principales son:
- Puede crear servicios OLTP tolerantes a errores, de latencia baja y alto rendimiento al mantener el código y los datos cerca en la misma máquina. Algunos ejemplos son interfaces de usuario interactivas, búsqueda, sistemas de Internet de las cosas (IoT), sistemas de comercialización, sistemas de detección de fraudes y procesamiento de tarjetas de crédito y, además, administración de registros personales.
- Puede simplificar el diseño de la aplicación. Los microservicios con estado eliminan la necesidad de colas y memorias caché adicionales, que son las que tradicionalmente se han necesitado para tratar los requisitos de disponibilidad y latencia de una aplicación puramente sin estado. Los servicios con estado son de alta disponibilidad y de latencia baja de forma natural, lo que disminuye la cantidad de partes en movimiento que administrar en la aplicación en su conjunto.
Modelos de programación admitidos
Service Fabric ofrece varias maneras de escribir y administrar los servicios. Los servicios pueden usar las API de Service Fabric para sacar el máximo provecho de los marcos de aplicaciones y las características de la plataforma. Los servicios también pueden ser cualquier programa ejecutable compilado escrito en cualquier lenguaje y hospedado en un clúster de Service Fabric. Para más información, consulte Modelos de programación admitidos.
Contenedores
De forma predeterminada, Service Fabric implementa y activa estos servicios como procesos. Service Fabric puede implementar también servicios en contenedores. Lo importantes es que puede mezclar servicios en procesos y servicios en contenedores en la misma aplicación. Service Fabric admite la implementación de contenedores de Linux y contenedores de Windows en Windows Server 2016. Puede usar Service Fabric para implementar aplicaciones existentes y servicios con o sin estado en un contenedor.
Reliable Services
Reliable Services es un entorno de trabajo ligero para escribir servicios que se integran con la plataforma Service Fabric y que se benefician de todo el conjunto de características de la plataforma. Reliable Services puede no tener estado (de forma similar a la mayoría de las plataformas de servicios, como servidores web o roles de trabajo de Azure Cloud Services), y el estado se conserva en una solución externa, como Azure DB o Azure Table Storage. Reliable Services también puede tener estado, y este se conserva directamente en el propio servicio mediante Reliable Collections. El estado cuenta con una alta disponibilidad mediante la replicación y se distribuye a través de particiones, todo administrado automáticamente por Service Fabric.
Reliable Actors
Basado en Reliable Services, el entorno de Reliable Actor es un entorno de aplicación que implementa el modelo de Virtual Actor, basado en el modelo de diseño de actores. El marco de Reliable Actor usa unidades independientes del proceso y el estado con la ejecución de subproceso único denominadas actores. El marco de Reliable Actor proporciona comunicaciones integradas para actores y las configuraciones de escalado horizontal y persistencia de estado establecidas previamente.
ASP.NET Core
Service Fabric se integra con ASP.NET Core como modelo de programación de primera clase para la creación de aplicaciones API y web. ASP.NET Core se puede utilizar de dos maneras diferentes en Service Fabric:
- Se hospeda como archivo ejecutable invitado. Se usa principalmente para ejecutar aplicaciones ASP.NET Core existentes en Service Fabric sin realizar ningún cambio en el código.
- Se ejecuta en una instancia de Reliable Services. Permite una mejor integración con el entorno de ejecución de Service Fabric y permite servicios ASP.NET Core con estado.
Ejecutables de invitado
Un ejecutable de invitado es un ejecutable arbitrario y existente, escrito en cualquier lenguaje, que se hospeda en un clúster de Service Fabric junto con otros servicios. Los ejecutables de invitado no se integran directamente con las API de Service Fabric. Sin embargo, todavía se beneficiarán de las características que ofrece la plataforma, como la detección de servicio y la creación de informes de carga y de estado personalizada mediante la llamada de API de REST. También tienen soporte técnico completo de ciclo de vida de aplicación.
Ciclo de vida de aplicación
Al igual que sucede con otras plataformas, una aplicación en Service Fabric normalmente pasa por las siguientes fases: diseño, desarrollo, prueba, implementación, actualización, mantenimiento y eliminación. Service Fabric ofrece compatibilidad de primera clase para todo el ciclo de vida de aplicación de las aplicaciones de nube: desde el desarrollo hasta la implementación, la administración diaria, el mantenimiento y, finalmente, la retirada. El modelo de servicio habilita varios roles distintos para participar de manera independiente en el ciclo de vida de la aplicación. En Ciclo de vida de la aplicación de Service Fabric se proporciona información general de las API y cómo las utilizan los distintos roles durante todas las fases del ciclo de vida de la aplicación de Service Fabric.
El ciclo de vida completo de la aplicación se puede administrar con cmdlets de PowerShell, comandos de la CLI, API de C#, API de Java y API de REST. También puede configurar canalizaciones de implementación continua e integración continua con herramientas como Azure Pipelines o Jenkins.
Prueba de aplicaciones y servicios
Para crear verdaderos servicios de escala en la nube, es fundamental comprobar que las aplicaciones y los servicios pueden admitir errores reales. El servicio de análisis de errores se ha diseñado para probar los servicios incorporados en Service Fabric. Con el servicio de análisis de errores, puede provocar errores significativos y ejecutar escenarios de prueba completos con sus aplicaciones. Estos errores y escenarios ejercen y validan los numerosos estados y transiciones que experimentará un servicio durante su vigencia, y todo ello de forma segura, controlada y uniforme.
Las acciones están orientadas a un servicio de prueba mediante errores individuales. Un programador del servicio puede utilizar como bloques de creación para escribir escenarios complicados. Los ejemplos de errores simulados son:
- Reiniciar un nodo para simular cualquier número de situaciones en que un equipo o máquina virtual se reinicia.
- Mover una réplica de un servicio con estado para simular el equilibrio de carga, la conmutación por error o la actualización de la aplicación.
- Invocar la pérdida de quórum en un servicio con estado para crear una situación en la que las operaciones de escritura no pueden continuar porque no hay suficientes réplicas "secundarias" o "de copia de seguridad" para aceptar los datos nuevos.
- Invocar la pérdida de datos en un servicio con estado para crear una situación en la que se borra completamente todo el estado en memoria.
Los escenarios son operaciones complejas compuestas por una o varias acciones. El servicio de análisis de errores proporciona dos escenarios completos integrados:
- Escenario de caos: simula errores continuos intercalados (tanto correctos como incorrectos) en todo el clúster durante períodos prolongados.
- Escenario de conmutación por error: una versión del escenario de prueba de caos dirigida a una partición de servicio específica, que no afecta a los demás servicios.
Clústeres
Un clúster de Service Fabric es un conjunto de máquinas físicas o virtuales conectadas a la red, en las que se implementan y administran los microservicios. Los clústeres pueden escalar a miles de equipos. Una máquina física o virtual que forma parte de un clúster se denomina nodo del clúster. A cada nodo se le asigna un nombre de nodo (una cadena). Los nodos tienen características como las propiedades de colocación. Cada máquina física o virtual tiene un servicio de inicio automático, FabricHost.exe, que empieza a ejecutarse en el arranque y luego inicia dos archivos ejecutables: Fabric.exe y FabricGateway.exe. Estos dos ejecutables conforman el nodo. En los escenarios de prueba, se pueden hospedar varios nodos en un solo equipo y máquina virtual mediante la ejecución de varias instancias de Fabric.exe y FabricGateway.exe.
Los clústeres de Service Fabric se pueden crear en cualquier máquina virtual o física que ejecute Windows Server o Linux. Puede implementar y ejecutar aplicaciones de Service Fabric en cualquier entorno donde haya un conjunto de equipos de Windows Server o Linux que estén conectados entre sí, ya sea de manera local, en Microsoft Azure o con algún proveedor en la nube.
Clústeres en Azure
La ejecución de clústeres de Service Fabric en Azure proporciona integración con otras características y servicios de Azure, lo que facilita las operaciones y la administración del clúster y hace que sea más confiable. Un clúster es un recurso de Azure Resource Manager, que permite modelar clústeres como cualquier otro recurso de Azure. Resource Manager también permite realizar una administración sencilla de todos los recursos utilizados por el clúster como una sola unidad. Los clústeres de Azure se integran con Diagnósticos de Azure y Registros de Azure Monitor. Los tipos de nodo de clúster son conjuntos de escalado de máquinas virtuales, por lo que la funcionalidad de escalado automático está integrada.
Puede crear un clúster en Azure a través de Azure Portal, a partir de una plantilla o en Visual Studio.
Service Fabric en Linux permite compilar, implementar y administrar aplicaciones de alta disponibilidad y escalabilidad en Linux de la misma forma que en Windows. Los marcos de Service Fabric (Reliable Services y Reliable Actors) se encuentran disponibles en Java en Linux, además de en C# (.NET Core). Puede compilar igualmente servicios ejecutables invitados con cualquier lenguaje o marco. También se admite la organización de contenedores de Docker. Los contenedores de Docker pueden ejecutar archivos ejecutables invitados o servicios de Service Fabric nativos que utilizan los marcos de Service Fabric. Para más información, consulte Service Fabric en Linux.
Hay algunas características que se admiten en Windows, pero no en Linux. Para más información, vea Diferencias entre Service Fabric en Linux (versión preliminar) y Windows (disponible con carácter general).
Clústeres independientes
Service Fabric le proporciona un paquete de instalación para que cree clústeres independientes de Service Fabric de forma local o en cualquier proveedor en la nube. Los clústeres independientes le dan la libertad de hospedar un clúster siempre que lo desee. Si los datos están sujetos a restricciones legales o de cumplimiento o si desea mantener los datos locales, puede hospedar clústeres y aplicaciones propios. Las aplicaciones de Service Fabric se pueden ejecutar en varios entornos de hospedaje sin realizar cambios, de tal forma que puede transferir los conocimientos sobre la creación de aplicaciones de un entorno de hospedaje a otro.
Creación del primer clúster independiente de Service Fabric
Aún no se admiten clústeres de Linux independientes.
Seguridad de clúster
Los clústeres deben estar protegidos para evitar que usuarios no autorizados se conecten a su clúster, especialmente cuando en él se están ejecutando cargas de trabajo de producción. Aunque se puede crear un clúster no seguro, si lo hace, permite que cualquier usuario anónimo se conecte a él si expone los puntos de conexión de administración a una red pública de Internet. No se puede habilitar la seguridad de un clúster no seguro en una fase posterior, ya que la seguridad se habilita en el momento en que se crea el clúster.
Estos son los escenarios de seguridad de clúster:
- Seguridad de nodo a nodo
- Seguridad de cliente a nodo
- Control de acceso basado en rol de Service Fabric
Para más información, lea Proteger un clúster.
Ampliación
Si agrega nuevos nodos al clúster, Service Fabric reequilibra las réplicas e instancias de la partición entre el número aumentado de nodos. El rendimiento general de la aplicación mejora y se reduce la contención para el acceso a la memoria. Si los nodos del clúster no se usan de forma eficaz, puede reducir su número de nodos. Service Fabric vuelve a reequilibrar las réplicas e instancias de la partición en el número reducido de nodos para aprovechar mejor el hardware de cada nodo. Puede escalar clústeres en Azure manualmente o mediante programación. Los clústeres independientes se pueden escalar manualmente.
Actualizaciones de clústeres
Periódicamente se publican nuevas versiones de Service Fabric en tiempo de ejecución. Realice actualizaciones en tiempo de ejecución o de Service Fabric en el clúster, a fin de que siempre ejecute una versión compatible. Además de las actualizaciones de Service Fabric, también puede actualizar la configuración de clúster, como los certificados o los puertos de la aplicación.
Un clúster de Service Fabric es un recurso de su propiedad administrado parcialmente por Microsoft. Microsoft es responsable de la aplicación de revisiones del sistema operativo subyacente y de realizar actualizaciones de Service Fabric en el clúster. Puede configurar el clúster para recibir las actualizaciones automáticas de Service Fabric cuando Microsoft publica una versión nueva, o bien seleccionar una versión de Service Fabric compatible que desee. Las actualizaciones de configuración y de Service Fabric pueden definirse en Azure Portal o en Resource Manager. Para más información, lea Actualización de un clúster de Azure Service Fabric.
Un clúster independiente es un recurso que es totalmente de su propiedad. Por tanto, usted es el responsable de la aplicación de revisiones del sistema operativo subyacente y de iniciar las actualizaciones de Service Fabric. Si el clúster se puede conectar a https://www.microsoft.com/download, puede configurar el clúster para que se descargue automáticamente y aprovisione el nuevo paquete en tiempo de ejecución de Service Fabric. A continuación, podría iniciar la actualización. Si el clúster no puede acceder a https://www.microsoft.com/download, puede descargar manualmente el nuevo paquete en tiempo de ejecución desde una máquina conectada a Internet y después iniciar la actualización. Para más información, lea Actualización de un clúster independiente de Azure Service Fabric.
Supervisión del estado
Service Fabric presenta un modelo de estado diseñado para marcar las condiciones poco favorables del clúster o de la aplicación en entidades específicas, como nodos de clúster y réplicas de servicio. El modelo de mantenimiento utiliza informadores de estado (componentes del sistema y guardianes). El objetivo es obtener un diagnóstico y reparación sencillo y rápido. El escritor del servicio debe pensar de antemano en el estado y en cómo diseñar informes de estado. Cualquier condición que pueda afectar al estado debe notificarse, sobre todo si puede ayudar a marcar la causa raíz de los problemas. La información de estado puede ahorrar tiempo y esfuerzo en la depuración y la investigación una vez que el servicio está en funcionamiento a escala en producción.
Los generadores de informes de Service Fabric identificaron las condiciones de interés. Informan sobre esas condiciones en función de su vista local. El almacén de estado agrega datos de mantenimiento que todos los informadores envían para determinar si el estado de las entidades es bueno en general. La intención es que el modelo sea completo, flexible y fácil de usar. La calidad de los informes de mantenimiento determina la precisión de la vista de estado del clúster. Los falsos positivos que muestran erróneamente problemas pueden afectar negativamente a las actualizaciones u otros servicios que usan datos de mantenimiento. Ejemplos de estos servicios son los servicios de reparación y los mecanismos de alerta. Por lo tanto, se necesita cierto grado de reflexión para proporcionar informes que capturen condiciones que resulten interesantes de la mejor manera posible.
Los informes pueden elaborarse a partir de:
- Réplicas o instancias de servicio de Service Fabric supervisado.
- Guardianes internos implementados como un servicio de Service Fabric (por ejemplo, un servicio sin estado de Service Fabric que supervisa las condiciones y los informes de problemas). Los guardianes pueden implementarse en todos los nodos o se pueden asociar al servicio supervisado.
- Guardianes internos que se ejecutan en los nodos de Service Fabric pero que no se implementan como servicios de Service Fabric.
- Guardianes externos que sondean el recurso desde fuera del clúster de Service Fabric (por ejemplo, un servicio de supervisión de tipo Gomez).
Desde el principio, los componentes de Service Fabric informan del estado de todas las entidades del clúster. Los informes de mantenimiento del sistema proporcionan visibilidad en el clúster y funcionalidad de la aplicación, además de marcar problemas a través del estado. Para aplicaciones y servicios, los informes de estado del sistema comprueban que las entidades se implementan y que se comportan correctamente desde la perspectiva de Service Fabric en tiempo de ejecución. Los informes no proporcionan ninguna supervisión de estado de la lógica de negocios del servicio ni detectan procesos que hayan dejado de responder. Para agregar información de estado específica a la lógica del servicio, implemente informes de estado personalizados en los servicios.
Service Fabric permite ver los informes de estado agregados al almacén de estado de varias formas:
- Service Fabric Explorer y otras herramientas de visualización.
- Consultas de estado (a través de PowerShell, CLI, API FabricClient de C# y API FabricClient de Java o API de REST).
- Consultas generales que devuelven una lista de entidades con el estado como una de las propiedades (a través de PowerShell, CLI, las API o REST).
Supervisión y diagnóstico
La supervisión y el diagnóstico son fundamentales para el desarrollo, la prueba y la implementación de aplicaciones y servicios en cualquier entorno. Las soluciones de Service Fabric funcionan mejor cuando diseña e implementa la supervisión y el diagnóstico que ayudan a asegurarse de que las aplicaciones y los servicios funcionen según lo previsto en un entorno de desarrollo local o en producción.
Los objetivos principales de la supervisión y diagnóstico son:
- Detectar y diagnosticar problemas de hardware y de infraestructura
- Detectar problemas de software y aplicaciones, y reducir el tiempo de inactividad del servicio
- Conocer el consumo de recursos y facilitar la toma de decisiones de operaciones
- Optimizar el rendimiento de la aplicación, el servicio y la infraestructura
- Generar información de la empresa e identificar áreas de mejora
El flujo de trabajo general de la supervisión y el diagnóstico consta de tres pasos:
- Generación de eventos: incluye eventos (registros, seguimientos y eventos personalizados) en los niveles de infraestructura (clúster), plataforma y aplicación o servicio.
- Agregación de eventos: es preciso recopilar y agregar los eventos generados antes de que se puedan mostrar.
- Análisis: los eventos se deben visualizar y estar accesibles en algún formato, para permitir analizarlos y mostrarlos cuando sea necesario.
Hay varios productos que abarcan las tres áreas, y puede elegir tecnologías diferentes para cada uno. Para obtener más información, lea Supervisión y diagnóstico para Azure Service Fabric.
Pasos siguientes
- Aprenda a crear un clúster en Azure o un clúster independiente en Windows.
- Intente crear un servicio con los modelos de programación Reliable Services o Reliable Actors.
- Más información sobre la migración desde Cloud Services.
- Más información acerca de la supervisión y el diagnóstico de servicios.
- Más información sobre las pruebas de aplicaciones y servicios.
- Más información sobre la administración y orquestación de recursos de clúster.
- Examine los ejemplos de Service Fabric.
- Más información sobre las opciones de soporte técnico de Service Fabric.
- Lea el blog del equipo para consultar artículos y anuncios.