Arquitectura de recuperación ante desastres de VMware a Azure: clásico
En este artículo se describe la arquitectura y los procesos usados al implementar la replicación, la conmutación por error y la recuperación de máquinas virtuales (VM) de VMware entre un sitio de VMware local y Azure en la recuperación ante desastres, mediante el servicio Azure Site Recovery: clásico.
Para más información sobre la arquitectura modernizada, consulte este artículo.
Componentes de la arquitectura
En la tabla y el gráfico siguientes se proporciona una visión general de los componentes que se usaron para la recuperación ante desastres de máquinas físicas o máquinas virtuales de VMware en Azure.
| Componente | Requisito | Detalles |
|---|---|---|
| Azure | Una suscripción a Azure, una cuenta de Azure Storage para almacenamiento en caché, un disco administrado y una red de Azure. | Los datos replicados desde las máquinas virtuales locales se almacenan en Azure Storage. Las máquinas virtuales de Azure se crean con los datos replicados cuando se ejecuta una conmutación por error desde el entorno local en Azure. Las máquinas virtuales de Azure se conectan a la red virtual de Azure cuando se crean. |
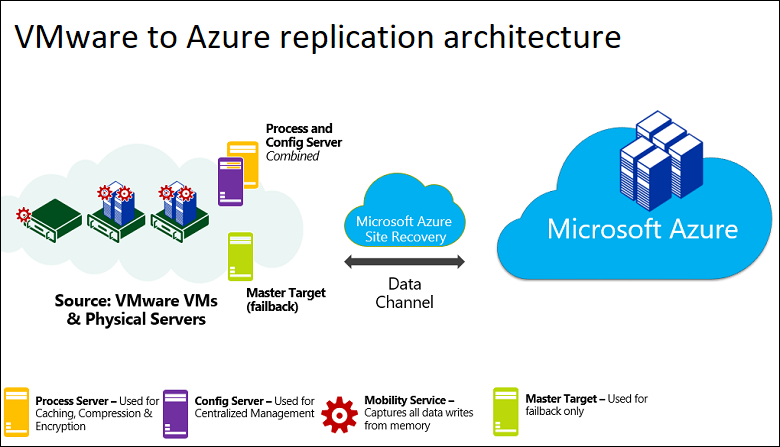
| Equipo del servidor de configuración | Una sola máquina local. Se recomienda ejecutarla como una máquina virtual de VMware que pueda implementarse desde una plantilla de OVF descargada. La máquina ejecuta todos los componentes locales de Site Recovery, incluido el servidor de configuración, el servidor de procesos y el servidor de destino maestro. |
Servidor de configuración: coordina las comunicaciones entre el entorno local y Azure, además de administrar la replicación de datos. Servidor de proceso: Se instala de forma predeterminada en el servidor de configuración. Recibe los datos de la replicación; los optimiza mediante almacenamiento en caché, compresión y cifrado, y los envía a Azure Storage. El servidor de procesos también instala Azure Site Recovery Mobility Service en las máquinas virtuales que se van a replicar y realiza la detección automática de las máquinas locales. A medida que crece la implementación, puede agregar más servidores de procesos independientes para controlar mayores volúmenes de tráfico de replicación. Servidor de destino principal: Se instala de forma predeterminada en el servidor de configuración. Controla los datos de replicación durante la conmutación por recuperación desde Azure. En el caso de las implementaciones de gran tamaño, puede agregar un servidor de destino maestro independiente adicional para la conmutación por recuperación. |
| Servidores de VMware | Las máquinas virtuales VMware se hospedan en servidores ESXi de vSphere locales. Se recomienda un servidor vCenter para administrar los hosts. | Durante la implementación de Site Recovery, se agregan servidores VMware al almacén de Recovery Services. |
| Máquinas replicadas | Mobility Service está instalado en cada una de las máquinas virtuales de VMware que se van a replicar. | Se recomienda permitir la instalación automática desde el servidor de procesos. Si lo desea, también puede instalar manualmente el servicio o usar un método de implementación automatizada, como Configuration Manager. |
Configuración de la conectividad de red saliente
Para que Site Recovery funcione de la forma esperada, debe modificar la conectividad de red saliente para permitir la replicación de su entorno.
Nota:
Site Recovery de máquinas VMware o físicas que usan la arquitectura clásica no admite el uso de un proxy de autenticación para controlar la conectividad de red. Lo mismo se admite al usar la arquitectura modernizada.
Conectividad de salida para las direcciones URL
Si usa un proxy de firewall basado en direcciones URL para controlar la conectividad de salida, debe permitir el acceso a ellas:
| Nombre | Comercial | Gobierno | Descripción |
|---|---|---|---|
| Storage | *.blob.core.windows.net |
*.blob.core.usgovcloudapi.net |
Permite que los datos se puedan escribir desde la máquina virtual a la cuenta de almacenamiento de caché en la región de origen. |
| Microsoft Entra ID | login.microsoftonline.com |
login.microsoftonline.us |
Proporciona autorización y autenticación de las direcciones URL del servicio Site Recovery. |
| Replicación | *.hypervrecoverymanager.windowsazure.com |
*.hypervrecoverymanager.windowsazure.us |
Permite que la máquina virtual se comunique con el servicio Site Recovery. |
| Azure Service Bus | *.servicebus.windows.net |
*.servicebus.usgovcloudapi.net |
Permite que la máquina virtual escriba los datos de diagnóstico y supervisión de Site Recovery. |
A fin de que se filtre una lista exhaustiva de direcciones URL para la comunicación entre los servicios de Azure y la infraestructura de Azure Site Recovery, consulte la sección Requisitos de red del artículo sobre requisitos previos.
Proceso de replicación
Al habilitar la replicación para una VM, comienza la replicación inicial en el almacenamiento de Azure mediante la directiva de replicación especificada. Tenga en cuenta lo siguiente:
- Para las VM de VMware, la replicación es de nivel de bloque, casi continua, mediante el agente del servicio de movilidad que se ejecuta en la VM.
- Se aplica la configuración de directivas de replicación:
- Umbral de RPO. Esta configuración no afecta a la replicación. Ayuda con la supervisión. Se genera un evento y, opcionalmente, se envía un correo electrónico, si el RPO actual supera el límite del umbral que especifique.
- Retención de punto de recuperación. Esta configuración especifica cuánto tiempo atrás quiere ir cuando se produce una interrupción. La retención máxima es de 15 días en disco administrado.
- Instantáneas coherentes con la aplicación. Las instantáneas coherentes con la aplicación pueden tomarse cada 1 a 12 horas, según las necesidades de la aplicación. Son instantáneas de blob de Azure estándar. El agente de movilidad que se ejecuta en una VM solicita una instantánea de VSS de acuerdo con esta configuración, y marca ese momento como punto coherente con la aplicación en el flujo de replicación.
Nota:
Un período de retención de punto de recuperación alto puede tener una implicación en el costo de almacenamiento, ya que quizás se deban guardar más puntos de recuperación.
El tráfico se replica en los puntos de conexión públicos de Azure Storage a través de Internet. Como alternativa, puede usar Azure ExpressRoute con emparejamiento de Microsoft. No se admite la replicación del tráfico entre un sitio local y Azure a través de una red privada virtual (VPN) de sitio a sitio.
La operación de replicación inicial garantiza que los datos completos en el equipo al momento de habilitar la replicación se envían a Azure. Una vez terminada la replicación inicial, comienza la de los cambios incrementales en Azure. Los cambios marcados para una máquina se envían al servidor de procesos.
Comunicación se realiza como se indica a continuación:
- Las máquinas virtuales se comunican con el servidor de configuración local en el puerto HTTPS 443 entrante para la administración de la replicación.
- El servidor de configuración organiza la replicación con Azure a través del puerto HTTPS 443 saliente.
- Las máquinas virtuales envían datos de replicación al servidor de procesos (que se ejecuta en la máquina del servidor de configuración) en el puerto HTTPS 9443 entrante. Este puerto se puede modificar.
- El servidor de procesos recibe los datos de la replicación, los optimiza, los cifra y los envía a Azure Storage a través del puerto 443 de salida.
Los datos de replicación registran el primer aterrizaje en una cuenta de almacenamiento en caché de Azure. Estos registros se procesan y los datos se almacenan en un disco administrado de Azure (denominado disco de inicialización de Azure Site Recovery). Los puntos de recuperación se crean en ese disco.

Proceso de resincronización
- En ocasiones, durante la replicación inicial o mientras se transfieren los cambios diferenciales, puede haber problemas de conectividad de red entre la máquina de origen y el servidor de proceso, o entre el servidor de procesos y Azure. Cualquiera de estas situaciones puede producir errores momentáneos en la transferencia de datos a Azure.
- Para evitar problemas con la integridad de datos y minimizar los costos de transferencia de datos, Site Recovery marca una máquina para la resincronización.
- Un equipo también se puede marcar para la resincronización en situaciones como las siguientes para mantener la coherencia entre la máquina de origen y los datos almacenados en Azure.
- Si un equipo sufre un apagado forzado
- Si un equipo sufre cambios de configuración, como el cambio de tamaño de disco (modificar el tamaño del disco de 2 TB a 4 TB)
- La resincronización solo envía los datos diferenciales a Azure. La transferencia de datos entre el entorno local y Azure se minimiza mediante el cálculo de sumas de comprobación de los datos entre la máquina de origen y los datos almacenados en Azure.
- De forma predeterminada, la resincronización está programada para ejecutarse automáticamente fuera del horario de oficina. Si no desea esperar para volver a sincronizar fuera del horario de forma predeterminada, puede volver a sincronizar una máquina virtual manualmente. Para ello, vaya a Azure Portal y seleccione la máquina virtual >Volver a sincronizar.
- Si se produce un error en la resincronización predeterminada fuera del horario de oficina y es necesaria una intervención manual, se genera un error en el equipo específico en Azure Portal. Puede resolver el error y desencadenar la resincronización de forma manual.
- Una vez finalizada la resincronización, se reanudará la replicación de los cambios diferenciales.
Administración de las directivas de replicación
- Al habilitar la replicación puede personalizar la configuración de las directivas de replicación.
- Puede crear una directiva de replicación en cualquier momento y aplicarla al habilitar la replicación.
Coherencia con múltiples máquinas virtuales
Si desea que varias máquinas se repliquen al mismo tiempo y estas comparten puntos de recuperación coherentes frente a bloqueos y coherentes con la aplicación al conmutar por error, puede reunirlas en un grupo de replicación. La coherencia entre varias máquinas virtuales afecta al rendimiento de la carga de trabajo y solo debe usarse para las que ejecuten cargas de trabajo que necesiten coherencia en todas las máquinas.
Instantáneas y puntos de recuperación
Los puntos de recuperación se crean a partir de instantáneas de los discos de máquina virtual tomadas en un momento determinado. Al conmutar por error una máquina virtual se usa un punto de recuperación para restaurarla en la ubicación de destino.
Al conmutar por error, normalmente queremos garantizar que la máquina virtual empieza sin daños ni pérdida de datos y que los datos de la máquina virtual son coherentes para el sistema operativo y para las aplicaciones que se ejecutan en ella. Esto depende del tipo de instantánea realizada.
Site Recovery toma instantáneas como sigue:
- Site Recovery toma instantáneas coherentes frente a bloqueos de datos de forma predeterminada e instantáneas coherentes con la aplicación si especifica una frecuencia para ello.
- Los puntos de recuperación se crean a partir de las instantáneas y se almacenan según la configuración de retención establecida en la directiva de replicación.
Coherencia
La siguiente tabla explica los diferentes tipos de coherencia.
Coherente frente a bloqueos
| Descripción | Detalles | Recomendación |
|---|---|---|
| Una instantánea coherente frente a bloqueos captura los datos que estaban en el disco cuando se tomó la instantánea. No incluye nada de la memoria. Contiene el equivalente de los datos de disco que estuvieran presentes si se bloqueó la máquina virtual o se extrajo el cable de alimentación del servidor en el momento en que se tomara la instantánea. Un punto de recuperación coherente frente a bloqueos no garantiza la coherencia de datos para el sistema operativo o las aplicaciones de la máquina virtual. |
Site Recovery crea puntos de recuperación coherentes frente a bloqueos cada cinco minutos de forma predeterminada. No se puede modificar esta configuración. |
Hoy en día, la mayoría de las aplicaciones se pueden recuperar bien a partir de instantáneas coherentes frente a bloqueos. Los puntos de replicación coherentes frente a bloqueos suelen bastar para la replicación de sistemas operativos y aplicaciones de tipo servidor DHCP y de impresión. |
Coherente con la aplicación
| Descripción | Detalles | Recomendación |
|---|---|---|
| Se crean puntos de recuperación coherentes con la aplicación a partir de instantáneas coherentes con la aplicación. Una instantánea consistente entre aplicaciones contiene toda la información en una instantánea consistente entre bloqueos, además de todos los datos en memoria y las transacciones en curso. |
Las instantáneas coherentes con la aplicación usan el servicio Volume Shadow Copy (VSS): 1) Azure Site Recovery usa el método de copia de seguridad de solo copia (VSS_BT_COPY) que no cambia la hora de la copia de seguridad ni el número de secuencia del registro de transacciones de Microsoft SQL. 2) Cuando se inicia una instantánea, VSS realiza una operación de copia en escritura (COW) en el volumen. 3) Antes de realizar la operación COW, VSS informa a todas las aplicaciones de la máquina que deben vaciar los datos en memoria en el disco. 4) A continuación, VSS permite que la aplicación de recuperación ante desastres/copia de seguridad (en este caso, Site Recovery) lea los datos de la instantánea y continúe. |
Se toman instantáneas coherentes con la aplicación de acuerdo con la frecuencia que especifique. Esta frecuencia debe ser siempre menor que la establecida para retención de los puntos de recuperación. Por ejemplo, si retiene puntos de recuperación con la configuración predeterminada de 24 horas, debe establecer la frecuencia en menos de 24 horas. Son más complejas y tardan más tiempo en completarse que las instantáneas coherentes frente a bloqueos. Afectan el rendimiento de las aplicaciones que se ejecutan en la máquina virtual habilitada para la replicación. |
Proceso de conmutación por error y conmutación por recuperación
Una vez que la replicación está configurada y tras ejecutar una exploración de la recuperación ante desastres (conmutación por error de prueba) para comprobar que todo funciona según lo previsto, puede ejecutar la conmutación por error y la conmutación por recuperación, según sea necesario.
Va a conmutar por error una única máquina o crear planes de recuperación para conmutar por error varias máquinas virtuales. La ventaja de un plan de recuperación en lugar de la conmutación por error de una única máquina incluye:
- Puede modelar las dependencias de aplicaciones con la inclusión de todas las máquinas virtuales por la aplicación en un único plan de recuperación.
- Puede agregar scripts, runbooks de Azure y ponerlos en pausa para acciones manuales.
Después de desencadenar la conmutación por error inicial, debe confirmarla para que se inicie. Para ello, acceda a la carga de trabajo desde la máquina virtual de Azure.
Cuando el sitio local principal esté disponible de nuevo, podrá prepararse para la conmutación por recuperación. Para realizar la conmutación por recuperación, debe configurar una infraestructura de conmutación por recuperación, que incluya:
- Servidor de procesos temporal de Azure: para realizar una conmutación por recuperación desde Azure, debe configurar una máquina virtual de Azure para que actúe como servidor de procesos y controle la replicación desde Azure. Dicha máquina virtual se puede eliminar cuando finalice la conmutación por recuperación.
- Conexión VPN: para la conmutación por recuperación, necesita una conexión VPN o ExpressRoute desde la red de Azure al sitio local.
- Servidor de destino maestro independiente: de manera predeterminada, el servidor de destino maestro que se instaló con el servidor de configuración en la máquina virtual local de VMware controla la conmutación por recuperación. Si necesita realizar la conmutación por recuperación en grandes volúmenes de tráfico, debe configurar un servidor de destino maestro local diferente para este propósito.
- Directiva de conmutación por recuperación: para replicar de nuevo en el sitio local, necesita una directiva de conmutación por recuperación. Esta directiva se crea automáticamente cuando crea una directiva de replicación entre el entorno local y Azure.
Una vez instalados los componentes, la conmutación por recuperación se produce en tres acciones:
- Fase 1 Vuelva a proteger las máquinas virtuales de modo que realicen la replicación desde Azure de vuelta a las máquinas virtuales VMware locales.
- Fase 2: Ejecute una conmutación por error en el sitio local.
- Fase 3: Una vez que las cargas de trabajo han conmutado por recuperación, debe habilitar de nuevo la replicación de las máquinas virtuales locales.

Pasos siguientes
Siga este tutorial para habilitar la replicación de VMware en Azure.