Nota
L'accés a aquesta pàgina requereix autorització. Podeu provar d'iniciar la sessió o de canviar els directoris.
L'accés a aquesta pàgina requereix autorització. Podeu provar de canviar els directoris.
Blob Storage ya es compatible con el protocolo Network File System (NFS) 3.0. De este modo, proporciona compatibilidad con el sistema de archivos de Linux en cuanto a los precios y la escala de almacenamiento de objetos, y permite a los clientes de Linux montar un contenedor en el Blob Storage desde una máquina virtual (VM) de Azure o un equipo local.
Siempre es un reto ejecutar cargas de trabajo heredadas a gran escala, como la informática de alto rendimiento (HPC) en la nube. Una razón es que las aplicaciones suelen usar protocolos de archivos tradicionales, como el sistema de archivos de red (NFS) para acceder a los datos. Además, los servicios nativos de almacenamiento en la nube se centran en el almacenamiento de objetos que tienen un espacio de nombres plano y metadatos extensivos, en lugar de sistemas de archivos que proporcionan un espacio de nombres jerárquico y operaciones de metadatos eficientes.
Blob Storage ahora admite un espacio de nombres jerárquico y, al combinarse con la compatibilidad con el protocolo NFS 3.0, Azure facilita la ejecución de aplicaciones heredadas además del almacenamiento de objetos en la nube a gran escala.
Aplicaciones y cargas de trabajo adecuadas para usar NFS 3.0 con Blob Storage
La característica de protocolo NFS 3.0 está optimizada para cargas de trabajo de alto rendimiento, a gran escala y con mucha lectura con E/S secuencial. Es ideal para escenarios que implican varios lectores y numerosos subprocesos en los que el rendimiento es más crítico que la latencia baja. Algunos ejemplos comunes son:
High-Performance Computing (HPC): los trabajos de HPC suelen implicar miles de núcleos que leen los mismos conjuntos de datos grandes simultáneamente. La característica de protocolo NFS 3.0 usa el rendimiento del almacenamiento de objetos para eliminar los cuellos de botella tradicionales del servidor de archivos. Ejemplos:
Secuenciación genómica: procesamiento de conjuntos de datos genómicos masivos.
Modelado de riesgos financieros: simulaciones de Monte Carlo sobre datos históricos.
Análisis sísmico: datos geoemicos para la exploración de petróleo y gas.
Previsión meteorológica: modelado de datos meteorológicos para la predicción climática y de tormentas.
Macrodatos y análisis (Data Lakes): muchas herramientas de análisis requieren directorios jerárquicos. BlobNFS (a través de Azure Data Lake Storage Gen2) ofrece esta estructura al tiempo que admite protocolos de archivos estándar. Ejemplos:
Aprendizaje automático: alimentación de datos de entrenamiento a clústeres de GPU mediante E/S de archivos estándar.
Log Analytics: agregación de registros de miles de orígenes.
Sistemas avanzados de asistencia para controladores (ADAS): los flujos de trabajo de ADAS producen petabytes de datos de sensor secuenciales, como nubes de punto LiDAR y fuentes de cámara de alta resolución, que deben ingerirse de forma eficaz y analizarse a escala para la simulación y el entrenamiento del modelo. Ejemplo:
- Almacenar secuencias de vídeo liDAR sin procesar y secuencias de vídeo de varias cámaras desde vehículos de prueba autónomos mediante NFS 3.0 y, a continuación, ejecutar simulaciones de reproducción a gran escala en miles de nodos de proceso para validar algoritmos de percepción.
Media & Entertainment - las granjas de renderizado necesitan un gran acceso a grandes bibliotecas de recursos. NFS 3.0 sobre blob proporciona una interfaz de archivos para herramientas de renderizado heredadas que requieren rutas de archivo. Ejemplos:
Representación de vídeo: nodos distribuidos que leen recursos de origen.
Transcodificación: convertir archivos de vídeo sin procesar de gran tamaño en formatos de streaming.
Copia de seguridad de base de datos - esta característica ofrece un destino objetivo NFS 3.0 rentable sin conectores complejos ni instantáneas costosas. Ejemplos:
- Oracle RMAN puede escribir piezas de copia de seguridad grandes directamente para el archivado a largo plazo y habilitar la restauración directa desde cualquier máquina virtual Linux montada en NFS.
Cuándo no usar NFS 3.0 con Blob Storage
Evite los recursos compartidos de archivos de uso general o las cargas de trabajo transaccionales debido a las características de almacenamiento de objetos:
| Tipo de carga de trabajo | Reason | Mejor alternativa |
|---|---|---|
| Bases de datos transaccionales | Requiere bloqueo pormenorizados, latencia de submilisegundos y escrituras aleatorias frecuentes. | Managed Disks o Azure NetApp Files o Azure Files |
| edición de archivos In-Place | La edición de archivos obliga a reescribir completamente los blobs, lo que hace que las operaciones sean ineficientes. | Azure Files |
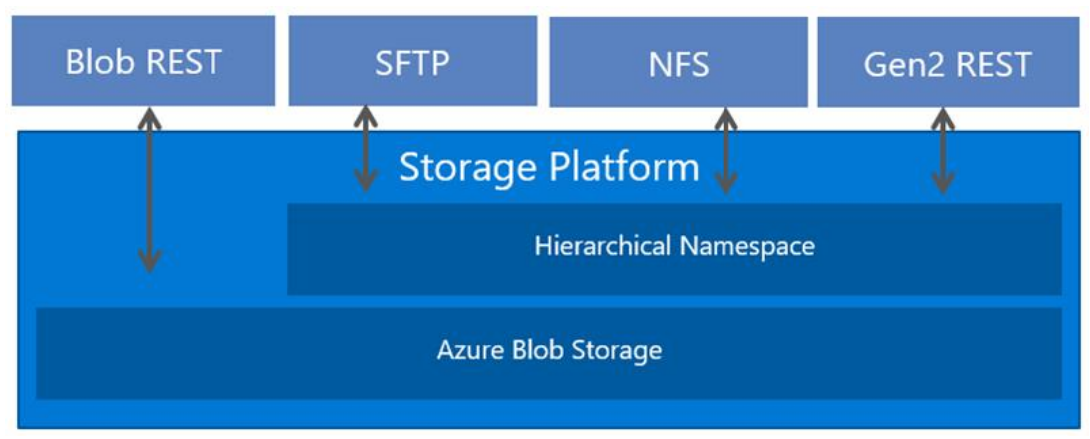
NFS 3.0 y el espacio de nombres jerárquico
La compatibilidad con el protocolo NFS 3.0 requiere que los blobs se organicen en un espacio de nombres jerárquico. Puede habilitar un espacio de nombres jerárquico al crear una cuenta de almacenamiento. La capacidad de usar un espacio de nombres jerárquico se introdujo con Azure Data Lake Storage. Organiza objetos (archivos) en una jerarquía de directorios y subdirectorios de la misma manera en que se organiza el sistema de archivos en el equipo. El espacio de nombres jerárquico se escala linealmente y no degrada el rendimiento ni la capacidad de datos. Los diferentes protocolos se extienden desde el espacio de nombres jerárquico. El protocolo NFS 3.0 es uno de los protocolos disponibles.
Datos almacenados como blobs en bloques
Cuando la aplicación realiza una solicitud mediante el protocolo NFS 3.0, esa solicitud se traduce en una combinación de operaciones de blobs en bloques. Por ejemplo, las solicitudes de llamada a procedimiento remoto (RPC) de lectura NFS 3.0 se traducen en la operación Obtener blob. Las solicitudes RPC de escritura de NFS 3.0 se convierten en una combinación de Get Block List, Put Block y Put Block List.
Los blobs en bloques están optimizados para procesar de manera eficaz grandes cantidades de datos de lectura intensiva. Los blobs en bloques están formados por bloques. Cada bloque se identifica mediante un identificador de bloque. Un blob en bloques puede incluir hasta 50 000 bloques. Cada bloque de un blob en bloques puede tener un tamaño diferente, hasta el tamaño máximo permitido para la versión del servicio que usa la cuenta.
Flujo de trabajo general: montaje de un contenedor de cuenta de almacenamiento
Los clientes de Linux pueden montar un contenedor en Blob Storage desde una máquina virtual (VM) de Azure o un equipo local. Para montar un contenedor de una cuenta de almacenamiento, debe hacer lo siguiente.
Cree una instancia de Azure Virtual Network (VNet).
Configure la seguridad de red.
Cree y configure una cuenta de almacenamiento que acepte tráfico solo desde la red virtual.
Cree un contenedor en la cuenta de almacenamiento.
Monte el contenedor.
Para obtener instrucciones paso a paso, consulte Montaje de Blob Storage con el protocolo Network File System (NFS) 3.0.
Seguridad de las redes
El tráfico debe originarse desde una red virtual. Una red virtual permite a los clientes conectarse de forma segura a su cuenta de almacenamiento. La única manera de proteger los datos en su cuenta es mediante una red virtual y otra configuración de seguridad de red. Cualquier otra herramienta que se usa para proteger los datos, incluida la autorización de clave de cuenta, la seguridad de Microsoft Entra y las listas de control de acceso (ACL), no se puede usar para autorizar una solicitud NFS 3.0.
Para más información, consulte Recomendaciones de seguridad de red para Blob Storage.
Conexiones de red compatibles
Un cliente puede conectarse a través de un punto de conexión privado o público y desde cualquiera de las siguientes ubicaciones de red:
La red virtual que configure para la cuenta de almacenamiento.
En este artículo, nos referiremos a esa red virtual como red virtual principal. Para más información, consulte Concesión de acceso desde una red virtual.
Una red virtual emparejada que se encuentre en la misma región que la red virtual principal.
Tendrá que configurar la cuenta de almacenamiento para permitir el acceso a esta red virtual emparejada. Para más información, consulte Concesión de acceso desde una red virtual.
Una red local que esté conectada a la red virtual principal mediante VPN Gateway o una puerta de enlace de ExpressRoute.
Para más información, consulte Configuración del acceso desde redes locales.
Una red local que esté conectada a una red emparejada.
Esta acción puede realizarse mediante VPN Gateway o una puerta de enlace de ExpressRoute junto con tránsito de puerta de enlace.
Importante
El protocolo NFS 3.0 usa los puertos 111 y 2048. Si se va a conectar desde una red local, asegúrese de que el cliente permite la comunicación saliente a través de esos puertos. Si ha concedido acceso a redes virtuales específicas, asegúrese de que los grupos de seguridad de red asociados a esas redes virtuales no contengan reglas de seguridad que bloqueen la comunicación entrante a través de esos puertos.
Limitaciones y problemas conocidos
Consulte el artículo Problemas conocidos para obtener una lista completa de problemas y limitaciones de la versión actual de NFS 3.0.
Precios
Consulte la página Precios de Azure Blob Storage para ver los costos de almacenamiento y transacciones de datos.