Nota
L'accés a aquesta pàgina requereix autorització. Podeu provar d'iniciar la sessió o de canviar els directoris.
L'accés a aquesta pàgina requereix autorització. Podeu provar de canviar els directoris.
Al igual que muchos otros servicios de Azure, Stream Analytics se usa mejor con otros servicios para crear una solución de extremo a otro más amplia. En este artículo se describen soluciones sencillas de Azure Stream Analytics y diversos patrones de arquitectura. Puede ampliar estos patrones para desarrollar soluciones más complejas. Los patrones que se describen en este artículo pueden usarse en una amplia variedad de escenarios. Encontrará ejemplos de patrones específicos del escenario en las arquitecturas de soluciones de Azure.
Crear un trabajo de Stream Analytics para impulsar la experiencia de paneles de control en tiempo real
Con Azure Stream Analytics, puede crear rápidamente paneles y alertas en tiempo real. Una solución sencilla ingiere eventos desde Event Hubs o IoT Hub y alimenta el panel de Power BI con un conjunto de datos de streaming. Para obtener más información, vea el tutorial detallado Analizar datos de llamadas fraudulentas con Stream Analytics y visualice los resultados en el panel de Power BI.
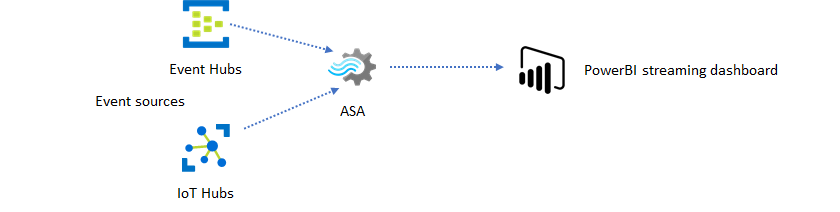
Puede compilar esta solución en tan solo unos minutos mediante Azure Portal. No es necesario codificar ampliamente. En su lugar, puede usar el lenguaje SQL para expresar la lógica de negocios.
Este patrón de solución ofrece la latencia más baja desde el origen del evento en el panel de Power BI en un explorador. Azure Stream Analytics es el único servicio de Azure con esta capacidad integrada.
Uso de SQL para el panel
El panel de Power BI ofrece una baja latencia, pero no se puede usar para generar informes de Power BI completos. Un patrón de informes común consiste en generar primero la salida de los datos en SQL Database. Luego, use el conector SQL de Power BI para consultar SQL en busca de los datos más recientes.
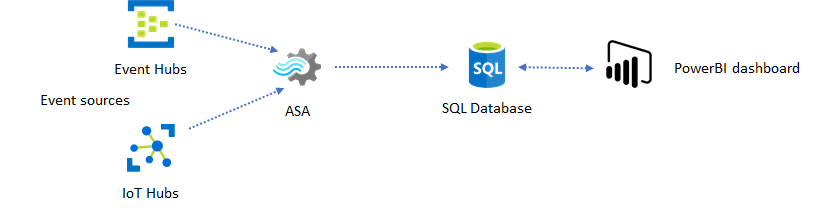
El uso de SQL Database ofrece mayor flexibilidad, pero a costa de una latencia ligeramente mayor. Esta solución es óptima para los trabajos con requisitos de latencia mayores que un segundo. Al usar este método, puede maximizar las capacidades de Power BI para segmentar y desglosar aún más los datos para los informes y disponer de muchas más opciones de visualización. También obtendrá la flexibilidad de usar otras soluciones de panel, como Tableau.
SQL no es un almacén de datos de alto rendimiento. El rendimiento máximo de SQL Database en Azure Stream Analytics es actualmente de aproximadamente 24 MB/s. Si los orígenes de evento de la solución generan datos a mayor velocidad, tendrá que usar la lógica de procesamiento de Stream Analytics para reducir la velocidad de salida a SQL. Puede usar técnicas, como el filtrado, agregados en ventanas, coincidencia de patrones con combinaciones temporales y funciones analíticas. La velocidad de salida a SQL puede optimizarse aún más mediante las técnicas que se describen en Salida de Azure Stream Analytics a Azure SQL Database.
Incorporación de información en tiempo real en la aplicación con la mensajería de eventos
El segundo uso más popular de Stream Analytics es generar alertas en tiempo real. En este patrón de solución, la lógica de negocios en Stream Analytics se puede usar para detectar patrones espaciales y temporales o anomalías y luego generar señales de alerta. Sin embargo, a diferencia de la solución de panel donde Stream Analytics usa Power BI como un punto de conexión preferido, puedes utilizar otros receptores de datos intermedios. Estos receptores incluyen Event Hubs, Service Bus y Azure Functions. Como el generador de la aplicación, debe decidir qué receptor de datos funciona mejor para su escenario.
Para generar alertas en el flujo de trabajo de negocio existente, se debe implementar una lógica de consumidor de eventos descendente. Dado que puede implementar lógica personalizada en Azure Functions, Azure Functions es la forma más rápida para realizar esta integración. Encontrará un tutorial para usar Azure Function como la salida de un trabajo de Stream Analytics en Ejecución de Azure Functions desde trabajos de Azure Stream Analytics. Azure Functions también admite varios tipos de notificaciones, incluidos texto y correo electrónico. Para este tipo de integración, también se puede usar Logic Apps, con Event Hubs entre Stream Analytics y Logic Apps.
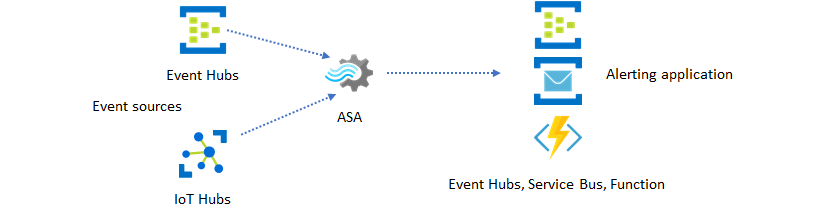
Por otro lado, el servicio Azure Event Hubs ofrece el punto de integración más flexible. Muchos otros servicios, como Azure Data Explorer, pueden consumir eventos de Event Hubs. Los servicios se pueden conectar directamente a los receptores de Event Hubs desde Azure Stream Analytics para completar la solución. Event Hubs también es el agente de mensajería de más alto rendimiento disponible en Azure para estos escenarios de integración.
Sitios web y aplicaciones dinámicas
Puede crear visualizaciones personalizadas en tiempo real, como visualización de mapas o panel de control, mediante Azure Stream Analytics y Azure SignalR Service. Cuando se usa SignalR, los clientes web se pueden actualizar y mostrar contenido dinámico en tiempo real.
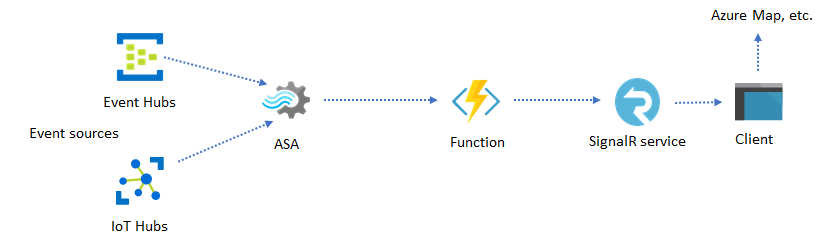
Incorporación de información en tiempo real en la aplicación a través de almacenes de datos
La mayoría de los servicios web y aplicaciones web de hoy en día usan un modelo de solicitud y respuesta para procesar la capa de presentación. El patrón de solicitud y respuesta es fácil de crear y se puede escalar fácilmente con un tiempo de respuesta bajo mediante almacenes front-end sin estado y escalables, como Azure Cosmos DB.
Un volumen de datos elevado suele crear cuellos de botella de rendimiento en un sistema basado en CRUD. El patrón de solución aprovisionamiento de eventos se usa para resolver los cuellos de botella de rendimiento. Los patrones y la información temporales también son difíciles e ineficaces de extraer de un almacén de datos tradicional. Las aplicaciones modernas impulsadas por datos de alto volumen suelen adoptar una arquitectura basada en el flujo de datos. Azure Stream Analytics como el motor de proceso para los datos en movimiento es una pieza clave de esa arquitectura.
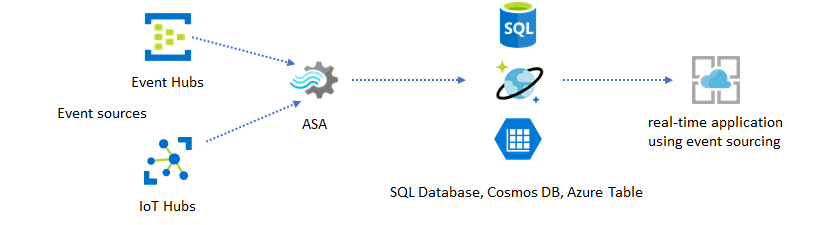
En este patrón de solución, los eventos se procesan y agregan en almacenes de datos mediante Azure Stream Analytics. La capa de aplicación interactúa con los almacenes de datos mediante el modelo tradicional de solicitud y respuesta. Debido a la capacidad de Stream Analytics de procesar un gran número de eventos en tiempo real, la aplicación es altamente escalable sin tener que ampliar la capa de almacén de datos de forma masiva. La capa de almacén de datos es esencialmente una vista materializada en el sistema. En Salida de Azure Stream Analytics a Azure Cosmos DB se describe cómo se usa Azure Cosmos DB como una salida de Stream Analytics.
En las aplicaciones reales donde la lógica de procesamiento es compleja y existe la necesidad de actualizar determinadas partes de la lógica de forma independiente, se pueden crear varios trabajos de Stream Analytics junto con Event Hubs como agente intermediario de eventos.
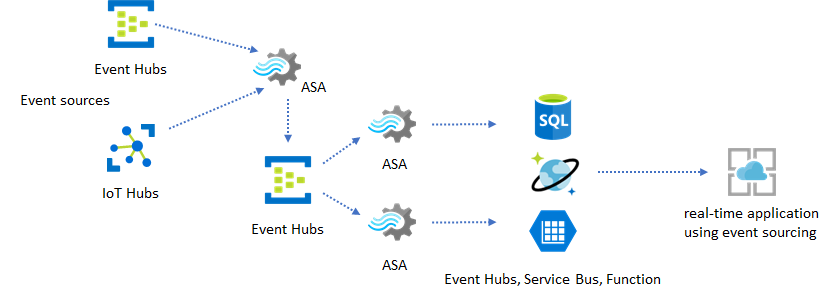
Este patrón mejora la resistencia y facilidad de uso del sistema. Sin embargo, aunque Stream Analytics garantiza un procesamiento de exactamente una vez, hay una pequeña posibilidad de que eventos duplicados terminen en los Event Hubs intermedios. Es importante para el trabajo de Stream Analytics descendente depurar los eventos mediante claves de lógica en una ventana de retrospectiva. Para más información sobre la entrega de eventos, consulte la referencia Garantías de entrega de eventos.
Uso de datos de referencia para la personalización de la aplicación
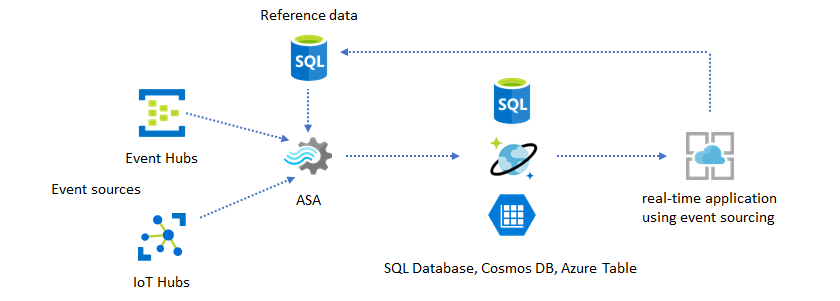
La característica de datos de referencia de Azure Stream Analytics está diseñada específicamente para la personalización del usuario final, como las alertas de umbral, el procesamiento de reglas y las geovallas. La capa de aplicación puede aceptar los cambios de parámetro y almacenarlos en SQL Database. El trabajo de Stream Analytics periódicamente consulta la base de datos en busca de cambios y hace que los parámetros de personalización sean accesibles a través de una combinación de datos de referencia. Para más información sobre cómo usar los datos de referencia para la personalización de la aplicación, consulte Datos de referencia SQL y Combinación de datos de referencia.
Este patrón también se puede usar para implementar un motor de reglas donde se definen los umbrales de las reglas de los datos de referencia. Para más información sobre las reglas, consulte Procesar reglas configurables basadas en umbrales en Azure Stream Analytics.
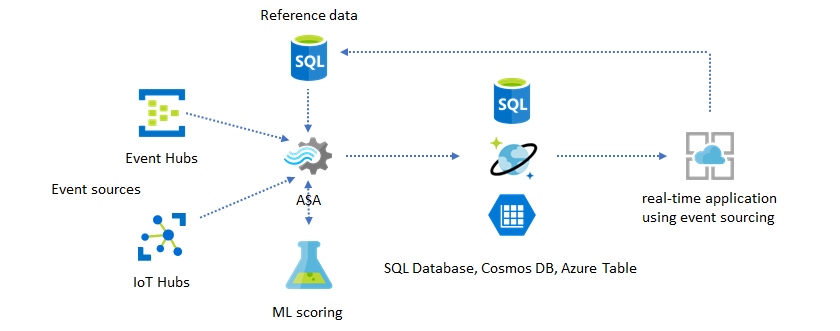
Añade aprendizaje automático a tus perspectivas en tiempo real
El modelo de detección de anomalías integrado de Azure Stream Analytics es una manera cómoda de introducir el aprendizaje automático a la aplicación en tiempo real. Para obtener una gama más amplia de necesidades de Machine Learning, consulte Integración de Azure Stream Analytics con Azure Machine Learning. Puede implementar modelos desde Azure Machine Learning y llamarlos como funciones definidas por el usuario (UDF) en las consultas de Stream Analytics.
Para los usuarios avanzados que desean incorporar el entrenamiento y la puntuación en línea en la misma canalización de Stream Analytics, consulte este ejemplo de cómo hacerlo con regresión lineal.
Almacenamiento de datos en tiempo real
Otro patrón común es el almacenamiento de datos en tiempo real, también conocido como almacén de datos de streaming. Además de los eventos que llegan a Event Hubs e IoT Hub desde la aplicación, Azure Stream Analytics que se ejecutan en IoT Edge puede usarse para satisfacer las necesidades de limpieza de datos, reducción de datos y almacenamiento y reenvío de datos. Stream Analytics que se ejecuta en IoT Edge puede manejar de manera eficiente los problemas de limitación de ancho de banda y conectividad en el sistema. Stream Analytics puede admitir velocidades de rendimiento de hasta 200 MB/s al escribir en Azure Synapse Analytics.
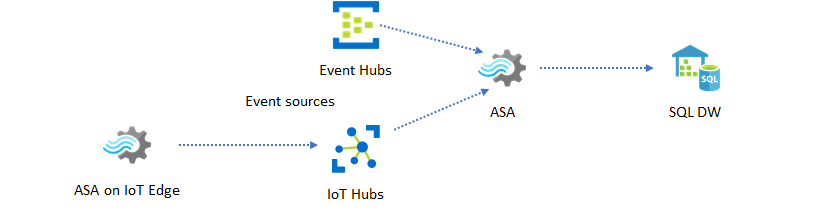
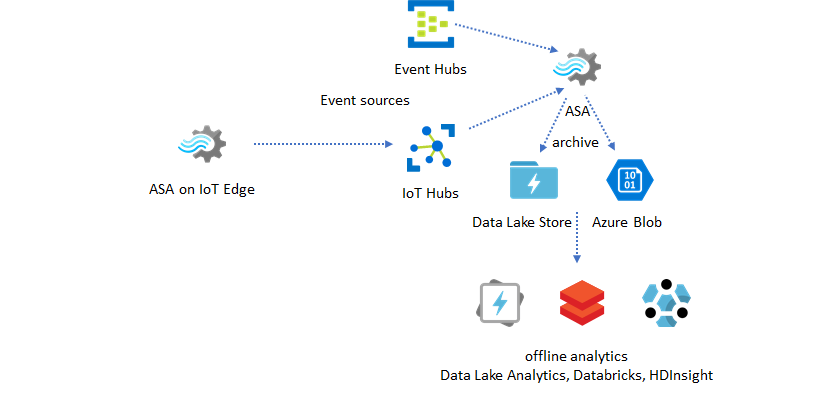
Archivado de datos en tiempo real para el análisis
La mayoría de las actividades de ciencia de datos y análisis aún se realizan offline. Con Azure Stream Analytics, se pueden archivar datos a través de la salida de Azure Data Lake Store Gen2 y formatos de salida Parquet. Esta funcionalidad elimina la fricción para alimentar datos directamente en Azure Synapse Analytics, Azure Databricks, Microsoft Fabric y Azure HDInsight. En esta solución, Azure Stream Analytics se usa como un motor de extracción, transformación y carga de datos (ETL) casi en tiempo real. Puede explorar los datos archivados en Data Lake mediante distintos motores de proceso.
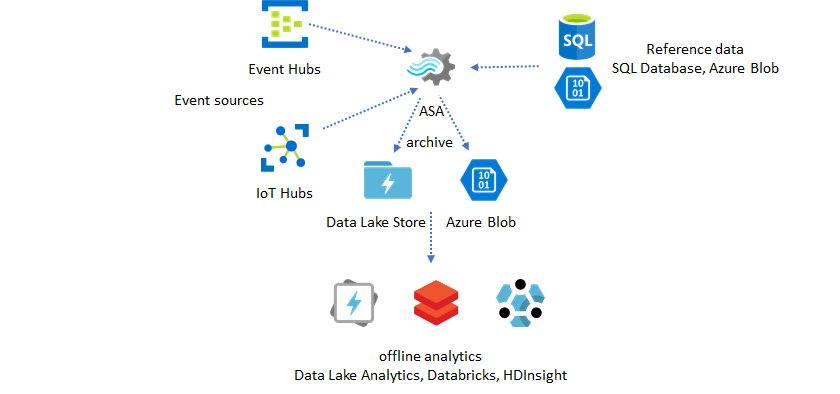
Uso de datos de referencia para el enriquecimiento
Con frecuencia, el enriquecimiento de datos es un requisito para los motores de ETL. Azure Stream Analytics admite el enriquecimiento de datos con datos de referencia desde SQL Database y Azure Blob Storage. El enriquecimiento de datos se puede realizar para los datos que llegan a Azure Data Lake y Azure Synapse Analytics.
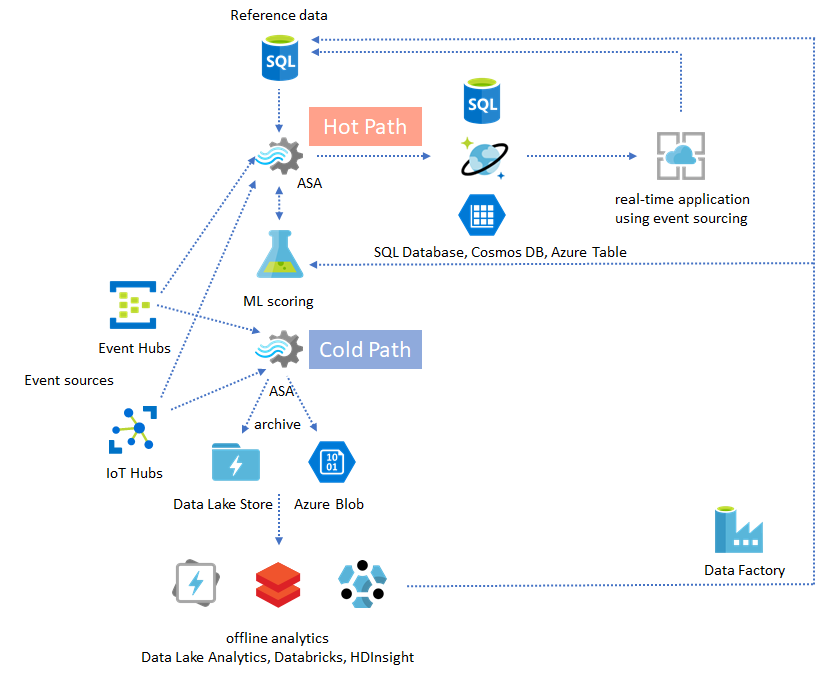
Operativizar los conocimientos a partir de datos archivados
Si combina el patrón de análisis en modo sin conexión con el patrón de la aplicación casi en tiempo real, puede crear un bucle de retroalimentación. El bucle de comentarios permite que la aplicación se ajuste automáticamente para cambiar los patrones en los datos. Este bucle de retroalimentación puede ser tan sencillo como cambiar el valor del umbral para las alertas, o tan complejo como el reentrenamiento de modelos de aprendizaje automático. Se puede aplicar la misma arquitectura de solución a ambos trabajos ASA que se ejecutan en la nube y en IoT Edge.
Integración de Apache Kafka
Stream Analytics admite Apache Kafka como entrada y salida a través de Azure Event Hubs con el punto de conexión de Kafka. Este patrón habilita:
- Migración desde arquitecturas basadas en Kafka existentes a Azure
- Escenarios híbridos que conectan clústeres de Kafka locales a Azure
- Integración con las herramientas y conectores del ecosistema de Apache Kafka
Salida de Delta Lake para arquitecturas de almacén de lago de datos
Para arquitecturas modernas de Lakehouse, Stream Analytics puede escribir directamente en formato Delta Lake en Azure Data Lake Storage Gen2. Delta Lake proporciona:
- Transacciones ACID para una ingesta confiable de datos
- Aplicación y evolución del esquema
- Capacidades de viaje en el tiempo para el control de versiones de datos
- Acceso unificado a datos por lotes y streaming
Elección del patrón correcto
Use esta tabla para ayudar a seleccionar el patrón adecuado para su escenario:
| Escenario | Patrón recomendado | Ventaja clave |
|---|---|---|
| Paneles en tiempo real | Conjunto de datos de streaming de Power BI | Latencia más baja |
| Informes complejos | SQL Database + Power BI | Funcionalidades completas de BI |
| Alertas activadas por eventos | Event Hubs + Azure Functions | Integración flexible |
| Análisis de Data Lake | Salida de Delta Lake | Transacciones ACID |
| Cargas de trabajo de Kafka | Punto de conexión de Kafka de Event Hubs | Compatibilidad de protocolos |
Cómo supervisar trabajos de Azure Stream Analytics (ASA)
Un trabajo de Azure Stream Analytics se puede ejecutar las 24 horas, los 7 días de la semana, para procesar eventos entrantes continuamente en tiempo real. La garantía de disponibilidad es fundamental para el estado general de la aplicación. Si bien Stream Analytics es el único servicio de análisis de streaming del sector que ofrece una garantía de disponibilidad del 99,9%, aún puede producirse cierto nivel de tiempo de inactividad. A lo largo de los años, Stream Analytics ha introducido métricas, registros y estados de trabajo para reflejar el estado de los trabajos. Todos ellos se muestran a través del servicio Azure Monitor y se pueden exportar a un área de trabajo de Log Analytics para un análisis más profundo. Para más información, consulte Supervisión del trabajo de Stream Analytics con Azure Portal.
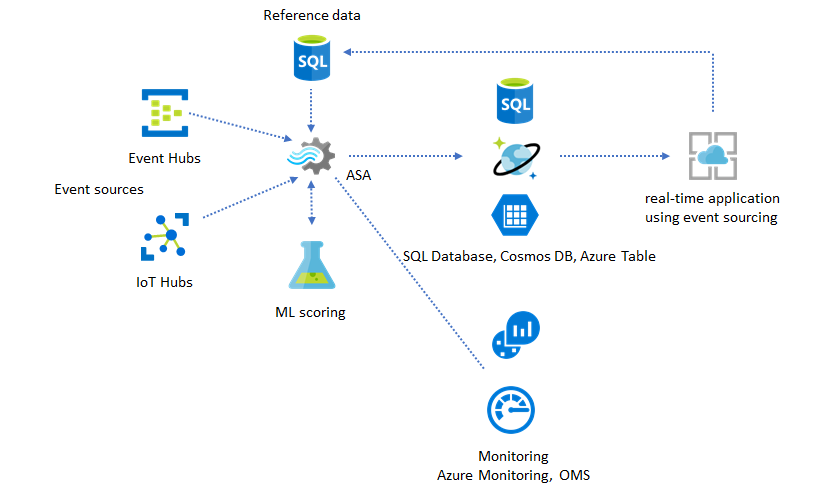
Hay dos elementos clave que se deben supervisar:
-
En primer lugar y ante todo, debe asegurarse de que el trabajo esté en ejecución. Si el trabajo no está en el estado de ejecución, no se generan nuevas métricas ni logs. Los trabajos pueden cambiar a un estado de error por diversos motivos, como por ejemplo, un uso elevado de la unidad de almacenamiento (es decir, se está quedando sin recursos).
Métricas de retraso de marca de agua
Esta métrica refleja cuán lejos se encuentra el procesamiento de canalización del tiempo de reloj (segundos). Parte del retraso se atribuye a la lógica de procesamiento inherente. Como resultado, la supervisión de la tendencia creciente es mucho más importante que la supervisión del valor absoluto. La demora en estado estable debe ser abordada por el diseño de la aplicación, no mediante supervisión o alertas.
Configuración de alertas y paneles
Configuración de alertas de Azure Monitor para la supervisión proactiva:
- Uso de SU : alerta cuando se mantiene por encima de 80% para evitar errores de trabajo
- Retraso en la marca de agua: alerta sobre el aumento de tendencias que indican un retraso en el procesamiento
- Eventos de entrada y salida : Supervisión de caídas repentinas que indican problemas de conectividad
- Errores en tiempo de ejecución : seguimiento de errores de deserialización y conversión de datos
Para una observabilidad centralizada, exporte métricas y registros de Stream Analytics a un área de trabajo de Log Analytics. Esto habilita:
- Correlación y análisis entre trabajos
- Consultas personalizadas de Kusto para diagnóstico profundo
- Integración con paneles de control y cuadernos de Azure
En caso de error, los registros de actividad y los registros de diagnóstico son los mejores lugares para empezar a buscar errores.
Construir aplicaciones resilientes y de misión crítica
Independientemente de la garantía del SLA de Azure Stream Analytics y el grado de cuidado con el que se ejecute la aplicación de un extremo a otro, se producen interrupciones. Si la aplicación es de misión crítica, debe estar preparado para interrupciones y poder recuperar sin contratiempos.
Para las aplicaciones de alerta, lo más importante es detectar la alerta siguiente. Al recuperar, puede elegir reiniciar el trabajo desde la hora actual, omitiendo las alertas anteriores. La semántica de hora de inicio del trabajo es por la primera hora de salida, no la primera hora de entrada. La entrada retrocede una cantidad de tiempo apropiada para garantizar que la primera salida a la hora especificada está completa y es correcta. No obtendrá agregados parciales y desencadenará alertas inesperadamente como resultado.
También puede optar por iniciar la salida desde una cierta cantidad de tiempo en el pasado. Las políticas de retención de Event Hubs e IoT Hub mantienen una cantidad razonable de datos para permitir procesar datos del pasado. El inconveniente es la rapidez con la que puede ponerse al día y comenzar a generar nuevas alertas oportunas. Los datos pierden su valor rápidamente con el tiempo, por lo que es importante ponerse al día rápidamente. Hay dos formas de ponerse al día rápidamente:
- Aprovisionar más recursos (SU) al ponerse al día.
- Reiniciar desde la hora actual.
Reiniciar desde la hora actual es fácil de hacer, con el inconveniente de que deja un vacío durante el procesamiento. Este método podría resultar adecuado para los escenarios de alerta, pero puede ser problemático para los escenarios de panel y no debería usarse en absoluto para los escenarios de archivado y almacenamiento de datos.
El aprovisionamiento de más recursos puede acelerar el proceso, pero el efecto de tener un aumento importante en la velocidad de procesamiento es complejo.
Realice pruebas para comprobar que su trabajo se pueda escalar a un mayor número de unidades de servicio. No todas las consultas son escalables. Deberá asegurarse de que la consulta sea paralelizada.
Asegúrese de que haya particiones suficientes en la instancia ascendente de Event Hubs o IoT Hub y que pueda agregar más unidades de procesamiento (TU) para escalar el rendimiento de entrada. Recuerde que cada unidad de rendimiento de Event Hubs tiene una velocidad de salida máxima de 2 MB/s.
Asegúrese de haber aprovisionado recursos suficientes en los receptores de salida (por ej., SQL Database, Azure Cosmos DB) para que no limiten el auge de salida, que a veces puede provocar un bloqueo del sistema.
Lo más importante es prever el cambio de velocidad de procesamiento, probar estos escenarios antes de entrar en producción y estar preparado para escalar el procesamiento correctamente durante el tiempo de recuperación de errores.
En el escenario extremo en el que se retrasan los eventos de entrada, es posible que se eliminen todos los eventos retrasados si ha aplicado al trabajo una ventana de llegada retrasada. La eliminación de los eventos puede parecer un comportamiento misterioso al principio. Sin embargo, si se tiene en cuenta que Stream Analytics es un motor de procesamiento en tiempo real, espera que los eventos entrantes estén cerca de la hora de reloj. Tiene que eliminar los eventos que infringen estas restricciones.
Arquitecturas Lambda o proceso de retrocarga
Afortunadamente, se puede usar el patrón de archivado de datos anterior para procesar estos eventos retrasados correctamente. La idea es que la tarea de archivado procese los eventos entrantes según su momento de llegada y archive los eventos en el intervalo de tiempo adecuado en Azure Blob o Azure Data Lake Store con la hora del evento. No importa lo tarde que llegue un evento, nunca se eliminará. Siempre llegará al cubo temporal oportuno. Durante la recuperación, es posible volver a procesar los eventos archivados y reponer los resultados en el almacén deseado. Esto es similar al modo en que se implementan los patrones lambda.
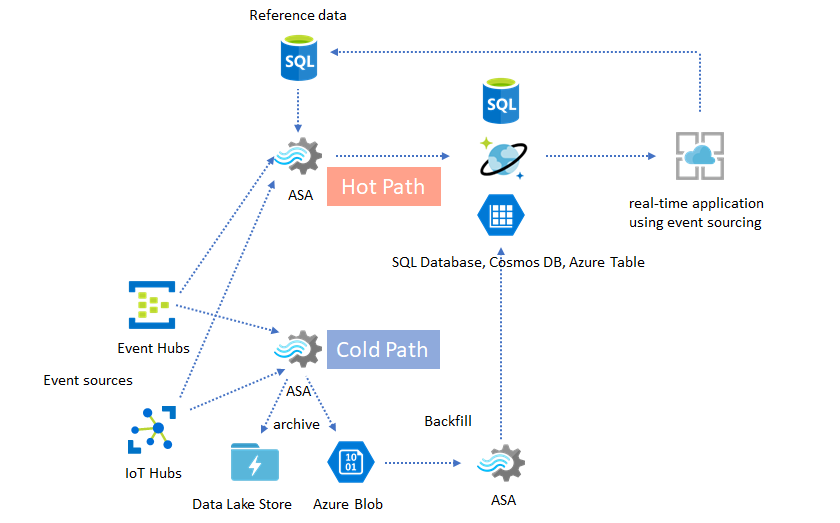
El proceso de reposición se debe realizar con un sistema de procesamiento por lotes sin conexión, que probablemente tiene un modelo de programación diferente que el de Azure Stream Analytics. Esto significa que tendrá que volver a implementar la lógica de procesamiento completo.
Para la reposición, aún es importante aprovisionar al menos temporalmente más recursos a los receptores de salida para aceptar un mayor rendimiento que durante el procesamiento de estado estable.
| Escenarios | Reiniciar inmediatamente | Reinicio desde la última hora de parada | Reinicio desde ahora + reposición con eventos archivados |
|---|---|---|---|
| Creación de paneles | Crea una brecha | Aceptar una interrupción breve | Utilice para una interrupción prolongada |
| Alertas | Aceptable | Aceptar una interrupción breve | No es necesario |
| Aplicación de aprovisionamiento de eventos | Aceptable | Aceptar una interrupción breve | Utilice para una interrupción prolongada |
| Almacenamiento de datos | Pérdida de datos | Aceptable | No es necesario |
| Análisis sin conexión | Pérdida de datos | Aceptable | No es necesario |
Integrándolo todo
No es difícil imaginar que todos los patrones de soluciones mencionados anteriormente se pueden combinar en un sistema complejo de un extremo a otro. El sistema combinado puede incluir paneles, alertas, una aplicación de abastecimiento de eventos, almacenamiento de datos y funcionalidades de análisis sin conexión.
La clave consiste en diseñar el sistema en patrones que admite composición, de modo que cada subsistema se pueda compilar, probar, actualizar y recuperar de manera independiente.
Pasos siguientes
Ha aprendido sobre varios patrones de solución mediante Azure Stream Analytics. A continuación, puede profundizar y crear su primer trabajo de Stream Analytics: