Nota
L'accés a aquesta pàgina requereix autorització. Podeu provar d'iniciar la sessió o de canviar els directoris.
L'accés a aquesta pàgina requereix autorització. Podeu provar de canviar els directoris.
En este artículo se describe cómo la generación aumentada de recuperación permite a los LLM tratar los orígenes de datos como conocimientos sin tener que entrenar.
Los LLM tienen amplias bases de conocimiento a través del entrenamiento. En la mayoría de los escenarios, puede seleccionar un LLM que esté diseñado para sus requisitos, pero estos LLM aún requieren entrenamiento adicional para comprender los datos específicos. La generación aumentada de recuperación le permite hacer que los datos estén disponibles para los LLM sin entrenarlos primero.
Funcionamiento de RAG
Para realizar la generación aumentada de recuperación, cree inserciones para los datos junto con preguntas comunes sobre ellos. Puede hacerlo sobre la marcha o puede crear y almacenar las inserciones mediante una solución de base de datos vectorial.
Cuando un usuario realiza una pregunta, el LLM usa las inserciones para comparar la pregunta del usuario con los datos y encontrar el contexto más relevante. Este contexto y la pregunta del usuario se envían al LLM en un aviso, y el LLM elabora una respuesta basada en tus datos.
Proceso de RAG básico
Para realizar el RAG, debe procesar cada origen de datos que quiera usar para las recuperaciones. El proceso básico es el siguiente:
- Fragmente datos grandes en partes manejables.
- Convierta los fragmentos en un formato que se pueda buscar.
- Almacene los datos convertidos en una ubicación que permita un acceso eficaz. Además, es importante almacenar metadatos relevantes para citas o referencias cuando el LLM proporciona respuestas.
- Envíe los datos convertidos a los LLM en solicitudes.
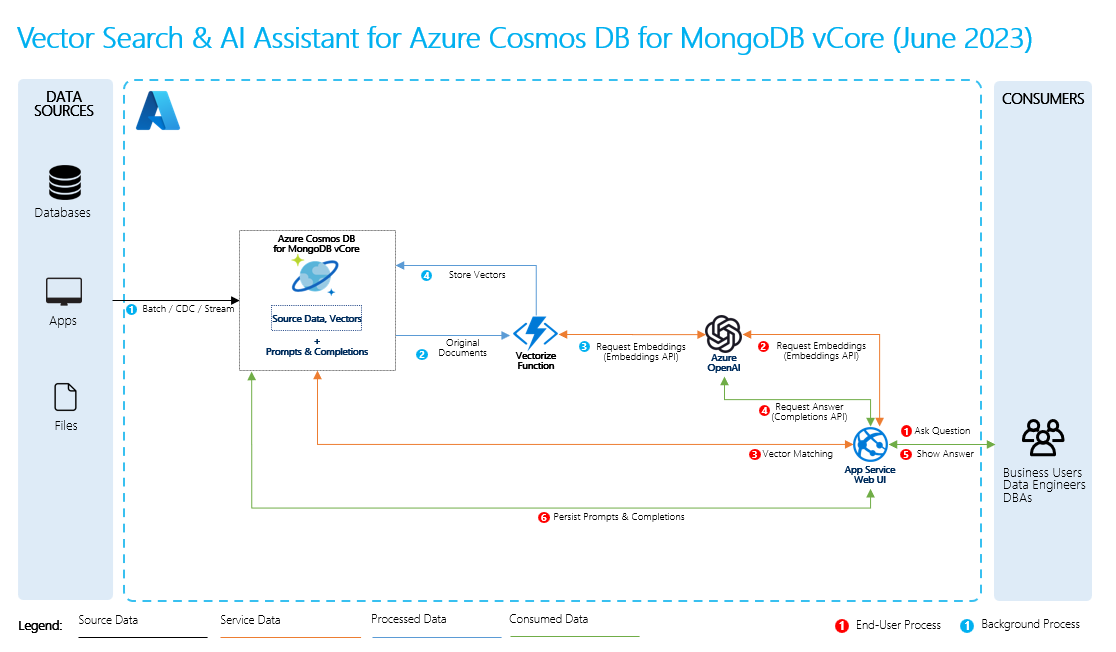
- Datos de origen: aquí es donde existen los datos. Podría ser un archivo o carpeta en la máquina, un archivo en el almacenamiento en la nube, un recurso de datos de Azure Machine Learning, un repositorio de Git o una base de datos SQL.
- Fragmentación de datos: los datos del origen deben convertirse en texto sin formato. Por ejemplo, hay que abrir documentos de Word o PDF y convertirlos en texto. A continuación, el texto se fragmenta en partes más pequeñas.
- Conversión del texto en vectores: son inserciones. Los vectores son representaciones numéricas de conceptos convertidos en secuencias numéricas, lo que facilita a los equipos comprender las relaciones entre ellos.
- Vínculos entre los datos de origen y las inserciones: esta información se almacena como metadatos en los fragmentos que creó, que se usan para ayudar a que los LLM generen citas al generar respuestas.
Consulte también
Col·laboreu amb nosaltres a GitHub
La font d'aquest contingut es pot trobar al GitHub, on també podeu crear i revisar problemes i sol·licituds d'extracció. Per obtenir més informació, consulteu la nostra guia per a col·laboradors.