Nota
L'accés a aquesta pàgina requereix autorització. Podeu provar d'iniciar la sessió o de canviar els directoris.
L'accés a aquesta pàgina requereix autorització. Podeu provar de canviar els directoris.
Se aplica a:✅ Ingeniería de datos de tejido y ciencia de datos
Al crear un área de trabajo en Microsoft Fabric, se crea automáticamente un grupo de starter que está asociado a esa área de trabajo. Con la configuración simplificada en Microsoft Fabric, no es necesario elegir los tamaños de nodo o máquina, ya que estas opciones se controlan en segundo plano. Esta configuración proporciona una experiencia de inicio de sesión de Apache Spark más rápida (de 5 a 10 segundos) para que los usuarios empiecen a trabajar y ejecuten los trabajos de Apache Spark en muchos escenarios comunes sin tener que preocuparse por configurar el proceso. En escenarios avanzados con requisitos de proceso específicos, los usuarios pueden crear un grupo de Apache Spark personalizado y ajustar el tamaño de los nodos en función de sus necesidades de rendimiento.
Para realizar cambios en la configuración de Apache Spark en un área de trabajo, debe tener el rol de administrador de esa área de trabajo. Para más información, consulte Roles en áreas de trabajo.
Para administrar la configuración de Spark para el grupo asociado al área de trabajo:
Vaya a la configuración del área de trabajo en el área de trabajo y elija la opción Ingeniería/Ciencia de datos para expandir el menú:
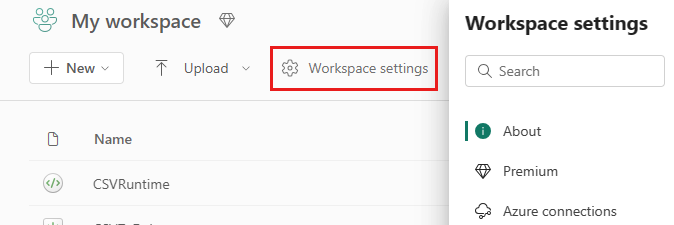
Verás la opción Spark Compute en el menú de la izquierda:
Nota:
Si cambia el grupo predeterminado de grupo de inicio a un grupo de Spark personalizado, es posible que vea inicio de sesión más largo (~3 minutos).


pool
Grupo predeterminado para el área de trabajo
Puede usar el grupo de inicio creado automáticamente o crear grupos personalizados para el área de trabajo.
Piscina de inicio: Piscinas activas prehidratadas creadas automáticamente para una experiencia más rápida. Estos clústeres son de tamaño medio. El pool de inicio se establece en una configuración predeterminada basada en la SKU de capacidad de Fabric comprada. Los administradores pueden personalizar los nodos y ejecutores máximos en función de sus requisitos de escalado de cargas de trabajo de Spark. Para más información, consulte Configuración de grupos de inicio
Grupo de Spark personalizado: puede ajustar el tamaño de los nodos, el escalado automático y asignar dinámicamente ejecutores en función de los requisitos del trabajo de Spark. Para crear un grupo de Spark personalizado, el administrador de capacidad debe habilitar la opción Grupos de áreas de trabajo personalizadas en la sección Proceso de Spark de configuración de Capacidad de administración.
Nota:
El control de nivel de capacidad de los grupos de áreas de trabajo personalizados está habilitado de forma predeterminada. Para obtener más información, consulte Configurar y gestionar las configuraciones de ingeniería de datos y ciencia de datos para las capacidades de Fabric.
Los administradores pueden crear grupos de Spark personalizados en función de sus requisitos de proceso seleccionando la opción Nuevo grupo.

Apache Spark para Microsoft Fabric admite clústeres de nodo único, lo que permite a los usuarios seleccionar una configuración de nodo mínima de 1 en cuyo caso el controlador y el ejecutor se ejecutan en un solo nodo. Estos clústeres de nodo único ofrecen alta disponibilidad restaurable durante los errores de nodo y una mejor confiabilidad del trabajo para cargas de trabajo con requisitos de proceso más pequeños. También puede habilitar o deshabilitar la opción de escalado automático para los grupos de Spark personalizados. Cuando se habilita con el escalado automático, el grupo adquiriría nuevos nodos dentro del límite máximo de nodos especificado por el usuario y los retiraría después de la ejecución del trabajo para mejorar el rendimiento.
También puede seleccionar la opción para asignar dinámicamente ejecutores para agrupar automáticamente un número óptimo de ejecutores dentro del límite máximo especificado en función del volumen de datos para mejorar el rendimiento.

Obtenga más información sobre el cómputo de Apache Spark en Fabric.
- Personalizar la configuración de proceso para los elementos: como administrador del área de trabajo, puede permitir que los usuarios ajusten las configuraciones de proceso (propiedades de nivel de sesión que incluyen Driver/Executor Core, Driver/Executor Memory) para elementos individuales, como cuadernos, definiciones de trabajos de Spark mediante Entorno.

Si el administrador del área de trabajo desactiva la configuración, el grupo predeterminado y sus configuraciones de proceso se usan para todos los entornos del área de trabajo.
Entorno
El entorno proporciona configuraciones flexibles para ejecutar los trabajos de Spark (cuadernos, definiciones de trabajos de Spark). En un entorno, puede configurar las propiedades de proceso, seleccionar diferentes entornos de ejecución, configurar dependencias de paquetes de biblioteca en función de los requisitos de carga de trabajo.
En la pestaña Entorno, tiene la opción de establecer el entorno predeterminado. Puede elegir qué versión de Spark desea usar para el área de trabajo.
Como administrador del área de trabajo de Fabric, puede seleccionar un entorno como entorno predeterminado del área de trabajo.
También puede crear uno nuevo a través de la lista desplegable Entorno.

Si deshabilita la opción para tener un entorno predeterminado, puede seleccionar la versión de runtime de Fabric de las versiones disponibles listadas en el menú desplegable.

Más información sobre los runtimes de Apache Spark.
Trabajos
La configuración de trabajos permite a los administradores controlar la lógica de admisión de trabajos para todos los trabajos de Spark del área de trabajo.

De forma predeterminada, todas las áreas de trabajo están habilitadas con la función de admisión optimista de trabajos. Obtenga más información sobre la admisión de trabajos de Spark en Microsoft Fabric.
Puede habilitar la opción Reservar núcleos máximos para trabajos activos de Spark para desactivar el enfoque de admisión optimista de trabajos y reservar el máximo de núcleos para sus trabajos de Spark.
También puede establecer el tiempo de espera de sesión de Spark para personalizar la expiración de la sesión para todas las sesiones interactivas del cuaderno.
Nota:
La expiración predeterminada de la sesión se establece en 20 minutos en el caso de las sesiones interactivas de Spark.
Alta concurrencia
El modo de simultaneidad alta permite a los usuarios compartir las mismas sesiones de Spark en cargas de trabajo de ingeniería de datos y ciencia de datos de Apache Spark para Fabric. Un elemento como un cuaderno usa una sesión de Spark para su ejecución y, cuando está habilitada, permite a los usuarios compartir una sola sesión de Spark en varios cuadernos.

Más información sobre la alta simultaneidad en Apache Spark para Fabric.
Registro automático de modelos y experimentos de Machine Learning
Los administradores ahora pueden habilitar el registro automático para sus modelos y experimentos de Machine Learning. Esta opción captura automáticamente los valores de los parámetros de entrada, las métricas de salida y los elementos de salida de un modelo de Machine Learning a medida que se entrena. Más información sobre el registro automático.

Contenido relacionado
- Lea sobreApache Spark Runtimes en Fabric: información general, control de versiones, soporte de múltiples runtimes y Actualización del protocolo Delta Lake.
- Obtenga más información en la documentación pública de Apache Spark.
- Encuentre respuestas a las preguntas más frecuentes: Preguntas más frecuentes sobre la configuración de administración del área de trabajo de Apache Spark.