Detección de anomalías en análisis de puntos de conexión
Nota:
Esta funcionalidad está disponible como complemento de Intune. Para obtener más información, consulte Complementos de Intune.
En este artículo se explica cómo funciona la detección de anomalías en Análisis de puntos de conexión como un sistema de advertencia temprana.
La detección de anomalías supervisa el estado de los dispositivos de la organización en busca de regresiones de productividad y experiencia del usuario después de los cambios de configuración. Cuando se produce un error, Anomalías correlaciona los objetos de implementación pertinentes para permitir una solución rápida de problemas, sugerir causas principales y corrección.
Los administradores pueden confiar en la detección de anomalías para obtener información sobre la experiencia del usuario que afecta a los problemas antes de que llegue a ellos a través de otros canales. El foco inicial para la detección de anomalías está en Bloqueos o bloqueos de la aplicación y Detener reinicios de errores.
Información general
Con la detección de anomalías, puede detectar posibles problemas en un sistema antes de que se conviertan en un problema grave. Tradicionalmente, los equipos de soporte técnico tienen una visibilidad limitada de los posibles problemas.
a menudo, solo obtienen un subconjunto de los problemas notificados o escalados a través del canal de soporte técnico, que no es realmente representativo de todo lo que sucede en su organización.
deben pasar innumerables horas revisando paneles personalizados intentando identificar la causa principal, solucionar problemas, crear alertas personalizadas, cambiar umbrales y ajustar parámetros.
La detección de anomalías tiene como objetivo solucionar estos problemas habilitando a los administradores de TI con información crítica.
Además de detectar anomalías, puede ver los grupos de correlación de dispositivos para explorar posibles causas principales de anomalías de gravedad media y alta. Estas cohortes de dispositivos permiten ver los patrones identificados entre los dispositivos. Hemos adoptado un enfoque proactivo para la administración de dispositivos mediante la identificación de dispositivos "en riesgo" en esas cohortes. Estos son los dispositivos que se encuentran bajo los patrones identificados con alta confianza, pero aún no han visto esas anomalías.
Nota:
Las cohortes de dispositivos solo se identifican para anomalías de gravedad media y alta.
Requisitos previos
Licencias o suscripciones: las características avanzadas de Análisis de puntos de conexión se incluyen como un complemento de Intune en Microsoft Intune Suite y requiere un costo adicional para las opciones de licencia que incluyen Microsoft Intune.
Permisos: la detección de anomalías usa permisos de rol integrados
Pestaña Anomalías
Inicie sesión en el Centro de administración de Microsoft Intune.
SeleccioneInformación general sobre análisisde puntos de conexión>de informe>.
Seleccione la pestaña Anomalías . La pestaña Anomalías proporciona una introducción rápida a las anomalías detectadas en su organización.
En este ejemplo, la pestaña Anomalías muestra una anomalía con impacto de gravedad media . Puede agregar filtros para refinar la lista.
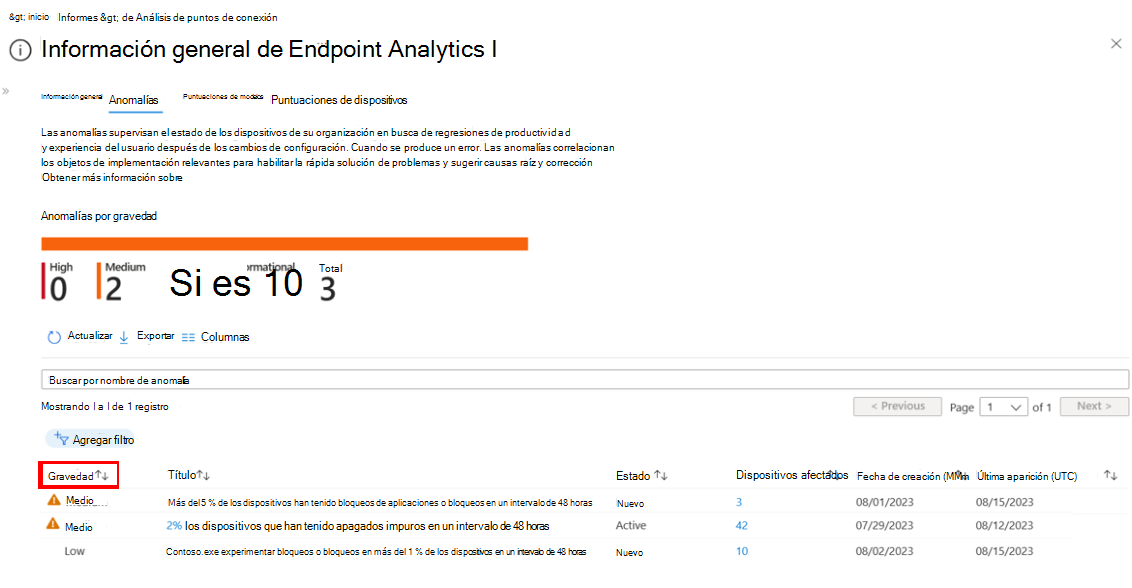
Para ver más información sobre un elemento específico, selecciónelo de la lista. Puede ver detalles como el nombre de la aplicación, qué dispositivos se ven afectados, cuándo se detectó el problema por primera vez y se produjo por última vez, y los grupos de dispositivos que podrían contribuir al problema.
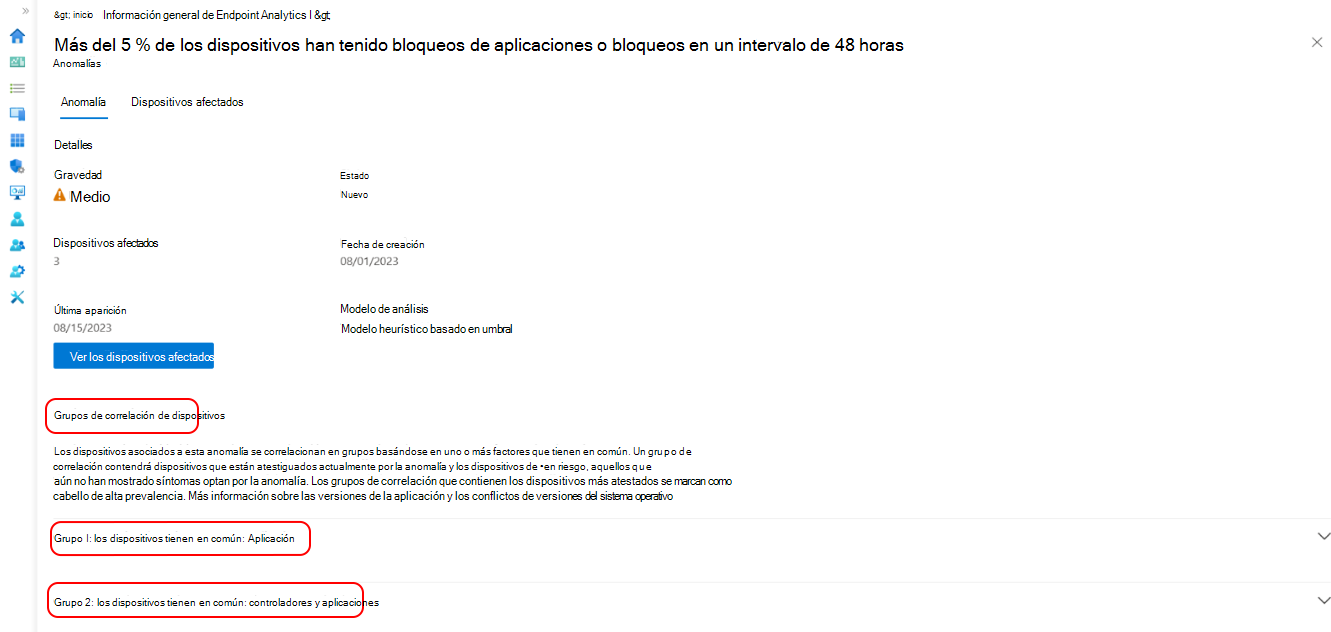
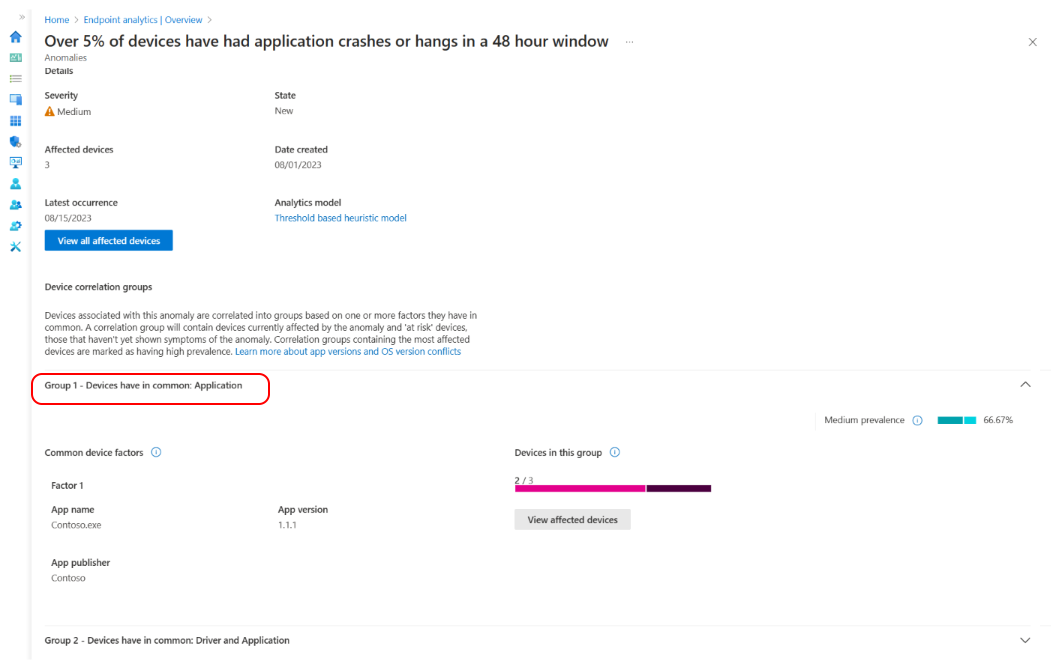
Seleccione un grupo de correlación de dispositivos de la lista para obtener una vista detallada de los factores comunes de los dispositivos. Los dispositivos se correlacionan en función de uno o varios atributos compartidos, como la versión de la aplicación, la actualización de controladores, la versión del sistema operativo y el modelo de dispositivo. Puede ver el número de dispositivos afectados actualmente por la anomalía y los dispositivos en riesgo de experimentar la anomalía. La tasa de prevalencia también muestra el porcentaje de dispositivos afectados de una anomalía que son miembros de un grupo de correlación.
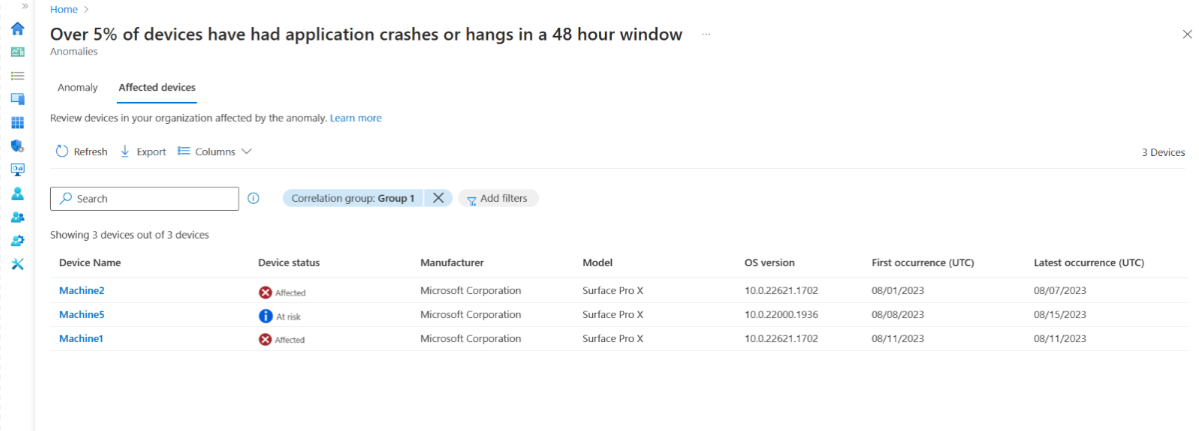
Seleccione Ver dispositivos afectados para mostrar una lista de dispositivos con atributos clave relevantes para cada dispositivo. Puede filtrar para ver los dispositivos de grupos de correlación específicos o mostrar todos los dispositivos afectados por esa anomalía en su organización. Además, la escala de tiempo del dispositivo muestra eventos más anómalos.




Modelos estadísticos para determinar anomalías
El modelo analítico creado detecta cohortes de dispositivos que se enfrentan a un conjunto anómalo de reinicios de errores de detención y bloqueos de aplicaciones que necesitan atención del administrador para mitigar y resolver. Los patrones identificados a partir de los registros de telemetría y diagnóstico del sensor determinan estas cohortes de dispositivos.
Modelo heurístico basado en umbrales: el modelo heurístico implica establecer uno o más valores de umbral para bloqueos o bloqueos de aplicaciones o reinicios de errores de detención. Los dispositivos se marcan como anómalos si hay una infracción en el umbral establecido anterior. El modelo es simple pero eficaz; es adecuado para resolver problemas prominentes o estáticos con dispositivos o sus aplicaciones. Actualmente, los umbrales se definen previamente sin una opción de personalización.
Modelo de pruebas t emparejadas: las pruebas t emparejadas son un método matemático que compara pares de observaciones en un conjunto de datos, buscando una distancia estadísticamente significativa entre sus medios. Las pruebas se usan en conjuntos de datos que constan de observaciones relacionadas entre sí de alguna manera. Por ejemplo, el recuento de reinicios de stop error desde el mismo dispositivo antes y después de un cambio de directiva o la aplicación se bloquea en un dispositivo después de una actualización del sistema operativo (sistemas operativos).
Modelo de puntuación Z de población: los modelos estadísticos basados en puntuación Z de población implican calcular la desviación estándar y la media de un conjunto de datos y, a continuación, usar esos valores para determinar qué puntos de datos son anómalos. La desviación estándar y la media se usan para calcular la puntuación Z de cada punto de datos, que representa el número de desviaciones estándar lejos de la media. Los puntos de datos que se encuentran fuera de un intervalo determinado son anómalos. Este modelo es adecuado para resaltar dispositivos o aplicaciones atípicos de la línea de base más amplia, pero requiere conjuntos de datos suficientemente grandes para ser precisos.
Modelo de puntuación Z de serie temporal: los modelos de puntuación Z de serie temporal son una variación del modelo estándar de puntuación Z diseñado para detectar anomalías en los datos de series temporales. Los datos de serie temporal son una secuencia de puntos de datos recopilados a intervalos regulares a lo largo del tiempo, como el agregado de Stop Error Restarts. La desviación estándar y la media se calculan para una ventana deslizante de tiempo, mediante métricas agregadas. Este método permite que el modelo sea sensible a los patrones temporales de los datos y se adapte a los cambios en su distribución a lo largo del tiempo.
Pasos siguientes
Para obtener más información, vaya a:
Comentaris
Properament: al llarg del 2024 eliminarem gradualment GitHub Issues com a mecanisme de retroalimentació del contingut i el substituirem per un nou sistema de retroalimentació. Per obtenir més informació, consulteu: https://aka.ms/ContentUserFeedback.
Envieu i consulteu els comentaris de