Nota
L'accés a aquesta pàgina requereix autorització. Podeu provar d'iniciar la sessió o de canviar els directoris.
L'accés a aquesta pàgina requereix autorització. Podeu provar de canviar els directoris.
Al utilizar Copilot Studio, puede mejorar sus agentes con conocimientos específicos del dominio, impulsados por los mismos orígenes de datos conocidos y de confianza que usted crea mediante conectores de Power Platform.
Al cargar contenido externo desde el dispositivo, OneDrive o SharePoint, puede enriquecer los agentes con conocimientos contextuales adaptados a su empresa. Microsoft Dataverse almacena estos archivos de forma segura y los procesa automáticamente en índices semánticos e incrustaciones vectoriales. Esta configuración permite a los agentes generar respuestas más precisas y basadas en la información que proporcione.
Los archivos cargados en Copilot Studio usan Microsoft Dataverse para ingerir archivos sin procesar y crear índices e incrustaciones vectoriales. Estos índices e incrustaciones ayudan a proporcionar respuestas de calidad para tus agentes. Puede cargar estos archivos desde el equipo o conectando a OneDrive o SharePoint.
Cuando subes archivos como fuentes de conocimiento, ayudas a enriquecer a tus agentes con datos adicionales, complementas el conocimiento del modelo de lenguaje y bases al agente en información específica que proporcionas. Puede cargar varios archivos, que el sistema indexa semánticamente como incrustaciones de vectores y, a continuación, usa como conocimiento para los agentes. Puedes compartir el conocimiento que se utiliza en los agentes con los usuarios autenticados y no autenticados del agente.
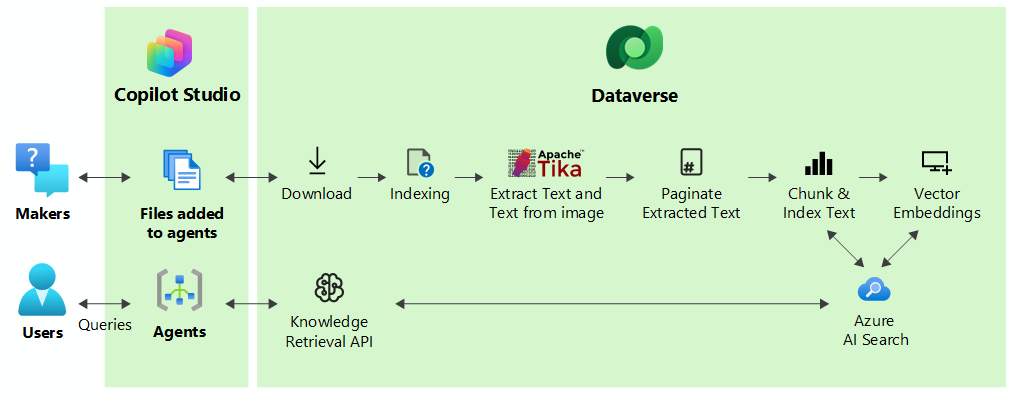
Para mejorar las respuestas de un agente, el sistema subía fragmentos de archivos en piezas para un procesamiento más rápido y los indexaba vectorialmente para proporcionar coincidencias semánticas con la consulta del usuario. El sistema almacena los archivos de forma segura en Dataverse. Cuando un usuario consulta a través de un agente, Copilot Studio busca los fragmentos más relevantes que coinciden con la intención de la consulta del usuario y devuelve los resultados al usuario.
De forma similar, Dataverse ingiere archivos de OneDrive y SharePoint mediante las opciones de carga de archivos. También ingiere contenido no estructurado, como artículos de knowledge base de Salesforce, ServiceNow, Confluence y Zendesk, para proporcionar mejores resultados semánticos para el agente.
Note
Obtenga más información en Uso del intérprete de código para analizar datos estructurados.
Conectores de Power Platform para datos no estructurados
Los siguientes conectores de Power Platform funcionan con orígenes de datos no estructurados:
OneDrive
Use la opción Cargar archivos > de OneDrive con una interfaz del selector de archivos para elegir los archivos y carpetas que desea incluir. Una vez seleccionados, el sistema recupera los elementos en Dataverse y los indexa para su uso. Las carpetas que añades incluyen todos los archivos y subcarpetas compatibles dentro de esa carpeta hasta el límite total de archivos.
SharePoint
Use la opción Cargar archivos > de SharePoint para seleccionar archivos y carpetas a través de una interfaz del selector de archivos. Después de seleccionar estos elementos, el conector los recupera en Dataverse y los indexa para su uso. Al agregar carpetas, se incluyen todos los archivos y subcarpetas admitidos dentro de esa carpeta hasta el límite total de archivos. Actualmente, el conector no admite Pages.
Note
Cuando se usa SharePoint como origen de conocimiento, Copilot Studio recupera el contenido a través de la indexación de búsqueda de SharePoint, no mediante la lectura directa de vistas de lista como AllItems.aspx. Es posible que los elementos de SharePoint recién agregados o actualizados no estén disponibles para el agente hasta que se complete la indexación de búsqueda. Asegúrese de que el agente tiene los permisos necesarios, como Sites.Read.All y Files.Read.All, y el contenido se almacena en formatos de archivo admitidos.
Salesforce
El conector de Salesforce para datos no estructurados admite la recuperación de bases de conocimiento que contienen artículos de conocimiento. Seleccione una Base de conocimiento y el conector indexa todos los artículos de esa Base de conocimiento. No puedes seleccionar artículos o temas individuales. Al consultar datos, no puedes especificar un artículo o base de conocimiento específica. La lista de conocimientos muestra un único objeto para todos los objetos de conocimiento que seleccione al crear el origen.
ServiceNow
El conector de ServiceNow para datos no estructurados admite la recuperación de bases de conocimiento que contienen artículos de conocimiento. Las bases de conocimiento contienen artículos. Seleccione una Base de conocimiento y el conector indexa todos los artículos de esa Base de conocimiento. No puedes seleccionar artículos individuales. Al consultar datos, no puedes especificar una base de conocimiento, una carpeta o un artículo individual. La lista de conocimientos muestra un único objeto para todos los objetos de conocimiento que seleccione al crear el origen.
Confluencia
El conector de Confluence para datos no estructurados admite la recuperación de los espacios que contienen páginas. El conector también soporta subcarpetas. No puedes seleccionar páginas individuales. Al consultar datos, no puedes especificar una página. La lista Knowledge muestra un único objeto para todas las páginas dentro del espacio.
Zendesk
El conector de Zendesk para datos no estructurados admite la recuperación de la base de conocimiento que contiene artículos de conocimiento. No puedes seleccionar artículos, categorías o secciones individuales. Al consultar datos, no puedes especificar un artículo, categoría o sección. La lista de conocimiento muestra un único objeto para todos los artículos de la base de conocimiento.
Seguridad
Cuando un usuario consulta un agente que usa un origen de Power Platform Connector, el sistema realiza comprobaciones de autorización.
Acceso al conector
Cuando use por primera vez un origen basado en conectores, el sistema le pedirá que seleccione un conector de Power Platform existente o agregue uno. Este proceso garantiza que solo comparta datos con creadores que tengan los permisos adecuados para acceder al origen de datos.
Acceso al contenido
Cuando un usuario realiza una consulta, el sistema utiliza su información de conexión para comprobar la fuente de datos y verificar que tiene permiso para ver el contenido. Aunque el sistema almacena fragmentos e índices localmente en Dataverse, realiza una comprobación en tiempo real de las consultas para asegurarse de que el usuario actual tiene acceso a los datos antes de proporcionar un resumen o respuesta.
Note
- El sistema no devuelve resultados a los usuarios si no tienen permiso para conjuntos específicos de archivos o artículos de knowledge base. En su lugar, reciben un mensaje estándar que dice "no se han encontrado resultados." Si los usuarios creen que debe haber resultados para esa fuente, deben trabajar con sus administradores para asegurarse de que tienen permisos para los datos a los que intentan acceder. El usuario necesita asignarle un rol de seguridad adecuado en Dataverse, como el rol de Usuario Básico.
- El sistema no almacena localmente la información de permisos de contenido. Realiza todas las comprobaciones de permisos en tiempo real con la fuente para asegurarse de que estén lo más actualizadas posible.
Frecuencia de sincronización y actualización de archivos
Un trabajo de sincronización programado mantiene actualizados los archivos conectados de OneDrive y SharePoint y artículos de conocimientos no estructurados. Este trabajo se ejecuta automáticamente en segundo plano, actualizando el contenido de los archivos y reindexando los cambios para proporcionar resultados precisos para las consultas. Las actualizaciones administran no solo los cambios en el contenido, sino que también garantizan que el contenido eliminado del origen ya no aparezca como parte de ninguna respuesta de consulta. Actualmente, no se puede desencadenar manualmente una actualización.
Para obtener más información sobre el tiempo de frecuencia de actualización, consulte Copilot Studio límites de orígenes de conocimiento de datos no estructurados.
Licencias
Todas las solicitudes que implican conocimiento se cobran en las tarifas de mensajería de respuestas generativas de Microsoft Copilot. Para más información, consulte Tarifas de facturación y gestión.
Si las fuentes de conocimiento requieren la ingestión de datos, el almacenamiento de los datos y los índices correspondientes para recuperarlos están sujetos a los derechos de almacenamiento que tiene el cliente. Para más información sobre la búsqueda en lenguaje natural de Dataverse, véase Mejorar experiencias impulsadas por IA con la búsqueda de Dataverse.
Límites y limitaciones
Cuando activas por primera vez el soporte de datos no estructurados, Dataverse puede tardar entre 5 y 30 minutos en configurarse e indexar antes de procesar los archivos añadidos. El período de tiempo depende del tamaño del entorno actual de Dataverse.
Cada agente puede tener un máximo de 500 objetos de conocimiento. Estos objetos pueden ser archivos, carpetas, artículos de conocimiento, sitios web u otras fuentes.
Actualmente, un agente solo puede usar cinco fuentes diferentes a la vez. Por ejemplo, SharePoint, Dataverse, OneDrive u otros orígenes.
Para obtener más información sobre los límites y limitaciones específicos de los orígenes de datos no estructurados admitidos, consulte la sección límites de las fuentes de conocimiento de datos no estructurados de Copilot Studio.
Note
Los agentes de Copilot Studio requieren la búsqueda en Dataverse para usar este origen de conocimiento. Si no puede agregar un archivo habilitado para Dataverse a un agente, pida al administrador que active la búsqueda de Dataverse en su entorno. Para obtener más información sobre la búsqueda de Dataverse y cómo administrarla, consulte ¿Qué es la búsqueda de Dataverse y Configurar la búsqueda de Dataverse para su entorno?
Para acceder a OneDrive y SharePoint contenido almacenado en Dataverse, los usuarios deben tener al menos una licencia de usuario básico para Power Apps o Dynamics 365. Además, los permisos de usuario Básico también deben incluir permisos de lectura para las siguientes tablas y entidades:
- Ensamblado de plugin
- Tipo de complemento
- Mensaje del SDK
- Paso de procesamiento de mensajes del SDK
- Imagen del paso de procesamiento de mensajes del SDK
Puede configurar estos permisos en el Centro de administración de Power Platform o en el Centro de administración de Dynamics 365.
Preguntas más frecuentes
¿Cuál es la diferencia entre las dos opciones de SharePoint en Agregar conocimiento?
En el cuadro de diálogo Add knowledge, verá dos opciones de SharePoint.

La opción SharePoint de la sección de carga de archivos (1) es para cargar archivos o carpetas individuales de SharePoint a su agente. Esta opción carga una copia del archivo de SharePoint a Dataverse y mantiene una relación sincrónica para mantener el archivo actualizado. Durante las consultas, se accede a SharePoint para validar los permisos de usuario para el contenido. Los archivos almacenados de Dataverse consumen almacenamiento de datos, pero proporcionan una funcionalidad de búsqueda semántica de documento completo y compatibilidad con texto dentro de imágenes para determinados tipos de documentos, como archivos PDF.
Use la opción 1 cuando desee una sincronización rápida y no los archivos estáticos cargados en Dataverse. Se actualiza automáticamente cuando se cambian los archivos de origen.
La otra opción SharePoint (2) proporciona la integración completa de SharePoint en Copilot Studio mediante el conector SharePoint. Use esta opción cuando necesite funcionalidades completas del conector de SharePoint, configuraciones de autenticación personalizadas o opciones de consulta avanzadas.
Diferencias en tiempo de ejecución
| Escenario | Opción 1: carga de archivos | Opción 2: Conector de SharePoint |
|---|---|---|
| Almacenamiento de contenido | Copiado en Dataverse desde SharePoint | Reside en SharePoint |
| Funcionalidad de búsqueda | Busca en un índice semántico de Dataverse creado a partir de vectores incrustados del contenido ingerido copiado de SharePoint | Consulta directamente la infraestructura de búsqueda de SharePoint |
| Actualización del contenido | El contenido se sincroniza cada cuatro a seis horas, en función de la finalización de la ingesta. | En tiempo real y refleja el contenido disponible más reciente |
| Listas de SharePoint | Supported | No está soportado |
| Consumo de almacenamiento de Dataverse | Sí, para los archivos copiados y los índices de búsqueda | No |
| Filtros de consulta avanzados | No disponible | Filtrar por título, autor, modificado por, fecha de modificación |
Uso de opciones
Use la opción 1 en las siguientes situaciones:
- Necesita compatibilidad con listas de SharePoint
- El agente usa solo un conjunto específico de archivos o carpetas.
- Quiere una búsqueda semántica de alta calidad con tecnología de incrustaciones vectoriales.
- Un intervalo de actualización de contenido de cuatro a seis horas es suficiente
Use la opción 2 en las situaciones siguientes:
- Sin retraso en la sincronización de contenido, como una wiki actualizada con frecuencia o un sitio de anuncio
- Es necesario evitar el consumo de Dataverse, especialmente para bibliotecas de documentos de gran tamaño
- Uso de filtros de consulta avanzados, como el filtrado basado en el autor, la fecha de modificación o el título
Note
Ambas opciones requieren autenticación de usuario. Los usuarios pueden iniciar sesión antes de que el agente recupere los resultados del contenido de SharePoint. Obtenga más información sobre el tiempo de sincronización y los límites de archivos en los límites del origen de conocimiento de datos no estructurados de Copilot Studio.
¿Por qué no se muestra el icono de SharePoint en la sección Cargar archivos del cuadro de diálogo Agregar conocimiento?
Hay un ligero retraso después de instalar una solución hasta que aparezca en todas las organizaciones existentes. Para iniciar una actualización manual, siga estos pasos:
Inicia sesión en el centro de administración de Power Platform usando credenciales de administrador.
En la barra lateral, seleccione Administrar.
En la lista de productos, seleccione Aplicaciones de Dynamics 365.
Busque poweraiextensions.
Seleccione los tres puntos (... ) para Microsoft Dynamics 365 - PowerAIExtensions y seleccione Install.
En el menú desplegable, seleccione el entorno y, a continuación, seleccione Instalar.
Una vez completada la instalación, abra Power Apps en una nueva ventana.
En el panel izquierdo, seleccione Soluciones.
Seleccione Detalles.
Compruebe que la versión de PowerAIExtensions Solution Anchor esté establecida en 1.01.688 o posterior.
¿Qué ocurre cuando agrego más de 500 objetos de conocimiento a mi agente?
No puedes añadir más objetos a menos que primero elimines los anteriores.
¿Cada agente tiene su propio índice del origen de conocimiento?
Dataverse almacena fuentes de conocimiento para usarlas en el entorno donde las creas. Si varios agentes usan la misma carpeta SharePoint, todos los agentes usan una sola instancia de esa carpeta.
¿Qué ocurre si agrego una carpeta de SharePoint o OneDrive que supere el número máximo de archivos, carpetas y subcarpetas?
Copilot Studio recupera e indexa hasta el número máximo de archivos, carpetas y subcarpetas. No procesa los elementos restantes y no indica qué elementos se procesan o no.
Uno de los archivos que he agregado aparece como parte del origen de conocimiento, pero no puedo obtener respuestas de él. ¿Por qué?
Este problema puede estar relacionado con uno de los siguientes motivos:
- La página Conocimiento no notifica el archivo ni la carpeta como Listo.
- El nombre de archivo incluye un carácter no admitido (específicamente para archivos de SharePoint).
- El archivo tiene una configuración de confidencialidad de Confidencial o Extremadamente Confidencial, o tiene protección con contraseña.
- No se admite el tipo de archivo.
- El archivo o carpeta procede de un sitio de OneDrive o SharePoint de otro usuario, y el usuario no lo compartió con usted.
- El archivo es un archivo de base de conocimiento y su cuenta no tiene los permisos necesarios para ver el contenido en el sistema de origen.