Nota
L'accés a aquesta pàgina requereix autorització. Podeu provar d'iniciar la sessió o de canviar els directoris.
L'accés a aquesta pàgina requereix autorització. Podeu provar de canviar els directoris.
Puedes usar mosaicos para maximizar la aceleración de la aplicación. El azulejamiento divide los subprocesos en subconjuntos rectangulares iguales o bloques. Si utiliza un tamaño de bloque adecuado y un algoritmo de mosaico, puede obtener aún más aceleración del código de C++ AMP. Los componentes básicos del mosaico son:
tile_staticvariables. La principal ventaja de la división en bloques es la mejora en el rendimiento deltile_staticacceso. El acceso a los datos entile_staticmemoria puede ser significativamente más rápido que el acceso a los datos del espacio global (arrayoarray_viewobjetos). Se crea una instancia de la variabletile_staticpara cada mosaico y todos los subprocesos del mosaico tienen acceso a la variable. En un algoritmo típico de mosaico, los datos se copian una vez de la memoria global en latile_staticmemoria, y luego se accede a ellos muchas veces desde latile_staticmemoria.tile_barrier::wait Método Una llamada a
tile_barrier::waitsuspende la ejecución del subproceso actual hasta que todos los subprocesos en la misma tile alcancen la llamada atile_barrier::wait. No se puede garantizar el orden en el que se ejecutarán los subprocesos, solo que ningún subproceso del icono se ejecutará más allá de la llamada atile_barrier::waithasta que todos los subprocesos hayan alcanzado la llamada. Esto significa que, mediante el uso del métodotile_barrier::wait, puede realizar tareas de forma individual para cada unidad de procesamiento, en lugar de hacerlo para cada subproceso. Un algoritmo de mosaico típico tiene código para inicializar la memoria de todo el mosaico, seguido de una llamada atile_barrier::wait. El código siguientetile_barrier::waitcontiene cálculos que requieren acceso a todos lostile_staticvalores.Indexación local y global. Tiene acceso al índice del hilo en relación con el objeto
array_viewcompleto oarray, y al índice con respecto a la tesela. El uso del índice local puede facilitar la lectura y depuración del código. Normalmente, se usa la indexación local para acceder a las variablestile_static, y la indexación global para acceder a las variablesarrayyarray_view.Clase tiled_extent y Clase tiled_index. Utilizas un
tiled_extentobjeto en lugar de unextentobjeto en la llamadaparallel_for_each. Se usa un objetotiled_indexen lugar de un objetoindexen la llamadaparallel_for_each.
Para aprovechar el uso de tiling, el algoritmo debe dividir el dominio de cálculo en bloques y luego copiar los datos del bloque en variables tile_static para un acceso más rápido.
Ejemplo de índices globales, de tiles y locales
Nota:
Los encabezados de C++ AMP están en desuso a partir de la versión 17.0 de Visual Studio 2022.
Si se incluyen encabezados AMP, se generarán errores de compilación. Defina _SILENCE_AMP_DEPRECATION_WARNINGS antes de incluir encabezados AMP para silenciar las advertencias.
El diagrama siguiente representa una matriz de 8x9 de datos organizados en iconos 2x3.
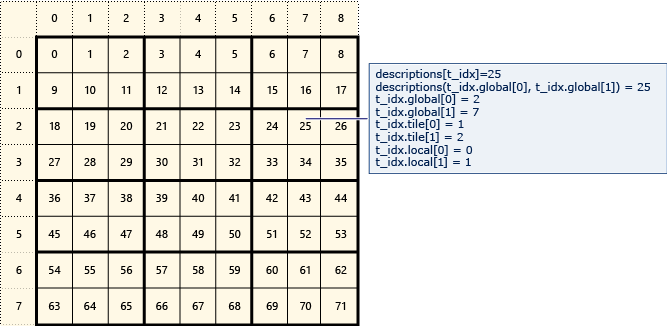
En el siguiente ejemplo se muestran los índices globales, de mosaico y locales de esta matriz en mosaico. Un array_view objeto se crea mediante elementos de tipo Description.
Description contiene los índices globales, de mosaico y locales del elemento de la matriz. El código de la llamada a parallel_for_each establece los valores de los índices globales, de icono y locales de cada elemento. La salida muestra los valores en las estructuras Description.
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
El trabajo principal del ejemplo se encuentra en la definición del array_view objeto y la llamada a parallel_for_each.
El vector de
Descriptionestructuras se copia en un objeto 8x9array_view.Se llama al
parallel_for_eachmétodo con untiled_extentobjeto como dominio de proceso. Eltiled_extentobjeto se crea llamando alextent::tile()método de ladescriptionsvariable . Los parámetros de tipo de la llamada aextent::tile(),<2,3>especifican que se crean iconos 2x3. Por lo tanto, la matriz 8x9 se divide en mosaicos de 12, cuatro filas y tres columnas.El método
parallel_for_eachse llama mediantetiled_index<2,3>un objeto (t_idx) como índice. Los parámetros de tipo del índice (t_idx) deben coincidir con los parámetros de tipo del dominio de proceso (descriptions.extent.tile< 2, 3>()).Cuando se ejecuta cada subproceso, el índice
t_idxdevuelve información sobre el icono que el subproceso está en (tiled_index::tilepropiedad) y la ubicación del subproceso dentro del icono (tiled_index::localpropiedad).
Sincronización de iconos: tile_static y tile_barrier::wait
En el ejemplo anterior se muestra el diseño de mosaico y los índices, pero no es muy útil. La disposición de mosaicos resulta útil cuando los mosaicos son integrales para el algoritmo y explotan las variables tile_static. Dado que todos los subprocesos de un icono tienen acceso a tile_static variables, las llamadas a tile_barrier::wait se usan para sincronizar el acceso a las tile_static variables. Aunque todos los subprocesos de un icono tienen acceso a las tile_static variables, no hay ningún orden garantizado de ejecución de subprocesos en el icono. En el ejemplo siguiente se muestra cómo usar tile_static variables y el tile_barrier::wait método para calcular el valor medio de cada icono. Estas son las claves para comprender el ejemplo:
RawData se almacena en una matriz 8x8.
El tamaño del icono es 2x2. Esto crea una cuadrícula de mosaicos de 4x4, y los promedios se pueden almacenar mediante un objeto
arrayen una matriz de 4x4. Solo hay un número limitado de tipos que puede capturar por referencia en una función restringida de AMP. Laarrayclase es una de ellas.El tamaño de la matriz y el tamaño de la muestra se definen mediante instrucciones ,
#defineya que los parámetros de tipo enarray,array_view,extentytiled_indexdeben ser valores constantes. También puede usar declaracionesconst int static. Como ventaja adicional, es trivial cambiar el tamaño de la muestra para calcular el promedio sobre mosaicos de 4 x 4.Se declara una
tile_staticmatriz de 2x2 de valores flotantes para cada baldosa. Aunque la declaración está en la ruta de código de cada subproceso, solo se crea una matriz para cada tesela de la matriz.Hay una línea de código para copiar los valores de cada icono en la
tile_staticmatriz. Para cada subproceso, después de copiar el valor en la matriz, la ejecución en el subproceso se detiene debido a la llamada atile_barrier::wait.Cuando todos los subprocesos de un icono han alcanzado la barrera, se puede calcular el promedio. Dado que el código se ejecuta para cada subproceso, hay una
ifinstrucción para calcular solo el promedio en un subproceso. El promedio se almacena en la variable averages. La barrera es esencialmente la estructura que controla los cálculos por mosaico, al igual que se podría usar unforbucle.Los datos de la
averagesvariable, ya que es unarrayobjeto, deben copiarse de nuevo en el host. En este ejemplo se usa el operador de conversión de vectores.En el ejemplo completo, puede cambiar SAMPLESIZE a 4 y el código se ejecuta correctamente sin ningún otro cambio.
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
Condiciones de carrera
Puede ser tentador crear una tile_static variable denominada total e incrementar esa variable para cada subproceso, como esta:
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
El primer problema con este enfoque es que tile_static las variables no pueden tener inicializadores. El segundo problema es que hay una condición de carrera en la asignación a total, porque todos los subprocesos del icono tienen acceso a la variable en ningún orden determinado. Puede programar un algoritmo para solo permitir que un hilo acceda al total en cada barrera, como se muestra a continuación. Sin embargo, esta solución no es extensible.
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
Barreras de memoria
Hay dos tipos de accesos de memoria que deben sincronizarse: la memoria global y la memoria tile_static. Un concurrency::array objeto asigna solo memoria global. Un concurrency::array_view puede hacer referencia a memoria global, a tile_static memoria, o a ambas, en función de cómo se construyó. Hay dos tipos de memoria que se deben sincronizar:
memoria global
tile_static
Una barrera de memoria garantiza que los accesos a memoria están disponibles para otros subprocesos del icono de subprocesos y que los accesos a memoria se ejecutan según el orden del programa. Para asegurar esto, los compiladores y procesadores no reordenan las lecturas y escrituras a través de la barrera de memoria. En C++ AMP, una barrera de memoria se crea mediante una llamada a uno de estos métodos:
tile_barrier::wait (Método): Crea una barrera alrededor de tanto la memoria global como
tile_static.tile_barrier::wait_with_all_memory_fence (Método): crea una barrera alrededor de la memoria global y de
tile_static.Método tile_barrier::wait_with_global_memory_fence: crea una barrera solo alrededor de la memoria global.
Método tile_barrier::wait_with_tile_static_memory_fence: Crea una barrera únicamente alrededor de la memoria
tile_static.
Llamar a la barrera específica que necesita puede mejorar el rendimiento de la aplicación. El tipo de barrera afecta a cómo el compilador y el hardware reordenan las sentencias. Por ejemplo, si usa una barrera de memoria global, solo se aplica a los accesos a memoria global y, por lo tanto, el compilador y el hardware pueden reordenar las lecturas y escrituras en tile_static variables en los dos lados de la barrera.
En el ejemplo siguiente, la barrera sincroniza las escrituras en tileValues, una variable tile_static. En este ejemplo, tile_barrier::wait_with_tile_static_memory_fence se llama a en lugar de tile_barrier::wait.
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
Consulte también
C++ AMP (Paralelismo masivo acelerado de C++)
tile_static Palabra clave