Nota
L'accés a aquesta pàgina requereix autorització. Podeu provar d'iniciar la sessió o de canviar els directoris.
L'accés a aquesta pàgina requereix autorització. Podeu provar de canviar els directoris.
Se aplica a:![]() SQL Server en Linux
SQL Server en Linux
En este tutorial se muestra cómo crear y configurar un grupo de disponibilidad (AG) para SQL Server en Linux. A diferencia de SQL Server 2016 (13.x) y versiones anteriores en Windows, puede habilitar un grupo de disponibilidad, ya sea creando primero el clúster de Pacemaker subyacente o sin crearlo. La integración con el clúster, si es necesario, se produce más adelante.
El tutorial incluye las siguientes tareas:
- Habilitar grupos de disponibilidad.
- Crear puntos de conexión y certificados de grupo de disponibilidad.
- Usar SQL Server Management Studio (SSMS) o Transact-SQL para crear un grupo de disponibilidad.
- Crear el inicio de sesión de SQL Server y los permisos para Pacemaker.
- Crear recursos de grupos de disponibilidad en un clúster de Pacemaker (tipo externo solamente).
Requisitos previos
Implemente el clúster de alta disponibilidad de Pacemaker tal como se explica en Implementar un clúster de Pacemaker para SQL Server en Linux.
Habilitar la característica de grupos de disponibilidad
A diferencia de como se hace en Windows, no puede usar PowerShell ni SQL Server Configuration Manager para habilitar la característica de grupos de disponibilidad. En Linux, puede habilitar la característica grupos de disponibilidad de dos maneras: usar la utilidad mssql-conf o editar el mssql.conf archivo manualmente.
Importante
Debe habilitar la funcionalidad AG para réplicas de solo configuración, incluso en SQL Server Express.
Usar la utilidad mssql-conf
En un símbolo del sistema, ejecute el siguiente comando:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
Editar el archivo mssql.conf
También puede modificar el mssql.conf archivo, ubicado en la /var/opt/mssql carpeta . Agregue las líneas siguientes:
[hadr]
hadr.hadrenabled = 1
Reiniciar SQL Server
Después de habilitar los grupos de disponibilidad, debe reiniciar SQL Server. Use el siguiente comando:
sudo systemctl restart mssql-server
Crear los puntos de conexión y los certificados del grupo de disponibilidad
Un grupo de disponibilidad usa puntos de conexión TCP para la comunicación. En sistemas Linux, SQL Server solo admite puntos de conexión para un grupo de disponibilidad (AG) si se utilizan certificados para la autenticación. Debe restaurar el certificado desde una instancia en todas las demás instancias que participan como réplicas en el mismo AG (grupo de disponibilidad). Necesita el proceso de certificado incluso para una réplica de configuración únicamente.
Solo puede crear puntos de conexión y restaurar certificados mediante Transact-SQL. También puede usar certificados no generados por SQL Server. Además necesita un proceso para administrar y reemplazar los certificados que expiren.
Importante
Si tiene previsto usar el asistente de SQL Server Management Studio para crear el grupo de disponibilidad (AG), aun así deberá crear y restaurar los certificados mediante Transact-SQL en Linux.
Para obtener una sintaxis completa sobre las opciones disponibles para los distintos comandos (incluida la seguridad), consulte:
Nota:
Aunque está creando un grupo de disponibilidad, el tipo de punto de conexión usa FOR DATABASE_MIRRORING, ya que algunos aspectos subyacentes se han compartido en algún momento con esa característica ahora en desuso.
En este ejemplo se crean certificados para una configuración de tres nodos. Los nombres de las instancias son LinAGN1, LinAGN2 y LinAGN3.
Ejecute la siguiente secuencia de comandos en
LinAGN1para crear la clave maestra, el certificado y el punto de conexión, así como para realizar una copia de seguridad del certificado. En este ejemplo se usa el puerto TCP típico de 5022 para el punto de conexión.CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN1_Cert WITH SUBJECT = 'LinAGN1 AG Certificate'; GO BACKUP CERTIFICATE LinAGN1_Cert TO FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN1_Cert, ROLE = ALL ); GOHaga lo mismo en
LinAGN2:CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN2_Cert WITH SUBJECT = 'LinAGN2 AG Certificate'; GO BACKUP CERTIFICATE LinAGN2_Cert TO FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN2_Cert, ROLE = ALL ); GOPor último, realice la misma secuencia en
LinAGN3:CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN3_Cert WITH SUBJECT = 'LinAGN3 AG Certificate'; GO BACKUP CERTIFICATE LinAGN3_Cert TO FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN3_Cert, ROLE = ALL ); GOUtilizando
scpu otra utilidad, copie las copias de seguridad del certificado en cada nodo que desee incluir en el grupo de disponibilidad.En este ejemplo:
- Copie
LinAGN1_Cert.cerenLinAGN2yLinAGN3. - Copie
LinAGN2_Cert.cerenLinAGN1yLinAGN3. - Copie
LinAGN3_Cert.cerenLinAGN1yLinAGN2.
- Copie
Cambie la propiedad y el grupo asociados a los archivos de certificado copiados a
mssql.sudo chown mssql:mssql <CertFileName>Cree los inicios de sesión de nivel de instancia y los usuarios asociados a
LinAGN2yLinAGN3enLinAGN1.CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GOPrecaución
La contraseña debe seguir la directiva de contraseña predeterminada de SQL Server. De forma predeterminada, la contraseña debe tener al menos ocho caracteres y contener caracteres de tres de los siguientes cuatro conjuntos: mayúsculas, minúsculas, dígitos en base 10 y símbolos. Las contraseñas pueden tener hasta 128 caracteres. Use contraseñas lo más largas y complejas posible.
Restaura
LinAGN2_CertyLinAGN3_CertenLinAGN1. Disponer de los certificados de las otras réplicas es un aspecto importante de la comunicación y la seguridad de las AG.CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOConceda a los inicios de sesión asociados con
LinAGN2yLinAGN3el permiso para conectarse al punto de conexión enLinAGN1.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login;Cree los inicios de sesión de nivel de instancia y los usuarios asociados a
LinAGN1yLinAGN3enLinAGN2.CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GORestaura
LinAGN1_CertyLinAGN3_CertenLinAGN2.CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOConceda a los inicios de sesión asociados con
LinAGN1yLinAGN3el permiso para conectarse al punto de conexión enLinAGN2.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login; GOCree los inicios de sesión de nivel de instancia y los usuarios asociados a
LinAGN1yLinAGN2enLinAGN3.CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GORestaura
LinAGN1_CertyLinAGN2_CertenLinAGN3.CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GOConceda a los inicios de sesión asociados con
LinAG1yLinAGN2el permiso para conectarse al punto de conexión enLinAGN3.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GO
Crear el grupo de disponibilidad
En esta sección se muestra cómo usar SQL Server Management Studio (SSMS) o Transact-SQL para crear el grupo de disponibilidad para SQL Server.
Uso de SQL Server Management Studio
En esta sección se muestra cómo crear un grupo de disponibilidad externo con un tipo de clúster mediante SSMS usando el Asistente para Nuevo Grupo de Disponibilidad.
En SSMS, expanda Always On High Availability, haga clic con el botón derecho en Grupos de disponibilidad y seleccione Asistente para nuevo grupo de disponibilidad.
En el cuadro de diálogo Introducción, seleccione Siguiente.
En el cuadro de diálogo Especificar opciones de grupo de disponibilidad , escriba un nombre para el grupo de disponibilidad y seleccione un tipo de clúster de
EXTERNALoNONEen la lista desplegable. UseEXTERNALal implementar Pacemaker. UseNONEpara escenarios especializados, como el escalado horizontal de lectura. Seleccionar la opción de detección del estado a nivel de base de datos es opcional. Para obtener más información sobre esta opción, consulte la opción de conmutación por error de detección de estado de la base de datos a nivel de grupo de disponibilidad. Seleccione Siguiente.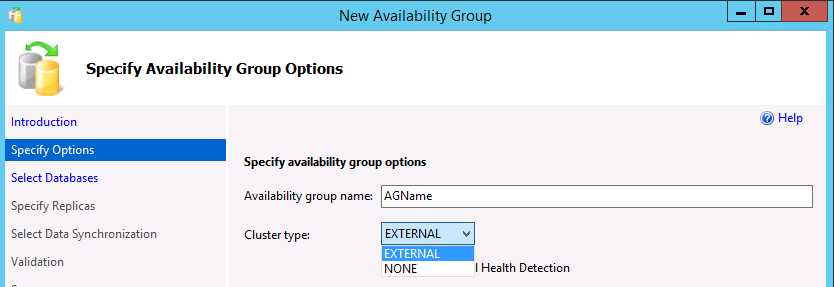
En el cuadro de diálogo Seleccionar bases de datos, seleccione las bases de datos que desea que participen en el grupo de disponibilidad. Cada base de datos debe tener una copia de seguridad completa para poder agregarla a un Grupo de Disponibilidad Always On. Seleccione Siguiente.
En el cuadro de diálogo Especificar réplicas, seleccione Agregar réplica.
En el cuadro de diálogo Conectar al servidor, escriba el nombre de la instancia de Linux de SQL Serverque va a ser la réplica secundaria y las credenciales para conectarse. Seleccione Conectar.
Repita los dos pasos anteriores para la instancia que contenga una réplica únicamente de configuración u otra réplica secundaria.
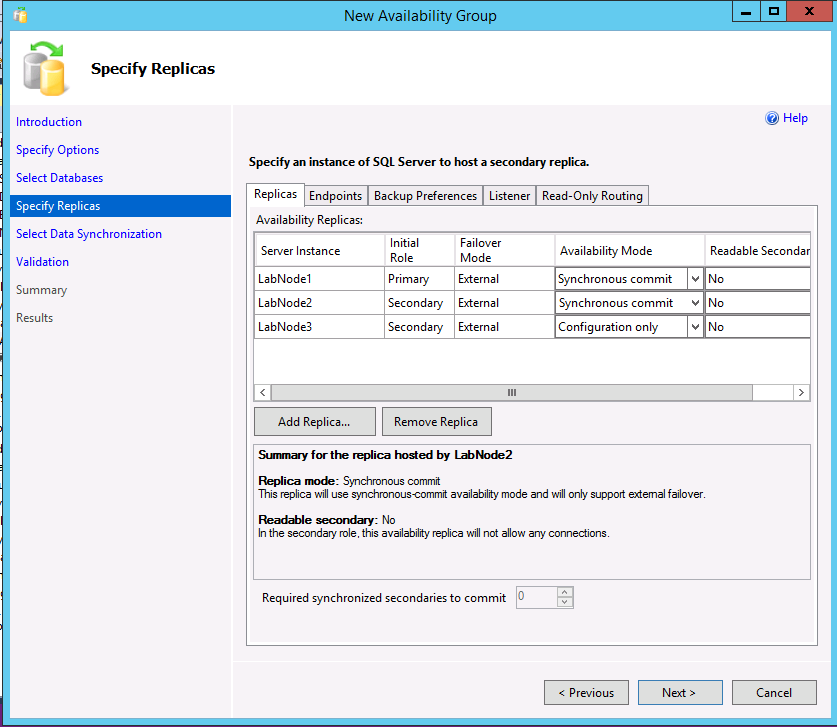
Las tres instancias aparecen en el diálogo Especificar réplicas. Si utiliza un tipo de clúster externo, para la réplica secundaria que es verdaderamente secundaria, asegúrese de que el modo de disponibilidad coincida con el de la réplica principal y que el modo de conmutación por error esté establecido en Externo. Para la réplica de solo configuración, seleccione el modo de disponibilidad correspondiente a configuración únicamente.
El siguiente ejemplo muestra un AG con dos réplicas, un tipo de clúster Externo y una réplica solo para configuración.
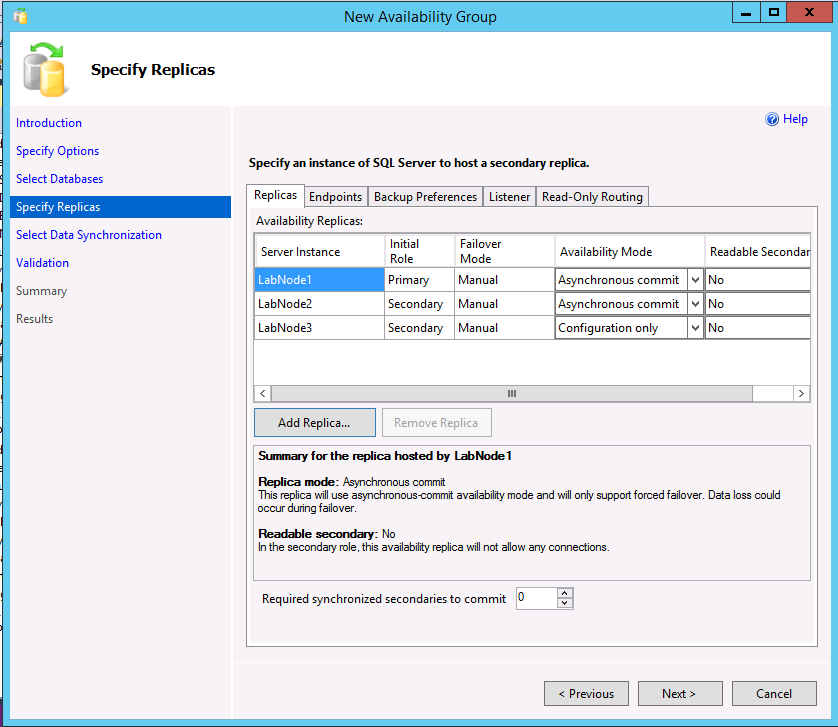
En el ejemplo siguiente se muestra un AG con dos réplicas, un tipo de clúster Ninguno y una réplica solo de configuración.
Si desea cambiar las preferencias de copia de seguridad, seleccione la pestaña Preferencias de copia de seguridad. Para obtener más información sobre las preferencias de copia de seguridad con grupos de disponibilidad, consulte Configuración de copias de seguridad en réplicas secundarias de un grupo de disponibilidad AlwaysOn.
Si utiliza secundarias legibles o crea un grupo de disponibilidad (AG) con un tipo de clúster 'None' para escala de lectura, puede crear un listener seleccionando la pestaña Listener. También puede agregar un listener más adelante. Para crear un agente de escucha, elija la opción Crear un agente de escucha del grupo de disponibilidad y escriba un nombre, un puerto TCP/IP y si se va a usar una dirección IP DHCP estática o asignada automáticamente. Para un grupo de disponibilidad con un tipo de clúster "None", la dirección IP debe ser estática y configurarse como la dirección IP principal.
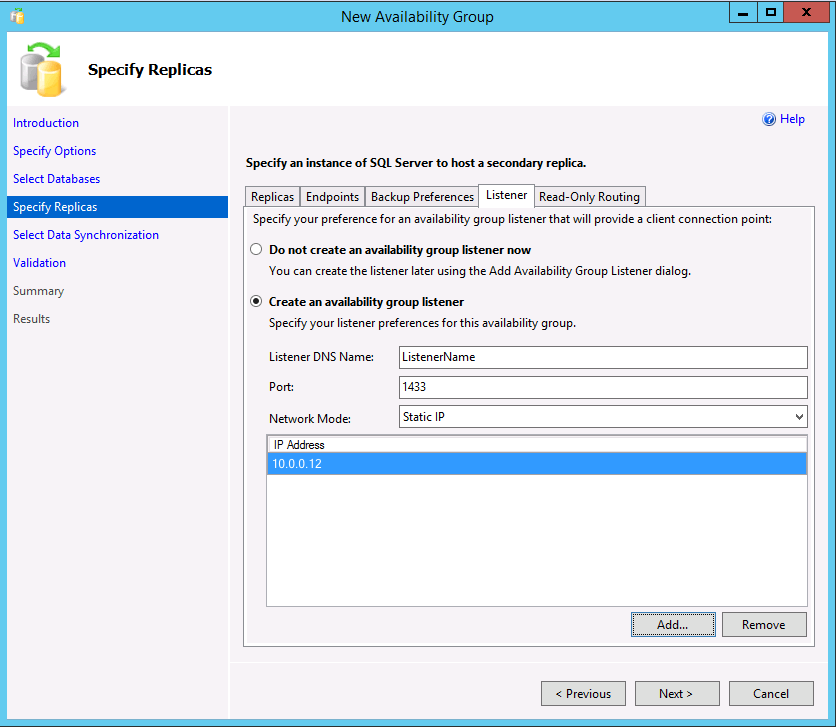
Si crea un agente de escucha para escenarios legibles, SSMS permite la creación del enrutamiento de solo lectura en el asistente. También puede agregarlo más adelante a través de SSMS o Transact-SQL. Para agregar enrutamiento de solo lectura ahora:
Seleccione la pestaña Read-Only Routing.
Ingrese las direcciones URL de las réplicas de solo lectura. Estas direcciones URL son similares a los puntos de conexión, salvo que usan el puerto de la instancia, no el punto de conexión.
- Seleccione cada dirección URL y, en la parte inferior, seleccione las réplicas legibles. Para seleccionar varios, mantenga presionada la tecla Mayús o seleccione arrastrar.
Seleccione Siguiente.
Elija cómo inicializar las réplicas secundarias. El valor predeterminado es usar replicación automática, que requiere la misma ruta de acceso en todos los servidores que participan en el grupo de disponibilidad (AG). También puede hacer que el asistente realice una copia de seguridad, copiar y restaurar (la segunda opción); puede hacerlo si ha realizado manualmente la copia de seguridad, copiado y restaurado la base de datos en las réplicas (tercera opción); o incorporar la base de datos más adelante (última opción). Al igual que con los certificados, si va a realizar copias de seguridad y copiarlas manualmente, establezca permisos en los archivos de copia de seguridad en las otras réplicas. Seleccione Siguiente.
En el cuadro de diálogo de Validación, si el asistente no devuelve Éxito para todas las comprobaciones, investigue a fondo. Algunas advertencias son aceptables y no son graves, por ejemplo si no se crea un cliente de escucha. Seleccione Siguiente.
En el cuadro de diálogo Resumen, seleccione Finalizar. El proceso de creación del grupo de disponibilidad ya comienza.
Una vez finalizada la creación del grupo de disponibilidad, seleccione Cerrar en los Resultados. Ahora puede ver el AG (grupo de disponibilidad) en las réplicas en las vistas de administración dinámica y en la carpeta Always On Alta disponibilidad de SSMS.




Uso de Transact-SQL
En esta sección se muestran ejemplos de creación de un AG (grupo de disponibilidad) mediante Transact-SQL. Puede configurar la escucha y el enrutamiento de solo lectura después de crear el grupo de disponibilidad. Puede modificar el propio grupo de disponibilidad mediante ALTER AVAILABILITY GROUP, pero no puede cambiar el tipo de clúster en SQL Server 2017 (14.x). Si no tenía la intención de crear un AG con un tipo de clúster Externo, debe eliminarlo y volver a crearlo con un tipo de clúster Ninguno. Para obtener más información y otras opciones, consulte los vínculos siguientes:
- CREAR GRUPO DE DISPONIBILIDAD (Transact-SQL)
- ALTERAR GRUPO DE DISPONIBILIDAD (Transact-SQL)
- Configuración del enrutamiento de solo lectura para un grupo de disponibilidad Always On
- Configuración de un agente de escucha para un grupo de disponibilidad Always On
Ejemplo A: Dos réplicas con una réplica solo de configuración (tipo de clúster externo)
En este ejemplo se muestra cómo crear un grupo de disponibilidad con dos réplicas que utiliza una réplica solo de configuración.
Ejecute la siguiente instrucción en el nodo que actúa como réplica principal y contiene la copia de lectura y escritura completa de las bases de datos. En este ejemplo se usa propagación automática.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE <DBName> REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N' TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC ), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', AVAILABILITY_MODE = CONFIGURATION_ONLY ); GOEn una ventana de consulta conectada a la otra réplica, ejecute la siguiente instrucción para unir la réplica al Grupo de Disponibilidad e iniciar el proceso de siembra desde la réplica principal a la réplica secundaria.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GOEn una ventana de consulta conectada a la réplica de solo configuración, ejecute la siguiente instrucción para unirla al grupo de disponibilidad.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO
Ejemplo B: Tres réplicas con enrutamiento de solo lectura (tipo de clúster Externo)
En este ejemplo se muestran tres réplicas completas y cómo puede configurar el enrutamiento de solo lectura como parte de la creación inicial del AG (grupo de disponibilidad).
Ejecute la siguiente instrucción en el nodo que actúa como réplica principal y contiene la copia de lectura y escritura completa de las bases de datos. En este ejemplo se usa propagación automática.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE < DBName > REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN2.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:1433') ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:1433') ), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN2.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN3.FullyQualified.Name:1433') ) LISTENER '<ListenerName>' ( WITH IP = ('<IPAddress>', '<SubnetMask>'), Port = 1433 ); GOAlgunos aspectos que se deben tener en cuenta sobre esta configuración:
-
AGNamees el nombre del AG. -
DBNamees el nombre de la base de datos que usas con el AG. También puede ser una lista de nombres separados por comas. -
ListenerNamees un nombre diferente de cualquiera de los servidores o nodos subyacentes. Se registra en DNS junto conIPAddress. -
IPAddresses una dirección IP asociada aListenerName. También es único y no es el mismo que ninguno de los servidores o nodos. Las aplicaciones y los usuarios finales usanListenerNameoIPAddresspara conectarse al AG.-
SubnetMaskes la máscara de subred deIPAddress. En SQL Server 2019 (15.x) y versiones anteriores, este valor es255.255.255.255. En SQL Server 2022 (16.x) y versiones posteriores, este valor es0.0.0.0.
-
-
En una ventana de consulta conectada a la otra réplica, ejecute la siguiente instrucción para unir la réplica al Grupo de Disponibilidad e iniciar el proceso de siembra desde la réplica principal a la réplica secundaria.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GORepita el paso 2 para la tercera réplica.
Ejemplo C: Dos réplicas con enrutamiento de solo lectura (clúster de tipo Ninguno)
En este ejemplo se muestra la creación de una configuración de dos réplicas con un tipo de clúster Ninguno. Utilice esta configuración para el escenario de escalado de lectura en el que no se espera ninguna conmutación por error. Este paso crea el listener que es en realidad la réplica principal y el enrutamiento de solo lectura, utilizando la funcionalidad de distribución equitativa (round robin).
Ejecute la siguiente instrucción en el nodo que actúa como réplica principal y contiene la copia de lectura y escritura completa de las bases de datos. En este ejemplo se usa propagación automática.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = NONE) FOR DATABASE <DBName> REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name: <PortOfEndpoint>', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, PRIMARY_ROLE( ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = (('LinAGN1.FullyQualified.Name'.'LinAGN2.FullyQualified.Name')) ), SECONDARY_ROLE( ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:<PortOfInstance>' ) ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfEndpoint>', FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ('LinAGN1.FullyQualified.Name', 'LinAGN2.FullyQualified.Name') )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfInstance>') ), LISTENER '<ListenerName>' (WITH IP = ( '<PrimaryReplicaIPAddress>', '<SubnetMask>'), Port = <PortOfListener> ); GOEn este ejemplo:
-
AGNamees el nombre del AG. -
DBNamees el nombre de la base de datos que usas con el AG. También puede ser una lista de nombres separados por comas. -
PortOfEndpointes el número de puerto que usa el punto de conexión que crea.-
PortOfInstancees el número de puerto que usa la instancia de SQL Server.
-
-
ListenerNamees un nombre que es diferente de cualquiera de las réplicas subyacentes, pero en realidad no se utiliza. -
PrimaryReplicaIPAddresses la dirección IP de la réplica principal.-
SubnetMaskes la máscara de subred deIPAddress. En SQL Server 2019 (15.x) y versiones anteriores, este valor es255.255.255.255. En SQL Server 2022 (16.x) y versiones posteriores, este valor es0.0.0.0.
-
-
Una la réplica secundaria al grupo de disponibilidad e inicie el aprovisionamiento automático.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = NONE); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GO
Crear el inicio de sesión de SQL Server y los permisos para Pacemaker
Un clúster de alta disponibilidad de Pacemaker que usa SQL Server en Linux necesita acceso a la instancia de SQL Server y permisos en el propio grupo de disponibilidad. Estos pasos crean el inicio de sesión y los permisos asociados, junto con un archivo que indica a Pacemaker cómo autenticarse en SQL Server.
En una ventana de consulta conectada a la réplica principal, ejecute la siguiente secuencia de comandos:
CREATE LOGIN PMLogin WITH PASSWORD = '<password>'; GO GRANT VIEW SERVER STATE TO PMLogin; GO GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::<AGThatWasCreated> TO PMLogin; GOEn el nodo 1, escriba el comando :
sudo emacs /var/opt/mssql/secrets/passwdEste comando abre el editor de Emacs.
Escriba las dos líneas siguientes en el editor:
PMLogin <password>Mantenga presionada la tecla
Ctrly presioneX; luegoC, para salir y guardar el archivo.Ejecute:
sudo chmod 400 /var/opt/mssql/secrets/passwdpara bloquear el archivo.
Repita los pasos 1 a 5 en los demás servidores que actúan como réplicas.
Crear los recursos del grupo de disponibilidad en el clúster de Pacemaker (solamente externo)
Después de crear un GA en SQL Server, debe crear los recursos correspondientes en Pacemaker al especificar un clúster de tipo 'Externo'. Un grupo de disponibilidad (AG) necesita dos recursos: el recurso de grupo de disponibilidad y un recurso de dirección IP. La configuración del recurso de dirección IP es opcional si no usa un agente de escucha. Sin embargo, se recomienda cuando necesite funcionalidades de escucha.
El recurso AG que cree es un tipo de recurso denominado clon. El recurso AG tiene copias en cada nodo y un recurso de control denominado como maestro. El maestro está asociado con el servidor que hospeda la réplica principal. Los demás recursos hospedan réplicas secundarias (estándar o solo de configuración) y pueden ascender a master en una conmutación por error.
Nota:
En SQL Server 2025 (17.x) con la actualización acumulativa (CU) 3 y versiones posteriores, el agente HA de Pacemaker v2 (versión preliminar) está disponible para Red Hat Enterprise Linux (RHEL) y Ubuntu a través del paquete mssql-server-ha. Las implementaciones no productivas pueden evaluar el agente de HA de Pacemaker v2. El agente de alta disponibilidad de Pacemaker existente (v1) sigue siendo totalmente compatible con las implementaciones de producción. Para más información, consulte Agente de alta disponibilidad de Pacemaker v2 (versión preliminar).
Agente HA de Pacemaker v1
Cree el recurso AG en Pacemaker mediante el agente de HA de Pacemaker (v1): (
ocf:mssql:ag)sudo pcs resource create <NameForAGResource> ocf:mssql:ag ag_name=<AGName> meta failure-timeout=30s promotable notify=trueEn este ejemplo,
NameForAGResourcees el nombre único que se asigna a este recurso de clúster para el Grupo de Disponibilidad yAGNamees el nombre del Grupo de Disponibilidad que creó.Cree el recurso de dirección IP para el AG que asocia con la funcionalidad de escucha.
sudo pcs resource create <NameForIPResource> ocf:heartbeat:IPaddr2 ip=<IPAddress> cidr_netmask=<Netmask>En este ejemplo,
NameForIPResourcees el nombre único del recurso IP yIPAddresses la dirección IP estática que se asigna al recurso.Para asegurarse de que la dirección IP y el recurso de AG se ejecuten en el mismo nodo, configure una restricción de colocación.
sudo pcs constraint colocation add <NameForIPResource> with promoted <NameForAGResource>-clone INFINITYEn este ejemplo,
NameForIPResourcees el nombre del recurso IP yNameForAGResourcees el nombre del recurso AG.Cree una restricción de orden para asegurarse de que el recurso del Grupo de Disponibilidad esté activo y funcionando antes que la dirección IP. Si bien la restricción de coubicación implica una restricción de ordenación, este paso la refuerza.
sudo pcs constraint order promote <NameForAGResource>-clone then start <NameForIPResource>En este ejemplo,
NameForIPResourcees el nombre del recurso IP yNameForAGResourcees el nombre del recurso AG.
Agente de alta disponibilidad de Pacemaker v2 (versión preliminar)
El agente de alta disponibilidad de Pacemaker v2 usa una arquitectura basada en servicios. El agente se ejecuta como un servicio de sistema dedicado denominado mssql-pcsag, que es responsable de controlar las operaciones de alta disponibilidad específicas de SQL Server y la comunicación con Pacemaker.
El mssql-pcsag servicio se administra mediante controles de servicio del sistema estándar. Puede iniciar, detener, reiniciar y comprobar el estado de este servicio según sea necesario mediante los siguientes comandos:
sudo systemctl start mssql-pcsag # Start the Pacemaker HA agent v2 (mssql-pcsag) service
sudo systemctl stop mssql-pcsag # Stop the Pacemaker HA agent v2 (mssql-pcsag) service
sudo systemctl restart mssql-pcsag # Restart the Pacemaker HA agent v2 (mssql-pcsag) service
sudo systemctl status mssql-pcsag # Check the status of the Pacemaker HA agent v2 (mssql-pcsag) service
Pacemaker interactúa con los grupos de disponibilidad de SQL Server a través del mssql-pcsag servicio. Para que la supervisión y la conmutación por error del grupo de disponibilidad funcionen correctamente:
- El clúster de Pacemaker debe ejecutarse.
- El
mssql-pcsagservicio debe ejecutarse.
Aunque Pacemaker y mssql-pcsag se implementan como componentes independientes, funcionan juntos en tiempo de ejecución. Si se detienen Pacemaker o el servicio mssql-pcsag, las operaciones de conmutación por error del grupo de disponibilidad no funcionan según lo previsto.
Nota:
Reiniciar el mssql-pcsag servicio no reinicia SQL Server. Del mismo modo, reiniciar SQL Server no reinicia automáticamente el agente de alta disponibilidad de Pacemaker. Compruebe que ambos servicios se ejecutan durante la solución de problemas.
El agente de Alta Disponibilidad (HA) de Pacemaker v2 introduce mejoras en fiabilidad y rendimiento en comparación con el agente anterior, que incluyen:
Se ha mejorado el rendimiento de la conmutación por error para reducir los tiempos de conmutación por error planeados y no planeados.
Compatibilidad con directivas de conmutación por error automática flexibles, incluida la configuración del nivel de condición de error y el tiempo de espera para la comprobación del estado.
Ejemplo: la siguiente instrucción Transact-SQL cambia el nivel de condición de error de un grupo de disponibilidad existente denominado AG1 al nivel 2:
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);Ejemplo: la siguiente instrucción Transact-SQL cambia el umbral de tiempo de espera de comprobación de estado de un grupo de disponibilidad existente denominado AG1 a 60 000 milisegundos (60 segundos).
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT = 60000);Ejemplo: Después de aplicar la configuración, use la siguiente instrucción Transact-SQL para comprobar el nivel de condición de error configurado y el tiempo de espera de comprobación de estado para los grupos de disponibilidad.
SELECT failure_condition_level, health_check_timeout FROM sys.availability_groups;Compatibilidad con TLS 1.3 para la comunicación entre el clúster de Pacemaker y SQL Server.
Cree el recurso AG en Pacemaker mediante el agente de alta disponibilidad de Pacemaker v2: (
ocf:mssql:agv2)sudo pcs resource create <NameForAGResource> ocf:mssql:agv2 ag_name=<AGName> meta failure-timeout=30s promotable notify=trueSi actualiza desde el agente de alta disponibilidad de Pacemaker v1 a v2, quite el recurso AG existente antes de crear el
agv2recurso.sudo pcs resource delete <NameForAGResource>Esta operación detiene temporalmente la sincronización del grupo de disponibilidad (AG) mientras se está recreando el recurso. Al eliminar y volver a crear el recurso del grupo de disponibilidad de Pacemaker, no se elimina el grupo de disponibilidad. Después de recrear el recurso, Pacemaker reanuda automáticamente la administración y la sincronización de AG.
Cree el recurso de dirección IP para el AG que asocia con la funcionalidad de escucha.
sudo pcs resource create <NameForIPResource> ocf:heartbeat:IPaddr2 ip=<IPAddress> cidr_netmask=<Netmask>En este ejemplo,
NameForIPResourcees el nombre único del recurso IP yIPAddresses la dirección IP estática que se asigna al recurso.Para asegurarse de que la dirección IP y el recurso de AG se ejecuten en el mismo nodo, configure una restricción de colocación.
sudo pcs constraint colocation add <NameForIPResource> with promoted <NameForAGResource>-clone INFINITYEn este ejemplo,
NameForIPResourcees el nombre del recurso IP yNameForAGResourcees el nombre del recurso AG.Cree una restricción de orden para asegurarse de que el recurso del Grupo de Disponibilidad esté activo y funcionando antes que la dirección IP. Si bien la restricción de coubicación implica una restricción de ordenación, este paso la refuerza.
sudo pcs constraint order promote <NameForAGResource>-clone then start <NameForIPResource>En este ejemplo,
NameForIPResourcees el nombre del recurso IP yNameForAGResourcees el nombre del recurso AG.