Diagnóstico y resolución de contención de bloqueos por subproceso en SQL Server
En este artículo se ofrece información detallada sobre cómo identificar y resolver problemas relacionados con la contención de bloqueos por subproceso de aplicaciones de SQL Server en sistemas de alta simultaneidad.
Nota:
Las recomendaciones y los procedimientos recomendados que se documentan aquí se basan en la experiencia práctica durante el desarrollo y la implementación de sistemas OLTP reales. Fue publicado originalmente por el equipo de Microsoft SQL Server Customer Advisory Team (SQLCAT).
Fondo
En el pasado, los equipos con Windows Server estándar solo usaban uno o dos chips de microprocesador/CPU y las CPU se diseñaban con un solo procesador o "núcleo". El aumento de la capacidad de procesamiento de los equipos se ha logrado mediante el uso de CPU más rápidas, lo que ha sido posible en gran medida gracias a los avances en la densidad de transistores. De acuerdo con la ley de Moore, la densidad de transistores o el número de transistores que se pueden colocar en un circuito integrado se han duplicado constantemente cada dos años desde el desarrollo de la primera CPU de un solo chip de uso general en 1971. En los últimos años, el enfoque tradicional de aumentar la capacidad de procesamiento de los equipos con CPU más rápidas se ha incrementado gracias a la creación de equipos con varias CPU. En el momento de redactar este documento, la arquitectura de CPU Intel Nehalem admite hasta ocho núcleos por CPU, que cuando se usan en un sistema de ocho sockets se pueden duplicar a 128 procesadores lógicos mediante el uso de la tecnología de subprocesamiento múltiple simultáneo (SMT). En las CPU de Intel, SMT se denomina Hyper-Threading. A medida que aumenta el número de procesadores lógicos en equipos compatibles con x86, los problemas relacionados con la simultaneidad aumentan debido a que los procesadores lógicos compiten por los recursos. En esta guía se explica cómo identificar y resolver problemas de contención de bloqueo concretos observados al ejecutar aplicaciones de SQL Server en sistemas de alta simultaneidad con algunas cargas de trabajo.
En esta sección, analizamos las lecciones aprendidas por el equipo de SQLCAT desde el diagnóstico y la resolución de problemas de contención de bloqueos por subproceso. La contención de bloqueos por subproceso es un tipo de problema de simultaneidad observado en cargas de trabajo de clientes reales en sistemas de gran escala.
Síntomas y causas de la contención de bloqueos por subproceso
En esta sección se describe cómo diagnosticar problemas de la contención de bloqueos por subproceso, que es perjudicial para el rendimiento de las aplicaciones OLTP en SQL Server. El diagnóstico y la solución de problemas de bloqueo por subproceso se deben considerar un tema avanzado, que requiere conocimiento de las herramientas de depuración y los elementos internos de Windows.
Los bloqueos por subproceso son primitivos de sincronización ligeros que se usan para proteger el acceso a las estructuras de datos. Los bloqueos por subproceso no son exclusivos de SQL Server. El sistema operativo los utiliza cuando el acceso a una estructura de datos determinada solo es necesario durante un breve período de tiempo. Cuando un subproceso que intenta adquirir un bloqueo por subproceso no puede obtener acceso, se ejecuta en un bucle que se comprueba periódicamente para determinar si el recurso está disponible en lugar de suspenderlo inmediatamente. Tras un período de tiempo, un subproceso que espera en un bloqueo por subproceso se suspenderá antes de que pueda adquirir el recurso. La suspensión permite que se ejecuten otros subprocesos en ejecución en la misma CPU. Este comportamiento se conoce como interrupción y se explica con más detalle más adelante en este artículo.
SQL Server emplea bloqueos por subproceso para proteger el acceso a algunas de sus estructuras de datos internas. Los bloqueos por subproceso se usan en el motor para serializar el acceso a determinadas estructuras de datos de manera similar a los bloqueos temporales. La principal diferencia entre un bloqueo temporal y un bloqueo por subproceso es el hecho de que estos últimos giran (se ejecutan un bucle) durante un período de tiempo para comprobar la disponibilidad de una estructura de datos, mientras que un subproceso que intente obtener acceso a una estructura protegida por un bloqueo temporal se suspende inmediatamente si el recurso no está disponible. La suspensión requiere el cambio de contexto de un subproceso de la CPU para que otro subproceso pueda ejecutarse. Se trata de una operación relativamente costosa y, en el caso de los recursos que se retienen durante un período breve, resulta más eficiente en general permitir que un subproceso se ejecute en un bucle que compruebe periódicamente la disponibilidad del recurso.
Los ajustes internos del motor de base de datos introducidos en SQL Server 2022 (16.x) hacen que los bloqueos por subproceso sean más eficaces.
Síntomas
En los sistemas de alta simultaneidad con mucha actividad, es normal ver la contención activa en las estructuras a las que se accede con frecuencia y que están protegidas por bloqueos por subproceso. Este uso solo se considera problemático cuando la contención presenta una sobrecarga de CPU significativa. Las estadísticas de bloqueo por subproceso se exponen en la vista de administración dinámica (DMV) sys.dm_os_spinlock_stats dentro de SQL Server. Por ejemplo, esta consulta produce el siguiente resultado:
Nota:
Más adelante en este artículo se explicará más detalladamente cómo interpretar la información que devuelve esta DMV.
SELECT * FROM sys.dm_os_spinlock_stats
ORDER BY spins DESC;
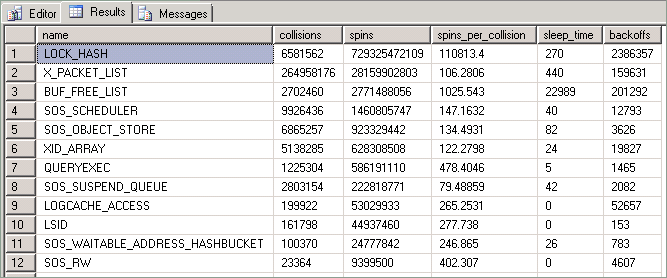
Las estadísticas expuestas por esta consulta se describen de la siguiente manera:
| Column | Descripción |
|---|---|
| Collisions | Este valor se incrementa cada vez que se bloquea el acceso de un subproceso a un recurso protegido por un bloqueo por subproceso. |
| Spins | Este valor se incrementa cada vez que un subproceso ejecuta un bucle mientras espera que un bloqueo por subproceso esté disponible. Se trata de una medida de la cantidad de trabajo que realiza un subproceso mientras intenta adquirir un recurso. |
| Spins_per_collision | Proporción de giros por colisión. |
| Sleep time | Relacionado con los eventos de interrupción; no obstante, no es relevante para las técnicas descritas en este artículo. |
| Backoffs | Se producen cuando un subproceso de "giro" que intenta acceder a un recurso retenido ha determinado que tiene que permitir que se ejecuten otros subprocesos en la misma CPU. |
A los efectos de este análisis, las estadísticas de especial interés son el número de colisiones, los giros y los eventos de interrupción que se producen dentro de un período específico cuando el sistema está sobrecargado. Cuando un subproceso intenta acceder a un recurso protegido por un bloqueo por subproceso, se produce una colisión. Cuando se produce una colisión, el número de colisiones se incrementa y el subproceso empieza a girar en un bucle y comprueba periódicamente si el recurso está disponible. Cada vez que el subproceso gira (en bucle), se incrementa el número de giros.
Los giros por colisión son una medida de la cantidad de giros que se producen mientras un subproceso retiene un bloqueo por subproceso y te indicarán cuántos giros se producen mientras los subprocesos retienen el bloqueo por subproceso. Por ejemplo, pocos giros por colisión y un número elevado de colisiones implican que hay una pequeña cantidad de giros en el bloqueo por subproceso y que hay muchos subprocesos que compiten por él. Una gran cantidad de giros significa que el tiempo dedicado a girar en el código del bloqueo por subproceso es relativamente prolongado (es decir, el código pasa por un gran número de entradas en un cubo de hash). A medida que aumenta la contención (lo que aumenta el número de colisiones), también aumenta el número de giros.
Las interrupciones se pueden considerar de manera similar a los giros. Por diseño, para evitar el exceso de desperdicio de CPU, los bloqueos por subproceso no siguen girando indefinidamente hasta que puedan acceder a un recurso retenido. Para asegurarse de que un bloqueo por subproceso no hace un uso excesivo de los recursos de CPU, los bloqueos por subproceso se interrumpen o dejan de girar y entran en suspensión. Los bloqueos por subproceso se interrumpen con independencia de si alguna vez obtienen la propiedad del recurso de destino. Esto se hace para permitir la programación de otros subprocesos en la CPU con la esperanza de que esto pueda permitir que se produzca un trabajo más productivo. El comportamiento predeterminado del motor consiste en girar durante un intervalo de tiempo continuo antes de realizar una interrupción. El intento de obtener un bloqueo por subproceso requiere que se mantenga un estado de simultaneidad de caché, que es una operación de gran consumo de CPU en relación con el costo de CPU del giro. Por lo tanto, los intentos de obtener un bloqueo por subproceso se realizan con moderación y no se realizan cada vez que un subproceso gira. En SQL Server, ciertos tipos de bloqueo por subproceso (por ejemplo: LOCK_HASH) utilizando un intervalo que aumenta exponencialmente entre intentos de adquisición del bloqueo por subproceso (hasta un límite determinado), lo que a menudo reduce el efecto en el rendimiento de la CPU.
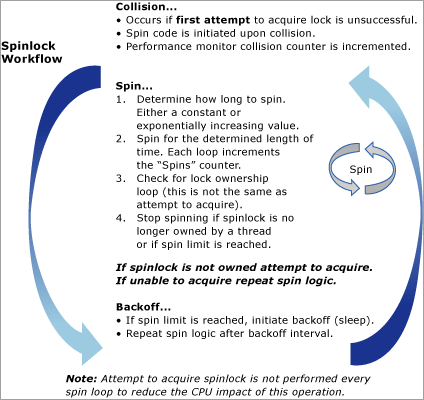
El siguiente diagrama ofrece una vista conceptual del algoritmo de bloqueo por subproceso:
Escenarios típicos
La contención de bloqueos por subproceso puede producirse por una serie de motivos que pueden no estar relacionados con las decisiones de diseño de bases de datos. Dado que los bloqueos por subproceso acceden a estructuras de datos internas, la contención de bloqueos por subproceso no se manifiesta de la misma manera que la contención de bloqueos temporales de búfer, que se ve afectada directamente por las opciones de diseño de esquemas y los patrones de acceso a datos.
El síntoma asociado principalmente a la contención de bloqueos por subproceso es un uso elevado de CPU como resultado del gran número de giros y los muchos subprocesos que intentan adquirir el mismo bloqueo por subproceso. En general, esto se ha observado en sistemas de >= 24 y normalmente en sistemas de >= 32 núcleos de CPU. Tal y como se indicó antes, cierto nivel de contención en bloqueos por subproceso es normal en sistemas OLTP de alta simultaneidad con una carga significativa y, a menudo, hay un gran número de giros (miles de millones o billones) que se indican en la DMV sys.dm_os_spinlock_stats en sistemas que se han ejecutado durante mucho tiempo. De nuevo, la observación de un número elevado de giros para un tipo determinado de bloqueo por subproceso no es información suficiente para determinar que hay un efecto negativo en el rendimiento de la carga de trabajo.
Una combinación de varios de los síntomas siguientes puede indicar contención de bloqueos por subproceso:
Se observa un gran número de giros e interrupciones para un tipo determinado de bloqueo por subproceso.
El sistema experimenta un uso intensivo de CPU o picos en el consumo de CPU. En escenarios de uso intensivo de CPU, verás esperas de señal elevadas en SOS_SCHEDULER_YIELD (que se muestran en la DMV
sys.dm_os_wait_stats).El sistema está experimentando una alta simultaneidad.
El uso de CPU y los giros aumentan de forma desproporcionada en relación con el rendimiento.
Importante
Aunque se cumplan todas las condiciones anteriores, es posible que la causa principal del uso elevado de CPU sea otra. De hecho, en la gran mayoría de los casos, el aumento de uso de CPU se debe a motivos distintos de la contención de bloqueos por subproceso. Algunas de las causas más comunes del aumento de consumo de CPU son las siguientes:
Consultas que son más costosas con el tiempo debido al crecimiento de los datos subyacentes, lo que se traduce en la necesidad de realizar lecturas lógicas adicionales de los datos residentes en memoria.
Cambios en los planes de consulta que dan lugar a una ejecución mejorable.
Si se cumplen todas estas condiciones, realice una investigación más profunda sobre los posibles problemas de contención de bloqueos por subproceso.
Un fenómeno común diagnosticado fácilmente es una divergencia significativa en el rendimiento y el uso de la CPU. Muchas cargas de trabajo OLTP tienen una relación entre el rendimiento y el número de usuarios del sistema y el consumo de CPU. Un alto número de giros junto con una divergencia significativa del consumo y el rendimiento de CPU pueden ser una señal de contención de bloqueos por subproceso que supone una sobrecarga de la CPU. Una cuestión importante que hay que tener en cuenta es que también es común ver este tipo de divergencia en los sistemas cuando ciertas consultas son más costosas con el tiempo. Por ejemplo, las consultas ejecutadas en conjuntos de datos que realizan más lecturas lógicas a lo largo del tiempo pueden producir síntomas similares.
Es fundamental descartar otras causas más comunes de uso elevado de CPU al solucionar este tipo de problemas.
Ejemplos
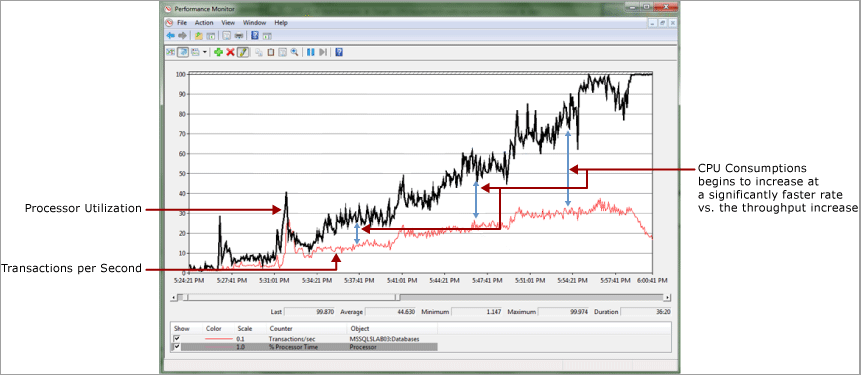
En el ejemplo siguiente, hay una relación casi lineal entre el consumo de CPU y el rendimiento, medida en transacciones por segundo. Es normal ver algunas divergencias aquí porque la sobrecarga se produce a medida que aumenta la carga de trabajo. Como se muestra aquí, esta divergencia pasa a ser significativa. También hay una caída vertiginosa del rendimiento cuando el consumo de CPU alcanza el 100 %.
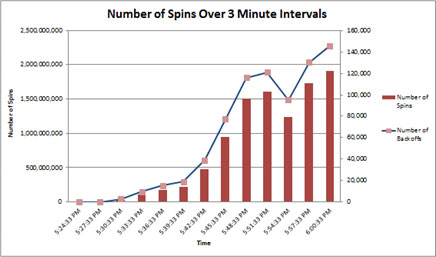
Al medir el número de giros en intervalos de tres minutos, se puede ver un aumento más exponencial que lineal en los giros, lo que indica que la contención de bloqueos por subproceso puede ser problemática.
Como se indicó anteriormente, los bloqueos por subproceso son más comunes en los sistemas de alta simultaneidad que están sobrecargados.
Entre los escenarios que son propensos a este problema se incluyen los siguientes:
Problemas de resolución de nombres causados por no usar nombres completos de objetos. Para obtener más información, consulte el artículo sobre la descripción de los bloqueos de SQL Server causados por bloqueos de compilación. Este problema específico se describe con más detalle en este artículo.
Contención de cubos de hash de bloqueo en el administrador de bloqueos para cargas de trabajo que acceden con frecuencia al mismo bloqueo (por ejemplo, un bloqueo compartido en una fila de lectura frecuente). Este tipo de contención surge como un bloqueo por subproceso de tipo LOCK_HASH. En un caso en concreto, vimos que este problema surgió como resultado de patrones de acceso modelados incorrectamente en un entorno de prueba. En este entorno, un número de subprocesos mayor que el esperado accedía constantemente a la misma fila exacta debido a parámetros de prueba incorrectamente configurados.
Alta tasa de transacciones DTC cuando hay un alto grado de latencia entre los coordinadores de transacciones MSDTC. Este problema específico se documenta en detalle en la entrada de blog de SQLCAT sobre la resolución de las esperas relacionadas con DTC y la optimización de la escalabilidad de DTC.
Diagnosticar la contención de bloqueos por subproceso
En este sección se ofrece información sobre la contención de bloqueos por subproceso de SQL Server. Las herramientas principales que se usan para diagnosticar la contención de bloqueos por subproceso son las siguientes:
| Herramienta | Usar |
|---|---|
| Supervisión del rendimiento | Busque condiciones de uso elevado de CPU o divergencia entre el rendimiento y el consumo de CPU. |
sys.dm_os_spinlock stats DMV** |
Busque un gran número de giros y eventos de interrupción durante períodos de tiempo. |
| Eventos extendidos de SQL Server | Se usa para realizar el seguimiento de las pilas de llamadas de bloqueos por subproceso que experimentan un alto número de giros. |
| Volcados de memoria | En algunos casos, los volcados de memoria del proceso de SQL Server y las herramientas de depuración de Windows. En general, este nivel de análisis se realiza cuando se involucran los equipos de soporte técnico de Microsoft SQL Server. |
El proceso técnico general para diagnosticar la contención de bloqueos por subproceso de SQL Server es el siguiente:
Paso 1: Determinar que existe contención que puede estar relacionada con un bloqueo por subproceso.
Paso 2: capturar estadísticas de
sys.dm_ os_spinlock_stats para encontrar el tipo de bloqueo por subproceso que tiene más contención.Paso 3: Obtener símbolos de depuración para sqlservr.exe (sqlservr.pdb) y colocar los símbolos en el mismo directorio que el archivo .exe (sqlservr. exe) del servicio SQL Server para la instancia de SQL Server. \ Para ver las pilas de llamadas de los eventos de interrupción, debes tener símbolos para la versión concreta de SQL Server que se ejecute. Los símbolos para SQL Server están disponibles en el servidor de símbolos de Microsoft. Para obtener más información sobre cómo descargar símbolos del servidor de símbolos de Microsoft, consulte el artículo sobre la depuración con símbolos.
Paso 4: Usar eventos extendidos de SQL Server para realizar un seguimiento de los eventos de interrupción de los tipos de bloqueo por subproceso de interés.
Los eventos extendidos ofrecen la posibilidad de realizar un seguimiento del evento de “interrupción” y capturar la pila de llamadas de la(s) operacion(es) que intentan obtener el bloqueo por subproceso con mayor frecuencia. Mediante el análisis de la pila de llamadas, es posible determinar qué tipo de operación contribuye a la contención de cualquier bloqueo por subproceso concreto.
Tutorial de diagnóstico
En el siguiente tutorial se muestra cómo usar las herramientas y técnicas para diagnosticar un problema de contención de bloqueos por subproceso en un escenario real. Este tutorial se basa en una interacción con el cliente que ejecuta un banco de pruebas de rendimiento para simular aproximadamente 6500 usuarios simultáneos en un servidor de 8 sockets y 64 núcleos físicos con 1 TB de memoria.
Síntomas
Se observaron picos periódicos en la CPU, que llevó la utilización de la CPU a casi el 100 %. Se observó una divergencia entre el rendimiento y el consumo de CPU que originó el problema. En el momento en que se produjo el mayor pico de CPU, se estableció un patrón en el que se producía un gran número de giros durante los períodos de uso intensivo de CPU en intervalos concretos.
Se trataba de un caso extremo en el que la contención era tal que creaba una condición de convoy de bloqueos por subproceso. Un convoy se produce cuando los subprocesos ya no pueden dar servicio a la carga de trabajo, sino que emplean todos los recursos de procesamiento que intentan obtener acceso al bloqueo. El registro del monitor de rendimiento muestra esta divergencia entre el rendimiento del registro de transacciones y el consumo de CPU y, en última instancia, el mayor pico en el uso de CPU.
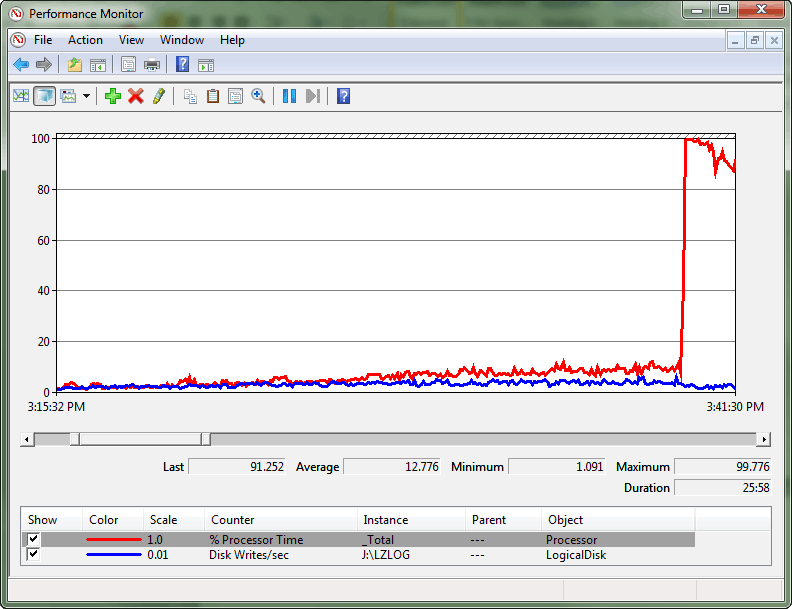
Tras consultar sys.dm_os_spinlock_stats para determinar la existencia de una contención significativa en SOS_CACHESTORE, se usó un script de eventos extendidos para medir el número de eventos de interrupción de los tipos de bloqueo por subproceso de interés.
| Nombre | Collisions | Giros | Giros por colisión | Backoffs |
|---|---|---|---|---|
SOS_CACHESTORE |
14,752,117 | 942,869,471,526 | 63,914 | 67,900,620 |
SOS_SUSPEND_QUEUE |
69,267,367 | 473,760,338,765 | 6,840 | 2,167,281 |
LOCK_HASH |
5,765,761 | 260,885,816,584 | 45,247 | 3,739,208 |
MUTEX |
2,802,773 | 9,767,503,682 | 3,485 | 350,997 |
SOS_SCHEDULER |
1,207,007 | 3,692,845,572 | 3,060 | 109,746 |
La manera más sencilla de cuantificar el efecto de los giros es observar el número de eventos de interrupción expuestos por sys.dm_os_spinlock_stats en el mismo intervalo de un minuto correspondientes a los tipos de bloqueo por subproceso con mayor número de giros. Este método es mejor para detectar una contención significativa porque indica cuando los subprocesos están agotando el límite de giros mientras esperan adquirir el bloqueo por subproceso. En el siguiente script se muestra una técnica avanzada que utiliza eventos extendidos para medir los eventos de interrupción relacionados e identificar las rutas de acceso al código específicas en las que se encuentra la contención.
Para obtener más información acerca de los eventos extendidos en SQL Server, consulte el artículo de introducción a los eventos extendidos de SQL Server.
Script
/*
This script is provided "AS IS" with no warranties, and confers no rights.
This script will monitor for backoff events over a given period of time and
capture the code paths (callstacks) for those.
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
Examples:
61LOCK_HASH
144 SOS_CACHESTORE
08MUTEX
*/
--create the even session that will capture the callstacks to a bucketizer
--more information is available in this reference: http://msdn.microsoft.com/en-us/library/bb630354.aspx
CREATE EVENT SESSION spin_lock_backoff ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
OR TYPE = 144 --SOS_CACHESTORE
OR TYPE = 8 --MUTEX
) ADD TARGET package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
);
--Ensure the session was created
SELECT * FROM sys.dm_xe_sessions
WHERE name = 'spin_lock_backoff';
--Run this section to measure the contention
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = START;
--wait to measure the number of backoffs over a 1 minute period
WAITFOR DELAY '00:01:00';
--To view the data
--1. Ensure the sqlservr.pdb is in the same directory as the sqlservr.exe
--2. Enable this trace flag to turn on symbol resolution
DBCC TRACEON (3656, -1);
--Get the callstacks from the bucketize target
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spin_lock_backoff';
--clean up the session
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = STOP;
DROP EVENT SESSION spin_lock_backoff ON SERVER;
Mediante el análisis de la salida, podemos ver las pilas de llamadas de las rutas de acceso al código más comunes para los giros de SOS_CACHESTORE. El script se ejecutó un par de veces distintas en el momento en que el uso de CPU era elevado para comprobar la coherencia de las pilas de llamadas devueltas. Las pilas de llamadas con el mayor número de cubos de ranuras son comunes entre las dos salidas (35 668 y 8506). Estas pilas de llamadas tienen un "número de ranuras" que es dos órdenes de magnitud mayor que la siguiente entrada más alta. Esta condición indica una ruta de acceso al código de interés.
Nota:
No es raro ver pilas de llamadas devueltas por el script anterior. Cuando el script se ejecutó durante 1 minuto, observamos que las pilas de llamadas con > de 1000 ranuras eran problemáticas. Sin embargo, las de > de 10 000 presentaban más probabilidades de crear problemas, ya que el número de ranuras era mayor.
Nota:
El formato de la siguiente salida se ha limpiado con fines de legibilidad.
Salida 1
<BucketizerTarget truncated="0" buckets="256">
<Slot count="35668" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid
CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey
CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="752" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
Salida 2
<BucketizerTarget truncated="0" buckets="256">
<Slot count="8506" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep+c7 [ @ 0+0x0 SpinlockBase::Backoff Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="190" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
En el ejemplo anterior, las pilas más interesantes tienen el número de ranuras más alto (35 668 y 8 506), que, de hecho, tienen un recuento de ranuras > 1000.
Puede que ahora la pregunta sea: "¿qué hago con esta información?". En general, se requiere un conocimiento profundo del motor de SQL Server para utilizar la información de la pila de llamadas, por lo que en este momento el proceso de resolución de problemas pasa a una zona gris. En este caso concreto, al examinar las pilas de llamadas, podemos ver que la ruta de acceso al código donde se produce el problema está relacionada con las búsquedas de metadatos y la seguridad (como se muestra en los siguientes marcos de pila CMEDCatalogOwner::GetProxyOwnerBySID & CMEDProxyDatabase::GetOwnerBySID)).
De forma aislada, es difícil utilizar esta información para resolver el problema, pero nos ofrece algunas ideas en las que centraremos la solución de problemas adicionales para aislar el problema.
Dado que este problema parecía estar relacionado con las rutas de acceso al código que realizan comprobaciones relacionadas con la seguridad, decidimos ejecutar una prueba en la que el usuario de la aplicación que se conecta a la base de datos tuviera privilegios de sysadmin. Aunque esta técnica nunca se recomienda en un entorno de producción, en nuestro entorno de prueba resultó ser un paso útil para la solución de problemas. Cuando las sesiones se ejecutaron con privilegios elevados (sysadmin), desaparecieron los picos de CPU relacionados con la contención.
Opciones y soluciones alternativas
Claramente, la solución de problemas de contención de bloqueos por subproceso puede ser una tarea nada sencilla. No hay un enfoque único y perfecto. El primer paso para solucionar un problema de rendimiento es identificar la causa principal. El uso de las técnicas y las herramientas que se describen en este artículo es el primer paso para realizar el análisis necesario para comprender los puntos de contención relacionados con el bloqueo por subproceso.
A medida que se desarrollan nuevas versiones de SQL Server, el motor continúa mejorando la escalabilidad implementando código que se optimiza mejor para sistemas de alta simultaneidad. SQL Server ha incorporado muchas optimizaciones para sistemas de alta simultaneidad, una de las cuales es una interrupción exponencial de los puntos de contención más comunes. Hay mejoras específicas que comienzan en SQL Server 2012 que mejoran específicamente este área en particular aprovechando los algoritmos de interrupción exponencial para todos los bloqueos por subproceso del motor.
Al diseñar aplicaciones avanzadas que necesiten un rendimiento y una escala extremos, considere la posibilidad de mantener la ruta de acceso al código necesaria en SQL Server lo más corta posible. Una ruta de acceso al código más corta significa que el motor de base de datos realiza menos trabajo y, de forma natural, evita puntos de contención. Muchos procedimientos recomendados tienen un efecto secundario en la reducción de la cantidad de trabajo que se requiere del motor y, por lo tanto, se traducen en la optimización del rendimiento de la carga de trabajo.
Tomaremos un par de procedimientos recomendados de los vistos en este artículo como ejemplos:
Nombres completos: El uso de nombres completos de todos los objetos eliminarán la necesidad de que SQL Server ejecute rutas de acceso al código que sean necesarias para resolver nombres. También se han observado puntos de contención en el tipo de bloqueo por subproceso SOS_CACHESTORE que se encuentra cuando no se usan nombres completos en llamadas a procedimientos almacenados. Si no se usan nombres completos, es necesario que SQL Server busque el esquema predeterminado del usuario, lo que da como resultado que se necesite una ruta de acceso al código más larga para ejecutar la instrucción SQL.
Consultas con parámetros: Otro ejemplo es el uso de consultas con parámetros y llamadas a procedimientos almacenados para reducir el trabajo necesario para generar planes de ejecución. De nuevo, esto da como resultado una ruta de acceso al código más corta para la ejecución.
Contención LOCK_HASH: En algunos casos, la contención en determinadas colisiones de estructuras de bloqueo o de cubos de hash resulta inevitable. Aunque el motor de SQL Server crea particiones de la mayoría de las estructuras de bloqueo, todavía hay ocasiones en las que la adquisición de un bloqueo produce el acceso al mismo cubo de hash. Por ejemplo, una aplicación accede simultáneamente a la misma fila mediante muchos subprocesos (es decir, datos de referencia). Este tipo de problemas puede abordarse mediante técnicas que escalan horizontalmente estos datos de referencia en el esquema de la base de datos o utilizan las sugerencias NOLOCK cuando es posible.
La primera línea de defensa en el ajuste cargas de trabajo de SQL Server consiste siempre en las prácticas de ajuste estándar (por ejemplo, indexación, optimización de consultas, optimización de E/S, etc.). Sin embargo, además de ajuste estándar que se realice, es importante seguir prácticas que reduzcan la cantidad de código necesario para realizar las operaciones. Aunque se sigan los procedimientos recomendados, todavía existe la posibilidad de que se produzca contención de bloqueos por subproceso en sistemas de alta simultaneidad ocupados. El uso de las herramientas y técnicas de este artículo puede ayudarte a aislar o a descartar este tipo de problemas y determinar cuándo es necesario recurrir a los recursos adecuados de Microsoft en busca de ayuda.
Es de esperar que estas técnicas proporcionen una metodología útil para este tipo de solución de problemas e información sobre algunas de las técnicas más avanzadas de generación de perfiles de rendimiento disponibles con SQL Server.
Anexo: Automatización de la captura de volcado de memoria
El siguiente script de eventos extendidos ha demostrado ser útil para automatizar la recopilación de volcados de memoria cuando la contención de bloqueos por subproceso se vuelve significativa. En algunos casos, se requerirán volcados de memoria para realizar un diagnóstico completo del problema o los equipos de soporte técnico de Microsoft lo solicitarán para realizar análisis detallados. En SQL Server 2008, hay un límite de 16 marcos de pilas de llamadas capturados por el generador de cubos, que puede que no sea lo suficientemente profundo como para determinar exactamente en qué parte del motor se escribe la pila de llamadas. SQL Server 2012 incorporó mejoras al aumentar a 32 el número de marcos de pilas de llamadas capturados por el generador de cubos.
El siguiente script de SQL se puede usar para automatizar el proceso de captura de volcados de memoria para ayudar a analizar la contención de bloqueos por subproceso:
/*
This script is provided "AS IS" with no warranties, and confers no rights.
Use: This procedure will monitor for spinlocks with a high number of backoff events
over a defined time period which would indicate that there is likely significant
spin lock contention.
Modify the variables noted below before running.
Requires:
xp_cmdshell to be enabled
sp_configure 'xp_cmd', 1
go
reconfigure
go
*********************************************************************************************************/
USE tempdb;
GO
IF object_id('sp_xevent_dump_on_backoffs') IS NOT NULL
DROP PROCEDURE sp_xevent_dump_on_backoffs
GO
CREATE PROCEDURE sp_xevent_dump_on_backoffs (
@sqldumper_path NVARCHAR(max) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"',
@dump_threshold INT = 500, --capture mini dump when the slot count for the top bucket exceeds this
@total_delay_time_seconds INT = 60, --poll for 60 seconds
@PID INT = 0,
@output_path NVARCHAR(MAX) = 'c:\',
@dump_captured_flag INT = 0 OUTPUT
)
AS
/*
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
*/
IF EXISTS (
SELECT *
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump'
)
DROP EVENT SESSION spinlock_backoff_with_dump
ON SERVER
CREATE EVENT SESSION spinlock_backoff_with_dump ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
--or type = 144 --SOS_CACHESTORE
--or type = 8 --MUTEX
--or type = 53 --LOGCACHE_ACCESS
--or type = 41 --LOGFLUSHQ
--or type = 25 --SQL_MGR
--or type = 39 --XDESMGR
) ADD target package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
)
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = START;
DECLARE @instance_name NVARCHAR(MAX) = @@SERVICENAME;
DECLARE @loop_count INT = 1;
DECLARE @xml_result XML;
DECLARE @slot_count BIGINT;
DECLARE @xp_cmdshell NVARCHAR(MAX) = NULL;
--start polling for the backoffs
PRINT 'Polling for: ' + convert(VARCHAR(32), @total_delay_time_seconds) + ' seconds';
WHILE (@loop_count < CAST(@total_delay_time_seconds / 1 AS INT))
BEGIN
WAITFOR DELAY '00:00:01'
--get the xml from the bucketizer for the session
SELECT @xml_result = CAST(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
--get the highest slot count from the bucketizer
SELECT @slot_count = @xml_result.value(N'(//Slot/@count)[1]', 'int');
--if the slot count is higher than the threshold in the one minute period
--dump the process and clean up session
IF (@slot_count > @dump_threshold)
BEGIN
PRINT 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 c:\ '''
SELECT @xp_cmdshell = 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 ' + @output_path + ' '''
EXEC sp_executesql @xp_cmdshell
PRINT 'loop count: ' + convert(VARCHAR(128), @loop_count)
PRINT 'slot count: ' + convert(VARCHAR(128), @slot_count)
SET @dump_captured_flag = 1
BREAK
END
--otherwise loop
SET @loop_count = @loop_count + 1
END;
--see what was collected then clean up
DBCC TRACEON (3656, -1);
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = STOP;
DROP EVENT SESSION spinlock_backoff_with_dump ON SERVER;
GO
/* CAPTURE THE DUMPS
******************************************************************/
--Example: This will run continuously until a dump is created.
DECLARE @sqldumper_path NVARCHAR(MAX) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"';
DECLARE @dump_threshold INT = 300; --capture mini dump when the slot count for the top bucket exceeds this
DECLARE @total_delay_time_seconds INT = 60; --poll for 60 seconds
DECLARE @PID INT = 0;
DECLARE @flag TINYINT = 0;
DECLARE @dump_count TINYINT = 0;
DECLARE @max_dumps TINYINT = 3; --stop after collecting this many dumps
DECLARE @output_path NVARCHAR(max) = 'c:\'; --no spaces in the path please :)
--Get the process id for sql server
DECLARE @error_log TABLE (
LogDate DATETIME,
ProcessInfo VARCHAR(255),
TEXT VARCHAR(max)
);
INSERT INTO @error_log
EXEC ('xp_readerrorlog 0, 1, ''Server Process ID''');
SELECT @PID = convert(INT, (REPLACE(REPLACE(TEXT, 'Server Process ID is ', ''), '.', '')))
FROM @error_log
WHERE TEXT LIKE ('Server Process ID is%');
PRINT 'SQL Server PID: ' + convert(VARCHAR(6), @PID);
--Loop to monitor the spinlocks and capture dumps. while (@dump_count < @max_dumps)
BEGIN
EXEC sp_xevent_dump_on_backoffs @sqldumper_path = @sqldumper_path,
@dump_threshold = @dump_threshold,
@total_delay_time_seconds = @total_delay_time_seconds,
@PID = @PID,
@output_path = @output_path,
@dump_captured_flag = @flag OUTPUT
IF (@flag > 0)
SET @dump_count = @dump_count + 1
PRINT 'Dump Count: ' + convert(VARCHAR(2), @dump_count)
WAITFOR DELAY '00:00:02'
END;
Anexo: Captura de estadísticas de bloqueo por subproceso a lo largo del tiempo
El siguiente script se puede usar para examinar las estadísticas de bloqueo por subproceso a lo largo de un período de tiempo específico. Cada vez que se ejecute, devolverá la diferencia entre los valores actuales y los valores anteriores recopilados.
/* Snapshot the current spinlock stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
USE tempdb;
GO
DECLARE @current_snap_time DATETIME;
DECLARE @previous_snap_time DATETIME;
SET @current_snap_time = GETDATE();
IF NOT EXISTS (
SELECT name
FROM tempdb.sys.sysobjects
WHERE name LIKE '#_spin_waits%'
)
CREATE TABLE #_spin_waits (
lock_name VARCHAR(128),
collisions BIGINT,
spins BIGINT,
sleep_time BIGINT,
backoffs BIGINT,
snap_time DATETIME
);
--capture the current stats
INSERT INTO #_spin_waits (
lock_name,
collisions,
spins,
sleep_time,
backoffs,
snap_time
)
SELECT name,
collisions,
spins,
sleep_time,
backoffs,
@current_snap_time
FROM sys.dm_os_spinlock_stats;
SELECT TOP 1 @previous_snap_time = snap_time
FROM #_spin_waits
WHERE snap_time < (
SELECT max(snap_time)
FROM #_spin_waits
)
ORDER BY snap_time DESC;
--get delta in the spin locks stats
SELECT TOP 10 spins_current.lock_name,
(spins_current.collisions - spins_previous.collisions) AS collisions,
(spins_current.spins - spins_previous.spins) AS spins,
(spins_current.sleep_time - spins_previous.sleep_time) AS sleep_time,
(spins_current.backoffs - spins_previous.backoffs) AS backoffs,
spins_previous.snap_time AS [start_time],
spins_current.snap_time AS [end_time],
DATEDIFF(ss, @previous_snap_time, @current_snap_time) AS [seconds_in_sample]
FROM #_spin_waits spins_current
INNER JOIN (
SELECT *
FROM #_spin_waits
WHERE snap_time = @previous_snap_time
) spins_previous
ON (spins_previous.lock_name = spins_current.lock_name)
WHERE spins_current.snap_time = @current_snap_time
AND spins_previous.snap_time = @previous_snap_time
AND spins_current.spins > 0
ORDER BY (spins_current.spins - spins_previous.spins) DESC;
--clean up table
DELETE
FROM #_spin_waits
WHERE snap_time = @previous_snap_time;
Paso siguiente
Comentaris
Properament: al llarg del 2024 eliminarem gradualment GitHub Issues com a mecanisme de retroalimentació del contingut i el substituirem per un nou sistema de retroalimentació. Per obtenir més informació, consulteu: https://aka.ms/ContentUserFeedback.
Envieu i consulteu els comentaris de