Kurz: Zpracování uložených dokumentů pomocí Azure Functions a Pythonu
Funkce Document Intelligence je možné použít jako součást kanálu automatizovaného zpracování dat sestaveného pomocí azure Functions. V této příručce se dozvíte, jak pomocí Azure Functions zpracovávat dokumenty nahrané do kontejneru úložiště objektů blob v Azure. Tento pracovní postup extrahuje data tabulky z uložených dokumentů pomocí modelu rozložení Document Intelligence a uloží data tabulky do souboru .csv v Azure. Data pak můžete zobrazit pomocí Microsoft Power BI (tady nejsou uvedená).

V tomto kurzu se naučíte:
- Vytvořit účet služby Azure Storage
- Vytvořte projekt Azure Functions.
- Extrahujte data rozložení z nahraných formulářů.
- Nahrání extrahovaných dat rozložení do Azure Storage
Požadavky
Bezplatné vytvoření předplatného - Azure
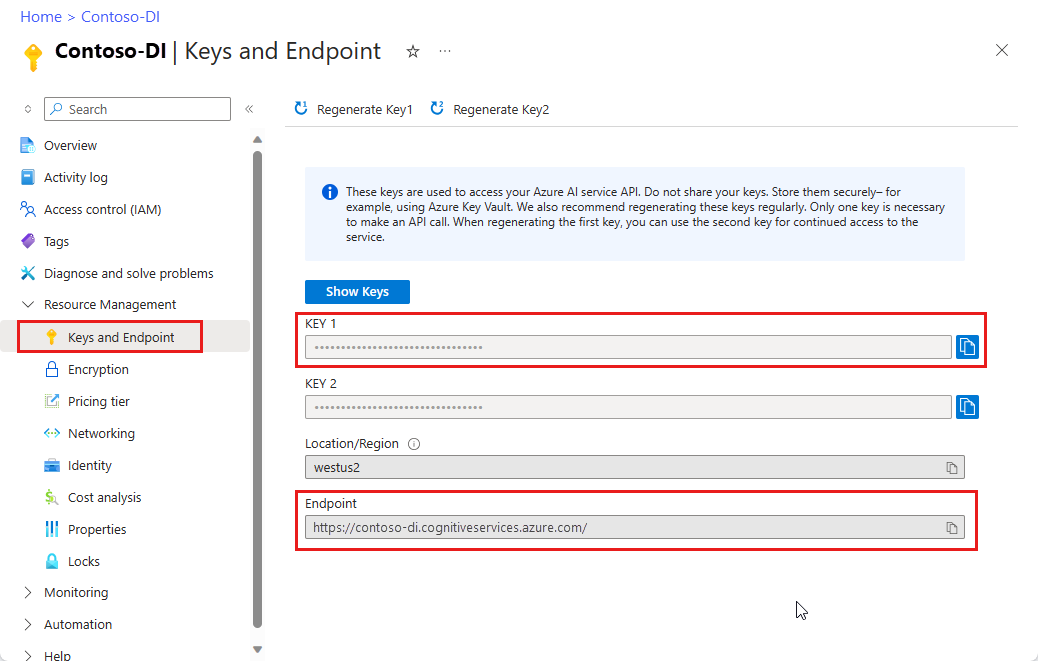
Prostředek Document Intelligence Jakmile budete mít předplatné Azure, vytvořte na webu Azure Portal prostředek Document Intelligence, abyste získali klíč a koncový bod. K vyzkoušení služby můžete použít cenovou úroveň
F0Free a později upgradovat na placenou úroveň pro produkční prostředí.Po nasazení prostředku vyberte Přejít k prostředku. Klíč a koncový bod z prostředku, který vytvoříte, potřebujete k připojení aplikace k rozhraní DOCUMENT Intelligence API. Klíč a koncový bod vložíte do kódu níže v tomto kurzu:
Python 3.6.x, 3.7.x, 3.8.x nebo 3.9.x (Python 3.10.x není pro tento projekt podporovaný).
Nejnovější verze editoru Visual Studio Code (VS Code) s nainstalovanými následujícími rozšířeními:
Rozšíření Azure Functions Po instalaci by se v levém navigačním podokně mělo zobrazit logo Azure.
Azure Functions Core Tools verze 3.x (verze 4.x není pro tento projekt podporovaná).
Rozšíření Pythonu pro Visual Studio Code Další informace najdete v tématuZačínáme s Pythonem ve VS Code.
Místní dokument PDF, který se má analyzovat. Pro tento projekt můžete použít náš ukázkový dokument PDF.
Vytvoření účtu služby Azure Storage
Na webu Azure Portal vytvořte účet Azure Storage pro obecné účely verze 2. Pokud nevíte, jak vytvořit účet úložiště Azure s kontejnerem úložiště, postupujte podle těchto rychlých startů:
- Vytvoření účtu úložiště Při vytváření účtu úložiště v poli Výkon podrobností instance>vyberte Výkon úrovně Standard.
- Vytvořte kontejner. Při vytváření kontejneru nastavte úroveň veřejného přístupu na Kontejner (anonymní přístup pro čtení kontejnerů a souborů) v okně Nový kontejner.
V levém podokně vyberte kartu Sdílení prostředků (CORS) a odeberte existující zásady CORS, pokud nějaké existují.
Po nasazení účtu úložiště vytvořte dva prázdné kontejnery úložiště objektů blob s názvem vstup a výstup.
Vytvoření projektu služby Azure Functions
Vytvořte novou složku s názvem functions-app , která bude obsahovat projekt, a zvolte Vybrat.
Otevřete Visual Studio Code a otevřete paletu příkazů (Ctrl+Shift+P). Vyhledejte a zvolte interpret Python:Select → zvolte nainstalovaný interpret Pythonu, který je verze 3.6.x, 3.7.x, 3.8.x nebo 3.9.x. Tento výběr přidá cestu interpreta Pythonu, kterou jste vybrali do projektu.
V levém navigačním podokně vyberte logo Azure.
Vaše existující prostředky Azure uvidíte v zobrazení Prostředky.
Vyberte předplatné Azure, které používáte pro tento projekt, a níže byste měli vidět aplikaci Funkcí Azure.

Vyberte oddíl Pracovní prostor (místní) umístěný pod vašimi uvedenými prostředky. Vyberte symbol plus a zvolte tlačítko Vytvořit funkci .

Po zobrazení výzvy zvolte Vytvořit nový projekt a přejděte do adresáře aplikace funkcí. Zvolte Vybrat.
Zobrazí se výzva ke konfiguraci několika nastavení:
Vyberte jazyk , → zvolte Python.
Výběrem interpreta Pythonu vytvořte virtuální prostředí → vyberte interpret, který jste nastavili jako výchozí dříve.
Vyberte šablonu → zvolte trigger služby Azure Blob Storage a dejte triggeru název nebo přijměte výchozí název. Potvrďte to stisknutím klávesy Enter .
V rozevírací nabídce vyberte nastavení → zvolte ➕Vytvořit nové nastavení místní aplikace.
Vyberte předplatné → zvolte předplatné Azure s účtem úložiště, který jste vytvořili → vyberte svůj účet úložiště → pak vyberte název vstupního kontejneru úložiště (v tomto případě
input/{name}). Potvrďte to stisknutím klávesy Enter .V rozevírací nabídce vyberte, jak chcete projekt otevřít → zvolte Otevřít projekt v aktuálním okně .
Jakmile dokončíte tyto kroky, VS Code přidá nový projekt funkce Azure s skriptem __init__.py Pythonu. Tento skript se aktivuje při nahrání souboru do vstupního kontejneru úložiště:
import logging
import azure.functions as func
def main(myblob: func.InputStream):
logging.info(f"Python blob trigger function processed blob \n"
f"Name: {myblob.name}\n"
f"Blob Size: {myblob.length} bytes")
Testování funkce
Stisknutím klávesy F5 spusťte základní funkci. VS Code zobrazí výzvu k výběru účtu úložiště pro rozhraní.
Vyberte účet úložiště, který jste vytvořili, a pokračujte.
Otevřete Průzkumník služby Azure Storage a nahrajte ukázkový dokument PDF do vstupního kontejneru. Pak zkontrolujte terminál VS Code. Skript by měl protokolovat, že ho aktivoval nahrání PDF.

Před pokračováním zastavte skript.
Přidání kódu pro zpracování dokumentů
Dále do skriptu Pythonu přidáte vlastní kód, který zavolá službu Document Intelligence a parsuje nahrané dokumenty pomocí modelu rozložení Document Intelligence.
Ve VS Code přejděte do souboru requirements.txt funkce. Tento soubor definuje závislosti pro váš skript. Do souboru přidejte následující balíčky Pythonu:
cryptography azure-functions azure-storage-blob azure-identity requests pandas numpyPak otevřete __init__.py skript. Přidejte následující příkazy
import:import logging from azure.storage.blob import BlobServiceClient import azure.functions as func import json import time from requests import get, post import os import requests from collections import OrderedDict import numpy as np import pandas as pdVygenerovanou
mainfunkci můžete nechat tak, jak je. Do této funkce přidáte vlastní kód.# This part is automatically generated def main(myblob: func.InputStream): logging.info(f"Python blob trigger function processed blob \n" f"Name: {myblob.name}\n" f"Blob Size: {myblob.length} bytes")Následující blok kódu volá rozhraní API pro analýzu analýzy dokumentů v nahraném dokumentu. Vyplňte hodnoty koncového bodu a klíče.
# This is the call to the Document Intelligence endpoint endpoint = r"Your Document Intelligence Endpoint" apim_key = "Your Document Intelligence Key" post_url = endpoint + "/formrecognizer/v2.1/layout/analyze" source = myblob.read() headers = { # Request headers 'Content-Type': 'application/pdf', 'Ocp-Apim-Subscription-Key': apim_key, } text1=os.path.basename(myblob.name)Důležité
Nezapomeňte klíč z kódu odebrat, až to budete hotovi, a nikdy ho veřejně neposílejte. V produkčním prostředí použijte bezpečný způsob ukládání přihlašovacích údajů a přístupu k vašim přihlašovacím údajům, jako je Azure Key Vault. Další informace najdete v tématu Zabezpečení služeb Azure AI.
Dále přidejte kód pro dotazování služby a získejte vrácená data.
resp = requests.post(url=post_url, data=source, headers=headers) if resp.status_code != 202: print("POST analyze failed:\n%s" % resp.text) quit() print("POST analyze succeeded:\n%s" % resp.headers) get_url = resp.headers["operation-location"] wait_sec = 25 time.sleep(wait_sec) # The layout API is async therefore the wait statement resp = requests.get(url=get_url, headers={"Ocp-Apim-Subscription-Key": apim_key}) resp_json = json.loads(resp.text) status = resp_json["status"] if status == "succeeded": print("POST Layout Analysis succeeded:\n%s") results = resp_json else: print("GET Layout results failed:\n%s") quit() results = resp_jsonPřidejte následující kód pro připojení k výstupnímu kontejneru Azure Storage. Jako název a klíč účtu úložiště zadejte vlastní hodnoty. Klíč můžete získat na kartě Přístupové klíče vašeho prostředku úložiště na webu Azure Portal.
# This is the connection to the blob storage, with the Azure Python SDK blob_service_client = BlobServiceClient.from_connection_string("DefaultEndpointsProtocol=https;AccountName="Storage Account Name";AccountKey="storage account key";EndpointSuffix=core.windows.net") container_client=blob_service_client.get_container_client("output")Následující kód analyzuje vrácenou odpověď Document Intelligence, vytvoří soubor .csv a nahraje ho do výstupního kontejneru.
Důležité
Tento kód budete pravděpodobně muset upravit tak, aby odpovídal struktuře vlastních dokumentů.
# The code below extracts the json format into tabular data. # Please note that you need to adjust the code below to your form structure. # It probably won't work out-of-the-box for your specific form. pages = results["analyzeResult"]["pageResults"] def make_page(p): res=[] res_table=[] y=0 page = pages[p] for tab in page["tables"]: for cell in tab["cells"]: res.append(cell) res_table.append(y) y=y+1 res_table=pd.DataFrame(res_table) res=pd.DataFrame(res) res["table_num"]=res_table[0] h=res.drop(columns=["boundingBox","elements"]) h.loc[:,"rownum"]=range(0,len(h)) num_table=max(h["table_num"]) return h, num_table, p h, num_table, p= make_page(0) for k in range(num_table+1): new_table=h[h.table_num==k] new_table.loc[:,"rownum"]=range(0,len(new_table)) row_table=pages[p]["tables"][k]["rows"] col_table=pages[p]["tables"][k]["columns"] b=np.zeros((row_table,col_table)) b=pd.DataFrame(b) s=0 for i,j in zip(new_table["rowIndex"],new_table["columnIndex"]): b.loc[i,j]=new_table.loc[new_table.loc[s,"rownum"],"text"] s=s+1Poslední blok kódu nakonec nahraje extrahovaná tabulka a textová data do elementu úložiště objektů blob.
# Here is the upload to the blob storage tab1_csv=b.to_csv(header=False,index=False,mode='w') name1=(os.path.splitext(text1)[0]) +'.csv' container_client.upload_blob(name=name1,data=tab1_csv)
Spuštění funkce
Opětovným stisknutím klávesy F5 funkci spusťte.
Pomocí Průzkumník služby Azure Storage nahrajte ukázkový formulář PDF do vstupního kontejneru úložiště. Tato akce by měla aktivovat spuštění skriptu a v výstupním kontejneru by se měl zobrazit výsledný soubor .csv (zobrazený jako tabulka).
Tento kontejner můžete připojit k Power BI a vytvořit bohaté vizualizace dat, která obsahuje.
Další kroky
V tomto kurzu jste se naučili používat funkci Azure Functions napsanou v Pythonu k automatickému zpracování nahraných dokumentů PDF a výstupu jejich obsahu v popisnějším formátu dat. Dále se dozvíte, jak pomocí Power BI zobrazit data.
- Co je funkce Document Intelligence?
- Další informace o modelu rozložení