Vlastní modely: přesnost a skóre spolehlivosti
Tento obsah se vztahuje na:![]() v4.0 (Preview)
v4.0 (Preview)![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Poznámka:
- Vlastní neurální modely během trénování neposkytují skóre přesnosti.
- Skóre spolehlivosti pro tabulky, řádky tabulky a buňky tabulky jsou k dispozici od verze rozhraní API 2024-02-02-29-preview pro vlastní modely.
Vlastní modely šablon generují odhadované skóre přesnosti při trénování. Dokumenty analyzované pomocí vlastního modelu vytvářejí skóre spolehlivosti pro extrahovaná pole. V tomto článku se naučíte interpretovat přesnost a skóre spolehlivosti a osvědčené postupy pro použití těchto skóre ke zlepšení přesnosti a výsledků spolehlivosti.
Skóre přesnosti
Výstup operace vlastního build modelu (v3.0) nebo train (v2.1) zahrnuje odhadované skóre přesnosti. Toto skóre představuje schopnost modelu přesně předpovědět popisovanou hodnotu ve vizuálně podobném dokumentu.
Rozsah hodnot přesnosti je procento mezi 0 % (nízké) a 100 % (vysoké). Odhadovaná přesnost se vypočítá spuštěním několika různých kombinací trénovacích dat, které předpovědí označených hodnot.
Document Intelligence Studio
– trénovaný vlastní model (faktura)
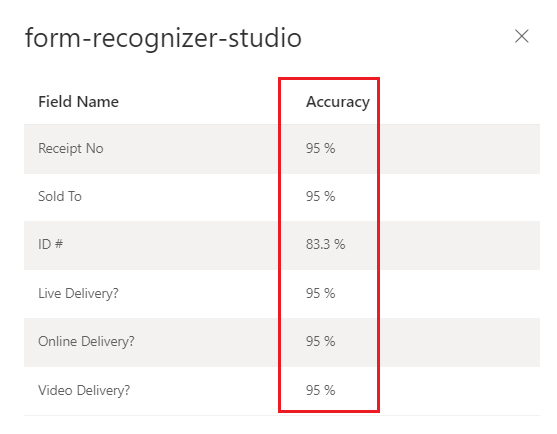
Skóre spolehlivosti
Poznámka:
- Skóre spolehlivosti tabulek, řádků a buněk jsou teď součástí verze rozhraní API 2024-02-02-29-preview.
- Skóre spolehlivosti pro buňky tabulky z vlastních modelů se přidá do rozhraní API počínaje rozhraním API verze 2024-02-02-29-preview.
Výsledky analýzy Document Intelligence vrací odhadovanou spolehlivost pro předpovězená slova, páry klíč-hodnota, značky výběru, oblasti a podpisy. V současné době ne všechna pole dokumentu vrací skóre spolehlivosti.
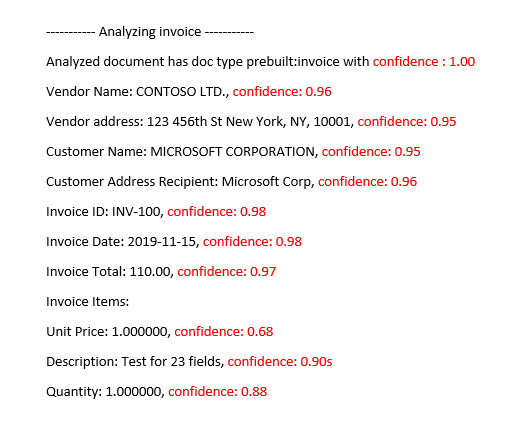
Spolehlivost pole označuje odhadovanou pravděpodobnost mezi 0 a 1, že předpověď je správná. Například hodnota spolehlivosti 0,95 (95 %) značí, že předpověď je pravděpodobně správná 19krát z 20krát. V případě scénářů, kdy je přesnost kritická, je možné pomocí spolehlivosti určit, jestli se má předpověď automaticky přijmout, nebo ji označit příznakem pro kontrolu člověka.
Model předpřipravené faktury v sadě Document Intelligence Studio
Interpretace přesnosti a skóre spolehlivosti pro vlastní modely
Při interpretaci skóre spolehlivosti z vlastního modelu byste měli zvážit všechna skóre spolehlivosti vrácená z modelu. Začněme seznamem všech skóre spolehlivosti.
- Skóre spolehlivosti typu dokumentu: Spolehlivost typu dokumentu je indikátorem úzce analyzovaného dokumentu, který se podobá dokumentům v trénovací datové sadě. Pokud je spolehlivost typu dokumentu nízká, značí to šablony nebo strukturální variace v analyzovaném dokumentu. Pokud chcete zvýšit spolehlivost typu dokumentu, označte dokument s danou variantou a přidejte ho do trénovací datové sady. Jakmile je model přetrénovaný, měl by být lépe vybavený pro zpracování této třídy variant.
- Spolehlivost na úrovni pole: Každé extrahované pole s popiskem má přidružené skóre spolehlivosti. Toto skóre odráží spolehlivost modelu na pozici extrahované hodnoty. Při vyhodnocování skóre spolehlivosti byste se také měli podívat na základní spolehlivost extrakce, abyste získali komplexní jistotu pro extrahovaný výsledek.
OCRVyhodnoťte výsledky pro extrakci textu nebo značky výběru v závislosti na typu pole a vygenerujte pro dané pole složené skóre spolehlivosti. - Skóre spolehlivosti Wordu Každé slovo extrahované v dokumentu má přidružené skóre spolehlivosti. Skóre představuje jistotu přepisu. Pole stránek obsahuje matici slov a každé slovo má přidružené rozpětí a skóre spolehlivosti. Rozsahy z extrahovaných hodnot vlastního pole odpovídají rozsahům extrahovaných slov.
- Skóre spolehlivosti značky výběru: Pole stránek obsahuje také matici značek výběru. Každá značka výběru má skóre spolehlivosti, které představuje spolehlivost značky výběru a detekce stavu výběru. Pokud má označené pole značku výběru, vlastní výběr pole v kombinaci s jistotou značky výběru představuje přesnou reprezentaci celkové přesnosti spolehlivosti.
Následující tabulka ukazuje, jak interpretovat skóre přesnosti a spolehlivosti za účelem měření výkonu vlastního modelu.
| Přesnost | Spolehlivost | Výsledek |
|---|---|---|
| Vysoká | Vysoká | • Model dobře funguje s popisky a formáty dokumentů. • Máte vyváženou trénovací datovou sadu. |
| Vysoká | Nízká | • Analyzovaný dokument se liší od trénovací datové sady. • Model by byl přínosem pro opětovné trénování s nejméně pěti dalšími označenými dokumenty. • Tyto výsledky můžou také znamenat variaci formátu mezi trénovací datovou sadou a analyzovaným dokumentem. Zvažte přidání nového modelu. |
| Malý zájem | Velký zájem | • Tento výsledek je nejpravděpodobnější. • Pro skóre s nízkou přesností přidejte další označená data nebo rozdělte vizuálně odlišné dokumenty do více modelů. |
| Nízká | Nízká | • Přidejte další označená data. • Rozdělte vizuálně odlišné dokumenty do více modelů. |
Spolehlivost tabulek, řádků a buněk
S přidáním tabulky, řádku a spolehlivosti buněk s 2024-02-29-preview rozhraním API najdete některé běžné otázky, které by vám měly pomoct s interpretací skóre tabulky, řádku a buněk:
Otázka: Je možné zobrazit vysoké skóre spolehlivosti pro buňky, ale nízké skóre spolehlivosti pro řádek?
Odpověď: Ano. Různé úrovně spolehlivosti tabulky (buňka, řádek a tabulka) jsou určeny k zachycení správnosti předpovědi na této konkrétní úrovni. Správně předpovězená buňka, která patří do řádku s jinými možnými chybami, by měla mít vysokou spolehlivost buněk, ale spolehlivost řádku by měla být nízká. Podobně by správný řádek v tabulce s výzvami s jinými řádky měl vysokou spolehlivost řádků, zatímco celková spolehlivost tabulky by byla nízká.
Otázka: Jaké je očekávané skóre spolehlivosti při sloučení buněk? Vzhledem k tomu, že sloučení vede ke změně počtu sloupců, jak jsou ovlivněny skóre?
A: Bez ohledu na typ tabulky očekáváte u sloučených buněk, že by měly mít nižší hodnoty spolehlivosti. Kromě toho by buňka, která chybí (protože byla sloučena se sousední buňkou), měla mít NULL také hodnotu s nižší jistotou. Kolik těchto hodnot může být nižší, závisí na trénovací datové sadě, obecný trend sloučených i chybějících buněk s nižším skóre by měl obsahovat.
Otázka: Jaké je skóre spolehlivosti, pokud je hodnota volitelná? Měli byste očekávat buňku NULL s hodnotou a vysokým skóre spolehlivosti, pokud hodnota chybí?
A: Pokud trénovací datová sada představuje volitelnost buněk, pomůže modelu zjistit, jak často se hodnota v trénovací sadě zobrazuje, a proto, co očekávat během odvozování. Tato funkce se používá při výpočtu spolehlivosti predikce nebo bez predikce (NULL). U chybějících hodnot, které jsou v trénovací sadě většinou prázdné, byste měli očekávat prázdné pole s vysokou jistotou.
Otázka: Jak ovlivňuje skóre spolehlivosti, pokud je pole volitelné a není k dispozici nebo chybí? Je očekávané, že skóre spolehlivosti odpovídá na tuto otázku?
A: Pokud v řádku chybí hodnota, má buňka přiřazenou hodnotu a jistotu NULL . Tady by mělo vysoké skóre spolehlivosti znamenat, že predikce modelu (bez hodnoty) bude pravděpodobně správná. Naproti tomu nízké skóre by mělo signalizovat větší nejistotu z modelu (a tím i možnost chyby, jako je zmeškaná hodnota).
Otázka: Jaká by měla být očekávání spolehlivosti buněk a spolehlivosti řádků při extrahování vícestráncové tabulky s řádkem rozděleným na stránky?
A: Očekáváte, že spolehlivost buňky bude vysoká a spolehlivost řádků může být potenciálně nižší než řádky, které nejsou rozděleny. Podíl rozdělených řádků v trénovací sadě dat může ovlivnit skóre spolehlivosti. Obecně platí, že rozdělený řádek vypadá jinak než ostatní řádky v tabulce (proto je model méně jistý, že je správný).
Otázka: U křížových tabulek s řádky, které čistě končí a začínají na hranicích stránky, je správné předpokládat, že skóre spolehlivosti jsou konzistentní napříč stránkami?
Odpověď: Ano. Vzhledem k tomu, že řádky vypadají podobně ve tvaru a obsahu bez ohledu na to, kde jsou v dokumentu (nebo na které stránce), měly by mít odpovídající skóre spolehlivosti konzistentní.
Otázka: Jaký je nejlepší způsob využití nových skóre spolehlivosti?
A: Podívejte se na všechny úrovně spolehlivosti tabulky, které začínají v přístupu shora dolů: začněte kontrolou spolehlivosti tabulky jako celku, pak přejděte k podrobnostem na úrovni řádku a podívejte se na jednotlivé řádky a nakonec se podívejte na jistoty na úrovni buněk. V závislosti na typu tabulky je potřeba poznamenat několik věcí:
U pevných tabulek už spolehlivost na úrovni buněk zachycuje poměrně hodně informací o správnosti věcí. To znamená, že stačí přecházet přes každou buňku a dívat se na její spolehlivost, aby pomohl určit kvalitu předpovědi. U dynamických tabulek jsou úrovně určené k tomu, aby byly vzájemně postavené na sobě, takže přístup shora dolů je důležitější.
Zajištění vysoké úspěšnosti modelu
Odchylky ve vizuální struktuře dokumentů ovlivňují přesnost modelu. Hlášená skóre úspěšnosti můžou být nekonzistentní, pokud se analyzované dokumenty liší od dokumentů používaných při trénování. Mějte na paměti, že sada dokumentů může při prohlížení lidmi vypadat podobně, ale modelu AI se může jevit jako nepodobná. Postup je seznam osvědčených postupů pro trénování modelů s nejvyšší přesností. Podle těchto pokynů by měl vytvořit model s vyšší přesností a skóre spolehlivosti během analýzy a snížit počet dokumentů označených pro kontrolu člověka.
Ujistěte se, že jsou v trénovací datové sadě zahrnuté všechny varianty dokumentu. Variace zahrnují různé formáty, například digitální nebo naskenované dokumenty PDF.
Pokud očekáváte, že model bude analyzovat oba typy dokumentů PDF, přidejte do trénovací datové sady alespoň pět vzorků každého typu.
Oddělte vizuálně odlišné typy dokumentů a vytrénujte pro ně samostatné modely.
- Obecně platí, že pokud odeberete všechny uživatelem zadané hodnoty a dokumenty vypadají podobně, musíte do existujícího modelu přidat další trénovací data.
- Pokud dokumenty nejsou podobné, rozdělte trénovací data do různých složek a vytrénujte model pro každou variantu. Pak můžete různé varianty zakomponovat do jednoho modelu.
Ujistěte se, že nemáte žádné nadbytečné popisky.
Ujistěte se, že popisky podpisu a oblasti neobsahují okolní text.